
基于ALOHA和多叉树的混合型RFID防碰撞算法
2021-03-24 07:46周伟辉蒋年德万心悦闫成成郭晓天
东华理工大学学报(自然科学版) 2021年1期
周伟辉,蒋年德,万心悦,闫成成,郭晓天
(1.东华理工大学 长江学院,江西 抚州 344000;2.东华理工大学 信息工程学院,江西 南昌 330013)
射频识别(RFID)是一种利用射频信号通过空间电磁耦合实现无接触式自动识别的技术,是物联网的关键支撑技术(钱志鸿等, 2012)。目前国内RFID技术发展趋近成熟,标签制作成本不断减少,其应用范围不断扩大,涉及到物流管理、防伪、动物管理、门禁、智能识别等领域(Myung et al., 2006)。RFID系统构成一般有三部分:标签、阅读器和计算机后台系统。RFID技术的三大难题:统一标准、多标签碰撞和信息安全,其中多标签碰撞指的是阅读器发送信号,在信号范围内有多个标签同时响应,阅读器不能同时识别多个标签的现象。因此,提出一种有效且快速解决多标签碰撞问题的RFID标签防碰撞算法将具有重要研究意义(王鑫等,2016)。
为解决标签碰撞问题,已有两大类防碰撞算法:基于二进制树的确定性算法和基于ALOHA的随机性算法(王雪等, 2010)。基于树的算法有二进制搜索树算法(王汉武等, 2018.)、动态二进制搜索树算法(周伟辉等, 2018)、碰撞树算法(Jia et al., 2012)、自适应多叉树算法(丁治国等, 2010)、一种改进的自适应多叉树防碰撞算法(王汉武等, 2018)、二进制分裂的空闲时隙消除算法(Su et al.,2017)、自调整混合树(AHT)算法(宋建华等, 2014)等。基于ALOHA算法主要包括时隙ALOHA算法(Liva, 2011)、帧时隙ALOHA算法(Wu et al., 2011)、动态帧时隙ALOHA(DFSA)算法(Deng et al., 2011)等。这两大类算法都能解决多标签碰撞问题,但ALOHA算法具有随机性,当待识别标签数目庞大时,标签碰撞的概率增加,且可能会出现某些标签经过N次碰撞,仍不能被识别,出现标签“饿死”现象,而基于树的算法虽然可以实现100%的标签读取率,但是识别时间较长。
笔者针对在标签数量较大情况下,DFSA算法吞吐量降低并可能出现标签不能被100%识别和多叉树算法识别标签时间增加的缺点,提出了一种ALOHA和多叉树的混合型(HAMT)算法。该算法首先采用DFSA算法进行标签识别,然后根据未识别标签数目动态选择多叉树算法进行标签识别,从而保证了标签100%被识别,提高吞吐率和缩短了识别时间。
1 HAMT算法
1.1 曼彻斯特编码
曼彻斯特编码通过电平的升降变化来描述逻辑“0”或逻辑“1”。在HAMT算法中,其主要作用是阅读器可以通过它准确地检测出标签ID之间的碰撞位。假设有Tag1和Tag2两个标签,它们ID编码分别为:0010110和0010001,通过曼彻斯特编码可以检测出碰撞位信息为0x10xxx。
1.2 HAMT算法思想
HAMT算法识别标签经过两个阶段:动态帧时隙阶段和多叉树阶段。动态帧时隙阶段:根据待识别标签数目确定时隙帧长,再根据时隙选择规则,标签选择其自身所响应的时隙号,最后判断时隙的状态,若碰撞则进入多叉树阶段。多叉树阶段:根据碰撞标签的数目,动态选择多叉树的叉数。阅读器利用曼彻斯特编码原则检测碰撞位,利用碰撞位获取查询前缀。
1.3 HAMT算法流程
在HAMT算法中,用i表示时隙号,用Vogt算法(张小红等, 2018)估计待识别标签数目N的值,并不断采用DFSA算法和自适应多叉树算法进行标签的识别,直到待识别标签数为0,算法结束(图1)。
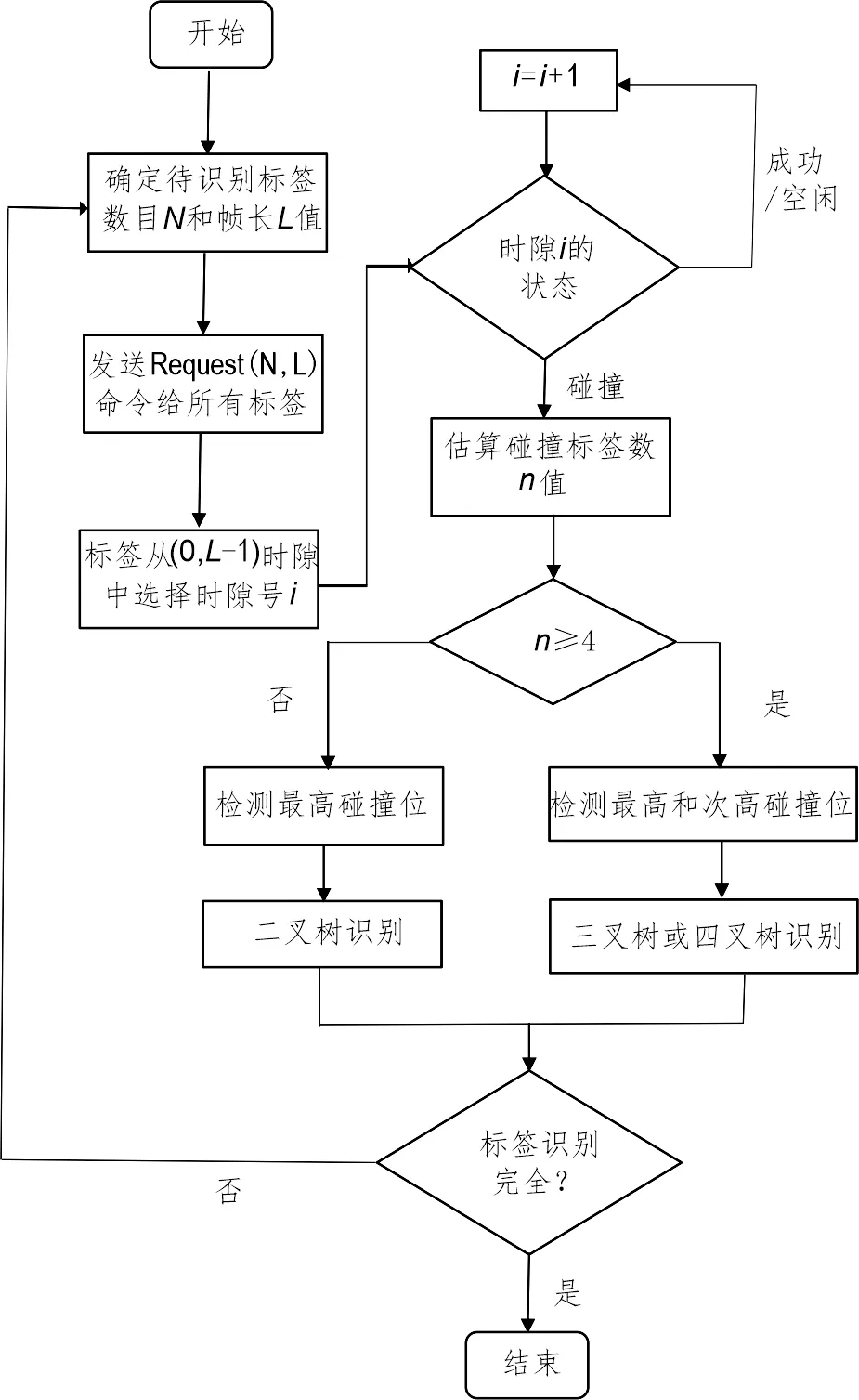
图1 HAMT算法流程图Fig.1 Flow chart of HAMT algorithm
步骤1:利用Vogt算法估算待识别标签数目N的值。有文献(张小红等, 2018)指出,帧长L与标签总数N存在以下关系:
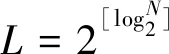
(1)
由公式(1)可计算出所需帧长L;
步骤2:阅读器发送Request(N,L)命令给所有标签,所有标签应答;
步骤3:标签根据自身ID号从(0,L-1)时隙中选择其所需时隙号i;
步骤4:判断时隙i的状态,有以下3种情况:
①时隙i为成功时隙,即该时隙中有且仅有1个标签响应,为成功识别标签。进行下一个时隙i=i+1;
②时隙i为空闲时隙,即该时隙没有标签响应,进行下一个时隙i=i+1;
③时隙i为碰撞时隙,即该时隙有2个以上标签响应,为碰撞标签,这些标签进入下一步进行处理;
步骤5:估算出碰撞标签数目n的值,判断n是否大于等于4:
若n≥4,阅读器检测最高和次高碰撞位的值,根据这两位的值,采用三叉树算法或四叉树算法进行识别;
若n<4,阅读器只检测最高碰撞位的值,采用二叉树算法进行识别;
步骤6:判断标签是否全部识别成功;
步骤7:若待识别标签还未全部识别成功,则跳转到步骤1;
步骤8:若待识别标签全部被识别,则算法结束。
1.4 HAMT算法实例演示
假设阅读器读取范围内共有10个待识别标签,其ID编码长度为8位,分别为TagA:10000110,TagB:11010010,TagC:01000010,TagD:01001010,TagE:10010010,TagF:00001010,TagG:10110011,TagH:01010101,TagI:01101100,TagJ:00110011。采用HAMT算法识别过程如下:
(1)由于待识别标签数目N=10,可计算出帧长L=8;
(2)检测最高碰撞位,得到最高碰撞位以后3位的信息,根据这3位信息选择响应的时隙号,如(100)A=(100)E=4,所以TagA和TagE响应在时隙4中,可依次分别计算出TagF响应在时隙0中,TagJ响应在时隙1中,TagC、D和H响应在时隙2中,TagI响应在时隙3中,TagG响应在时隙5中,TagB响应在时隙6中,成功识别了TagB、F、G、I和J;
(3) 根据上一步可以得到时隙2中有3个碰撞标签,分别是TagC、TagD和TagH,时隙4中有2个碰撞标签,分别是TagA和E;
(4)由于时隙2中有3个碰撞标签,所以阅读器再检测最高个次高碰撞位,得到碰撞信息为:“00”、“01”和“10”,采用三叉树算法进行识别,成功识别TagC、D和H。
(5)由于时隙4中有2个碰撞标签,分别为TagA和TagE,阅读器检测最高碰撞位,得到碰撞信息为:“0”和“1”,采用二叉树算法进行识别,成功识别TagA和TagE;
(6)所有标签全部识别完成,算法结束。
识别10个待识别标签数,所耗总时隙数为13个,只有1个空闲时隙和2个碰撞时隙,并且在多叉树阶段完全没有碰撞时隙和空闲时隙的产生。所以HAMT算法可以大大减少碰撞时隙数和总时隙数,从而提高系统的吞吐率。
2 实验仿真
在MATLAB环境下进行编程对HAMT算法进行仿真分析与对比,对比的算法包括DFSA算法、ACT算法和AHT算法。待识别标签数N的取值范围为[10,1 000],仿真实验100次取其平均值,分别进行了4组仿真实验对比:总时隙数对比、碰撞时隙数对比、通信开销对比和吞吐率对比。
图2所示为4种不同算法所需的总时隙数。从图2可以得出,HAMT算法所需总时隙数最少。当待识别标签数为1 000时,HAMT、AHT、ACT和DFSA算法所需总时隙数分别约为1 400、1 810、2 100和5 500个,因此HAMT算法在总时隙数上有所优化,特别是标签数量较大时,优化更明显。

图2 不同算法的总时隙数Fig.2 Total number of slots with different algorithm
图3表示的是4种算法的碰撞时隙数。从图3中可以看出,HAMT算法所产生的碰撞时隙数明显少于其他3种算法,是因为HAMT算法只会在DFSA算法阶段产生碰撞时隙,在多叉树算法识别过程中可完全避免碰撞时隙的产生。
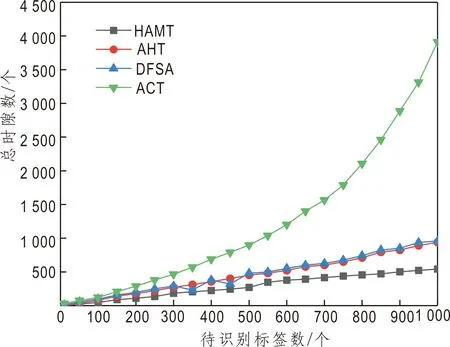
图3 不同算法的碰撞时隙数Fig.3 Collision time slots of different algorithm
图4为4种不同算法的吞吐率比较。吞吐率S指的是待识别标签总数N与在标签识别过程中所需总时隙数m之比,计算公式如下:
S=N/m
(2)
从图4可以看出,HAMT算法的吞吐率始终能够保持在0.72左右,明显优于其他3种算法。
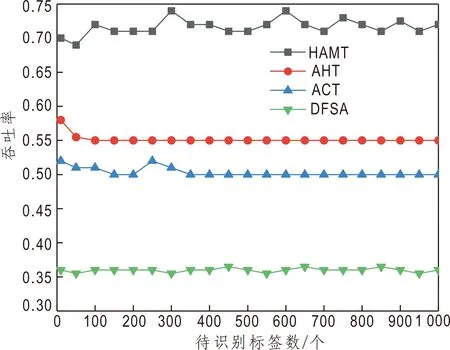
图4 不同算法吞吐率Fig.4 Throughput rate of different algorithm
图5为4种不同算法在系统通信开销中的对比。通信开销包括阅读器开销和标签开销,具体是指在标签识别过程中所要传送命令的总长度。从图5可以看出,HAMT的通信开销最低。当待识别标签总数位为1 000时,HAMT算法的通信开销为 1.0×10-5bit,明显低于其他3种算法。
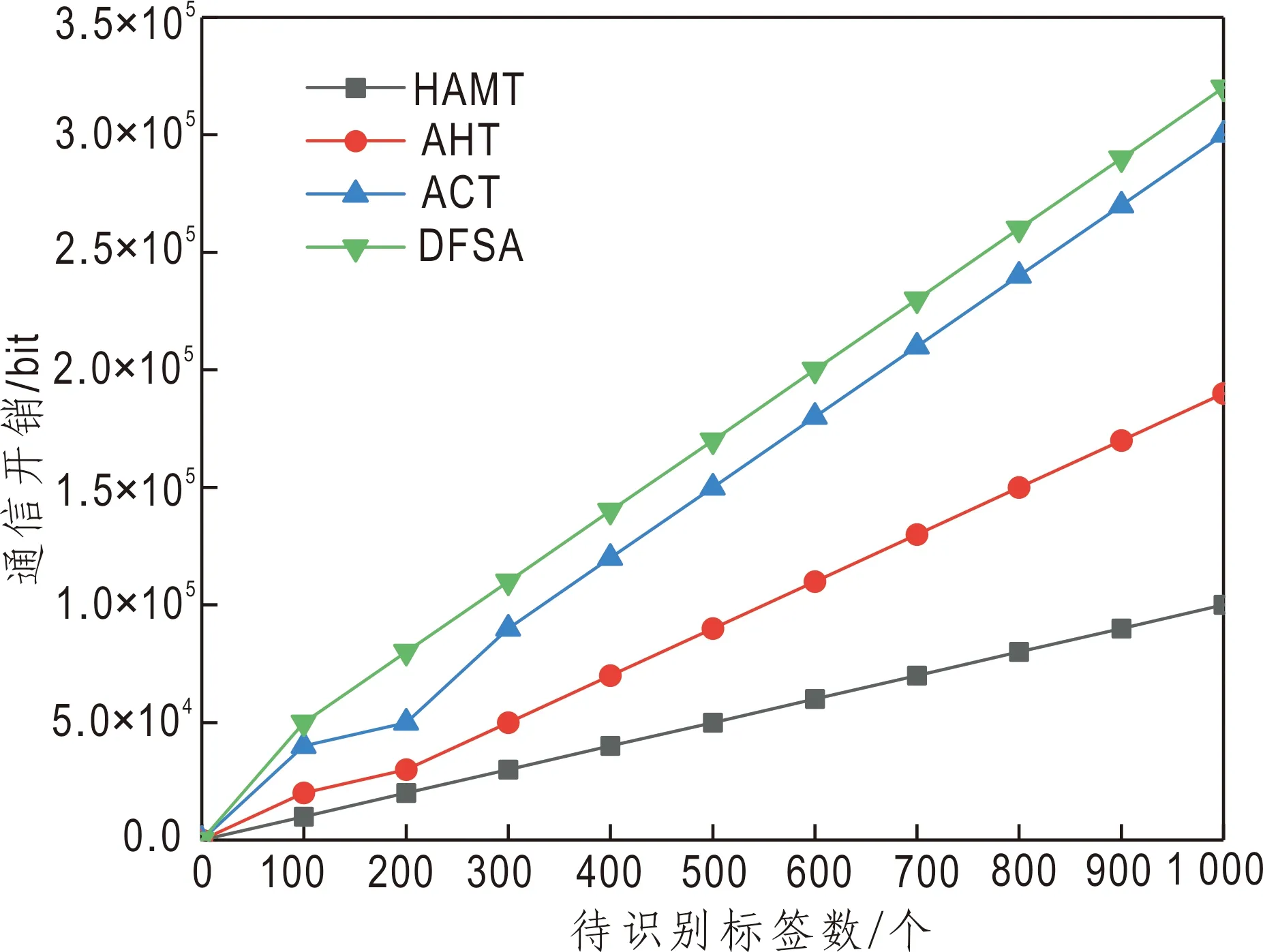
图5 不同算法通信开销Fig.5 Communication costs of different algorithms
3 结论
针对二进树算法和ALOHA算法的不足,提出了一种ALOHA和多叉树的混合型(HAMT)算法。该算法融合了二进制算法和ALOHA算法的优点,实现标签100%识别,并且识别速度快。仿真实验表明,HAMT算法减少了所需总时隙数,减少了系统通信开销,提高了吞吐率,使吞吐率能够保持在0.72左右。因此HAMT算法可以解决RFID系统中多标签碰撞问题,可在物联网系统中推广使用。
猜你喜欢
数字技术与应用(2022年7期)2022-08-03
英语世界(2020年10期)2020-11-06
中学生数理化·七年级数学人教版(2020年4期)2020-08-10
电脑报(2020年18期)2020-06-30
舰船电子对抗(2020年2期)2020-06-23
英语世界(2020年2期)2020-03-08
数学大王·低年级(2019年10期)2019-11-25
科学与技术(2018年23期)2018-06-17
山东工业技术(2016年5期)2016-03-04
电脑爱好者(2015年14期)2015-09-10
