
基于内容特征提取的短波红外-可见光人脸识别
2021-03-23 15:45胡麟苗楼晨风
光学精密工程 2021年1期
胡麟苗,张 湧,楼晨风
(1.中国科学院上海技术物理研究所,上海200083;2.中国科学院红外探测与成像技术重点实验室,上海200083;3.中国科学院大学,北京100049)
1 引 言
人脸识别自被提出以来就是计算机视觉研究的重点,近年来,随着深度学习的发展,基于可见光人脸图像的识别准确率得到了很大提高。目前的可见光人脸识别算法在公开的可见光人脸数据集(如LFW,MegaFace)上可以达到高于99%的准确率,这得益于不断发展的人脸识别算法、不断提升的计算能力和可以广泛获取的可见光人脸图像。但是,在实际应用中,可见光成像系统受环境干扰较为严重,在雾天、夜晚等环境成像质量较差,对人脸识别性能影响较大。为了解决可见光成像受干扰问题,在暗光条件下可以成像的短波红外成像系统成为另一个重要的图像来源。
短波红外是肉眼不可见的红外辐射波段之一,它属于主动成像波段,需要光源对成像目标进行照明,依靠物体表面反射的短波红外辐射进行成像,对雾、霭、烟尘等均有较好的穿透能力[1-2]。自然界中的大气辉光、星光和月光等均可作为短波红外的光源,其中大气辉光为主要自然光源,具有照射均匀的优点。作为对比,近红外成像系统主要的自然光源为月光,受月相、地月角度影响较大,容易产生方向性的阴影[3]。短波红外成像系统和近红外成像系统均可依靠主动式的人工光源进行成像,但短波红外人工光源具有更好的不可见性[4],配合短波红外成像系统可以有效增强安防监控系统的隐蔽性。
短波红外的波段特性使得其可用于夜间成像,但也正因为其与可见光不同的光谱特性,它所成的图像与可见光图像有较大的模态差异。目前的人脸识别系统中注册图像多为可见光图像,在应用短波红外成像系统获取人脸图像后,需要将短波红外图像与可见光注册图像进行匹配,两者间的模态差异会对匹配造成干扰。由于短波图像与可见光模态差异较大,用于可见光人脸识别的算法如InsightFace[5]直接应用于短波红外-可见光人脸识别时表现不佳。已有的针对近红外-可见光人脸识别的算法如[6-7],采用可见光预训练、近红外精调网络来生成对应近红外、可见光人脸图像的方式克服模态差异。由于近红外-可见光间模态差异小于短波红外光-可见光间的模态差异,图像生成难度相对更小,可见光图像上的预训练可以弥补数据量不足的缺陷,得到较好的识别结果。
在短波红外-可见光人脸识别研究中,Bihn等[3]提出直接应用在可见光数据集上预训练的VGG-Face(Visual Geometry Group-Face)[8]作为特征提取器,采用网络输出的特征对短波红外图像进行识别。但短波红外由于更小的数据量与更大的模态差异,在可见光图像上训练出的特征提取网络并不能很好克服短波红外-可见光间模态差异带来的干扰,在短波红外-可见光人脸识别任务中该方法准确度难以令人满意。
要进行跨模态的短波红外-可见光人脸识别,核心问题是消除模态差异的干扰。一个解决思路是找到一个短波红外人脸图像和可见光人脸图像共同拥有且可以用于识别的特征。它必须是两个图像域图像共有的特征,且与图像包含的内容信息相关,与图像所属图像域无关。在图像翻译研究中,研究者提出的“内容特征”这一概念可以用于解决这一问题。
图像翻译是指在保留输入图像内容的前提下,将输入图像翻译为目标图像域的图像的过程。它是近年来深度学习尤其是生成对抗网络在计算机视觉领域的重要应用之一,常被用于风格迁移[9]、图像生成[10]、图像超分辨[11-12]、图像去噪[13]及场景变换[14]等多个方面。较早的图像翻译框架如Pix2Pix[15],CycleGAN(Cycle Genera⁃tive Adversarial Network)[16]等采用生成对抗网络对输入图像直接进行转换。而之后的研究如MUNIT(Multimodal Unsupervised Image-to-Im⁃age Translation)[17],DRIT(Diverse Image-to-Im⁃age Translation)[18]等提出了图像的内容特征、风格特征分离的新思想。它们认为图像的特征空间可以分为内容特征和风格特征两部分。图像的内容特征是指与图像内容信息相关的部分,包含图像中的具体物体及物体的整体结构等。风格信息是指图像中与图像域相关的部分,包含了图像的纹理信息等。可以将图像翻译过程分解为输入图像内容特征、风格特征的提取,目标图像域风格特征的获取以及基于输入内容特征和目标域风格特征的图像生成过程。部分研究者选择将注意力机制引入图像翻译[19-20],使网络可以对图像中的重要区域给予更多关注。
图像翻译方法中提出的“内容特征”符合跨模态人脸识别任务中用于消除模态差异的方法的要求。受此启发,本文提出了基于内容特征提取的短波红外-可见光人脸识别框架,将短波红外-可见光人脸识别问题分解为跨图像域内容特征提取和基于内容特征的识别两个子问题。在短波红外-可见光人脸数据集上对图像翻译网络进行训练,将图像翻译框架中的内容特征提取器从框架中分离,用于待识别图像内容特征的提取;采用内容特征识别网络将待识别图像的内容特征与可见光注册图像的内容特征进行匹配,从而克服模态差异完成短波红外-可见光人脸识别任务。
本文的主要贡献为:(1)提出基于内容特征提取的短波红外-可见光人脸识别方法,将图像翻译方法中的内容特征用于消除模态差异对短波红外-可见光图像识别的影响;(2)对图像翻译框架DRIT进行改进,提出域内内容一致性函数和跨域内容一致性函数,提升内容特征提取器对特征提取的准确性;(3)设计了基于内容特征的识别网络,完成了短波红外-可见光人脸图像的识别,在短波红外-可见光人脸图像数据集上达到88.86%的准确率。
2 基于内容特征提取的人脸识别网络
在跨图像域的短波红外-可见光人脸识别中,模态差异会对识别造成较大干扰,如图1所示,图中“F_X-X”指采用普通的特征提取网络对图像提取的识别特征。同一目标在不同图像域中的图像间的差异可能会大于不同目标间的差异,传统的分类方式很难克服这一干扰。

图1 短波红外-可见光人脸识别中模态差异带来的影响Fig.1 Visible-light face recognition and SWIR-VIS face recognition
为了解决短波红外-可见光人脸识别任务中模态差异的干扰问题,受图像翻译中内容特征特性的启发,本文将短波红外-可见光人脸识别问题分解为两个子问题:跨图像域内容特征的提取和基于内容特征的识别。
2.1 整体结构
基于内容特征提取的人脸识别框架由内容特征提取器和基于内容特征的识别网络两个子模块构成。如图2所示,(c)中的内容特征提取器由(a)和(b)中的训练得到。
内容特征提取器从训练好的图像翻译框架中固化得到。引入了内容特征、风格特征分离思想的图像翻译框架DRIT设置了多种机制来实现对内容特征的提取。在研究中发现,由DRIT得到的内容特征提取器对内容特征提取的准确性仍无法满足人脸识别任务的要求,因此我们对该网络进行改进,提出了域内内容一致性损失函数和跨域内容一致性损失函数,提升网络中内容特征提取器对内容特征提取的准确性。将改进的DRIT模型中的内容特征提取器作为最终用于识别网络的内容特征提取器,提升了识别的准确率。
内容特征提取过程完成了从不同图像域图像中提取属于同一空间的特征的目标,基于内容特征的识别类似于可见光人脸识别过程,由特征处理和分类两部分构成。本文设计了用于内容特征识别的网络,与内容特征提取器结合,构成了整体识别框架,完成了短波红外-可见光人脸识别任务。

图2 本文提出框架(a)图像翻译中的交换生成与重建;(b)图像翻译中的自身重建;(c)本文提出的短波红外-可见光人脸识别框架Fig.2 Proposed framework(a)feature exchange and reconstruction in image translation;(b)self-reconstruction in image translation;(c)proposed recognition framework
2.2 内容特征提取器
2.2.1 DRIT模型
DRIT模型为Lee等提出的无监督图像翻译模型,它在循环一致性的基础上引入了内容、风格特征分离思想。内容特征指图像中较为低层的特征,例如图像中的方向、边缘等信息,而风格特征则是图像中较为高层的信息,如图像的颜色、纹理等信息。
DRIT模型由内容特征编码器(ECA(*),ECB(*))、风格特征编码器(ESA(*),ESB(*))、生成器(GA,GB)、内容特征判别器及图像域判别器构成。内容特征编码器和风格特征编码器用于图像内容、风格特征的提取,在网络中,两个图像域的内容特征的最后几层共享参数,以保证从两个图像域获取的内容特征属于同一空间。同时还设置了内容特征判别器,用于判别输入的内容特征来自哪个图像域,内容特征提取器的优化目标之一就是使得判别器无法区分输入的内容特征来自哪个图像域。
在训练时,DRIT模型会将输入图像的内容特征与自身的风格特征组合进行生成(图2(b)),在理想情况下,生成的图像应与输入图像一致,以 图 像 域 A为 例 ,应 有 :aself-reconstruct=同时,DRIT会将同时输入的两幅分别属于不同图像域的图像的内容和风格特征重新组合,生成对应的翻译图像,并对两个翻译结果再次进行内容、风格的交换组合,得到跨域重建结果(图2(a)):

此时跨域重建结果与原始输入图像之间也存在约束:ainput=aaross-reconstruct,binput=baross-reconstruct。基于这些约束关系,DRIT模型将输入图像与自身重建图像、跨域重建图像的L1距离作为损失函数,保证了翻译结果与输入图像在内容上的相似性。
DRIT模型在猫狗变换等任务中取得了较好的结果,但在短波红外-可见光人脸图像数据集上,翻译结果与参考图像相似度较低。尤其在对识别影响较大的眼睛、鼻子等部位,输出结果与真实图像差距较大。本文采用预训练好的Facenet模型对DRIT的输出结果进行识别,识别准确率仅为22%。
本文对DRIT框架进行分析,认为造成这一问题的主要原因是DRIT模型提取的内容特征的准确性不足,与DRIT模型的结构相关。第一,该框架被设计用于无监督的图像翻译,更强调输出结果风格的准确性,框架中的内容特征判别器仅判断输入的特征是否属于同一特征空间,对内容特征与输入图像的相关性未做判断。第二,框架中设置的基于循环一致性的重建损失函数仅从图像层面判断重建结果的准确性,未对内容特征进行约束。在图像翻译过程中,除了内容特征提取器,生成器也会对生成结果造成影响,仅依靠生成图像与输入图像的相似性,很难对内容特征提取的准确性进行直接判断。这些问题导致框架对同一内容的不同图像域图像提取的内容特征并不一致,干扰了翻译的准确性,导致在识别框架中,内容特征提取器的跨模态优势不明显。
针对DRIT存在的问题,本文在原有框架的基础上设计、引入了两个新损失函数,以优化原模型存在的内容特征提取准确性不足的问题。它们均基于内容特征提取器获得的内容特征进行计算,更好地对内容特征提取器进行优化。
2.2.2 基于目标一致性的跨域内容一致性损失函数
针对DRIT目标一致性差的问题,本文引入了跨域内容一致性损失函数。在2.2.1节描述的DRIT的训练过程中,输入图像经过交换特征得到生成图像u,v,u,v分别由输入图像binput,ainput的内容特征生成(公式(1)),对u,v进行内容特征提取:


对于期望情况,此时获得的内容特征应与从输入图像提取的内容特征一致,即:计算输入图像与生成图像的内容特征间的L2距离,并将之作为跨域内容一致性损失函数,以引导生成器从包含相同内容特征的不同域图像中提取相同的内容特征,强化两个图像域中内容特征提取器的一致性:

2.2.3 基于循环一致性的域内内容特征一致性损失函数
DRIT模型在训练中使用原输入图像的内容特征和属性特征进行了自身重建,得到自身重建图像aself-reconstruct,bself-reconstruct,同时还使用从生成图像提取的内容特征与原属性特征进行了循环重建,得到了循环重建图像across-reconstruct,bcross-reconstruct。在这两个重建过程中,重建图像使用的内容特征也是来自于输入图像。那么,从重建图像提取内容特征,也应与输入图像的内容特征一致:
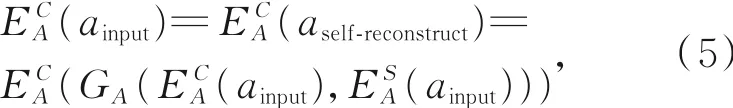

输入图像binput以及对应的重建图像与式(5)和式(6)类似。
两类重建图像均与输入图像属于同一图像域,内容特征提取由同一个内容特征提取器完成。本文使用对应域图像的内容提取器从重建图像与循环图像获取内容特征,并分别计算它们与输入图像内容特征的L2距离,作为域内内容特征一致性损失函数。该损失函数形式如式(7)所示:

通过设置域内内容特征一致性损失函数,我们强化了内容特征提取器对属于同一图像域且含有相同内容特征的图像进行特征提取时内容特征的一致性,
改进的DRIT模型的损失函数为DRIT模型的损失函数与新增损失函数的和:

2.3 基于内容特征的跨域识别网络
人脸识别通常包含图像预处理、特征提取、特征分类几部分。特征提取和分类多由深度神经网络完成。可见光人脸识别网络如Facenet、SphereFace和InsightFace等主要对损失函数进行优化,提出的损失函数如triplet loss(Facenet),ArcFace loss(InsightFace)等在可见光人脸识别任务中取得较好结果,其中ArcFace loss应用较广、效果较好。
经过内容特征提取后,两个图像域的图像被映射为属于同一特征空间的内容特征,此时的识别任务与可见光人脸识别类似,可由特征处理网络和分类部分完成。针对提取后的内容特征,本文设计了跨域识别网络,用于对内容特征进行进一步提取以及分类。
2.3.1 特征处理网络
人脸识别任务中,特征处理网络多以残差结构作为基本单元,通过多个单元的堆叠构成。文献[5]中提出了改进的残差单元,在可见光人脸识别任务中获得较好结果。
卷积神经网络中,常用的激活函数如ReLU等会给出一个稀疏的输出,Wu等[21]提出了MFM(Max-Feature-Map)激活函数层,可以进行特征选择并输出更为紧实的特征。
在本文提出的方案中,内容特征通道数为256,本文设置的特征处理网络去除了较浅的单元,由15个深度为256、3个深度为512的改进的残差单元组成特征处理网络,且采用MFM作为激活函数。
2.3.2 分类损失函数
虽然可见光识别算法中提出的损失函数在短波红外-可见光人脸识别中直接应用时效果不佳,使用InsightFace网络直接进行短波红外-可见光人脸识别时准确率仅为64.97%,但在使用内容特征提取器将不同域图像翻译到同一特征空间后,ArcFace loss成为识别任务较好的选择,因此本文提出的框架将ArcFace loss作为基于内容特征的识别网络中的损失函数。
ArcFace loss是对分类任务中经典的Soft⁃max的改进。它在角度空间对分类损失进行优化,达到加大类间距离、减小类内距离的效果,在可见光人脸识别任务中取得了优秀的结果。Softmax分类器中Softmax层的输入为最后一个全连接层的输出WTX+b,W,X,b分别为权值向量、特征向量和偏置值。将偏置值置零,对网络最后一层全连接层的特征与权重均进行L2归一化,再计算两者的点积,将点积值视为权重向量与特征向量的余弦值,使用反余弦函数解得权重向量与当前特征向量的角度值θ=arccos(WTX),在当前角度上加预设的角度间隔(Angular margin)m,使用余弦函数得到增加了角度间隔的余弦值cos(θ+m),将余弦值乘以放大尺度s后再进行Softmax计算,最终得到ArcFace损失函数:
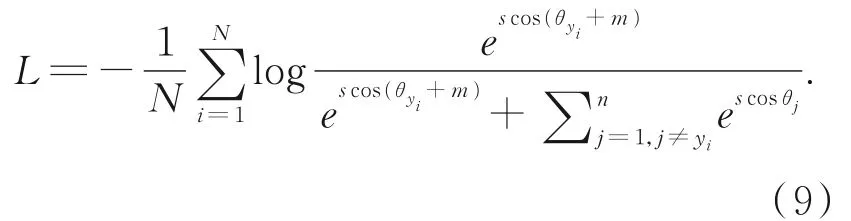
3 实验与分析
3.1 数据集
根据调研,目前还没有公开可获取的短波红外-可见光人脸数据集,因此本文采集短波红外与可见光人脸图像并建立数据集。可见光人脸图像采集设备为尼康的D5600单反相机,短波红外人脸图像的采集设备为Xenics公司的Bob⁃cat320短波相机。Bobcat320为一款采用InGaAs传感器的短波红外相机,可以采集波长范围为0.9~1.7μm的短波红外辐射。采集中,两台相机均设置为视频模式,单反相机采集分辨率为1 920×1 080的视频数据,Bobcat320相机采集分辨率为320×256的视频数据,采集过程中保证被采集对象头部位于画面中心位置。
数据集共包含207个目标,其中男性目标123,女性84。采集条件为半受控环境,在固定光照、距离下采集了目标不同角度、表情下的短波红外与可见光图像(如图3所示)。对采集的图像数据进行了眼部标注,并根据眼部位置进行了裁剪与对齐。
在实验中,随机选取不同性别各16个目标作为测试集,将剩余目标作为训练集,每个目标随机选取了7~10对图像构成训练集,实际训练集包含1 500张短波图像和1 500张可见光图像,测试集则包含745张短波红外图像和745张可见光人脸图像。

图3 短波红外-可见光数据集图像示例.第一行为短波红外图像,第二行为对应的可见光人脸图像Fig.3 Examples of self-built SWIR-VIS face image dataset,the first row shows SWIR face images and the second row shows the corresponding VIS face images
3.2 实验设置
实验平台为搭载英特尔8700k处理器及单张英伟达RTX2080Ti显卡的计算机,在自建短波红外-可见光人脸数据集的训练集上对模型进行训练、调试参数,在测试集上对模型性能进行评估,保证训练集与测试集数据没有重合部分。
3.2.2 参数设置
本文提出的改进的DRIT模型在原DRIT模型的基础上增加了新的损失函数,为了验证所提改进的效果,以DRIT模型为基准,在实验中原DRIT部分参数按文献[18]设置,调节本文提出的两个新损失函数的权重来验证本文所提改进的有效性并获取最优参数设置。之后,使用测试集图像进行短波红外-可见光的人脸图像翻译任务的验证,与其他图像翻译框架的表现进行对比。在实验中发现,在将跨域内容一致性损失函数的权重设置为5.5,域内内容一致性损失函数的权重设置为5时,训练得到的内容特征提取器在识别任务中取得最好结果。
对于基于内容特征的跨域识别网络,将公式(9)中的角度余裕m设置为0.5。受实验硬件条件限制,将batch大小设置为32,对网络进行训练,学习率初始设置为0.000 1,在不同阶段依次减小为0.000 05,0.000 01,0.000 001。
3.3 结果评估
对图像翻译模型DRIT,本文对其的改进主要是为了获取更高质量的内容特征提取器,在识别中更为准确地提取内容特征。提升内容特征提取的准确性,图像翻译结果与真实图像的相似性也应随之提升。因此,采用主观观察与客观识别的方式对改进的DRIT模型的翻译结果进行评估。在测试集上,采用训练好的改进的DRIT模型对短波红外图像进行图像翻译,观察其与真实参考图像的相似度。同时,采用在可见光图像上预训练好的Facenet[22]网络对模型输出的结果进行识别,以识别准确率来评估模型对内容特征提取的准确性。Facenet模型为Schroff等提出的基于深度神经网络的人脸识别模型,在实验中应用在LFW数据集上识别精度达到99.65%的预训练模型作为识别模型,对本文所提改进的DRIT模型和对比框架的翻译结果进行识别。
人脸识别任务通常可以分为两类:(1)身份识别:已有参考图像数据集,识别采集到的图像中目标的身份;(2)身份验证:给定一张参考图像和一张待判断图像,判断两幅图像中的目标是否为同一目标。本文所提框架的预期应用场景为暗光条件下的安防、监控场景,在该场景下,人脸识别需要面对的主要是第一类问题即识别问题,需要从已有可见光图像数据集中找到与待判定短波红外图像相符的目标。对该类问题,通常采用Rank-1准确率作为判断指标。Rank-1准确率即识别算法对输入的待检测图像进行识别,将概率最高的1个结果作为识别结果时,算法识别正确的概率。在实验中,算法均仅在训练集进行训练,在测试集上进行识别测试。
严肃党内政治生活是加强党的自身建设的基础性工作,要把我们党建设成为始终走在时代前列、人民衷心拥护、勇于自我革命、经得起各种风浪考验、朝气蓬勃的马克思主义执政党,就必须把严肃党内政治生活这一基础性工作做好。习近平同志站在保持党的马克思主义政党性质、更好担负历史使命、全面加强自身建设和形成良好党内政治生态的战略高度,对严肃党内政治生活的应有作用给予充分肯定。
3.4 对比算法
3.4.1 短波红外-可见光人脸图像翻译
作为对比,以DRIT为基准参考模型测试图像翻译结果,同时选取较为常见的图像翻译框架CycleGAN[16],MUNIT[17],UGATIT(Unsuper⁃vised Generative Attentional Image-to-Image Translation)[20]作为图像翻译效果的对比算法。
CycleGAN:首创性地引入循环一致性思想,使得无成对图像的图像翻译成为可能,且在相应数据集上取得了较好结果;
MUNIT:采用了内容与特征分离的思想进行图像翻译,与DRIT模型的区别主要在内容特征与风格特征结合的方式上以及循环一致性的实现方式;
UGATIT:在CycleGAN的基础上增加了新的注意力机制与正则化方法,提升了图像翻译效果。
3.4.2 短波红外-可见光人脸图像识别
针对短波红外-可见光人脸识别的相关研究较少,本文将针对该问题的在基于可见光预训练的VGG-Face方法、可见光人脸识别方法Insight⁃Face以及针对近红外-可见光人脸识别的DVG方法作为对比算法。
基于可见光预训练的短波红外-可见光人脸识别方法:Bihn等[3]提出,短波红外人脸图像与可见光人脸图像虽然有模态差距,但通过深度卷积网络可以从可见光图像中学习人脸结构信息,用于短波红外人脸图像的识别。该方案采用VGG-Face网络在可见光人脸图像数据集上进行训练,训练完成后,使用网络对短波图像进行特征提取,采用全连接层“fc7”输出的4 096维的特征向量作为识别特征,通过计算特征间距离判断两幅图像是否属于同一类别。
InsighFace:InsightFace为Deng等人提出的可见光人脸识别方法,提出了ArcFace和改进的残差单元,在可见光识别任务中得到较好的识别准确率。
DVG:DVG方法是基于图像翻译的另一种方法。该方法首先采用成对的近红外和可见光图像对生成器进行训练,之后采用训练好的生成器生成大规模、成对的近红外和可见光图像,与真实的近红外、可见光图像共同用于识别网络的训练,采用最终训练完成的网络完成识别任务。
本文在短波红外-可见光人脸图像数据集的训练集上对各对比算法进行训练,在测试集上测试各方法的识别Rank-1准确率,与本文提出的方法进行对比。
3.5 实验结果与分析
3.5.1 改进的DRIT模型内容特征提取
本文提出的对DRIT模型的改进的主要目的是使内容特征提取器可以更准确地提取内容特征。若内容特征提取的准确性增加,图像翻译框架翻译结果也会得到提升,本文首先对改进的DRIT模型图像翻译的结果进行评估,间接评估内容特征提取的准确性。
在相同训练集上对经典的无监督图像翻译框架CycleGAN,MUNIT模型、DRIT模型和UGATIT模型进行训练,并在相同的测试集上进行图像翻译,对翻译结果进行观察,得到主观性能判断。采用Facenet模型对翻译结果进行识别,将本文提出的改进的DRIT模型的结果与之进行对比。

图4 不同框架图像翻译结果对比,从左到右依次为:短波图像,MUNIT,CycleGAN,UGATIT,DRIT,改进的DRIT框架,参考图像Fig.4 Comparison of the images translated by different frameworks,the columns from left to right are:SWIR,MUNIT,CycleGAN,UGATIT,DRIT,the proposed improved DRIT and refer⁃ence images
图4 为图像翻译结果对比,可以看到,MU⁃NIT框架的结果仅大致轮廓与输入、参考图像相似,在细节上有很多模糊,对观察干扰严重;Cy⁃cleGAN模型翻译结果在大致结构上与参考图像相似,部分图像眼部周围存在失真情况,且整体皮肤色调与参考图像差异较大,对识别算法容易造成干扰;UGATIT模型结果上高频波纹较少,图像整体观感与可见光图像接近,但存在器官与输入图像不相符的情况,且在头部有一定偏转角度时,翻译结果失真较为严重;DRIT模型画面整体模糊,在轮廓、细节等方面均存在波纹现象;本文提出的改进的DRIT模型翻译结果与参考图像相似度较高,且在头部有一定偏转情况下依然有相对较好的表现(如图4倒数第2行所示)。
当头部偏转角度较大(水平或俯仰偏转大于20°)时,改进的DRIT模型存在翻译失真较大的情况。该现象的产生主要是因为训练数据以脸部正面图像为主(约占总训练集的91%),网络难以学习偏转较大时的映射信息。
对图像翻译框架输出图像的Facenet识别结果如表1所示,其中Real指使用预训练的模型对本数据集测试集中可见光图像进行识别的表现,其余结果均为Facenet网络对图像翻译结果进行测试的结果。改进的DRIT模型(DRITadv)翻译结果在Facenet算法下的准确率为27.6%,相对原DRIT模型提升5.4%,也优于对比的CycleGAN模型、MUNIT模型及UGATIT模型。

表1 图像翻译结果对比Tab.1 Results comparison of image translation
本文提出的改进的DRIT模型相对于原DRIT图像翻译质量有较大提升,翻译结果的可识别性增强,说明本文所做的改进可以使得网络更为准确地获取图像的内容特征,也提升了图像翻译的质量。
3.5.2 短波红外-可见光人脸图像识别
内容特征提取器与基于内容特征的识别网络相结合,构成了本文提出的短波红外-可见光人脸识别框架。在完成改进的DRIT模型的训练后,固化其中的内容特征编码器,将图像内容特征输入基于内容特征的识别网络进行识别。
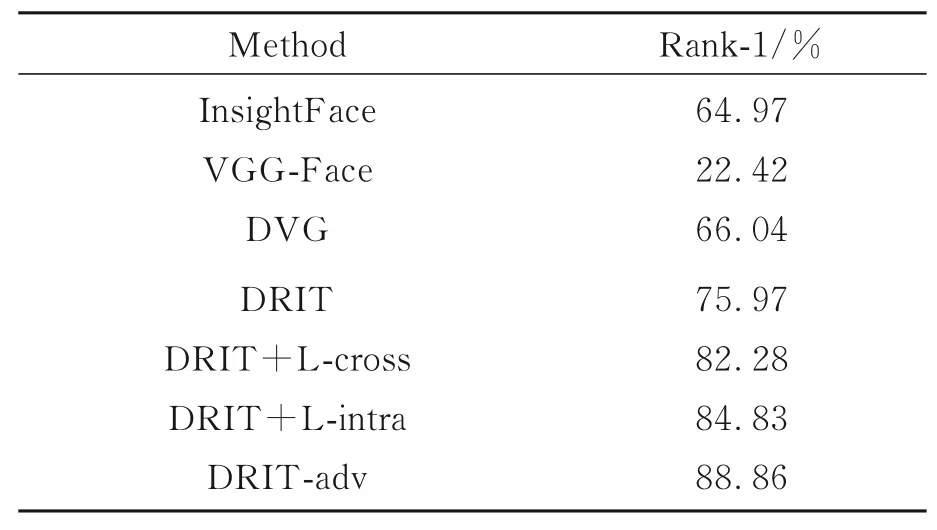
表2 短波红外-可见光数据集识别结果Tab.2 Recognition results on SWIR-VIS dataset
在自建短波-可见光人脸数据集上,跨模态人脸识别实验结果如表2所示。采用预训练的VGG-Face进行特征提取识别的Rank-1准确率仅为22.42%,与可见光人脸识别算法对图像翻译结果进行识别的准确率相当。DVG框架中训练得到的识别网络在测试集上的识别准确率为66.04%。采用原DRIT模型内容特征编码器提取内容特征的Rank-1准确率为75.97%,优于将图像翻译结果直接用于识别的方案,也优于Bihn等提出的基于VGG-Face的方法和DVG方案。在仅应用跨域内容一致性损失函数时(DRIT+L-cross),模型的Rank-1准确率提高了6.31%;在仅应用域内内容一致性损失函数时(DRIT+L-intra),模型的Rank-1准确率相较于改进前提升了8.86%;当采用本文改进得到的图像内容特征提取器时(DRIT-adv),模型的Rank-1准确率达到88.86%。
本文提出的基于内容特征提取的方案有效地消除了模态差异对识别的干扰,构建的基于内容特征的识别网络可以依据内容特征完成短波红外-可见光人脸识别。而本文对DRIT模型做出的改进在单独应用(DRIT+Lcross,DRIT+L-intra)与联合应用(DRIT-adv)时均有效提升了内容特征提取器对图像内容特征提取的准确性,提高了整体识别框架识别的准确率。
4 结 论
本文提出了基于内容特征提取的短波红外-可见光人脸图像识别框架。将短波-可见光人脸识别问题分解为内容特征提取和基于内容特征的识别两个子问题进行处理,以克服光谱特性差异带来的图像模态差异的干扰。提出将无监督图像翻译框架提取的内容特征用于减小图像的跨模态差距并对跨模态图像翻译框架DRIT进行了改进,通过增加域内内容一致性损失函数和跨域内容一致性损失函数提升了内容特征提取的准确性。设计了基于内容特征的特征处理、识别网络,根据内容特征设置网络结构,与内容特征提取器共同构成了具有较高识别率的短波红外-可见光人脸识别框架。在自建短波红外-可见光人脸数据集上进行测试,达到88.86%的识别准确率。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年31期)2020-06-01
电子制作(2019年14期)2019-08-20
动漫星空(2018年9期)2018-10-26
人民音乐(2016年1期)2016-11-07
时代风采(2016年12期)2016-07-21
时代风采(2016年10期)2016-07-21
林业与生态(2016年3期)2016-02-27
