
基于聚类和关键词提取的软件缺陷分析方法
2021-03-23 09:39:02高俊婷张丽萍赵凤荣
计算机工程与设计 2021年3期
高俊婷,张丽萍,赵凤荣
(内蒙古师范大学 计算机科学技术学院,内蒙古 呼和浩特 010022)
0 引 言
软件缺陷[1-3]通常以缺陷报告的形式存储在缺陷跟踪系统中[4],因此缺陷分析首要工作是对缺陷报告进行分析。缺陷报告数据量大、信息繁杂,修复缺陷耗时长成本高,传统的人工分析已经无法满足大规模的软件缺陷修复需求。
本文提出一种基于K-Means和主题模型的软件缺陷分析方法DAKSM(defect analysis method based on K-Means and subject model)。该方法将聚类和关键词提取共同应用于软件缺陷分析中,在聚类过程中加入无用词和同义词分析并引入粒子群算法,提高聚类准确率。在关键词提取部分加入通用关键词分析,提高关键词的针对性,最终将缺陷的类型和潜在表达内容直观地呈现给修复人员。由于目前缺陷追踪系统大多为英文版本,因此缺陷报告大部分为英文,该方法只适用于英文缺陷报告分析。若需要分析中文缺陷报告,则需在本文方法基础上将英文文本分析算法改进为中文文本分析算法,使之适应中文缺陷报告分析。实验结果表明,该方法在英文缺陷报告的聚类平均准确率能达到81%。
1 相关工作
缺陷分析是对软件开发过程中产生的缺陷信息进行分类和理解[5],将缺陷相关信息提供给修复人员和开发人员,使修复人员更快速地解决缺陷,了解缺陷产生的原因以避免此类缺陷再次产生。缺陷分析范围广泛、方法众多,现有缺陷分析主要分为人工分析方法和自动分析方法。
人工分析方法是通过开发人员的经验对缺陷报告进行分析,主要分为单属性、多属性分析[6,7]、定性和定量4种分析方法。定性分析主要有根本原因分析法(root cause analysis,RCA)、缺陷注入-发现矩阵分析法(DRE/DRM)、软件故障树分析法(software fault tree analysis,SFTA)、缺陷消除模型分析(defect removal model analysis,DRM)等方法;定量分析方法主要有(orthogonal defect classification,ODC)[8]和异常分类标准IEEE[9]等。
由于软件规模和数量的增大,人工分析过于耗费资源,于是研究人员致力于寻找软件缺陷自动分析方法。LiGuo Huang等提出一种自动ODC分类方法[8],对每一个缺陷类别建立一个支持向量机(support vector machine,SVM)分类器。该方法虽然最终分类结果比较好,但是由于只分析了某公司社交网络,导致结论通用性和代表性较低。
Thung等提出了一种缺陷自动分类框架和分类标准[10],获取源代码和缺陷报告,将源代码转换成抽象语法树(abstract syntax tree,AST),然后用SVM对文本特征和修改特征进行分类。该方法分类粒度较粗,且只分析500个缺陷,数据量较少。
夏鑫等更注重缺陷的触发方式,他们提出了基于触发方式的缺陷自动分类模型[11]。该方法将模糊逻辑作为特征提取方法,使分类效果更加准确,但该方法只将缺陷分为2个类型,对开发人员理解缺陷的帮助有限,还需开发人员进一步分析理解缺陷。
昆明理工大学的王延飞认为由于软件是给客户使用的[12],所以软件的一部分缺陷是用户提出的,并且软件缺陷描述大部分存在于软件的负面评论中,所以使用情感倾向分析方法重点分析软件评论。但评论包含无用信息较多,仅分析评论不具代表性。
大连理工大学的刘文杰等重点分析缺陷的严重性[13],分别组合并对比了不同特征表示方法和特征选择方法以及不同分类算法,最终得出各部分最优方式,但并未提出最优组合方式。
Indu Chawla等运用模糊逻辑的分类方法,将缺陷分为bug、特性增强和其它请求[14],实验验证该方法优于Pingclasai方法。但该方法收集到的原始数据集质量不高,严重影响分类性能。
另外,本团队的刘树毅等在缺陷预测方向提出了一种融合多策略特征筛选的跨项目软件缺陷预测方法[15]。该方法首先使用多策略筛选方法与过采样方法进行数据预处理;然后利用代价敏感的域自适应方法进行分类。该方法可以较好进行软件缺陷预测,不足之处在于对属性数量改变所带来分类性能突变估计不足,可能会导致计算资源的浪费、跨项目失效问题。
综上所述,大多数自动分析方法都要依据经验先制定分类标准,将缺陷进行人工标注,然后提取特征并用机器学习方法将缺陷进行分类,但是这种方法将经验与数据分离,分类鲁棒性较低;在提取特征方面考虑信息单一,没有考虑冗余特征和特征之间的位置关系;另外还需人工标注,消耗资源,最终分类后的信息有限。因此,本文针对这一问题,使用聚类和关键词提取的方法分析软件缺陷,将缺陷类型和潜在信息提供给修复人员,使缺陷可理解性更强,帮助修复人员更快速地了解缺陷并能更好地解决缺陷。
2 基于K-Means和主题模型的缺陷分析方法
2.1 研究框架
本文从数据角度出发提出一种软件缺陷自动分析的方法,即基于K-Means和主题模型的缺陷分析方法DAKSM。DAKSM流程如图1所示。

图1 DAKSM流程
该方法分为2个阶段:聚类和关键词提取。在聚类阶段,首先输入缺陷报告,然后对缺陷报告预处理,得到清洗后的缺陷报告文本。接下来对特征进行筛选和处理,获取缺陷有效特征,然后进行文本表示和权重计算,最后进行聚类,输出缺陷类型。在关键词提取阶段,将聚类后的缺陷类型作为输入,先提取主题词,然后过滤主题词,最后再一次提取主题词,将缺陷类型和该类型主题词作为关键词输出。
2.2 聚 类
大部分的缺陷分析方法要先确定缺陷的类型,而当前的缺陷类型都是对已有缺陷的总结和积累。由于缺陷的产生原因和形式是多样的,这种基于经验的方法并不能良好地适应缺陷的多样性。本文从缺陷报告的数据自身出发,采用聚类的方法科学地将缺陷划分为几个类型,聚类过程如图2所示。
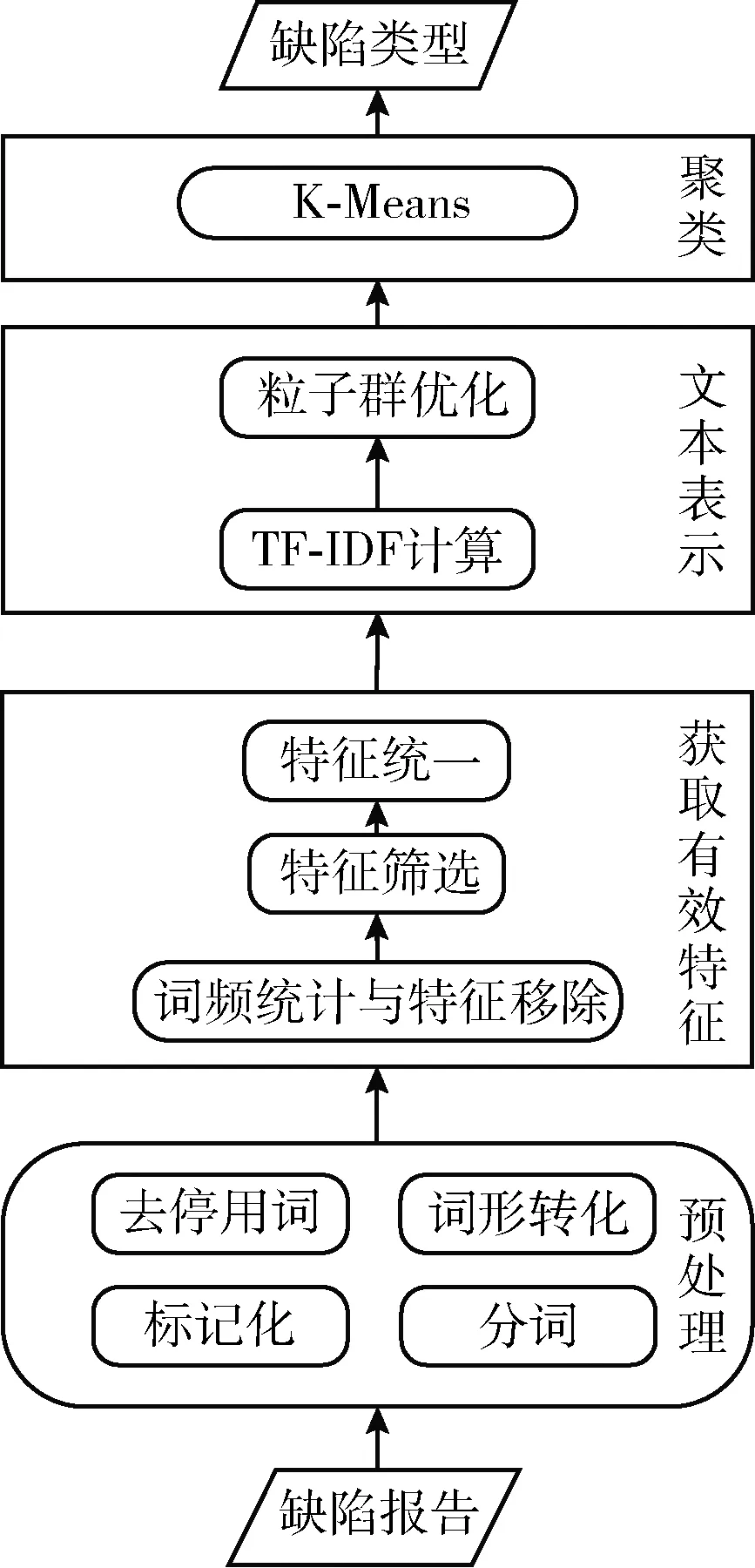
图2 聚类流程
本文将缺陷报告作为输入,选取摘要、详细描述和评论作为分析对象。首先对缺陷报告进行预处理,包括标记化、分词、去停用词和词形转化;接着使用词频统计、特征筛选和特征统一的方法来获取有效特征;下一步进行文本表示、TF-IDF计算权重值和粒子群算法优化权重值;最后用K-Means方法聚类,输出缺陷类型。聚类实现方法如算法1所示。
算法1: 聚类算法
Input: 缺陷报告xml文件
Output: 聚类后结果
(1)str=file.readline();//按行读取文件
(2)Whilestr=file.readline()!=nulldo
(3)Ifstr=="
提取bug_id,comment,thetext中的信息。
(4)str.toLowerCase();//转成小写
(5)str.remove("’");//去掉单引号。
(6)IfWords.count<=3Then
(7)str.remove(Words);//移除词频小于3的单词。
(8)Endif
(9)str.remove(Uselesswords);//去除无用词
(10)Fori=0:Synonym.length-1to
(11)Forj=0:Synonym[i].length-1to
(12)str.replace(Synonym[i][j],Synonym[i][0];)//
一组同义词都被替换为该组第一个单词。
(13)Endfor
(14)Endfor
(15)bug=bug+str+" ";
(16)Endif
(17)Endwhile
(18)fori=0:bug.length-1do
(19)bug[i].weight=w_TFIDF[i]*w_PSO[i];//计算每个特征的权重值
(20)Endfor
(21)Clustering=SimpleKMeans(bug);//K-Means取类后的结果
(22)returnClustering;
2.2.1 预处理
首先,获取缺陷报告,提取缺陷报告中的id号(
2.2.2 获取有效特征
接下来进入特征提取阶段。由于被处理的缺陷数据是多样的语言文本形式,所以会出现大量单词。为防止在文本表示时造成维度爆炸,本文在聚类之前对单词进行有效特征提取。提取有效特征也会降低聚类复杂度,提高聚类准确率。该阶段主要对单词特征进行处理,目的是提取对缺陷聚类而言有用处的单词。
(1)词频统计和特征移除
根据对数据的分析发现词频小于3的大多数为拼写错误或对缺陷无用的单词。因此,该方法首先要去掉出现频率小于3的单词,该方法可将特征维度缩减到原来的1/3。
(2)特征筛选
将特征移除后仍然有很多单词是经常出现但是对缺陷数据聚类而言没有作用的单词,特征筛选目的是过滤掉这些单词,本文将这些词称为无用词。首先分析出无用词,如yeah、nightly、hmm等单词可能是评论中掺杂的无用词;然后创建无用词列表,表1列举了部分无用词。在分析无用词的时候,我们使用人工分析的方法,考虑该单词的含义和作用,再考虑去掉该单词之后对整个语句的理解,如果不影响整句话含义,则设为无用词。通过对3款软件1500个缺陷的人工分析得到无用词列表。该列表含有web软件中大部分无用词。然后设计特征过滤算法,在特征移除后的特征子集上自动过滤掉无用词列表中的单词。实验表明使用经过特征过滤后的特征子集聚类效果好于未经过特征过滤的特征子集。
(3)特征统一
文档中可能出现实际意义相同但是表达不同的单词,例如:color可以被表达为red、blue和black等。这些单词虽然含义相同,但由于表达形式不同,所以它们在文档向量中是不同的。基于这个问题,本文提出一种针对软件缺陷聚类的特征统一处理方法,特征统一是指在软件缺陷聚类之前,将隐藏含义相同的单词统一成实际意义单词。这样做将降低特征维度,使聚类更准确。该方法首先分析出隐藏含义相同的单词,创建特征统一列表,部分特征统一见表2,将特征统一列表中的单词统一成实际意义单词。通过对3款软件1500个缺陷进行分析创建了特征统一表,该表包含大部分web软件应该统一含义的单词。然后设计特征统一算法自动将单词进行统一。实验结果表明,聚类前使用特征统一方法将提高聚类准确率。

表1 无用词

表2 特征统一
2.2.3 文本表示
文本表示是将计算机无法直接处理的无结构语言文本转化为可处理形式。向量空间模型(VSM)是一种文本表示模型。该模型由特征项、特征权重和特征向量组成[16]。使用该模型需要先确定文本的特征项和权重值,对于英文文本来说,一个词即为一个特征,因此本文选用单词作为VSM模型中的输入特征。
在权重计算方面,本文提出一种TF-IDF与粒子群相结合的权重计算方法。一般对于权重计算只选用TF-IDF、信息增益(IG)等方法,由于软件缺陷的特殊性,我们认为缺陷报告中摘要是缺陷的高度概括,所以将摘要设为重点分析部分,同时描述也是缺陷分析不可缺少的部分,评论集合了不同开发人员的多种角度对缺陷的描述。因此本文选用摘要、描述和评论作为分析对象。由于不同位置的特征提供的信息质量不同,所以需要根据单词存在位置的不同而设置不同的权重。为了分析不同位置与权重的关系,本文在权重计算上采用粒子群优化算法来计算特征在不同位置的最优权重。该方法对权重值的计算分为2步,首先通过TF-IDF计算出基本权重,然后再通过基于粒子群的特征权重算法计算出最终最优特征权重。特征权重计算公式为
wword(i)=wTF-IDF×wpso
(1)
wword(i)为第i个特征的权重;wTF-IDF为通过TF-IDF所计算出的权值;wpso为通过基于粒子群的特征权重算法计算过后的权重。
(1)TF-IDF(term frequency-inverse document frequency)
首先使用TF-IDF方法计算基本权重值,TF-IDF是一种常用的加权技术[17]。TF(term frequency)为词频,表示单词在文档中出现的频率,TF计算公式如下
(2)
ni,j是该词在文件中的出现次数,而∑knk,j则是在文件中所有字词的出现次数之和。IDF(inverse document frequency)为逆文本频率,主要思想为包含该词条的文档越少,IDF值越大,该词的区分度越高,IDF计算公式如下
(3)
其中,|D|为语料库中的文件总数,分子为包含词语的文件数目,如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用1+|{d∈D:t∈d}|作为分母。TF-IDF值为TF*IDF,本文的TF-IDF值由WEKA工具计算,WEKA是一款JAVA环境下开源的机器学习工具。本文使用StringToWordVector实现TF-IDF权重计算[18]。计算结果如图3所示。
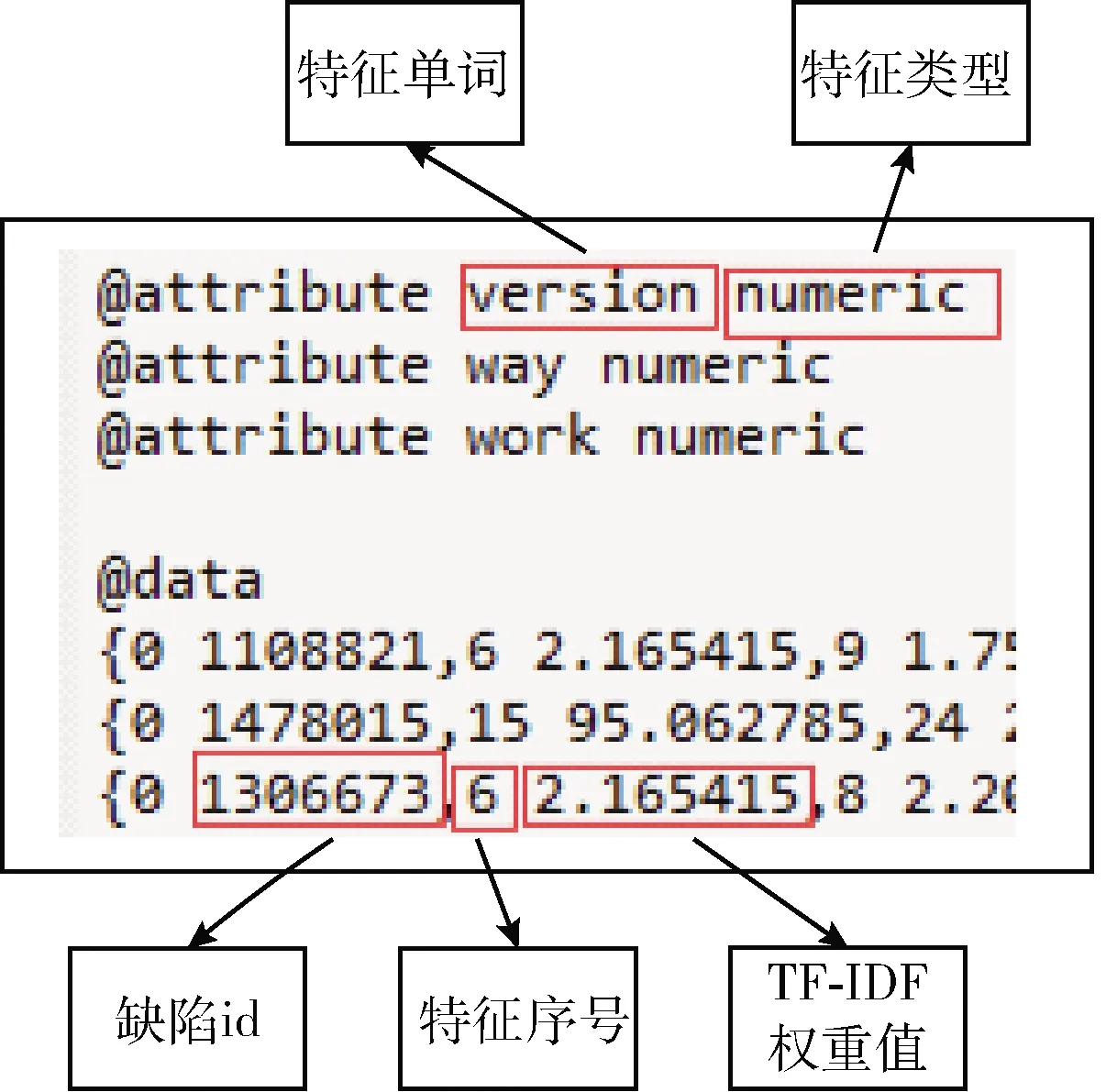
图3 TF-IDF计算结果
(2)基于粒子群算法的特征权重计算
粒子群算法是由J.Kennedy和R.Eberhart开发的一种生物启发式算法[19]。粒子群算法以其实现容易、精度高、收敛快等优点引起了学术界的重视[20,21]。利用粒子群算法可以有效地解决权重优化的问题。
在粒子群算法中,每一个单词在不同位置的权重值数组被抽象成一个粒子,由N个粒子组成一个种群。其中第i个粒子的位置被表示成一个D维的向量Xi=(xi1,xi2,…,xiD),i=1,2,…,N,并且它的速度也被表示成一个D维的向量Vi=(vi1,vi2,…,viD),i=1,2,…,N。所有粒子的适应值都由适应度函数计算得到,判断调整权重以后结果的好坏需要从两方面考虑:一方面是聚类的聚集程度,可以由K-Means算法的SquareError值得到,SquareError值越小分类的结果越好;另一方面是聚类的准确率,由正确分类的个数除以总个数得到,正确率越高分类效果越好。所以本文的适应度函数如下
(4)
其中,k1,k2为算法参数,s为聚类的SquareError值,a为聚类的准确率。此外,每个粒子还具有记忆功能,会记录当前搜索到的最优位置,称为个体极值pbest=(pi1,pi2,…,pgD),i=1,2,…,N,代表个体经验。此外,整个种群当前搜索到的最优位置称为全局极值gbest=(pi1,pi2,…,pgD),代表种群经验。每个粒子的速度更新由3部分组成:第一是惯性速度,代表粒子有维持自己之前速度的趋势;第二是认知速度,代表粒子有靠近个体最优位置的趋势;第三是社会速度,代表粒子有靠近群体最优位置的趋势。速度和位置更新公式如下
vid=ωvid+c1r1(pid-xid)+c2r2(pgd-xid)
(5)
xid=xid+vid
(6)
其中,ω是惯性权重,c1,c2是学习因子,r1和r2为[0,1]范围内的随机数。i=1,2,…,N为群体大小。粒子将会在目标搜索空间中追随当前的最优粒子在解空间中搜索。
惯性权重ω是影响算法性能的重要参数。文献[22]提出了一种惯性权重线性微分递减的方法,惯性权重的计算公式如下
(7)
(8)
由公式可以看出,在算法初期粒子的惯性权重较大,提高了粒子的全局搜索能力,保证粒子的多样性。而在算法后期粒子的惯性权重较小,提高了粒子的局部搜索能力,有利于找到最优解。该算法流程如图4所示。
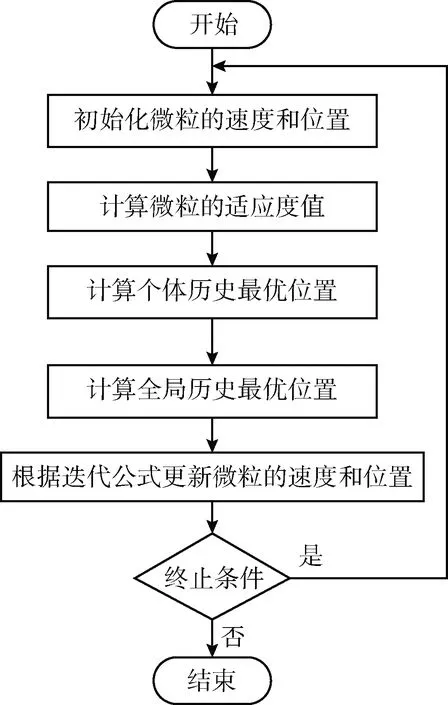
图4 粒子群算法流程
2.2.4 聚类
大部分缺陷分析方法都需要在训练模型前将缺陷手工分类,K-Means是一种无监督学习技术,可省去人工分类时间,但是该方法需要在聚类后人工分析聚类结果。分析发现,某些缺陷可被分到不同类别,相较于只能按照标签分类的方法,该方法灵活度较高。
在模型构建阶段,本文采用K-Means算法对缺陷进行聚类。K-Means算法是一种基于距离的聚类方法,该算法认为两个对象之间的欧氏距离越近,则它们相似度越大,且属于同一个类型的可能性也更大。算法首先需要设定K个簇中心点,随机选取中心点位置,然后计算对象与中心的距离,通过距离进行归类,接着重新计算距离,迭代2次-3次上述步骤,直到满足阈值或中心不再改变。
本文在实现K-Means算法时使用WEKA工具里的SimpleKMeans方法。图5为聚类结果部分示例。

图5 聚类结果部分示例
2.3 关键词提取方法
每一类缺陷里面还可能包含不同的主题,本节通过聚类结果,进一步提取主题与关键词。经实验发现,主题之间会出现许多相同关键词,这些词为缺陷通用关键词,例如firefox、bug和error等词,虽然是关键词,但由于单词概括性较强,区分度较差,实际分析意义不大,所以要在关键词提取之前将这些单词去掉。因此关键词提取分为关键词识别、关键词过滤和关键词再提取3个步骤。
2.3.1 关键词识别
在该阶段,本文使用主题模型中的(latent dirichlet allocation,LDA)提取出主题和主题词以及主题概率,将主题词作为该簇不同主题的关键词,以主题概率从高到低的顺序呈现给修复人员。LDA是一种无监督机器学习技术,用来生成文档主题,主要识别大规模文档集或语料库的隐藏主题信息[23]。该模型运用词袋模型,忽略词的排列顺序,将无结构的自然语言编写的文档信息转化为计算机可识别的模式。该模型包含词、主题和文档3层结构,对于一篇文档,首先通过LDA模型生成其主题分布与词分布,然后根据主题分布随机选取一个主题,再根据单词分布生成一个词,重复上述过程直至生成一篇文档。
本文将上一步经过K-Means聚类后的每一类设置成一个文件夹,将该类中的缺陷以一个缺陷一个文本的形式放入文件夹中,每个文本以缺陷id命名,内容为缺陷摘要、评论、描述的原始数据。将文件夹作为LDA输入,经过主题提取后得到每一类的主题以及该主题下的主题词和主题概率。
2.3.2 关键词过滤
分析发现,主题之间会出现许多概括性较强、区分度较差的单词,如firefox、bug和error等,这些词定义为通用关键词。在关键词过滤阶段主要过滤掉通用关键词,该过程首先比对上一步提取出的关键词,分析重复的单词;然后,设置通用关键词列表,表3为部分通用关键词列表;最后,在最原始数据集上去掉通用关键词,迭代提取和过滤过程直到分析出的结果比较符合要求。

表3 通用关键词
2.3.3 关键词再提取
经过关键词过滤后的文本中单词都具有高度识别性,因此,将去掉通用关键词后的数据集上再次提取关键词,提取结果以主题概率从高到低的顺序呈现给修复人员,帮助修复人员快速理解缺陷。
3 实验分析
3.1 验证指标
由于业界还未有类似方法,所以针对本文提出的基于聚类和关键词提取的缺陷分析方法 DAKSM进行组内评估验证,本文将从聚类准确的个数、准确率和评价聚类好坏的簇内误差平方和(SSE)这3个方面进行验证,以检验DAKSM方法的有效性。
准确率指经过分析后得出的聚类正确的缺陷数与全部缺陷数的比例。SSE值是K-Means聚类中常用的判断聚类好坏的标准。该值越小证明同一簇之间距离越小,聚类效果越好。该值由WEKA工具完成聚类时提供。
3.2 实验验证
3.2.1 数据源
Bugzilla是一个开源的缺陷管理系统,主要管理软件开发过程中存在的缺陷,许多软件公司使用bugzilla来进行缺陷管理,因此本文从bugzilla中下载缺陷报告进行分析。为了使研究更具有针对性,本文选用firefox、bugzilla和SeaMonke这3款web软件,并且为了保证实验的实用性,本文在每款软件中随机选取500个缺陷进行分析。
3.2.2 实验步骤
(1)在bugzilla中下载xml形式的缺陷报告,提取缺陷报告中的缺陷id、摘要、描述和评论。
(2)对提取出的文本进行预处理。
(3)将预处理过的文本提取有效特征。
(4)进行文本表示和权重计算,我们先用WEKA中的StringToWordVector将文本转换成空间向量,初步权值为TF-IDF,然后用基于粒子群算法的权重计算方法计算权重,其中粒子群算法的参数为:c1=1.49445,c2=1.49445,ωmax=0.8,ωmin=0.5,最大迭代次数为500次。
(5)用WEKA里面的SimpleKMeans实现K-Means聚类,欧氏距离作为算法的相似度测度,初始化方法选择k-Means++,最大迭代次数为500次,种子数为800,经过实验验证,将缺陷分为6个类别结果最准确,所以初始聚类的簇个数设置为6个。
(6)将聚类结果分别保存到不同的文件夹中,再用LDA提取出关键词,本文主题数设置为10个,每个主题下有20个主题词,根据经验将α和β分别设置为50/K和0.1,其中K为主题数,输出最终分析结果。
3.2.3 实验结果与分析
(1)聚类结果
1)不同获取有效特征方法的实验结果
获取有效特征:我们分别对比了未获取有效特征和使用该方法后的聚类效果:
方法1:只使用词频进行特征提取。
方法2:使用词频和特征筛选进行特征提取。
方法3:使用词频和特征统一获取有效特征。
方法4:使用词频、特征筛选和特征统一进行获取有效特征。
实验结果如图6所示,图6横坐标表示4种方法,纵坐标表示聚类正确的个数,不同的柱形代表不同的软件。
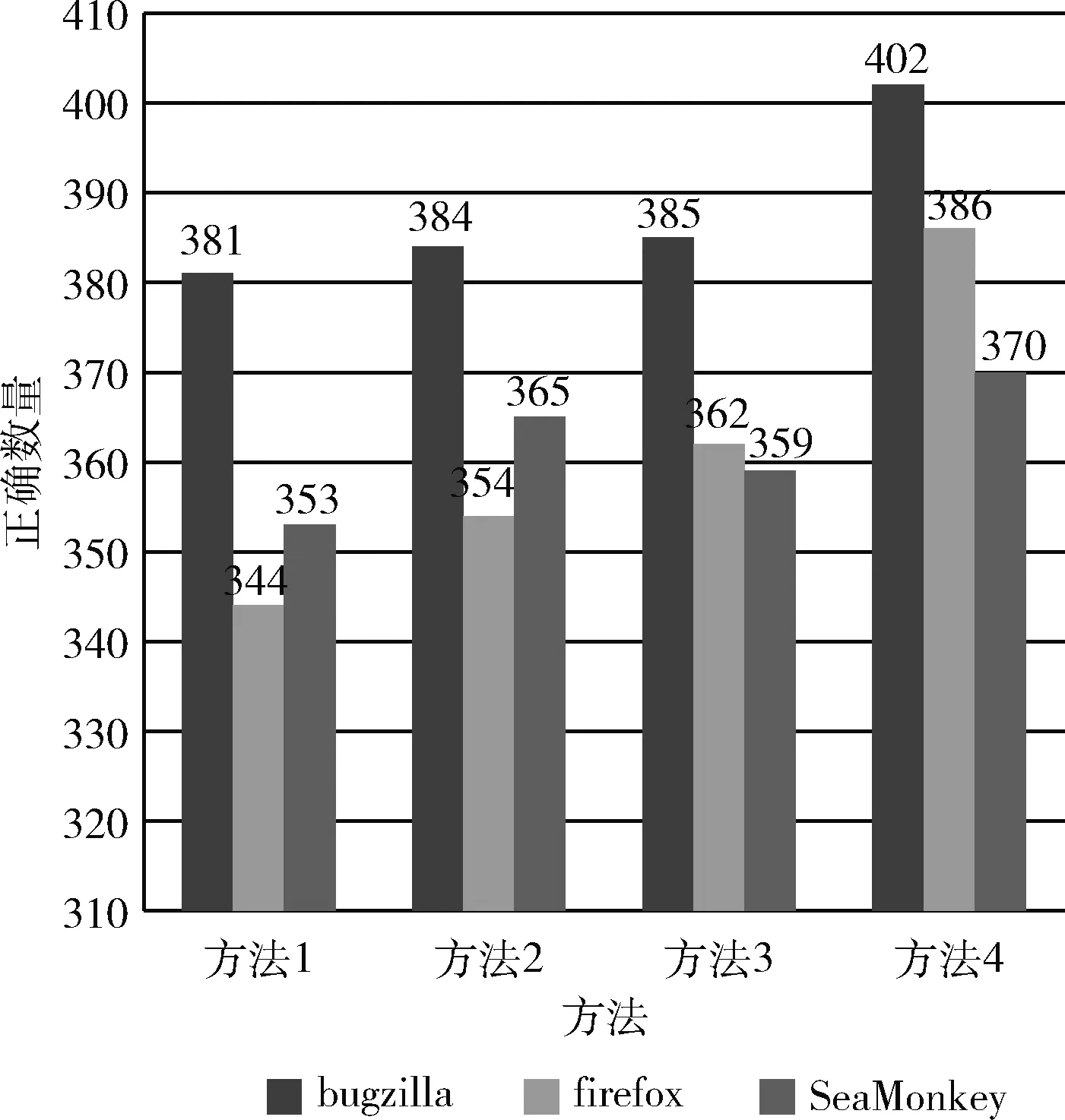
图6 不同获取有效特征方法聚类正确的数量
由图6可以看出:①bugzilla聚类时使用其它方法较方法1有小幅度提升,但使用方法2和方法3时差距不大,仅仅增加了1个;当使用方法4时准确个数有明显升高。②firefox对本文提出的方法较为敏感,准确个数提升较多。但firefox准确个数并不是很多,刚达到bugzilla使用方法3时的准确个数。③SeaMonkey软件在使用方法2时较方法1有明显提高,但是使用方法3反而降低了准确个数,但仍高于方法1,使用方法4优于方法1但与方法2差距不大。
由以上分析可以看出,方法2和方法3结果有较大起伏,但方法4对任何软件的准确个数都有较大的提升,总体来看本文提出的获取有效特征方法优于只使用词频的方法。
准确率如表4所示,方法2和方法3准确率都高于方法1,但是低于方法4,方法4有效提高准确率使准确率平均达到77.2%。该表看出使用方法1时firefox, SeaMonkey准确率较低,但bugzilla有良好的准确率,当使用方法4时准确率提高到了80.4%,因此bugzilla对方法4适应性比较好,准确率提升8.4%,SeaMonkey虽然使用方法1时准确率比firefox高,使用方法4后并没有太大的提升,反而比firefox准确率低,但通过平均准确率分析来看使用方法2和方法3差距不大,使用方法4相较于方法1有明显提高。表5表示不同方法不同软件的SSE值。由表4和表5综合来看,虽然bugzilla的SSE值最高,但是准确率却是最高的,firefox的SSE值最低,但是准确率也是最低的。因为SSE为WEKA工具中计算出来的簇之间实例距离,但是在实际语言中,有些很相似的句子会有不同的含义,比如:Password is not safe和No prompt when the password is not safe这两句话可能距离相对较小,但一个是安全问题,一个是页面设计时出现的问题;还有些看起来不是很相似,但是实际上应该被分成一个类别的句子,比如:Button should turn blue when clicked和Icon cannot be displayed,这两句话应该都是页面设计问题,但是在聚类时的距离可能会被计算为很大。因此只使用SSE作为评价指标是不合理的,本文选择准确率和SSE值共同作用,由表5可见,使用方法4的SSE值略低于使用方法1的SSE值,由此验证使用方法4聚类效果好于使用方法1。
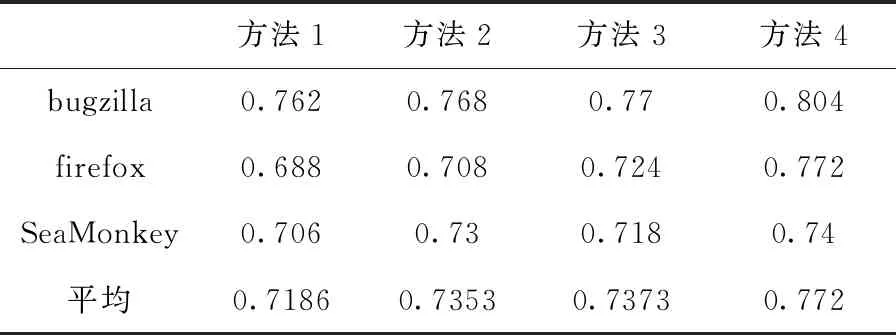
表4 不同获取有效特征方法的聚类准确率/%

表5 不同方法获取有效特征方法的聚类的SEE值/%
2)不同权重计算方法的实验结果
我们根据摘要,描述和评论来分析不同位置特征向量的权重。因为出现在摘要的特征单词一定会出现在描述中,所以一共可以分为5种情况。我们使用粒子群算法可以计算出单词在不同位置时最优的一组权重值,结果见表6。
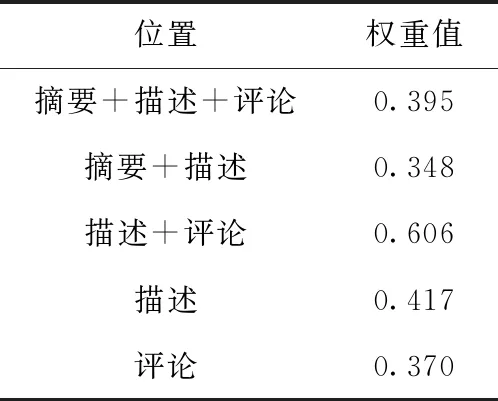
表6 基于粒子群算法权重计算结果
我们比较了使用了权重计算方法和未使用该方法的聚类效果:
方法1:只使用TF-IDF进行权重计算。
方法2:TF-IDF基础上加入基于粒子群算法的权重计算规则的权重计算。
图7显示了不同软件分别使用方法1和方法2后的准确率,从实验结果可以看出,加入权重后,所有软件聚类的准确率都明显提高,验证了特征单词所在位置的不同,其所提供的信息不同,需要通过加入权重来调整特征向量来提高聚类的效果。
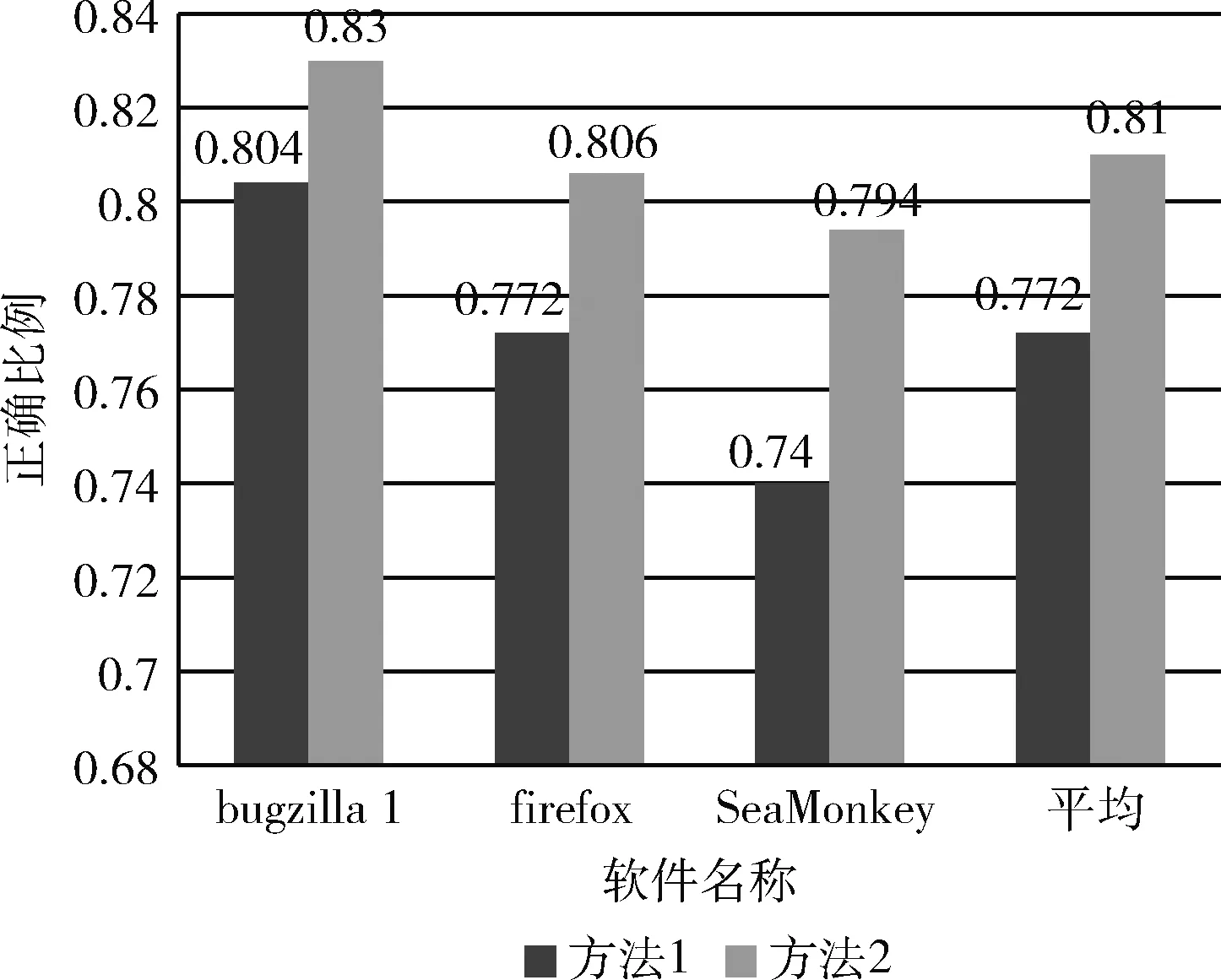
图7 不同权重计算方法的聚类结果
DAKSM方法实验结果:经过实验,使用DAKSM方法后每款软件的总体结果见表7。
(2)关键词提取结果
在聚类基础上,我们获得了不同类型的缺陷簇,接着我们提取不同簇的关键词。本文认为关键词提取时无用单词与聚类时无用单词有很大不同,因此本文在进行关键词提取时选用的是只经过预处理的缺陷报告,基于此本文首先

表7 聚类总结果
提取关键词,然后分析了通用关键词,在去掉了通用关键词后,我们提取了不同簇的不同主题以及关键词。我们在表8中列举了firefox中聚类结果为cluster 0的3个主题,每个主题下分别列举了5个关键词,由关键词得知,cluster 0是关于安全的问题,topic 0和topic 1为登陆或注册的身份安全问题,topic 2是支付问题,这2种主题同属于安全问题。

表8 主题与关键词
4 缺陷分析结果
4.1 web软件缺陷类别与主题
经过实验分析,Web程序缺陷主要分安全、功能、崩溃、文件传输、前后台传值和页面这6类,通过对主题和主题词分析得出每一类下面的不同关键词,通过分析整理后部分见表9。
4.2 web软件中缺陷数量关系
经过对实验结果的分析发现由于本文选择的3款软件为web软件,所以页面、前后台传值和功能类缺陷较多,而安全类较少,大部分为木马病毒攻击或密码等信息安全。而且大部分缺陷可被分成多个类别,比如“点击下载按钮

表9 部分缺陷类别与主题
无法进行下载”也许是因为页面的按钮不起作用,也可能是前后台传下载路径有问题,还有可能是文件本身不符合下载规定。经过分析发现一个缺陷可能由多个原因引起,因此在解决缺陷过程中不能只关注该缺陷的一方面,要全面分析才能有效地彻底解决缺陷。
4.3 开发人员建议
在对数据集进行清洗过程中发现,许多缺陷描述不是很清楚,这造成了缺陷自动分析过程中准确率降低,同时也对修复人员造成一定困扰,一般情况下摘要是缺陷的高度概括,应该聚集了缺陷的所有特征,但对数据集分析发现只看摘要并不能快速了解缺陷,还需要仔细阅读详细介绍才能大概了解缺陷的特征,有时甚至需要分析评论才能更好读懂缺陷,这对修复人员是一个挑战,因此建议开发人员写缺陷报告时尽量完善缺陷信息以减少分析时间,并提高开发人员再培训效率。
5 有效性威胁
5.1 内部有效性威胁
首先在特征筛选阶段,我们选用人工分析的方式分析出大部分web软件的无用词,在特征处理阶段也选用人工分析隐藏含义相同的单词,主观影响难以消除。其次在关键词提取过程中我们选用LDA提取主题词,每一次提取出的结果有一定差异,造成实验难以重复,另外本文只提取出关键词,下一步打算提取主题以便修复人员更高效修复缺陷。最后在评价部分,由于该方法主要针对修复人员看缺陷报告困难的问题,所以单用准确率来评价有些单一,下一步打算将结果呈现给修复人员,收集一些评价数据,例如理解时间、清晰度等值进行评价。
5.2 外部有效性威胁
我们选用了3款web软件作为分析数据验证本文提出的方法,有较强的针对性,并未分析其它类型软件,下一步打算使用本文方法进行多类型软件缺陷分析。其次为保证实验的多样性,本文随机选取3款软件各500个缺陷进行分析,缺陷数量略少导致某些类型缺陷过少,聚类过程中有严重不平衡现象。今后的工作中打算对更多的缺陷进行分析。
6 结束语
软件行业的快速发展给人们生活带来简便。但是,当软件存在缺陷的时候就会造成诸多威胁。因此,如何快速高效解决软件缺陷是研究者们一直以来研究的热点。本文提出了一种基于聚类和关键词提取的软件缺陷分析方法,利用K-Means和LDA主题建模技术分析缺陷报告,使缺陷理解性更强,使修复人员更有针对地寻找解决方法以便高效解决缺陷。另外经过实验验证了该方法的可行性。实验结果表明该方法能够为修复人员提供缺陷的关键信息。
在未来的工作中,我们希望统计更多类型的软件得到更多类型的缺陷,并使用增量学习来增加缺陷类型,使方法具有较好的鲁棒性。另外希望结合starckoverflow问答系统,综合缺陷关键词和问答系统关键词自动推荐出与该类缺陷相关的修复方式,以减少修复人员的修复时间。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
当代陕西(2020年17期)2020-10-28 08:18:18
中国交通信息化(2018年5期)2018-08-21 03:37:40
人大建设(2018年5期)2018-08-16 07:09:00
电子测试(2017年15期)2017-12-18 07:19:27
电信科学(2017年6期)2017-07-01 15:44:57
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
