
基于差分的图像感知哈希算法
2021-03-23 09:14:08闫国玉蒋遂平
计算机工程与设计 2021年3期
刘 帆,王 颖,闫国玉,蒋遂平
(1.中国航天科工集团第二研究院 七〇六所,北京 100854;2.西安电子科技大学 网络与信息安全学院,陕西 西安 710071)
0 引 言
图像感知哈希(perceptual hashing,pHash)[1]从一幅图像导出并可表征图像特征指纹。图像pHash算法与密码学哈希(cryptographic hashing,cHash)[2]算法不同。在cHash算法中,假设输入为一幅图像,则该图像的微小变化会通过雪崩效应引起输出结果即cHash值的巨大变化;而图像pHash算法则要求输入图像在视觉上相似时,输出的图像pHash值也相似。
近年来,随着云存储技术的发展,图像pHash算法对于图像文件的内容识别、完整性验证和水印技术起到重要作用。图像pHash算法被广泛用于可搜索加密方案中的相似性检索,并因为其能同时保证查询效率和结果精确度的优点,使其成为图像安全去重的重要技术之一[3,4]。
云存储和去重应用,要求pHash算法具有计算简单、一定的不同图像区分能力等特性。为此,本文提出并实现了循环贯序差分和拉普拉斯算子等两种基于差分的图像感知哈希算法。针对设计的算法,分别在小规模相似图像集合和大规模不同图像集上进行了测试。与现有复杂性类似的图像感知哈希算法相比,所提出的算法体现了图像像素点间的局部关联性,增加了不同图像哈希值间的差异,显著提升了不同图像的区分概率。
1 相关的工作
自从图像pHash的概念提出以来,研究人员已经提出了多种pHash算法。根据算法运行机制的不同,主要分为以下3类:
(1)基于图像灰度的pHash算法:利用图像灰度值与图像灰度均值的差或者利用相邻像素的灰度差等信息来计算pHash值。应用比较广泛的主要有均值pHash算法(average pHash,Avg pHash)[5],主要利用亮度变化小的区域即图像低频成分来描述整幅图像所含有的信息,计算复杂度低,但是进行图像相似性检测的准确率较低;块均值pHash算法[5],采用重叠阻塞和旋转操作来增强图像对几何失真的鲁棒性,在稳健性和可辨识性方面表现出比其它现有算法更高的性能并且实现简单;差分pHash算法[5]基于渐变实现,考虑了图像的局部特征。
(2)基于图像正交变换的pHash算法:对图像进行正交等方式的变换,利用变换后的系数与系数平均值的差计算pHash值。刘颖等[6]提出一种基于离散余弦变换(discrete cosine transform,DCT)和奇异值分解(singular va-lue decomposition,SVD)相结合的pHash算法,首先需要将图像进行分块DCT变换,然后将低频系数的组合进行SVD变换,最后将二值水印嵌入到奇异值所对应的矩阵上,这使得当嵌入较高强度的水印时也能具有较好的视觉不可感知性。Sheth等[7]提出了一种基于DCT、离散小波变换(discrete wavelet transformation,DWT)和密码技术组合的算法,对水印图像和原始图像提供强大的鲁棒性和感知透明度,以抵抗诸如裁剪、噪声和缩放之类的不同类型的攻击。
(3)基于图像特征点的pHash算法:通过提取图像特征点来表示图像。欧阳君林等[8]提出了一种基于四元数Zernike矩(quaternion Zernike moments,QZMs)和尺度不变特征变换(scale invariant feature transform,SIFT)的鲁棒图像哈希方案用于图像认证。所提出的方法可以定位篡改区域并检测修改的性质,包括对象插入、移除、替换、复制、移动、剪切和粘贴等操作。然而此方案对于图像噪声以及图像亮度变化较为敏感,使得其对该类型的图像篡改识别准确率较低。杨宁等[9]提出了一种基于SIFT特征和角度相对距离的图像配准算法,该算法充分利用了图像正确匹配特征点对之间存在的角度关系,实现了特征点之间的精确匹配。
基于图像灰度的pHash算法主要使用图像低频成分表征图像信息,计算复杂度不高,但精度较低。基于图像正交变换的pHash算法,对图像进行正交等方式的变换来获取图片的低频成分,只要图像之间的相互空间关系不变,即能提供良好的相似图像识别效果。但是该类算法的pHash值,大多仅能表示相较于该图像频率平均值比例的一个估计值,并不能提供图像真实的低频性质。基于图像特征点的pHash算法,生成的图像哈希序列维数较高,算法复杂度高,计算开销大,响应速度低,故这类pHash算法在图像快速相似性检索中很少使用。
此外,上述pHash算法的研究和应用中,重点考虑的是如何减小视觉上相似图像的pHash值差异,无法体现pHash值对不同图像的分辨程度。常用pHash算法在实际应用中,会将大量视觉上的不同图像判断为相似图像,所带来的通信开销很大。因此,需要解决感知哈希算法在应用过程中所带来的计算复杂度高、不同图像区分概率太低和通信开销大这一问题。
2 图像pHash算法
2.1 图像pHash值的计算流程
图像pHash值的计算流程如下:
(1)将M行N列像素点的大图像缩小为8×8、16×16、32×32即m×m等尺寸的小图像。
(2)彩色小图像转换为灰度小图像,此时图像可以表示为m阶图像灰度像素矩阵。使用如下规则
Gray=R×0.299+G×0.587+B×0.114
(1)
式中:Gray代表图像像素点的灰度值,R、G和B分别代表红、绿和蓝3种颜色通道的值,取值范围[0,255]。
(3)灰度小图像二值化,像素取值0或1,组成m阶二值像素矩阵。
(4)二值小图像像素按某种顺序串接为64、256、1024等长度的比特序列,作为图像的pHash值。
各种pHash算法的主要差异在于(3),例如,均值pHash计算图像的平均灰度如下
(2)

二值化方法如下

(3)
式中:h(i,j) 代表m阶二值像素矩阵第i行j列的值。如果像素的灰度大于等于平均灰度,则二值化结果为1,否则为0。同样地,在DCT pHash算法中,首先计算图像DCT系数,如果像素矩阵中第i行j列上的系数大于等于所有系数的均值,则该位置像素二值化结果就为1,否则为0。
2.2 图像二值化方法改进
针对图像pHash值的计算流程,提出了循环贯序差分pHash(Seq pHash)算法和拉普拉斯算子pHash(Laplace pHash)算法,并主要基于步骤(3)即图像二值化方法进行改进。
(1)Seq pHash:在Seq pHash算法中进行二值化时,图像中的像素按从上到下、从左到右的顺序依次排列。对每个像素而言,如果当前像素的灰度值大于或者等于后一个像素的灰度值时,则对应的二值像素为1,否则为0。当前像素是小图像中最后一个像素时,则当前像素的后一个像素为小图像中第一个像素。
图1给出了一个8×8小图像的例子,将小图像中的像素按照图1中的序号顺序可以排成一个序列,这是Seq pHash的顺序性。如果序列中一个像素A的灰度大于等于后一个像素B的灰度,则这个像素A对应的二值化结果为1,否则为0。如果一个像素A是序列中的最后一个像素,则像素A的后一个像素B是序列中第一个像素B,这是Seq pHash的循环性。例如在图1中,64号像素的后一个像素是1号像素。
(2)Laplace pHash:在Laplace pHash算法中,对图像灰度值进行二值化并使用了如下规则
(4)

图1 Seq pHash中像素的排列方式
式中:n为邻接像素的个数,D为m阶像素矩阵中第i行j列元素邻域像素点构成的集合,Gray(i,j) 为m阶像素矩阵中第i行j列元素邻域上像素点的灰度值。设有一个灰度值为220的像素A。如果像素A为图像中间像素,则其有8个邻接像素,此时n=8,如图2(a)所示。如果像素A在图像的4个角上,则其有3个邻接像素,此时n=3,如图2(b)~图2(e)所示。如果像素A在图像4个边缘,则有5个邻接像素,此时n=5,如图2(f)~图2(i)所示。

图2 Laplace pHash中邻接像素
在Laplace pHash算法中,仅使用了Laplace的一阶微分形式,并没有采用先计算Laplace差分,再计算过零点获得边缘像素进行二值化的方法[10]。这是因为图像二值化之前,较大的原始图像已经压缩为小图像,边缘效果已经不明显,利用Laplace算子计算边缘已经没有多大意义。
2.3 pHash值的相似性度量
汉明距离(Hamming distance)[11]是衡量两个字之间距离的一种方法。它通过统计两个相同长度的字所对应位不同的数量来计算字之间的距离,进一步达到相似性度量的目的。若x={x1,x2,…,xn} 和y={y1,y2,…,yn} 分别表示两个有限长度的字符串,以D(x,y) 表示两个字符串x,y之间的汉明距离,则相似性度量过程可表示如下
(5)
式中:Q(xi,yi) 取值有如下规则
(6)
为加快字符比较效率,将汉明距离相对于字符串长度作相对距离归一化。归一化后的汉明距离可以定义为
(7)
特别的是,可以通过异或运算的方式来计算二进制字符串间的汉明距离Db,其中符号⊕代表异或运算符,如下
(8)
因此,可以使用所获得的两个字符串之间的汉明距离来确定其相似性。为了识别相似的字符串,通常设置汉明距离的阈值,表示为T。
如果D(x,y)=0,则x和y被认为是相同的字符串。
如果D(x,y)≤T,则x和y被认为是相似的字符串。
如果D(x,y)>T,则x和y被认为是不相似的字符串。
两幅图像的pHash值差异采用汉明距离来进行度量。由于pHash值是比特序列,故汉明距离计算更加方便,只需要将两个比特序列异或后,计算其中的比特1的数目即可。
3 实验分析
使用图像pHash算法进行图像文件的相似性判断,本质上是将图像按照视觉相似性进行分类,即将图像分为与待上传图像相似的同类图像和不相似的异类图像。在模式分类中,要求同类事物的特征差距较小,不同类事物的特征差距较大[12]。因此,对于图像pHash算法,应该具有以下两个性质:
(1)类内聚合性:同一幅图像及其微小变形图像的pHash值差异应该较小。
(2)类间分离性:视觉上不同的两幅图像的pHash值差异应该较大,这样可以降低pHash冲突率。pHash冲突率,即在使用pHash值差异衡量图像相似性时,不同图像被认为是相同图像的概率。
利用收集到的图像数据集,从上述两个性质上,分析本文提出的pHash算法,并与常用的Avg pHash算法和DCT pHash算法进行对比。接下来,将进一步介绍具体实验过程和评估结果。
3.1 类内聚合性
类内聚合性测试的图像集合来自开源代码pHash库(https://www.phash.org/download/)。图像集合中有23幅不同的图像,每幅图像有4个版本:基准版本(misc)、模糊版本(blur)、压缩版本(compr)、旋转版本(rotd),其中blur版本图像经过高斯噪声和椒盐噪声等常见信号的处理;compr版图像经过联合图片专家组(joint photographic experts group,JPEG)制定的标准压缩算法的处理;rotd版是以图像对称中心为定点并作轻微旋转的图像。其中1幅图像的4个版本如图3所示。

图3 部分测试图像
分别在不同算法和不同比特数目下,计算每幅基准、模糊、压缩和旋转版本图像的pHash值,进一步得到汉明距离的平均值和方差,列于表1。在表1栏目数据区域,每个单元格有两行数值,第一行数值是平均值,第二行数值是方差。例如,在32×32图像尺寸1024比特数目下,计算每幅基准图像和其模糊版图像在Avg pHash算法下的pHash值。然后,求取两个pHash值间的汉明距离,则23组图像产生23个汉明距离。接下来,对该23个汉明距离值求取平均值和方差,分别为2.782 609和3.463 556。
从表1可以看出,在这个小规模图像集合上,随着图像尺寸的缩小,这4种图像pHash算法计算出的pHash值普遍存在着一种现象。每幅基准图像与其模糊、压缩、旋转版本图像pHash值的差异在不断缩小,这意味着类内聚合性“越来越好”。然而这是一种假象,因为伴随图像压缩率的提高,图像损失的信息熵也会越来越多,再去比较相似性已经没有任何意义。因此,计算图像的pHash值时,图像比特数不应太少,否则容易将不同的图像判别为相同或相似的图像。
此外,Avg pHash算法对于同一图像的不同变化版本,计算出的pHash值差异较小,Seq pHash算法、Laplace pHash算法和DCT pHash算法计算出的pHash值差异较大。因此,可以得出如下结论:即Avg pHash算法在类内聚合性上更有优势。但是,既然相似图像的pHash值差异较小,不相同图像的pHash值差异也可能较小,即不相同的图像也可能被判断为相同或相似的图像,再次说明图像分类中关于类间分离性的讨论很有必要。

表1 基准图像与其它版本图像的汉明距离均值和方差
3.2 类间分离性
为进一步分析pHash算法的类间分离性,采用CIFAR-100(http://www.cs.toronto.edu/~kriz/)的开源图像集合进行实验。CIFAR-100开源图像集合由32×32图像尺寸大小,共100个类的彩色图像组成。其中每个类包含600幅图像,500幅用于训练的图像和100幅用于测试的图像。以下是该图像数据集合中的类,以及每个类中的一些随机图像,如图4所示。
比较图像在256比特数目下的pHash值差异。选取CIFAR-100开源图像集合中的训练集,即100类不同景物的50 000幅不同彩色图像,作为本次实验的数据集。接下来,两两图像形成一对,那么这50 000幅图像可以组成 1 249 975 000 个图像对。采用不同pHash算法,求取每个图像对pHash值之间的汉明距离,并统计小于等于某个汉明距离的图像对的累计分布情况。
图5给出了不同pHash算法下图像对数目随汉明距离分布情况。可以看出,当汉明距离为50时,DCT pHash算法和Avg pHash算法便开始有数量比较可观的不相同图像对被判定为相似图像对,而在此情景下,Seq pHash算法和Laplace pHash算法所对应的汉明距离为90。相对而言,Seq pHash算法和Laplace pHash算法有较高的容错率。

图4 CIFAR-100数据集部分图像

图5 图像对数目随汉明距离分布情况

图7 汉明距离小于50时的图像对累计数目 随距离分布趋势
为进一步观察不同pHash算法下汉明距离小于50时图像对数目上存在的差距,图6给出了不同pHash算法下汉明距离小于50时图像对数目随距离分布的对数坐标变化趋势,图7给出了不同pHash算法下汉明距离小于50时图像对累计数目随距离分布情况。可以看出,Seq pHash值和Laplace pHash值在汉明距离小于50的图像对数目明显少于Avg pHash值和DCT pHash值的图像对数目。其中图6和图7,纵坐标均采用了底数为10的对数刻度。
图8给出了不同pHash算法下图像对累计数目随汉明距离分布情况,可以看出,大多数图像对的Seq pHash值和Laplace pHash值的汉明距离大于90,大多数图像对的Avg pHash值和DCT pHash值的汉明距离大于50。这表明,Seq pHash值和Laplace pHash值的pHash冲突概率[13]小于Avg pHash值和DCT pHash值的概率。

图8 图像对累计数目随汉明距离分布情况
表2给出了部分汉明距离下图像对数目的累计分布。例如,Avg pHash算法中有1693对图像的汉明距离小于等于2。可以看出,为达到百万分之一以下的哈希冲突率,即不同图像被认为是相同或相似图像的概率小于百万分之一,要求相同或相似图像对的累计数目不能超过1250对。这时,Avg pHash算法对应的汉明距离阈值为2,Seq pHash算法、Laplace pHash算法和DCT pHash算法对应的汉明距离阈值分别为33、48和10。Seq pHash算法、Laplace pHash算法的汉明距离阈值较大,可以容许的图像间差异较大,类间分离性优于Avg pHash算法和DCT pHash算法。
由于不同pHash算法的类内平均距离不同,用于判断两幅图像是否为同一图像的汉明距离阈值也应不同。采用模糊、压缩和旋转3种情况的平均值T作为阈值,方法如下
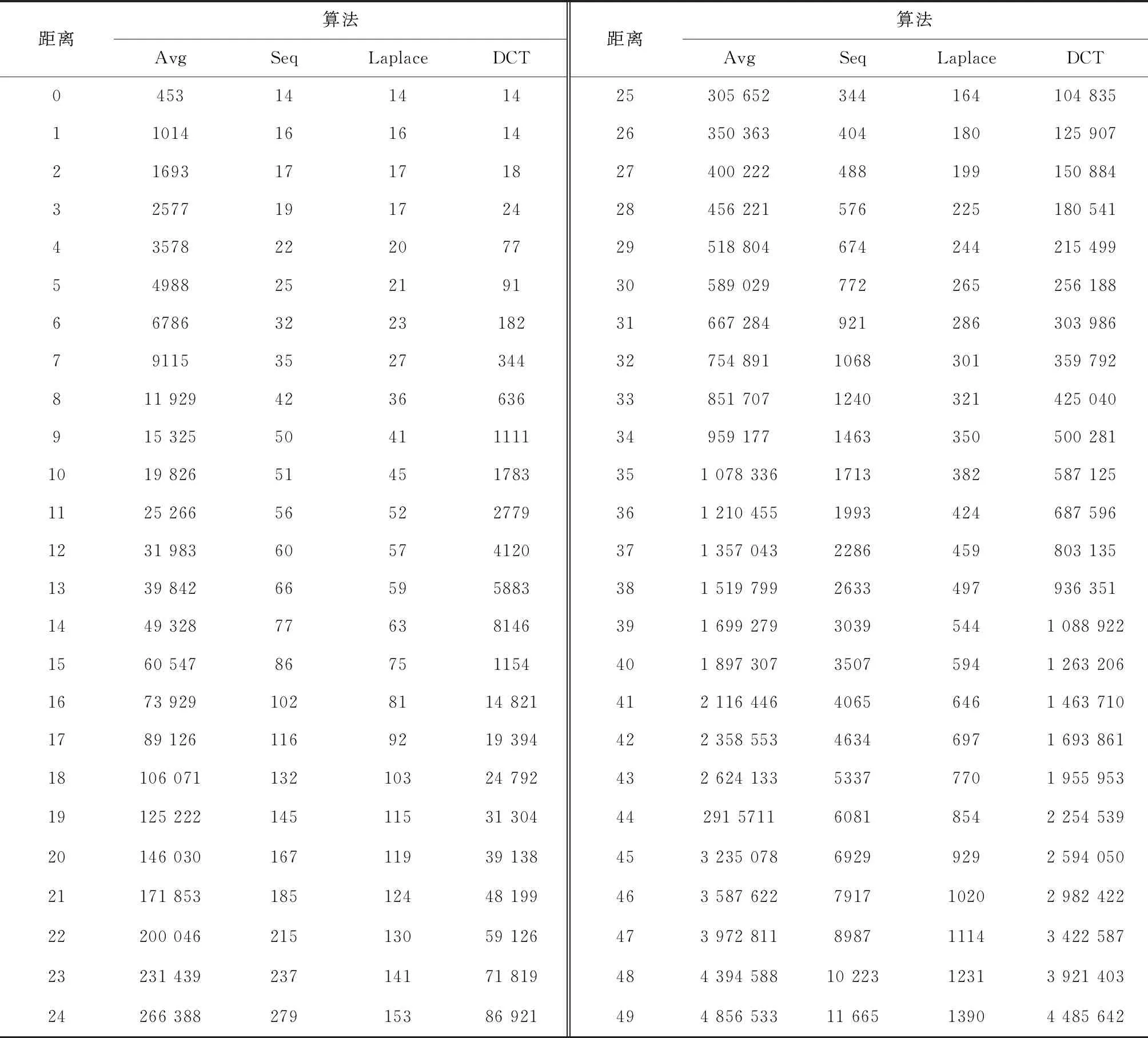
表2 部分汉明距离下的图像对累计数目
(9)
式中:D(mi,bi) 表示第i幅基准版图像和模糊版图像pHash值间的汉明距离;D(mi,ci) 表示第i幅基准版和压缩版图像pHash值间的汉明距离;D(mi,ri) 表示第i幅基准版和旋转版图像pHash值间的汉明距离。k值代表图像组数23,i取值范围[1,23]。此时,Avg pHash算法、Seq pHash算法、Laplace pHash算法和DCT pHash算法对应的汉明距离阈值分别为12、20、21和20,对应的相同或相似图像对数目的累计分别为31 983、167、124和39 138。其中,Seq pHash算法和Laplace pHash算法的相同或相似图像对累计数目较小,哈希冲突概率小,类间分离性优于Avg pHash算法和DCT pHash算法。
图像旋转造成的差异最大,超过平均差异,在工程中选择图像轻微旋转情况下的均值与方差的和作为判断图像相似性的汉明距离阈值。这时,Avg pHash算法、Seq pHash算法、Laplace pHash算法和DCT pHash算法的阈值分别为21、33、33和35,对应的相同或相似图像对数目的累计分别为171 853、1240、321和587 125。该种情况下,Seq pHash算法和Laplace pHash算法的相同或相似图像对累计数目明显较小,再次说明,Seq pHash算法和Laplace pHash算法的哈希冲突概率小,类间分离性优于Avg pHash算法和DCT pHash算法。
实验结果表明,Avg pHash算法没有考虑图像像素点之间的关系,而DCT pHash算法中DCT系数主要描述图像各种组成信号强弱的全局性质。因此,Avg pHash算法和DCT pHash算法的类间分离性相对较差。Seq pHash算法和Laplace pHash算法均考虑了像素点之间的关系,即图像的局部性质。Seq pHash算法考虑了相邻2个像素点之间的关系,Laplace pHash算法考虑了像素点与周围像素点的关系,在图像局部性上更有优势。因此,Laplace pHash算法的类间分离性好于Seq pHash算法。
由此可知,Seq pHash算法和Laplace pHash算法虽然增大了同一幅图像与其微小变形图像之间的pHash值差异,但也增大了不同图像之间pHash值的差异。也就是说,通过选择可以容许图像微小变化的汉明距离阈值,这两种算法将仍能按照视觉相似性进行图像的分类。此外,所设计算法可以更清楚地量化哈希碰撞效果,提高了查询结果的精确率和召回率。这样将进一步减少图像相似性判断的错误率,从而降低了对结果处理的开销。
4 结束语
本研究针对可搜索加密方案中相似性检索关于如何增大不相似图像差异这一问题,提出了Seq pHash和Laplace pHash两种基于差分的图像感知哈希算法,并对所提出的算法进行了性能测评。测评分别采用开源感知哈希库的小规模图像集和CIFAR-100大规模图像集。测试结果表明,所提出的图像感知哈希算法较好地体现了图像像素点间的局部关联性。在不同图像被认为是相同或相似图像的概率小于百万分之一情况下,Seq pHash算法和Laplace pHash算法对应汉明距离阈值均高于Avg pHash算法和DCT pHash算法对应汉明距离阈值。因此,所提出的pHash算法在类间分离性上优于所对比的常用pHash算法,它们不仅能够识别多种失真类型的相似图像,还能有效地降低不相似图像汉明距离接近的概率以实现不同图像的区分,可以更好地应用到可搜索加密方案中的相似性检索中。
猜你喜欢
中学化学(2024年4期)2024-04-29 22:54:35
中国铁路文艺(2016年6期)2016-05-14 08:13:13
中国民族医药杂志(2016年5期)2016-05-09 07:43:50
工业设计(2016年8期)2016-04-16 02:43:34
作文大王·低年级(2016年3期)2016-03-11 00:48:53
星星·散文诗(2015年35期)2015-10-27 21:00:08
计算机工程(2015年8期)2015-07-03 12:20:04
应用数学与计算数学学报(2014年4期)2014-09-26 12:16:00
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年12期)2014-02-27 11:58:03
