
一种为辅助诊断筛选机器学习模型的方法
2021-03-23 07:56:58邓子云
计算机与现代化 2021年3期
邓子云
(1.长沙商贸旅游职业技术学院经济湘商学院,湖南 长沙 410116;2.湖南大学国家超级计算长沙中心,湖南 长沙 410082)
0 引 言
判断接受医学检查的人员是否患有某种疾病,常规做法是医生根据医学检查结果的各项指标值来作出知识推断,既要求医生对专业领域非常熟悉,也要求医生能清楚各项指标在患病时的取值区间[1]。能否借助大数据技术帮助医生进行辅助诊断?即在积累了某种疾病足够数量的样本数据及诊断结果后,可以使用机器学习模型来辅助诊断新的样本数据对应的人员是否患有某种疾病[2]。
可以用来辅助诊断是否患有某种疾病的机器学习模型有很多,如K-近邻模型、支持向量机模型、逻辑回归模型等,但是应当选用哪种模型更优呢?自然是认为辅助诊断更为准确的模型更优。但是怎么衡量更为准确?能否研发一种引擎为医生自动推荐一种用于疾病辅助诊断的最优的机器学习模型?本文的研究就致力于研发这种引擎,并提出选择何种模型的筛选方法。
1 国内外研究现状
1)用人工智能技术作疾病辅助诊断的研究有很多,研究人员总在试图寻找更优的机器学习模型。有的研究人员用相似性分析技术分析出新的数据与已有病例数据的相似度来辅助诊断[3],有的研究人员用贝叶斯[4-5]、神经网络[6]等模型构建起诊断的大数据机器学习模型。这些研究的共同点是都需要有病例和非病例数据的积累,需要医护人员根据其认为可以作为判断依据的特征数据项来收集数据,再使用一种或多种模型在分析后作出比较,再选择一种最优的模型。也有的研究工作只讨论用于疾病辅助诊断的一种模型的参数调优。要比较机器学习模型,需要有衡量机器学习模型优劣的指标,主要有准确度、查准率、召回率、F1成绩、是否欠拟合、是否过拟合等[7-9]。
2)部分研究人员已研发了大数据智能的疾病辅助诊断系统。有研究人员研发出了专用于体检结果的疾病辅助诊断系统[10],还有研究人员研发了小型软件用于牙科疾病[11]、糖尿病[12]、乳腺癌[13]等疾病的辅助诊断,这些系统多是专用系统,有少数系统可以适用于多种疾病的辅助诊断,但采用的机器学习模型只支持1种或少量的几种。
鉴于以上分析,本文并不去寻找新的机器学习模型,而是提出筛选机器学习模型的方法,再运用这种筛选方法自动为医生推荐最优的机器学习模型。
2 机器学习模型及其筛选方法
2.1 可用于疾病辅助诊断的机器学习模型
机器学习模型有很多,主要有监督、无监督、强化学习等3类[14]。利用已有病例和非病例数据作疾病辅助诊断是典型二分法分类问题,即辅助诊断的结果为是否患有某种疾病。这种分类问题适宜采用的机器学习模型是有监督的机器学习模型,如逻辑回归、决策树、K-近邻、支持向量机、朴素贝叶斯、神经网络等[15],如表1所示。这些模型还可以分化出多种子类型的模型,如根据逻辑回归模型函数中的判定边界函数可分为1阶、2阶、…、n阶,根据成本函数中的正则项,又可分为L1范数、L2范数等[16]。

表1 可用于疾病辅助诊断的机器学习模型
有如此多可以采用的机器学习模型,到底采用哪种好呢?在为医生作疾病辅助诊断时,总不能把这些机器学习的模型都测试一遍吧?此外,医生应专注于医学领域的专业知识研究,机器学习的专业知识应由人工智能领域的专家完成,当然也可以联合完成。但是为了使机器学习的各种模型具有普适性,降低医生使用机器学习模型的难度,最好能为医生自动推荐最优的机器学习模型。
2.2 筛选机器学习模型的方法
综合已有研究人员提出的各种评价机器学习模型的做法[23-25],下面提出一种通用的筛选出最优的机器学习模型的方法,步骤如图1所示。
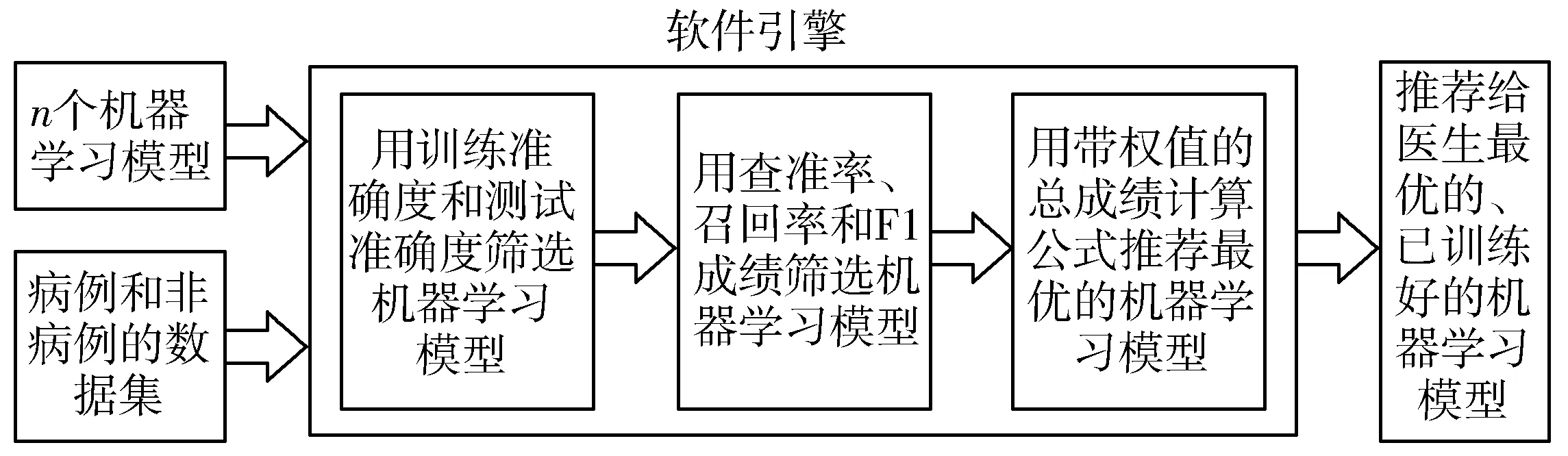
图1 筛选出最准确的机器学习模型的步骤
假定支持的机器学习模型集合为:
M={M1,M2,…,Mn},n≥1
1)用训练准确度和测试准确度筛选机器学习模型。
对已有的病例和非病例数据按9∶1的比例随机分组训练数据、测试数据,在作完机器学习模型Mi的验证测试后求得训练准确度和测试准确度,分别计为PAj、TAj。对机器学习模型Mi进行10次训练和验证测试,求得平均训练准确度和平均测试准确度作为机器学习模型Mi的训练准确度和测试准确度,分别记为PAi、TAi。
(1)
(2)
其中,i为机器学习模型的编号;j为对机器学习模型的10次训练中的某次训练的编号。
如果机器学习模型Mi同时满足以下条件1和条件2,则可继续进入下一轮的筛选。
条件1:PAi≥tand TAi≥t,t≥0.7
条件2:|PAi-TAi|≤d, 0.1≥d>0
条件1中,t表示用户设置的准确度阈值,t默认设置为0.7,训练准确度PAi和测试准确度TAi均必须大于或等于准确度阈值。条件2表示训练准确度PAi和测试准确度TAi应收敛,两者的差值的绝对值被称为收敛阈值,其值应在d以内,d默认设置为0.1。
2)用查准率、召回率和F1成绩筛选机器学习模型。
对已有数据按10%的比例分10次随机抽取测试数据,运用已训练出的机器学习模型Mi,计算出患病结果。再对比计算出的患病结果和实际患病情况,求出10次测试的查准率、召回率、F1成绩的平均值作为机器学习模型Mi最终的查准率、召回率、F1成绩。如表2所示的结果判断表示,以帮助求得查准率、召回率。

表2 是否患病的结果判断表示
表2中,True/False表示计算出的结果是否正确;Positive/Negative表示计算出的结果是1(患病)或0(未患病)。故TruePositive表示正确的计算出患病;FalsePositive表示错误的计算出患病;FalseNegative表示错误的计算出未患病。查准率、召回率的计算公式如公式(3)和公式(4)所示。
查准率:
(3)
召回率:
(4)
查准率PRi的计算公式中,CTruePositive表示对比计算出的患病结果和实际患病情况,为TruePositive的个数;CFalsePositive表示对比计算出的患病结果和实际患病情况,为FalsePositive的个数。召回率RRi的计算公式中,CFalseNegative表示对比计算出的患病结果和实际患病情况,为FalseNegative的个数。
F1成绩的计算公式如公式(5):
(5)
如果机器学习模型Mi同时满足条件3则可继续进入下一轮的筛选:
条件3:PRi≥rand RRi≥rand F1i≥r,r≥0.7
以上条件,表示查准率、召回率、F1成绩均应大于或等于阈值r,阈值r被称为三率阈值,三率阈值r默认设置为0.7。
3)用带权值的总成绩计算公式推荐最优的机器学习模型。
根据公式(6)计算机器学习模型Mi的总成绩:
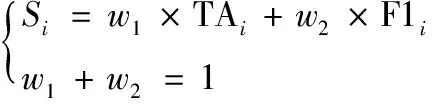
(6)
公式(6)中,w1和w2分别为测试准确度TAi和F1成绩F1i的权值,均默认设置为0.5。最后,给出总成绩最高的机器学习模型作为推荐给医生的最优的机器学习模型。
11月28日,ofo创始人兼CEO戴威的一封内部信流出,一向高傲倔强的戴威在信中近乎悲壮地说:“哪怕跪着也要活下去。”但即使跪了,就能解决问题吗?去年还被资本和大佬热捧的共享单车,怎么就变成了烫手山芋?
3 乳腺癌辅助诊断实例分析
不失一般性,下面采用TensorFlow的scikit-learn库中自带的乳腺癌数据集作为辅助诊断分析示例的数据集。
3.1 训练与测试用的数据集
从本文数据集中的肿瘤病灶造影图片中提取了10个关键特征,如表3所示。
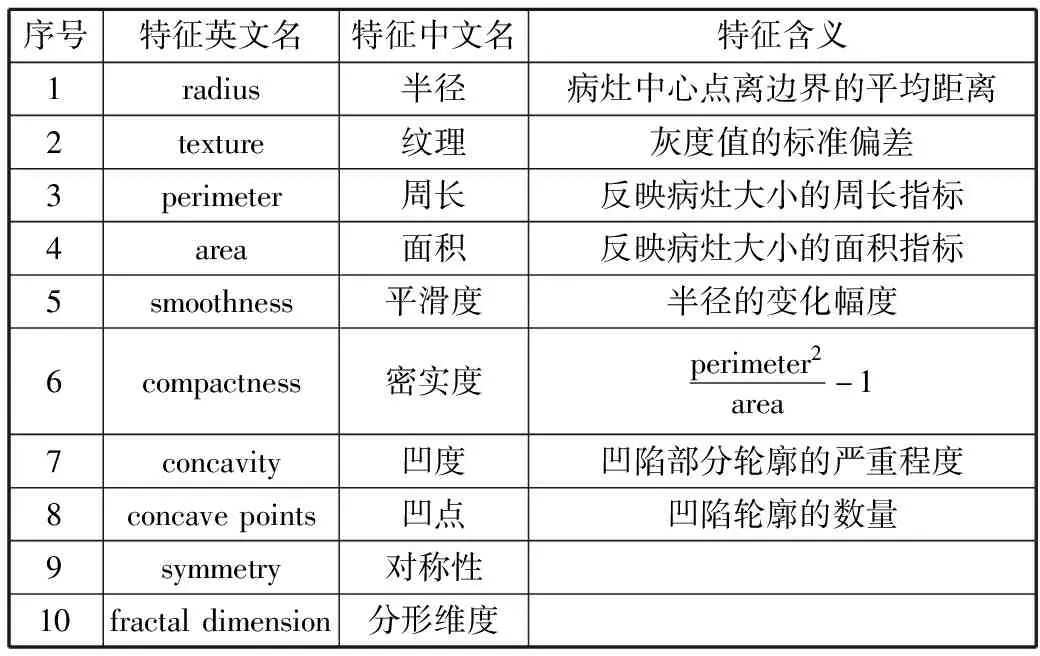
表3 乳腺癌数据集的10个关键特征
此外,根据这10个关键特征又计算形成了每个特征的标准差、最大值,这样形成了共计30个特征。数据集样本一共569个,其中,阳性样本(患有乳腺癌)357个,阴性样本(未患乳腺癌)212个。
3.2 实验环境
在Windows10操作系统下采用Anaconda3(64 bit)的Sypder作为开发工具,编程语言为Python3.6。软件开发和运行的硬件环境是Thinkpad T460s机型,该机型拥有512 GB固态硬盘,内存为8 GB,CPU为Intel(R)Core(TM)i5-6200U CPU @ 2.30 GHz 2.40 GHz。
筛选机器学习模型方法中的参数值设置如下:
t=0.9,d=0.02,r=0.9,w1=w2=0.5
3.3 供筛选的机器学习模型
为便于对比分析,充分利用scikit-learn库中已有的机器学习模型,这里用8个机器学习模型作为筛选的备选模型:
1)1阶逻辑回归模型。
2)普通的K-近邻模型。K值设为2。
3)带权重的K-近邻模型。K值设为2,权重设置为“distance”,即按距离设置权值。
4)线性的支持向量机模型。
5)2阶多项式的支持向量机模型。
6)3阶多项式的支持向量机模型。
7)一种高斯核心函数向量机模型。其中,γ=0.1。
8)一种高斯核心函数向量机模型。其中,γ=0.5。
3.4 用训练准确度和测试准确度筛选机器学习模型
经过10次模型训练和10次验证测试后,得出的8种机器学习模型的训练准确度和测试准确度如表4所示,绘制8个机器学习模型的学习曲线如图2所示。

表4 8个机器学习模型的训练准确度、测试准确度和计算时间

(a)1阶逻辑回归
根据条件1判断,发现2阶多项式的支持向量机、3阶多项式的支持向量机2个学习模型不满足条件,直接排除掉。从图2(e)、图2(f)这2个机器学习模型的学习曲线可以看出,2阶多项式的支持向量机模型虽然训练准确度和测试准确度随学习样本、测试样本数的增加而上升,但收敛于0.81左右;3阶多项式的支持向量机训练准确度和测试准确度变化不大,且收敛于0.64左右。
根据条件2,可以排除普通的K-近邻模型,因为|PAi-TAi|=0.025>0.02;也可以排除带权重的K-近邻模型,因为|PAi-TAi|=0.047>0.02。排除这2个机器学习模型的原因是认为学习曲线不收敛。从图8(b)、图8(c)也可以看出,普通的K-近邻模型和带权重的K-近邻模型这2个机器学习模型的训练准确率曲线和测试准确率曲线中间的间隙相对较宽。
实验中,通过记录各种模型的计算时间(训练时间+测试时间),可得到如表4所示的结果。从表中可见,2阶多项式的支持向量机模型花费时间最多,1阶逻辑回归模型花费时间最少。
3.5 用查准率、召回率和F1成绩筛选机器学习模型
经过上一步骤后,已经排除掉4个机器学习模型。再对上一步筛选出来的4个机器学习模型作10次模型训练和10次验证测试,得出查准率、召回率、F1成绩如表5所示。

表5 4个机器学习模型的查准率、召回率、F1成绩
从模型训练和测试结果数据来看,4个机器学习模型都满足条件3。
3.6 用带权值的总成绩计算公式推荐最优的机器学习模型
经计算,4个机器学习模型的总成绩如表5的最后1列所示。可见,高斯核心函数向量机模型(γ=0.5)的总成绩最高,作为最优的机器学习模型推荐给医生使用。
4 本文研究的不足与改进建议
本文研究工作尚存在以下不足:
1)支持的机器学习模型数量不足。目前仅支持8种机器学习模型,应当加入更多可用的通用机器学习模型,如决策树、朴素贝叶斯、神经网络等类型的机器学习模型。
2)筛选方法还有改进的空间。在应对需要长时间的训练时间的机器学习模型上应改进策略,如4阶多项式及更高阶的逻辑回归、支持向量机模型需要训练的时间就较长,可对比发现相对低阶多项式的机器学习模型在增加阶数并不能提升准确率的情况下,应停止尝试更高阶多项式的机器学习模型。
改进的办法是继续开展研究工作,加入更多的可支持的机器学习模型,改进机器模型的筛选方法使之更为高效、普适。
5 结束语
本文提出的筛选机器学习模型的方法分为用训练准确度和测试准确度筛选机器学习模型,用查准率、召回率和F1成绩筛选机器学习模型,用带权值的总成绩计算公式推荐最优的机器学习模型3个步骤来实现,可最终筛选出最优的机器学习模型推荐给医生使用。使用筛选方法前,应设置准确度阈值t、收敛阈值d、三率阈值r、测试准确度TAi的权值w1和F1成绩的权值w2这5个配置参数,也可以采用默认值。
本文提出的筛选机器学习模型的方法可用于多种疾病的辅助诊断。从乳腺癌的辅助诊断实例分析来看,最终选择高斯核心函数向量机模型(γ=0.5)推荐给医生使用,因为这个模型除满足筛选方法的3个条件外,总成绩最高,达到了0.985。
下一步的研究工作将加入更多的机器学习模型并改进机器模型的筛选方法,以弥补研究工作的不足。
猜你喜欢
上海工运(2020年8期)2020-12-14 03:11:56
科学(2020年3期)2020-11-26 08:18:20
建筑科技(2018年6期)2018-08-30 03:40:54
现代电子技术(2017年23期)2017-12-20 13:23:31
计算机应用(2016年10期)2017-05-12 11:02:20
中国交通信息化(2016年5期)2016-06-06 03:51:43
工业设计(2016年4期)2016-05-04 04:00:14
天津冶金(2014年4期)2014-02-28 16:52:58
机电信息(2014年35期)2014-02-27 15:54:30
计算机光盘软件与应用(2013年6期)2013-08-08 08:26:50
