
基于改进后的SegNet高分影像建筑物提取
2021-03-22 18:18沈晶灵杨晓竹
河南科技 2021年25期
沈晶灵 杨晓竹







摘 要:针对传统监督分类对高空间分辨率遥感影像中建筑物信息提取精度较低的问题,改进SegNet模型,利用U-Net模型中的跳层连接结构补充SegNet模型中解码器层的目标细节,加入空洞空间金字塔池化模块增强网络对多尺度目标的捕捉能力。利用改进后的SegNet、全卷积神经网络、支持向量机和最大似然法,对遥感影像中建筑物的提取结果进行对比分析。以法国国家信息与自动化研究所航空图像标记数据集为数据源,对分类结果进行定性和定量分析。在有限的迭代次数和实验区域内,改进后的SegNet的Kappa系数在80%以上,总体精度超过90%,在边缘细节的分类效果更精细,改进后的SegNet对遥感图像中建筑物的提取效果更好、精度更高,具有可行性和有效性。
关键词:SegNet;高分影像;建筑物提取;ASPP模块
中图分类号:P237 文献标识码:A 文章编号:1003-5168(2021)25-0006-05
High-Scoring Image Building Extraction Based on the Improved SegNet
SHEN Jingling YANG Xiaozhu
(College of Surveying and Mapping and Geographic Science, Liaoning University of Engineering and Technology,
Fuxin Liaoning 123000)
Abstract: In view of the low accuracy of building information extraction in high spatial resolution remote sensing images by traditional supervision classification, this paper improves the SegNet model, used the jumper connection structure in the U-Net model to supplement the target details of the decoder layer in the SegNet model, and adds ASPP module to enhance the network's ability to capture multi-scale targets.The results of the extraction of buildings in remote sensing imagery are compared using the improved SegNet, Full Convolutional Neural Networks, Support Vector Machine, and Maximum Likelihood Classification.Using the INRIA aerial image marker data set as the data source, through qualitative and quantitative analysis of the classification results, the improved SegNet Kappa coefficient is more than 80% in the limited iteration and experimental area, the overall accuracy is more than 90%, and its classification effect in the edge details is more fine.It is shown that the improved SegNet is more effective, more accurate and feasible for the extraction of buildings in remote sensing images.
Keywords: SegNet;high-scoring imagery;building extraction;ASPP module
高分辨率遙感图像的特征识别和检测是当前科学领域的研究热点[1],其提取的信息内容丰富,包括地物信息与纹理信息[2]。近年来,大量学者对高分辨率遥感影像中的地物信息提取等问题进行了研究,并提出了K均值[3]、迭代自组织的数据分析法(Iterative Self-Organizing Data Analysis Method,ISODATA)[4]、面向对象的分类方法[5]、最大似然法[6]、最小距离法[7]以及支持向量机[8-9]等方法。然而,在空间分辨率较高的遥感图像中,由于这些方法依赖于光谱特征,导致提取精度较低。随着分辨率的提高,图像中的噪声信息越来越突出。异物同谱和同物异谱等现象给影像质量带来的问题日益突出,给在高分辨率遥感图像中进行目标精确提取造成了很大影响[2]。
随着计算机硬件性能不断提高,由KRIZHEVSKY A等[10]提出的AlexNet网络,使得卷积神经网络在2012年再次受到广泛关注。AlexNet使用了一种基于LeNet[11]的更深层次的网络结构,使用卷积层来表现图像特征。LONG等[12]研究的全卷积神经网络(Fully Convolutional Network,FCN)模型,使卷积神经网络进入语义分割领域并得到广泛应用与发展。FCN的突出特点在于接受任意大小的输入,且有效地前向传播产生相应的输出。
宁宵等[13]提出利用U-Net模型,RONNEBERGER O等[14]提出利用SegNet模型和改进后的SegNet模型对遥感影像进行建筑物提取,对数据集进行模型训练,然后进行遥感影像的预测,达到了建筑物提取的目的,最后通过提取结果进行对比分析。基于目前遥感影像丰富的地类信息和复杂的建筑物结构的问题,U-Net模型和SegNet模型在遥感影像的建筑物、道路以及水体等重要地物的提取方面取得了良好效果。
在此基础上,对传统的SegNet模型进行改进。结合U-Net模型优点,使用其中的跳层连接结构补充SegNet模型的解码器层的目标细节,并在其中加入改进的ASPP模块,加强捕捉多尺度目标的能力,得到改进后的SegNet模型。通过改进后的SegNet模型对高分辨率遥感影像中的目标建筑物进行精确提取,并与MLC、SVM和FCN算法进行比较。结构表明该算法提取的分类精度更高,边缘细节更好,效果更佳。
1 研究方法
空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)由CHEN L C等[15]在DeepLab v2网络中提出,并在DeepLab v3中改进。图1为DeepLab v3中的改进ASPP模块。改进ASPP模块中包含空洞卷积的空洞率分别为6、12、18,以及一个1×1卷积和一个全局平均池化层,且在每一个空洞卷积和全局平均池化层后添加一个1×1卷积,使得各自输出的特征图维度相同。不同大小的空洞卷积能够捕捉多种尺寸的目标,增强网络对不同尺寸建筑物的分割能力。DeepLab v2中,ASPP模块采用4种不同空洞率的空洞卷积。但是,当空洞卷积的空洞率接近输入特征图尺寸时,空洞卷积只有中间部分的权重对特征图有效。DeepLab v3在ASPP中加入了一个全局平均池化层为1×1的卷积核。1×1卷积用于捕捉更细小的目标,而全局平均池化能够整合整个特征图的信息,有效解决了上述问题。最后,将空洞率为6、12、18的空洞卷积、1×1卷积和全局平均池化层得到的特征图进行concat操作。为了使其与输入相当,使用1×1卷积调整输出特征图的维度。
SegNet在卷积层部分全部采用尺寸为3×3的卷积核,导致SegNet对不同尺度对象的捕捉能力存在欠缺。使用SegNet网络进行建筑物和非建筑物二分类,实现遥感影像建筑物提取。它的上池化操作使其在小尺寸建筑物上提取效果较好,但在大尺寸建筑物上则提取结果不连续。同时,由于SegNet的解码器没有引入编码器阶段的特征图,导致丢失一定的细节。为了增强网络对多尺度目标的捕捉能力,在SegNet中加入改进的ASPP模块,同时通过加入U-Net中的跳层连接结构来补充解码器层的目标细节。
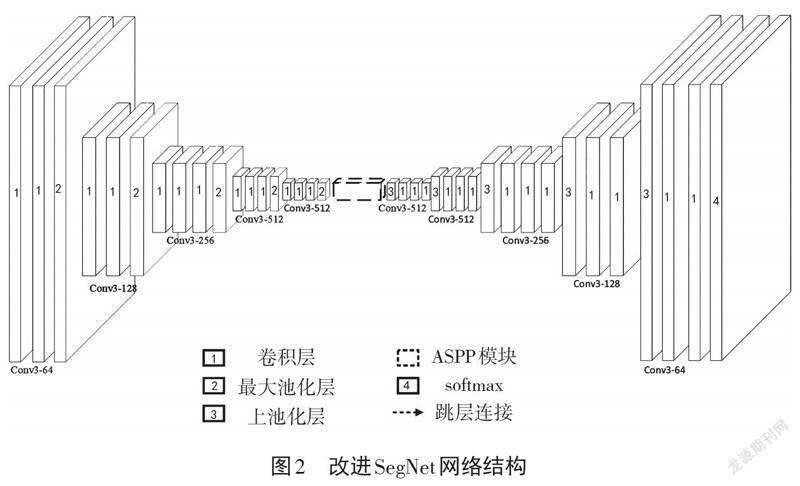
针对SegNet对不尺度目标信息捕捉能力有限,对大尺寸建筑物提取不连续的问题,提出改進SegNet网络结构,改进后的SegNet网络结构如图2所示。其中,Conv3-64是利用大小为3×3的卷积核,设置卷积层深度为64,整体网络结构采用对称形式的编码器-解码器结构。编码器层与VGG16的卷积层部分完全相同。13个层主要是卷积层、最大池化层和ReLU激活函数。5个最大池化层分为5组,每组的卷积层深度分别为64、128、256、512、512,均采用大小为3×3的卷积核。解码器与编码器相对称,同样分为5组,卷积层的深度和卷积核的尺寸也相同。不同的是,解码器将最大池化层对应替换为上池化层,以将特征图恢复至输入大小。在编码器与解码器层中间则是改进的ASPP模块,用多个空洞率的空洞卷积增强网络对多尺度目标的捕捉能力。改进SegNet在使用上池化来恢复特征图大小的同时,引入U-Net中提出的跳层连接结构。该结构能够将编码器得到的特征图采用concat操作与解码器对应位置的特征图结合,恢复在编码器阶段进行最大池化操作时丢失的信息。最后,通过softmax分类器[16]计算每个像素属于每一个类别的概率,从而判断该像素的所属类别。
2 试验与讨论
2.1 数据介绍与组织
本次试验选取了法国国家信息与自动化研究所的数据集(INRIA Aerial Image Labeling Dataset,IAILD)。该数据集所采用的遥感影像为美国、澳大利亚两处的居民地,并标注出建筑物与非建筑物,航空正射校正影像的空间分辨率是0.3 m,覆盖范围从人口密集地区(如旧金山的金融区)延伸到高山城镇地区(如奥地利蒂罗尔州的列昂斯),总面积为810 km2。同时法国国家信息与自动化研究所的数据集航空影像标注数据集也解决了遥感中的一个核心问题,即航空影像的自动像素化标注。本文选取3幅影像Ⅰ、Ⅱ、Ⅲ作为试验的测试数据,其原始影像和对应的真值图分别如图3、图4和图5所示。
2.2 试验环境与参数设置
本文试验环境为Window 7操作系统,基于Keras训练网络。硬件方面CPU为Intel(R) Core i7 4790,GPU为Nvidia GTX1060 6G,选取MLC、SVM、FCN作为对比算法。训练参数方面,均采用Adadelta[17]作为优化器,epoch设置为100,batch size设置为3。
2.3 试验结果与分析
图6为MLC、SVM、FCN和改进后的SegNet在a、b、c三幅影像的分类结果。由图6可以看出:MLC和SVM对高空间分辨率遥感影像中建筑物的提取效果不理想,且噪声多,在非建筑物的人造设施上出现了较为严重的错分现象;作为深度学习算法的FCN和改进后的SegNet的分类效果要明显好于MLC和SVM,二者对非建筑物的人造设施错分现象大大减少,整体分类效果较好;改进后的SegNet与FCN相比,其在边缘细节的分类效果上更优,对建筑物的边缘把控得更好(见图7),FCN则在大型建筑物的连续性上更有优势。
采用交并比(Intersection over Union,IoU)、Kappa和总体准确率(Overall Accuracy,OA)对分类结果进行定量评价。
交并比IoU的计算公式为:
IoU=TP/TP+FP+FN (1)
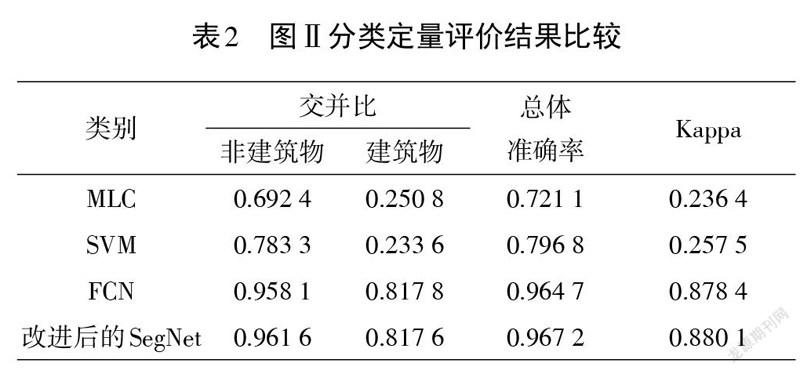
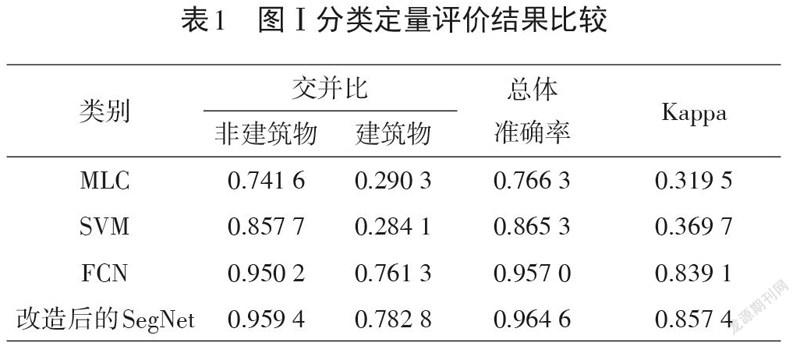
式中:[TP]代表正确的分类;[FP]代表错误分类;[FN]代表泄漏分类。表1、表2以及表3分别表示各个算法在3张影像上的分类准确率。
由表1可以看到,在每个评估指标中,改进后的SegNet算法测试结果明显高于其他3种分类算法。在表1中,FCN比MLC、SVM的Kappa系数和总体准确率分别提高51.96%、46.94%和19.07%、9.17%,本文算法比FCN算法的Kappa系数和总体准确率分别提高了1.83%和0.76%;在表2中,FCN比MLC、SVM的Kappa系数和总体准确率分别提高了64.20%、62.09%和24.36%、16.79%,本文算法比FCN算法的Kappa系数和总体准确率分别提高了0.17%和0.25%;在表3中,FCN比MLC、SVM的Kappa系数和总体准确率分别提高了55.73%、62.775%和16.14%、18.28%,本文算法比FCN算法的Kappa系数和总体准确率分别提高了0.73%和0.44%。
3 结论
①以IAILD作为试验数据,使用改进后的SegNet图像语义分割算法对遥感影像中的目标建筑物进行精确提取。将其与FCN、SVM和MLC这3种方法进行对比分析,得出以下结论:SVM和MLC两种分类算法在高分辨率遥感影像中提取出的不同类别建筑物之间分界线不明显,边缘模糊,分类精度较低;从试验结果可知,这两种分类算法的Kappa系数和总体准确率均较低,不适合高空间分辨率遥感影像对建筑物的精确提取。
②在利用改进后的SegNet和FCN两种分类算法对高空间分辨率遥感影像进行建筑物分类提取的结果中,两者的Kappa系数均在80%以上,总体准确率均超过90%,但相比之下改进后的SegNet算法所获得的结果在边缘细节的分类效果上更优,对建筑物的边缘把控得更好。
综上所述,通过对以上4种分类算法所得到的结果进行定性和定量分析,在有限的迭代次数及试验区域内,改进后的SegNet对目标建筑物的提取效果更好、精度更高,具有一定的可行性和真实有效性。尽管SegNet算法现处于起步阶段,但可以预见,未来几年,在该算法的基础上将会出现更加优秀、更加灵活的深度学习算法与更加符合科技发展的新的研究路线。
参考文献:
[1]赵英时.遥感应用分析原理与方法[M].北京:科学出版社,2003:165-168.
[2]元晨.高空间分辨率遥感影像分类研究[D].西安:长安大学,2016:16-21.
[3]王慧贤,靳惠佳,王娇龙,等.k均值聚类引导的遥感影像多尺度分割优化方法[J].测绘学报,2015(5):526-532.
[4]沈照庆,舒宁,龚衍,等.基于改进模糊ISODATA算法的遥感影像非监督聚类研究[J].遥感信息,2008(5):28-32.
[5]LOBO A,CHIC O,CASTERAD A.Classification of mediterranean crops with multisensor data:per-pixel versus per-object statistics and image segmentation[J].International Journal of Remote Sensing,1996(12):2385-2400.
[6]骆剑承,王钦敏,马江洪,等.遥感图像最大似然分类方法的EM改进算法[J].测绘学报,2002(3):234-239.
[7]朱建华,刘政凯,俞能海.一种多光谱遥感图象的自适应最小距离分类方法[J].中国图像图形学报,2000(1):24-27.
[8]张锦水,何春阳,潘耀忠,等.基于SVM的多源信息复合的高空间分辨率遥感数据分类研究[J].遥感学报,2006(1):49-57.
[9]FOODY G M,MATHUR A.A relative evaluation of multiclass image classification by support vector machines[J].IEEE Transactions on Geoscience and Remote Sensing,2004(6):1335-1343.
[10]KRIZHEVSKY A,SUTSKEVER I,HINTON G E.ImageNet classification with deep convolutional neural networks[J].Communications of the ACM,2017(6):84-90.
[11]LECUN Y,BOTTOU L.Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998(11):2278-2324.
[12]LONG J,SHELHAMER E,DARRELL T.Fully convolutional networks for semantic segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015(4):640-651.
[13]寧霄,赵鹏.基于U-Net卷积神经网络的年轮图像分割算法[J].生态学杂志,2019(5):1580-1588.
[14]RONNEBERGER O,FISCHER P,BROX T. U-Net:convolutional networks for biomedical image segmentation[M].New York:Springer Cham,2015:109-112.
[15]CHEN L C,PAPANDREOU G,KOKKINOS I,et al.DeepLab:semantic image segmentation with deep convolutional nets,atrous convolution,and fully connected CRFs[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2018(4):834-848.
[16]蒋怡,黄平,董秀春,等.基于Softmax分类器的小春作物种植空间信息提取[J].西南农业学报,2019(8):1880-1885.
[17]MATTHEW D Z.ADADELTA:an adaptive learning rate method[J/OL].Computer Science,2012[2021-07-10].https://www.oalib.com/paper/4035734#.YYzJEflT8YE.
3985501908239
