
Mask R-CNN 中特征不平衡问题的全局信息融合方法
2021-03-18 08:04周稻祥
计算机工程 2021年3期
文 韬,周稻祥,李 明
(太原理工大学大数据学院,山西晋中 030600)
0 概述
深度学习能够实现数据的分级特征表达且具有强大的视觉信息处理能力,而特征信息质量直接影响深度学习框架的判别精度,且现有判别模型多数采用顶层抽象特征或相邻层特征组合进行识别判断。由于关注局部信息而忽略全局信息的特征不平衡问题造成特征信息利用率较低,因此对全局均衡特征问题进行深入研究是机器视觉领域中的热点与难点。
目前,特征提取框架主要有单阶段与两阶段检测方法。其中,单阶段检测方法以基于深度学习的回归算法为主,仅需运行一次检测网络,速度较快但精度较低。文献[1]提出单发多盒探测器(Single Shot multi-box Detector,SSD)算法,该算法仅需单次运行卷积神经网络(Convolutional Neural Network,CNN)[2]即可得到结果,但存在识别准确率不高的问题。针对以上问题,文献[3-5]提出YOLO 系列算法,通过引入批量归一化(Batch Normalization,BN)[6]进一步提高网络识别速度与准确率。两阶段检测方法提取候选区域并对其相应区域进行分类。从整体上来看,两阶段检测算法的识别精度较高,但识别速度比单阶段检测方法低。文献[7]提出区域卷积神经网络(Regional-CNN,R-CNN),并利用选择搜索算法产生大量候选区域,进而对候选区域进行检测分类,但该算法的时间开销大,导致R-CNN 检测速度较慢。Fast R-CNN[8]通过权重共享方式实现网络的端到端训练,有效缩短网络时间开销,但是选择搜索算法的时间开销较大问题仍未解决。因此,Faster RCNN[9]使用区域建议网络替代选择搜索算法,有效减少产生候选区域的时间开销。Mask R-CNN[10]在Faster R-CNN 的基础上增加一个语义分割支路,实现多任务的训练与检测。
上述研究为现有平衡信息流中的特征不平衡问题提供了解决方案,但其均是基于局部或相邻特征层,并未考虑全局特征信息。因此,本文提出一种全局特征金字塔网络(Global Feature Pyramid Network,GFPN),该网络在不增加超参数的情况下,通过将不同层语义信息与各自特征相结合,从而形成包含各层语义信息的特征网络,以提高网络检测精度。
1 Mask R-CNN 框架
Mask R-CNN 框架如图1 所示,它是基于Faster R-CNN 框架增加一个与目标检测与回归并行的语义分割分支。前2 个分支沿用Faster R-CNN 方法,语义分割分支采用全卷积网络(Full Convolutional Network,FCN)[17]架构思想对感兴趣区域进行逐像素预测,该网络实现了单模型多任务的处理方式。
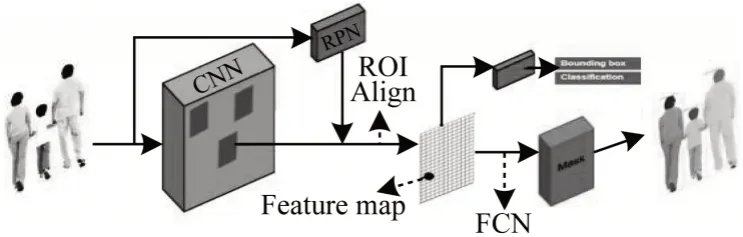
图1 Mask R-CNN 框架Fig.1 Mask R-CNN framework
在主干网络的特征提取器方面,Mask R-CNN 使用FPN+ResNet101 对特征进行提取,将提取的特征图输入区域建议网络中并产生不同尺度的锚点框,进而生成特征映射图。Mask R-CNN 应用改进的ROI Align 替代原来的ROI Pooling,有效缓解目标物体的边缘呈锯齿状。
Faster R-CNN 提出区域建议网络,用于寻找可能包含目标物体的预定义数量的区域,根据预先设定的不同比例、尺度的锚点产生不同候选框,并寻找最接近真实框的候选框。区域建议网络的产生使得生成候选区域的时间大幅缩短,降低由于产生候选区域而浪费的计算资源,使得网络可进一步接近实时检测。
ROI Align 的主要思想是取消量化,用双线性插值方法获取最终坐标,坐标采用浮点数值,将整个提取特征的过程简化为一个连续操作,解决量化过程中因量化计算而形成候选区域在原图实际偏差中较大的问题。
掩码表示是在Mask R-CNN 中增添一个用于实例分割的分支,并对每一个目标物体的不同个例建立一个m×m大小的二进制掩膜区分前后景,在分支中采用FCN 进行分割。与原始FCN 不同,该FCN 不进行分类,仅区分前后景,分类由另外一个分支来完成,每个分支任务不同,从而达到多任务效果,这也是网络集成程度较高的一种表现。
Mask R-CNN 使用的多任务损失函数如式(1)所示,该函数由分类损失函数、边界框损失函数与掩码损失函数3 个部分构成。
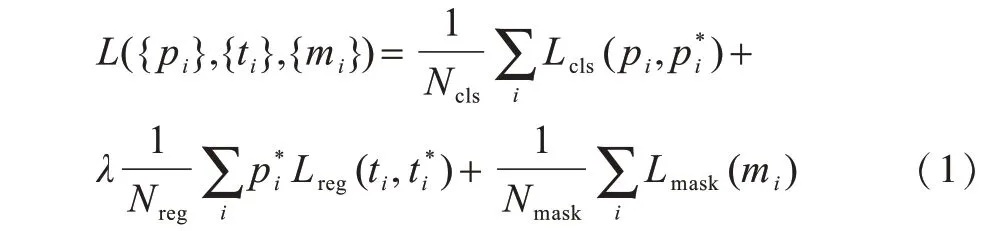
其中,Ncls表示分类类别的个数,Lcls表示分类损失函数,且其计算方法如式(2)所示:
1.2.4 划痕实验 OVCAR-8细胞以每孔2×105细胞接种于六孔板,待细胞长至完全融合后采用无菌200 μL枪头在中央划痕,PBS冲洗后采用倒置显微镜拍照;更换培养基后用11 μmol/L紫云英苷处理24 h,再次使用显微镜拍照,以0 μmol/为对照,以划痕宽度变化反应细胞迁移能力。
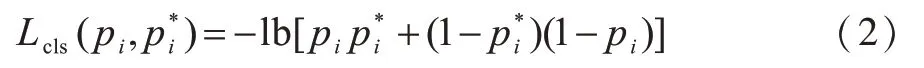
其中,pi表示物体被识别为目标的置信度是一个0、1 函数,当物体为正例时为1,否则为0,即只有当第i个框内物体为正例时,该锚点才对损失函数有贡献。
边界框回归损失函数如式(3)所示。除上述两类损失函数外,Mask R-CNN 中掩码分支使用的是平均二值交叉熵损失函数,具体如式(4)所示。
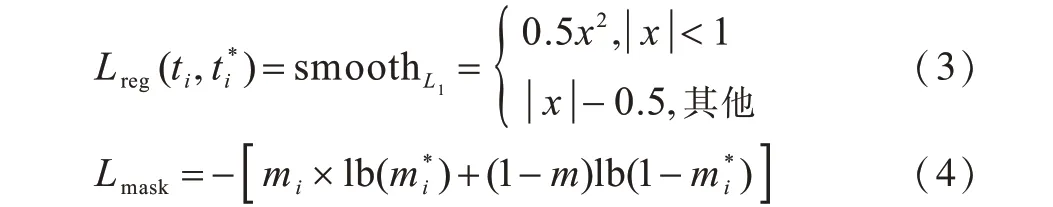
其中,mi表示物体被预测为目标的置信度表示第i个掩膜层中逐像素经过Sigmoid 函数后的输出,这样避免了类间竞争,将分类任务交给分类函数,mask 层只区分掩膜中的特定小类。
2 改进的FPN 特征提取网络
主干网络中的高层次特征具有更强的语义信息,浅层次特征具有更多的内容描述。近年来,在FPN 和PANet 中通过横向连接进行特征集合,进而促进目标检测的发展。受上述方法的启发,低层次和高层次信息在目标检测方面是互补的。研究表明,不同分辨率的综合特征具有均衡信息,但上述方法中的连接方式更多关注相邻的分辨率层,较少关注其他层级,使得部分特征信息在特征融合过程中存在丢失。
利用多层特征生成判别金字塔对检测至关重要。FPN 中通过自上而下的横向连接方式丰富浅层语义信息,且其仅利用邻域特征层信息,因此存在局限性。PANet 通过引入一个自下而上的路径来进一步增强低分辨率特征层的内容描述信息,它建立的额外路径虽然将底层内容描述与高层语义信息相融合,但是从总体特征层融合来看,仍未达到全局信息融合效果。不同于其他方法,ThunderNet 采用对应像素位叠加方式将后三层特征层相融合,该方法会引起以下2 个问题:1)底层具有纹理形态、对小物体敏感的内容描述未被利用;2)对应像素位叠加将会造成特征层厚度与计算量增大,且由于数值分布方差的增大造成模型效果较差。
综合上述方法,本文提出了GFPN,其网络框架如图2 所示。GFPN 通过依赖全局融合的语义特征来增强原始特征。金字塔中的每一个特征层都能从其他层中获得相同的信息,从而平衡信息流,使得特征更具辨别力。
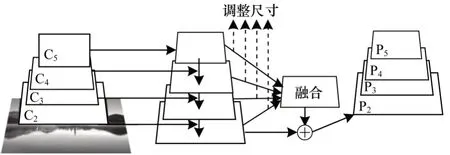
图2 GFPN 框架Fig.2 GFPN framework
与以往使用横向连接集成多级特征的方法不同,本文方法主要使用相同的深度集成融合语义特征来增强多分辨率特征,包含调整尺寸与融合2 个步骤。
在获取不同阶段的特征层时,阶段为i的特征层表示为Ci,在图像中,C2的分辨率最高,为了集成多级特性并同时保持其语义信息,本文将多级特征{C2,C3,C5}调整为同一分辨率(与C4相同,4 分辨率定义为M4×M4)对特征层进行重新排序,且按通道连接处理后,特征图输入后续的融合模块。融合模块如图3 所示,其由一个1×1×N卷积层与一个3×3×N的卷积层串行连接而成,目的在于对全局特征图进行融合,输出包含全局特征的特征图。Feature map大小为M4×M4×4N,其中,N为FPN 各个阶段输出的特征图的数量。1×1 卷积核的主要作用是将不同层信息融为一体,且对输入通道数进行降维(由输入的4N降为N)。此时,经过1×1 卷积过后的特征图变为M4×M4×N,之后连接的3×3×N的卷积核是为了消除由于上下采样、降维以及融合特征造成的特征混淆效应,使得邻域信息存在区别化,并保留细节信息,但不会改变特征图的层数,融合模块特征图输出仍为M4×M4×N。

图3 融合模块Fig.3 Fusion module
借鉴ResNet 中Skip Connection 思想,本文将经过融合模块处理后的特征图采用相同的反向过程对获得的特征进行重新标度,以增强原始特征,该过程中的每个原始特征图都将获得全局语义信息。
3 实验结果与分析
实验采用公开的COCO[18]数据集进行训练和预测,并采用相应的评价标准来衡量模型效果,评价标准包含AP(从0.5~0.95 步长为0.05 IoU 阈值下的平均值)、AP50和AP75(代表IoU 阈值为0.5 与0.75 下的AP 指标)。APS、APM、APL分别代表小(面积<322)、中(322<面积<962)、大(面积>962)3 种面积(面积是分割掩码中的像素数量)测量下的平均准确率值。Precision 与mAP 的计算公式为:

其中,TP 表示将正例分对的样例,FP 表示将正例分错的样例,N表示所有样本个数。
3.1 实验环境及参数设置
本文显卡采用Tesla P100 16 GB,使用Nvidia 图像处理驱动CUDA9.0 以及CUDNN 7.0.0 优化神经网络计算,使用的深度学习框架为Pytorch 1.1,运行环境为Python3.6,模型采用ImageNet[19]预训练权重模型。采用自适应梯度下降法调整学习率,且初始学习率设置为0.01。针对训练集设计40 000 epoch 在4 块GPU 上完成训练。模型训练损失函数如图4 所示。从图4 可以看出,算法在迭代30 000 次后开始收敛。
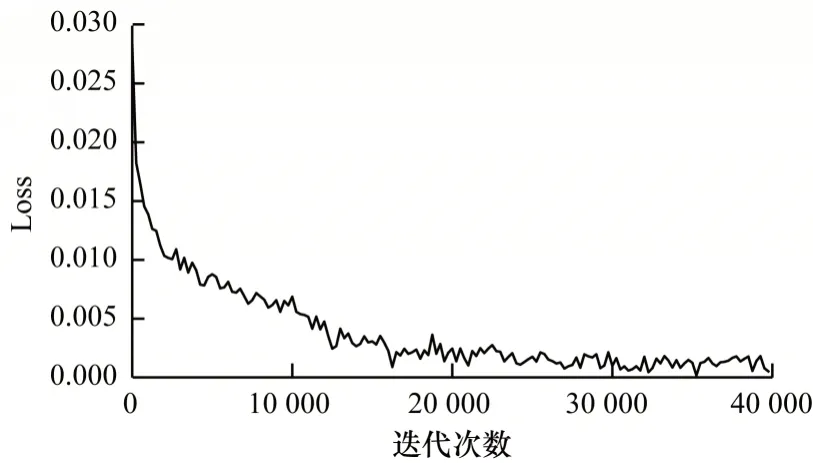
图4 训练损失函数图Fig.4 Graph of training loss function
3.2 同特征提取器的不同检测框架实验
为验证GFPN 对相同主体网络框架的提升效果,本文对基于GFPN 的Mask R-CNN 与其他主流检测网络进行对比,结果如表1 与图5 所示。从表1可以看出:相较于其他主流检测网络,融合全局特征层后的GFPN 在检测准确率方面有显著提升;与单阶段框架(SSD512,RetinaNet)相比,采用GFPN的Mask R-CNN 在AP 数值上提升了3~10 个百分点,在大、中、小3 种面积AP 指标上分别有3~8 个百分点、5~13 个百分点、4~15 个百分点的提升,尤其在小面积上的提升幅度较大;与双阶段(Libra R-CNN,Faster R-CNN w FPN)相比,采用GFPN 的Mask RCNN 在AP 数值上提升了2~6 个百分点,在大、中、小3 种面积上AP 指标分别有7~10 个百分点、4~8 个百分点、3~7 个百分点的提升;通过上述数值分析可得出,GFPN 可有效提升Mask R-CNN 的识别精度,且在不同方法框架对比下有明显优势。研究表明,在目标检测算法中,特征层不平衡现象对检测精度的影响是显著的,而全局特征融合实验结论也从实验角度验证了全局特征融合这一理论的可行性。
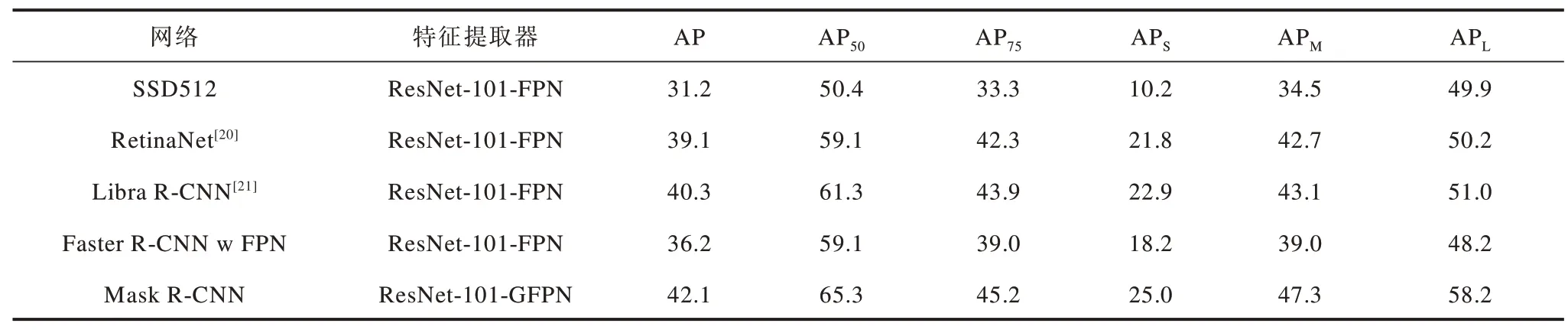
表1 本文网络与其他主流检测网络的识别精度对比Table 1 Comparison of recognition accuracy between the proposed network and other mainstream detection networks %

图5 5 种网络的实验效果对比Fig.5 Comparison of the experimental effect of five networks
3.3 不同特征提取器的同检测框架实验
实验在保证检测框架相同情况下,验证GFPN对模型识别精度的影响。本文选定检测框架为Mask R-CNN,采用不同规模的特征提取器进行实验,结果如表2 所示。从表2 可以看出,针对ResNet-101 而言,相比FPN,GFPN 在APS、APM、APL、总体AP上分别提高了4.9、6.2、8.0、3.9 个百分点,这说明GFPN 可有效提升网络识别精度,通过控制变量可显著提高GFPN 对网络的识别效果。
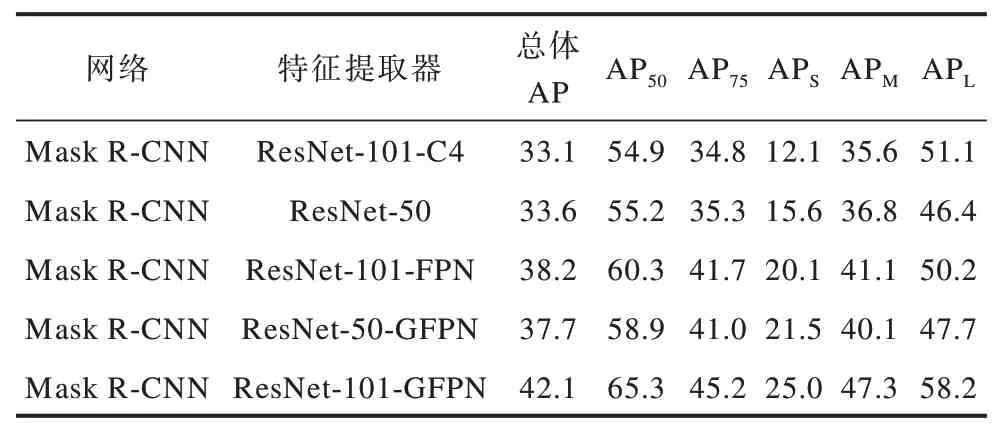
表2 不同特征提取器的识别精度对比Table 2 Comparison of recognition accuracy of different feature extractors%
3.4 时间对比分析
实验本文网络与其他主流检测网络在COCO 测试集的检测时间进行对比,结果如表3 所示。从表3 可以看出:与FPN 相比,GFPN 在未引入超参数的情况下增添了融合模块与浮点计算量;与Mask R-CNN ResNet-101-FPN 相比,ResNet-101-GFPN 的检测时间增加0.112 s;与Mask R-CNN ResNet-50-FPN 相比,ResNet-50-GFPN 的检测时间增加0.08 s。因此,从总体上来看,本文在未增加超参数的情况下,通过引入GFPN 使得网络仍能达到实时检测的效果。
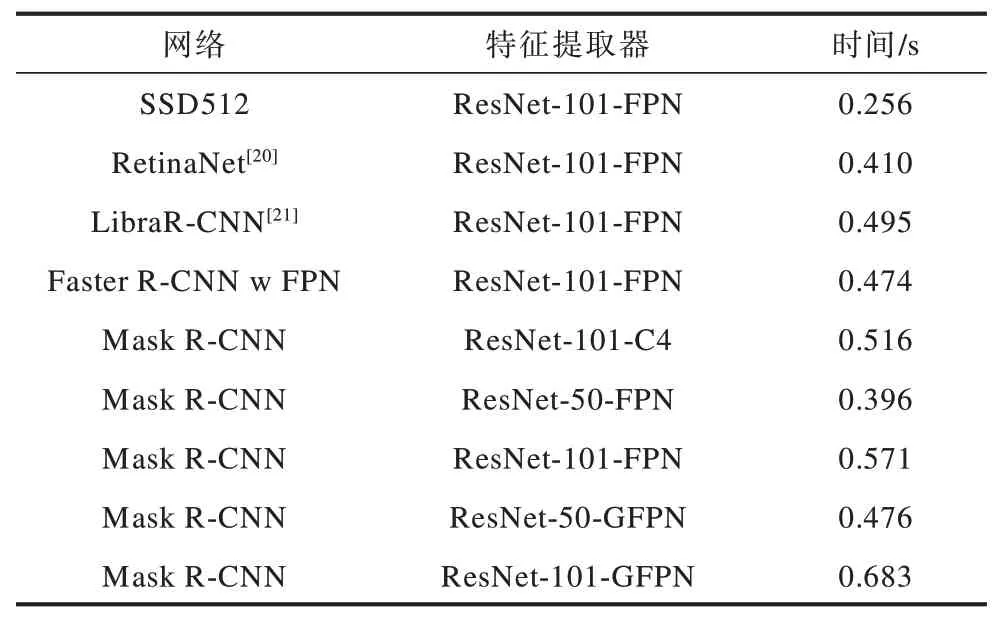
表3 本文网络与其他主流检测网络的时间对比Table 3 Comparison of time between the proposed network and other mainstream detection networks
4 结束语
本文针对特征不平衡问题,提出基于全局特征融合的GFPN,采用调整尺寸与融合2 个模块处理FPN 框架中不同分辨率特征层的特征,从而得到全局特征融合信息,以增强原始特征。实验结果表明,GFPN 可有效提升目标检测网络的识别效率,且在未引入超参数的情况下,不仅可有效改善识别精度,而且检测速度接近FPN。下一步将在不改变模型结构及不引入其他超参数的情况下,采用深度可分离卷积对Mask R-CNN+GFPN 进行轻量化处理,以进一步提高检测速度。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
金桥(2018年4期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
中国卫生(2014年5期)2014-11-10
