
基于动态行为和机器学习的恶意代码检测方法
2021-03-18 08:03陈佳捷彭伯庄吴佩泽
计算机工程 2021年3期
陈佳捷,彭伯庄,吴佩泽
(中国南方电网数字电网研究院有限公司,广州 510000)
0 概述
互联网的快速崛起给网络空间带来新的发展机遇,但同时也带来越来越严重的网络安全问题。高速互联网在实现设备与服务互连的同时,也为网络黑客从海外实施远程匿名攻击提供了便捷途径,在目前网络安全犯罪成本较低的情况下,黑客在各类社交网络传播恶意代码的频率逐年升高。恶意代码由攻击者创建旨在损害网络系统安全性或泄露被攻击者隐私信息,其包括蠕虫病毒、特洛伊木马等常见的计算机病毒,以及间谍软件、广告软件和行为记录软件等恶意软件。目前,恶意代码的数量正在呈爆发性增长。根据卡巴斯基报告[1],2019 年第一季度,网站META 区域受到加密挖掘恶意软件、网络钓鱼和勒索软件等持续攻击,该季度恶意软件攻击超过1.5亿次,平均每天达到160万次,相较2018年第一季度增长108%。
恶意代码的检测方法主要包括基于签名的检测方法、启发式检测方法以及行为式检测方法等,其中基于签名的检测方法应用最为广泛。该方法主要基于模式匹配的思想,为每种已知恶意代码产生一个唯一的签名特征标记并创建恶意代码库,通过将未知代码的签名特征与恶意代码库进行对比来识别恶意代码。其检测速度较快且准确率高,但对于未出现过的病毒无法进行检测。此外,大量恶意软件为避免被查杀进行加壳和混淆处理,增大了其检测与识别难度。
针对上述问题,本文提出一种结合动态行为和机器学习的恶意代码检测方法。建立自动化分析Cuckoo 沙箱[2]解析恶意代码网络日志以获取其行为信息,将Cuckoo 沙箱和改进DynamoRIO 系统相结合作为虚拟环境,提取恶意代码样本应用程序接口(Application Programming Interface,API)调用序列特征以全面获取其文件操作、进程操作和注册表操作等行为信息,并基于双向门循环单元(Bidirectional Gated Recurrent Unit,BGRU)网络构建恶意代码检测模型。
1 相关工作
对恶意代码的有效检测是保证网络空间安全的重要手段,现有恶意代码检测方法主要包括基于静态的检测方法和基于动态的检测方法。在基于静态的检测方法中,利用签名的恶意代码检测方法应用最广泛,其主要采用预定义的方式进行防护,虽然可识别通用应用程序中的恶意软件,但需要对签名数据库进行定期维护。目前,基于机器学习的恶意代码检测方法还使用了操作码特征[3]与二进制文件特征。文献[4]基于操作码序列以可执行文件向量来表示恶意软件,并采用机器学习算法检测恶意代码。文献[5]基于n-gram 和SVDD 技术提出一种未知恶意代码检测方法SSPV-SVDD,其对单个恶意代码家族的识别准确率达到97%。文献[6]提出一种基于可执行文件加壳算法的分类方法来检测恶意代码,先缩放给定可执行文件的熵值,将特定存储位置的熵值转换为符号表示,再使用朴素贝叶斯和支持向量机检测加壳算法并对符号分布进行分类,该方法的准确率和查全率分别达到95.35%和95.83%。文献[7-8]采用可视化方法将恶意代码转换为图像并使用神经网络进行训练,成功对恶意代码进行分类。
静态二进制检测方法在很大程度上受到混淆技术限制,虽然简单混淆的代码在一定程度上能被检测,但现有检测方法在处理混淆代码时存在NP 难题[9]。由于动态检测方法能有效检测恶意样本的行为信息,因此对于恶意代码动态检测技术的研究受到广泛关注。文献[10]提出一种恶意软件检测算法,利用目标可执行文件的动态收集所得指令跟踪记录来构建子图表示马尔可夫链,创建指令跟踪图间的相似度矩阵,并将其发送到支持向量机进行分类。文献[11]采用动态指令序列n-gram 提取特征,利用K 均值算法与EM 聚类算法对恶意代码进行分类,实验结果表明EM 聚类算法优于K 均值算法,且两种算法的分类精度均超过90%。
网络行为是影响恶意样本动态行为的重要因素。目前基于网络行为的恶意代码检测主要采用传统方法,即由人工设计特征字段,通过频数统计方式提取特征,并构建传统机器学习模型或卷积神经网络(Convolutional Neural Network,CNN)模型进行分类。文献[12]提出端到端的监督学习模型,从不同协议和网络流量层中提取多类特征,通过计算得到特征向量来检测恶意软件。除此之外,文献[13]将流量数据视为图像并提出一种基于CNN 的恶意软件流量分类方法,将表示学习方法应用于恶意软件流量分类。本文基于API 调用序列及网络行为来提取特征,采用词嵌入方式将网络流量转换为语句向量,并构建BGRU 深度学习模型对恶意代码进行检测。
2 本文恶意代码检测方法
2.1 方法流程
本文提出一种结合动态行为和机器学习的恶意代码检测方法,其流程如图1 所示。为全面记录恶意代码的行为信息,先构建Cuckoo 沙箱和DynamoRIO 系统获取动态行为,再针对恶意代码样本的API 调用序列与网络行为提取并融合特征,得到对应的特征向量并以此训练BGRU 分类模型,从而实现对恶意代码的检测。
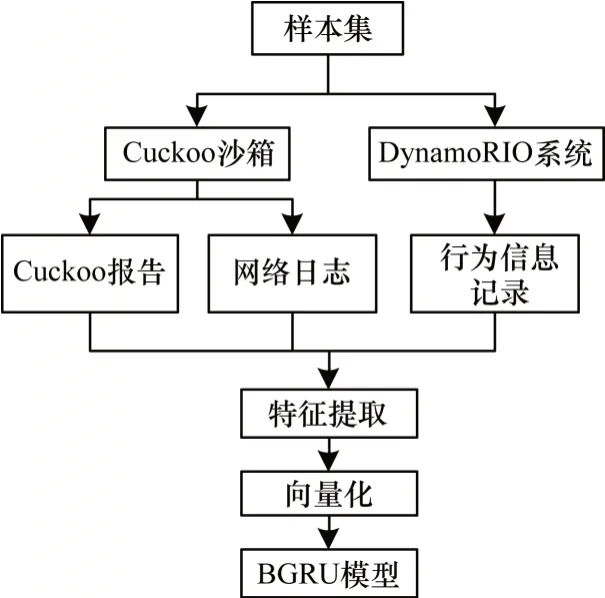
图1 本文方法的流程Fig.1 Procedure of the proposed method
2.2 动态行为获取
安全分析人员利用动态沙箱技术可从实际行为中分析并检测出恶意代码,并有效降低误报率。CWSandbox、Anubis、BitBlaze、Norman 以及ThreatExpert等分析系统利用动态插桩技术实现了对恶意样本行为的有效监控。因此,本文结合沙箱技术与动态插桩技术分析记录样本的行为信息。
本文采用Cuckoo 沙箱技术和DynamoRIO 系统动态二进制插桩工具来获得样本行为信息。Cuckoo沙箱和DynamoRIO 系统获取恶意代码样本API 序列信息的机制不同。Cuckoo 沙箱技术是一种封闭式沙箱技术,Cuckoo 沙箱可将二进制样本置于虚拟环境中自动化运行并记录其API 序列信息与网络通信信息。为解决恶意代码的反调试问题,本文对Cuckoo 沙箱源码的vmdetect.yar 规则进行改进,从而获取API 序列信息及网络通信信息,同时避免恶意代码检测出虚拟环境而停止运行。DynamoRIO 系统是一种有效的二进制插桩工具,其较Pin 运行速度更快。本文以基本块为单位,对各类指令进行分析,并基于回调机制对DynamoRIO 系统进行完善,使其能获取完整的API 序列调用信息,通过将Cuckoo 沙箱和DynamoRIO 系统相结合,以更全面地获取恶意代码样本行为信息。
2.2.1 Cuckoo 沙箱
Cuckoo 沙箱是Google 公司开发的一个开源的自动化恶意代码分析系统,可分析office 文档、pdf 文件、可执行文件以及电子邮件等多种文件类型,能用于Windows、Linux 和Android 等系统的恶意软件检测,其结构如图2 所示。Cuckoo 沙箱由一个处于核心位置的主机(中央管理软件)和多个Guest 计算机(用于分析的虚拟或物理计算机)组成。主机是沙箱运行的核心组件,主要负责样本执行与分析过程的调度以及Guest 计算机的管理。Guest 计算机处于隔离环境,每次样本分析都会从一个处于纯净状态的快照开始,可保证恶意代码样本被安全地执行与分析,从而确保分析的正确性,避免多个分析之间的相互干扰。
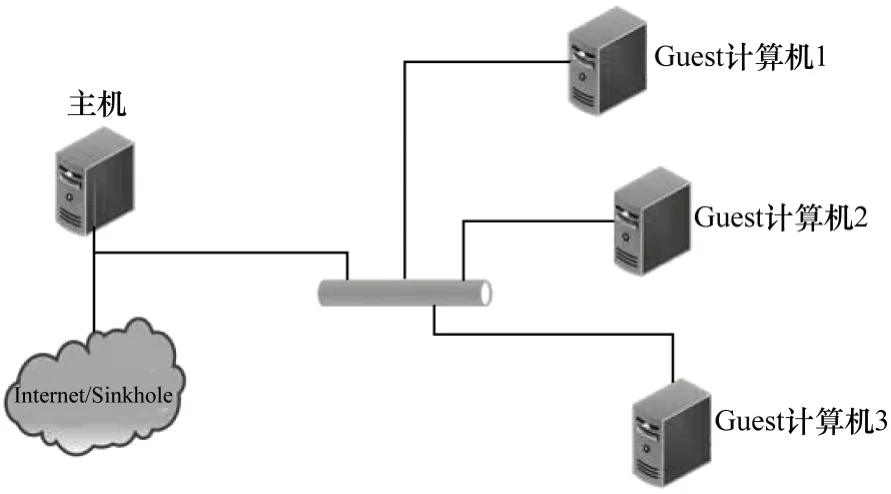
图2 Cuckoo 沙箱结构Fig.2 Cuckoo sandbox structure
采用Cuckoo 沙箱运行恶意代码样本后,可获得以下信息:1)恶意代码内部函数与Windows API 调用跟踪信息(API 日志);2)恶意代码执行期间文件创建、删除与下载的操作信息;3)以PCAP 形式对恶意代码网络行为的跟踪信息(网络日志);4)恶意代码样本的静态数据以及释放文件的行为信息;5)程序执行期间桌面操作截图;6)文件操作、注册表操作、互斥操作和服务操作等系统操作信息;7)机器全内存空间的转储信息。
恶意代码通常具有反调试功能,为有效记录恶意代码样本的行为信息,本文对Cuckoo 沙箱源码的vmdetect.yar 规则文件改进如下:

由Cuckoo 沙箱可得到存储格式为json 的恶意代码样本行为信息报告。此外,为进一步提取样本动态特征,本文基于FakeNet 模拟网络环境,将Cuckoo 沙箱记录的网络日志以pcap 格式进行存储,作为恶意代码样本的网络行为报告。
2.2.2 DynamoRIO 系统
由于目前恶意代码大部分已采用抗检测技术,当检测到虚拟环境或沙箱时会隐藏自身恶意行为,或者采用反Hook 及绕过API 层直接调用系统的方式,导致采用动态检测方法分析API 记录时出现漏报或误报。
DynamoRIO[14]是一种代码运行控制系统,该系统高效透明且控制全面,能有效监控应用程序中每个已执行的指令。DynamoRIO 系统也是一个跨平台的二进制检测平台,可适用于移植性程序。由于DynamoRIO 系统采用回调机制处理二进制可执行代码,因此通过设置回调,可利用DynamoRIO 系统轻松操控目标程序的二进制可执行代码。
本文对DynamoRIO 系统的drstrace 和drltrace 进行改进,进而获取二进制程序的行为信息,具体流程如图3 所示。改进后的DynamoRIO 系统以基本块为单位分析各指令,并对调用指令类型进行判断。如果属于系统调用,则分别采用drsys_syscall_name()函数和drsys_iterate_args()函数获取系统调用的名称与参数信息;如果属于API 调用,则分别采用dr_module_preferred_name()函数和drwrap_get_arg()函数获取API 调用的名称与参数信息。参数按照类型分为直接参数和间接参数两种。直接参数可从函数的栈中直接获取,例如立即数。间接参数需要根据函数栈中的地址间接寻址,从内存读取参数信息。本文将DynamoRIO 系统作为提取恶意代码样本行为信息的补充实验环境,并使用FakeNet 模拟网络环境。
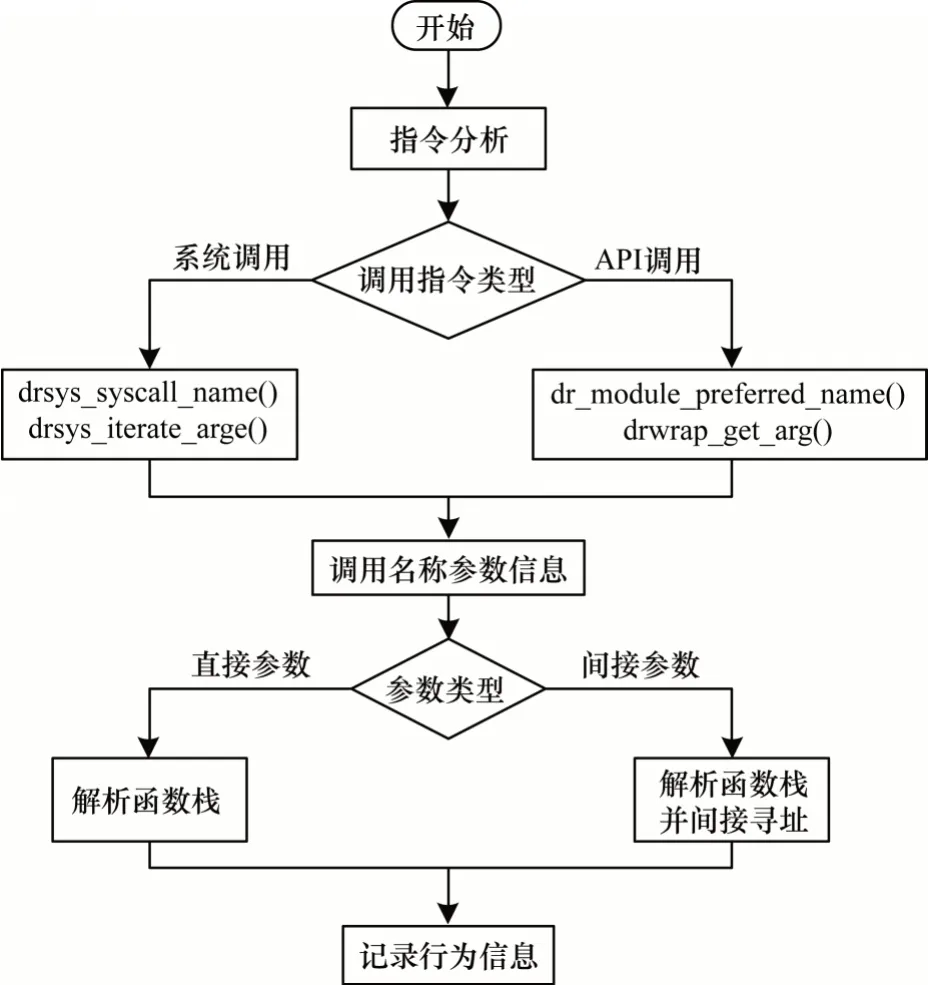
图3 DynamoRIO 系统操作流程Fig.3 Operation procedure of DynamoRIO system
2.3 特征提取与向量化
本节对上文中得到的行为信息进行特征提取并向量化(将API 序列转换为数字向量,用于分类模型输入)。恶意代码样本的行为信息表现在文件、进程、注册表以及网络等方面。而API 调用序列可表征恶意代码样本的文件操作、进程操作和注册表操作等。例如,修改注册表通常需要通过RegOpenKey Ex、RegSetValue、RegCloseKey 3 个API 调用组合来实现。因此,可利用这种API 调用组合来提取特征,从而得到恶意代码样本的文件操作、进程操作和注册表操作等信息。此外,还可通过Cuckoo 沙箱获取恶意代码样本的网络日志,进而得到其网络行为信息。为全面描述恶意代码样本的行为信息,本文从API调用序列和网络行为两方面提取特征。
2.3.1 API 调用序列
本文基于API 调用序列执行特征向量化。为了更有效地记录恶意代码样本的行为记录,在向量化之前,先对Cuckoo 沙箱报告进行分析。Cuckoo 沙箱的分析日志以json 格式存储,并通过调用来提取进程记录的顺序信息。在Cuckoo 沙箱报告中,API 调用序列存储于behavior/processes/calls 字段下,可根据processtree 字段绘制进程调用树,并结合processes/calls字段解析得到Cuckoo 沙箱的API 执行序列。然后对DynamoRIO 系统报告进行分析,从中提取API 信息,并将此结果与Cuckoo 沙箱的结果进行合并。
程序在执行过程中会多次循环调用相同的API序列以执行同一命令。由于本文目标是通过提取API 调用序列来检测恶意代码,因此无需大量重复的API 调用。基于此,本文去掉了冗余的API 调用序列,然后将其向量化。图4 为恶意代码样本报告中API提取示例(md5:ffff3f7dad938ac9c8cb2d2d4e25a310)。恶意代码样本根据calls 中的API 提取序列信息,并重复调用GetFileType(见方框处)。因此,本文将该冗余API 信息删除。

图4 恶意代码样本报告中API 提取示例Fig.4 Examples of API extraction in malicious code sample report
本文使用Word2vec[15]将API 序列全部转换为数字向量。Word2Vec 由两层神经网络组成,是Google公司于2013 年所推出用于构建单词向量的工具。单词向量是在文档中供计算机处理的单词数值向量。将文本语料库输入Word2Vec 中,输出即为文本语料库中每个单词的向量。与TF-IDF 等传统单词向量构造方法相比,Word2Vec 构造的单词向量包含更丰富的语义信息(具有相似语义的单词,其词向量表现出高度的相似性)。本文通过Word2Vec 将API序列转换为固定长度的向量,并将向量长度设置为50。
2.3.2 网络行为信息
为解析网络日志数据包pcap 文件,提取其特征并将其向量化后输入神经网络,本文基于文本分类的思想(不考虑文档整体,以文档中段落和语句为处理对象),对网络流量进行处理。
首先对pcap 文件进行解析,将其中的数据包作为处理对象,并根据每个数据包构造关键语句(特征向量),语句中每个单词均为数据包中的一个字段。然后利用词嵌入方法[16]从该语句中提取语义和语法特征。由于段落的语义通常可由关键语句决定,因此本文选择语句(数据包)的语义,而不是整个段落(网络流)的语义。此外,每个数据包固有的字段顺序起到类似语法规则的作用,这些语法规则对于构建恶意数据流量(基于签名的检测)或构建数据良性流量(异常检测)的语句模式起到决定性作用。值得注意的是,根据单个或多个数据包的行为和特征可以判断是否为恶意数据流量,因此这种基于数据包的语句特征提取方式可用于恶意代码样本的判定。
通常,每个数据包的字段为1 个字节的数据包头、数据包头的1 个字段或者有效载荷的数据块。本文将数据包头中的字段视为1 个单词,由于数据包中字段长度不同,因此得到的单词长度也不同。将数据包中字段长度固定为n个字节,如果数据包中字段长度小于n个字节,则将其用零填充,具体如图5 所示。由于大部分TCP 数据包含有14 个字节的MAC 报头、20 个字节的IP 报头和20 个字节的TCP报头[17],因此本文设置n=54。
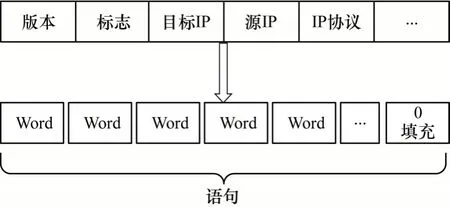
图5 数据流量向量化示意图Fig.5 Schematic diagram of data flow vectorization
2.4 分类模型
由于API 调用序列及网络流量中数据包信息均具有前后关系,因此经过特征提取与向量化处理后,特征向量也具有前后依赖关系,这与人脑思维类似。例如,人们阅读文章时能在理解前文所阅读单词的基础上理解当前阅读的单词。循环神经网络[18](Recurrent Neural Network,RNN)具有递归结构,可以连续保留先前的信息,但是随着时间的延长,其会失去保存与处理信息的能力,且存在梯度消失的问题。对此,研究人员提出RNN 的特殊选择方法,其中最具代表性的是LSTM[19]和GRU[20],这两种方法均可通过门控机制获取长期的依赖关系。GRU 结构更简单且计算复杂度更低,其运行速度要快于LSTM[21]。
具体而言,两个关键模块构成基于GRU 的网络。一个模块是包含第j个GRU 隐藏单元且具有相应权重矩阵Wr和Ur的复位门。当复位门关闭(=0)时,先前状态ht-1被忽略,当前隐藏状态ht仅由当前输入xt来定义,这表示可能丢弃全部对当前隐藏状态无用的信息。另一个模块是更新门其被设计为利用相应权重矩阵Wz和Uz来调节由先前状态ht-1传输到当前隐藏状态ht的信息的传输权重。为基于先前状态ht-1和当前输入xt的候选激活态,其相应的权重矩阵为Wh和Uh。
第j个GRU 隐藏单元的整个数据流量计算公式如下所示:
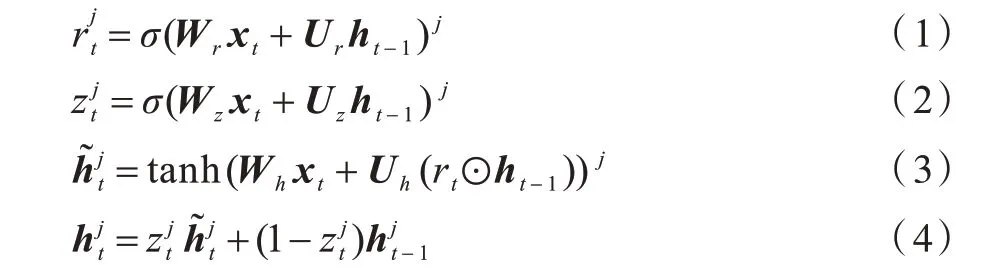
其中:σ(·)为sigmoid 激活函数,本文中σ(x)=(x∈ℝ);tanh(·)为双曲正切函数,本文中tanh(x)=(x∈ℝ);⊙为Hadamard 乘积,也称逐元素乘积,表示两个矩阵相应元素的乘积。
在提取单词的语义特征时,未来信息与语句S中的历史信息同样重要,而上述基于正序的体系结构仅考虑了历史信息。对此,本文使用BGRU 网络,该网络引入一个未来层解决上述问题,其结构如图6所示。在未来层中,数据的输入顺序与输入层相反。BGRU 网络使用两个隐藏层分别从过去和未来提取信息,这两个隐藏层连接到同一个输出层,BGRU 网络充分利用了输入序列的上下文信息。
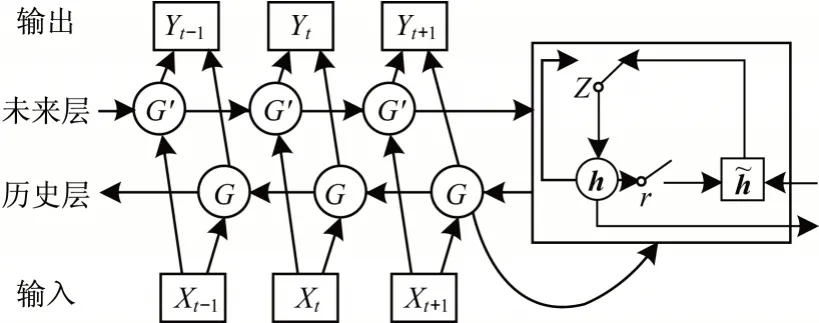
图6 BGRU 网络结构Fig.6 BGRU network structure
本文分类模型的结构如图7 所示。其中,左GRU 层通过馈送语句S的正序来学习当前输入xt的历史信息,而右GRU 层通过馈送语句S的逆序来获得当前输入xt的未来信息。

图7 本文分类网络结构Fig.7 Structure of the proposed classification network
语句S第i个单词最终输出的表达式如下:

本文通过RNN 模型分别学习到API_Cuckoo(从Cuckoo 沙箱中提取的API)、API_DynamoRIO(从DynamoRIO 系统提取的API)和Net_pcap(网络流量pcap 包)3 种序列特征。由于这3 种序列特征均具有前后依赖的关系,因此本文采用双向的BGRU 网络作为分类网络,其可以利用输入序列的上下文信息更好地学习序列特征的依赖关系。在图7 中,先将序列按前向顺序输入GRU 层得到前向输入隐藏层信息h_forward,再将序列按后向顺序输入GRU 层得到后向输入隐藏层信息h_backward,然后将两者结合后作为BGRU 的输出。通过BGRU 网络,本文学习到API_Cuckoo、API_DynamoRIO 和Net_pcap 3 种序列特征,然后通过Concat 拼接输出向量,最终基于全连接层和Softmax 层得到检测结果。
3 实验与结果分析
3.1 实验准备
本文结合Cuckoo 沙箱和改进DynamoRIO 系统作为虚拟环境,对恶意代码样本的API 调用序列及网络行为特征进行提取与融合,以全面获取恶意代码文本的行为信息。为构建神经网络模型,选择系统的开发框架为pytorch[22],开发语言为python 3.6。实验环境为Ubuntu 18.04.2 LTS 操作系统,NVIDIA GeForce GTX 1080 GPU 和8 GB 内存。
本文构建包含大量样本的数据集以对所提方法进行有效评估,数据集所用恶意代码样本来自恶意软件样本的公开存储库VirusShare,良性应用程序样本来自经过安全检查的Windows 7 操作系统平台,包括常见的exe、DLL 等PE 格式文件。数据集共有18 153 个样本,其中包含12 170 个恶意代码样本和5 983 个良性应用程序样本。
为确保恶意代码样本标签的可信度,通过在线病毒扫描网站Virustotal 将恶意代码样本与反病毒引擎的标签进行标记(在Virustotal 中通过调用相关API 进行样本上传,每个样本平均被58 个反病毒引擎扫描)。为保证样本标签的准确性,以大量反病毒引擎的扫描结果为筛选依据,根据恶意性判定频率筛选恶意代码样本。本文实验频率阈值设定为0.8,仅保留超过80%反病毒引擎判定为恶意性的恶意样本,良性应用程序样本均完全通过Virustotal 网站的恶意性检测。
3.2 度量指标
在本文实验中,使用准确率(A)、精确率(P)、召回率(R)以及F1 值作为分类模型的性能评价指标。在分类问题中,度量指标的混淆矩阵由TP、TN、FP和FN 4 个值构成,其中:TP 表示将正类样本预测为正的数量;TN 表示将负类样本预测为负的数量;FP 表示将负类样本预测为正的数量;FN 表示将正类样本预测为负的数量。
4)F1 值。精确率与召回率之间常出现矛盾,F1 值是两者的综合,被定义为精确率与召回率的调和平均值,即当参数α为1 时,即为F1 值的常见形式,即F1 值越高说明模型分类性能越好。
3.3 结果分析
为评估本文方法的有效性以及参数设置对实验结果的影响,以下分别进行隐含层节点数的选择实验、消融实验以及模型对比实验。
3.3.1 隐含层节点数的选择实验
BGRU 较BLSTM 结构更简单且计算复杂度更低,其隐含层节点数对模型的复杂度和分类效果有一定的影响。本文基于样本API 调用序列与网络行为的融合特征对模型进行训练,并通过选择实验得到隐含层节点数分别为50、100、150 和200 时本文模型的准确率、精确率、召回率以及F1 值,结果如表1所示。可以看出,当隐层结点数为100 时,模型各指标均为最优,其原因是当隐层结点数过少时,网络不具有必要的学习能力和信息处理能力。当隐层结点数过多时,网络结构的复杂性大幅增加,网络在学习过程中更易陷入局部极小点且学习速度减慢。因此,本文设置隐含层节点为100。
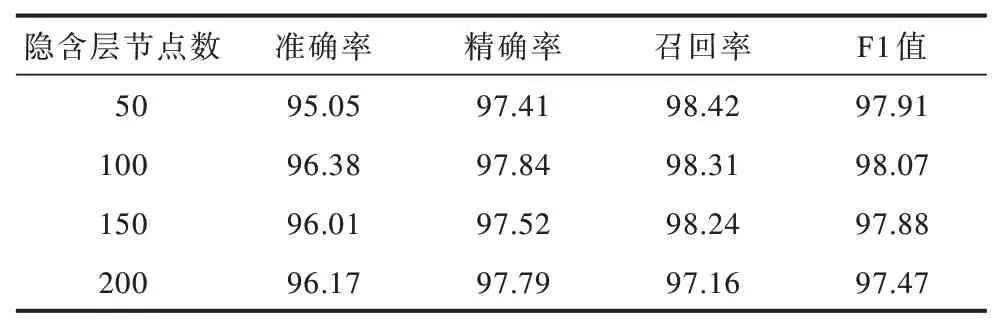
表1 不同隐含层节点数的选择实验结果Table 1 Results of selection experiment with different hidden layer nodes%
3.3.2 消融实验
为进一步探究不同序列特征对模型分类性能的影响,本文基于BGRU 模型进行消融实验,实验结果如表2 所示。可以看出,单独基于Cuckoo 沙箱得到的API 调用序列(API_Cuckoo)的分类效果比单独基于DynamoRIO 系统得到的API 调用序列(API_DynamoRIO)更好,将两者结合后,所得API_CkDR分类效果更好。将序列特征融入后形成API_Net_all,尽管准确率低于API_CkDR,但其精确率、召回率和F1 分数都要高于API_CkDR。
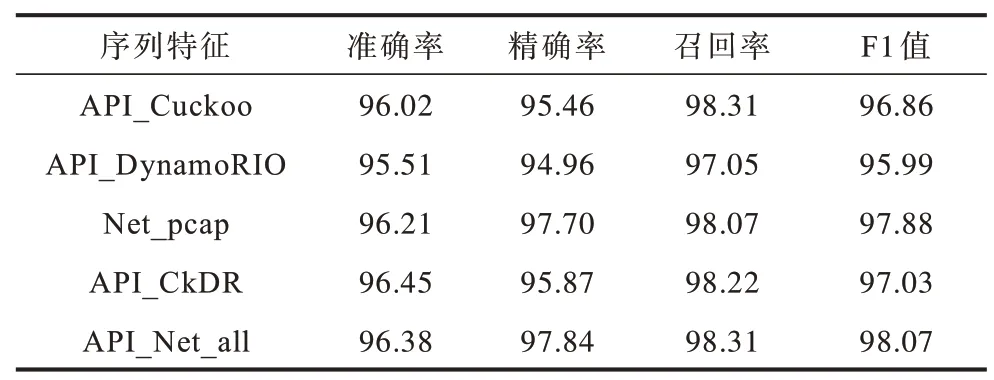
表2 消融实验结果Table 2 Ablation experiment results%
由上述分析可知,基于DynamoRIO 的API 调用序列对Cuckoo 沙箱具有一定的补充作用,其原因是目前恶意代码大部分采用了抗检测技术,当检测到虚拟环境或沙箱时会隐藏恶意行为,从而导致Cuckoo 沙箱的API 记录出现漏报或误报的情况。本文通过改进DynamoRIO 系统,能更准确和全面地获取二进制程序的行为信息,因此,将API_Cuckoo 和API_DynamoRIO结合得到的API_CkDR 分类效果更好。
上述序列特征的融入,从网络数据流量方面对模型特征进行了有效补充。表2 中精确率的有效提升说明模型对恶意代码样本检测能力得到加强。此外,F1 值的提升说明序列特征融入后,模型具有更好的分类性能。由消融实验结果可知,本文所提的API_cuckoo、API_DynamoRIO 和Net_pcap 对分类模型有正作用,均为有效特征。
3.3.3 模型对比实验
由上述实验结果可知,本文提出的API_Cuckoo、API_DynamoRIO 和Net_pcap 均为有效特征。由于这些网络特征具有前后依赖关系,而API 及网络流量的恶意行为取决于特征序列片段的上下文,且上下文在自然语言处理中至关重要,因此为了更好地学习到上述网络特征的内在关系,本文基于自然处理领域深度学习的研究结果,选择RNN 模型分别对各序列特征进行学习,以提取其内在信息。
为进一步验证不同模型的检测效果,本文基于Cuckoo 沙箱和改进DynamoRIO 系统相结合的虚拟环境,设计并建立单向的LSTM、GRU 和双向的BLSTM、BGRU 4 种RNN 模型进行对比。针对API_Cuckoo、API_DynamoRIO 和Net_pcap 特征长度不一致的问题,通过本文模型提取出各RNN 隐藏层中的向量来表示特征的内在信息,可将不等长的特征转化为等长的向量。因此,本文采用4 种RNN 模型进行实验,以探究不同RNN 结构及单双方向的神经网络对实验结果的影响,实验结果如表3 所示。
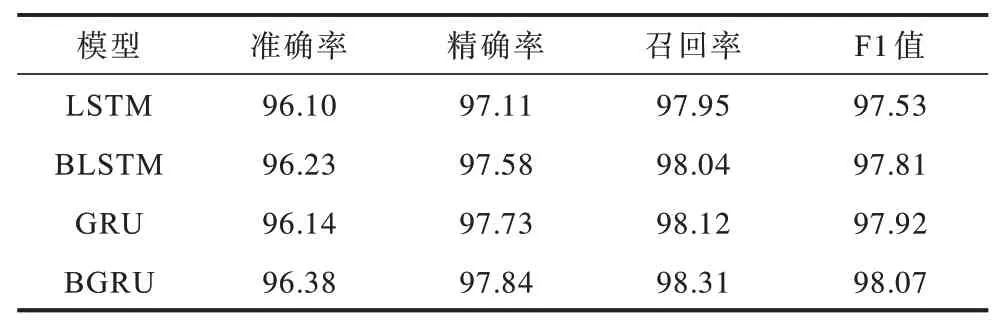
表3 不同模型对比实验结果Table 3 Comparison experiment results of different models%
由表3 可以看出,双向神经网络模型的检测性能均优于单向神经网络模型,例如BLSTM 优于LSTM,BGRU 优于GRU。这是因为在提取单词语义特征时,未来信息与历史信息同样重要,而基于正序体系结构的LSTM 和GRU 仅考虑了历史信息。双向神经网络模型引入未来层来解决该问题,利用两个隐藏层从过去和未来提取信息,并将这两个隐藏层连接到同一输出层。由于双向神经网络模型能充分利用输入序列的上下文信息,同时考虑到历史信息和未来信息,因此其检测性能更好。由表3 还可以看出,BGRU 的准确率最高,达到96.38%,其与BLSTM 实验结果接近,但训练速度是BLSTM 的1.26 倍,BGRU 准确率较GRU 更高。由上述结果可知,双向深度学习模型对于恶意代码的检测性能要优于单向深度学习模型。
此外,本文将BGRU 和BLSTM 的时间复杂度进行对比,发现BGRU 收敛速度较BLSTM 更快。这是因为GRU 参数较少,其更易收敛,且GRU 的结构较LSTM 更简单,因此BGRU 的训练与测试时间均较BLSTM 更短。从结构上来看,GRU 只有2 个门(update 和reset),LSTM 有3 个门(forget,input 和output),GRU 直接将隐藏状态传给下一个单元,而LSTM 则用记忆单元把隐藏状态包装起来。实际上,GRU 和LSTM 的性能在很多分类任务中较接近,但在本文实验中,由于引入更复杂的双向网络模型,GRU 的高速收敛使得模型训练效果更优,因此GRU的检测性能要略优于LSTM。
4 结束语
本文提出一种结合动态行为和机器学习的恶意代码检测方法。搭建Cuckoo 沙箱记录恶意代码网络行为信息,结合Cuckoo 沙箱和改进DynamoRIO系统提取恶意代码样本API 调用序列及网络行为特征,从而获取其网络行为信息,并采用Cuckoo 沙箱获取的恶意代码行为信息训练BGRU 分类模型。实验结果表明,该方法能全面获得恶意代码的行为信息,其采用的BGRU 模型检测效果较LSTM、BLSTM等模型更好,精确率和F1 值分别达到97.84% 和98.07%。后续将融合静态信息与API 调用序列的特征构建更复杂的机器学习模型,进一步提高恶意代码检测精度。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
商品与质量(2019年34期)2019-11-29
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
测控技术(2018年5期)2018-12-09
疯狂英语·新读写(2018年1期)2018-11-29
电脑爱好者(2018年12期)2018-06-26
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
科技创新导报(2016年28期)2017-03-14
信息安全研究(2016年4期)2016-12-01
