
基于堆叠分类器的心电异常监测模型设计
2021-03-18 13:45
计算机应用 2021年3期
(1.大连大学信息工程学院,辽宁大连 116622;2.大连大学物理科学与技术学院,辽宁大连 116622;3.周口师范学院网络工程学院,河南周口 466001)
0 引言
心电图(ElectroCardioGraph,ECG)记录的数据包含关于心脏活动节奏属性等重要数据。心电图包括5 种基本波P、Q、R、S、T,有时也包括U 波。P 波代表心房去极化;T 波代表心室的复极;T 波跟随着每一个QRS 复合物,通常情况下它与QRS 波有一个稳定的间隔[1]。心律失常是心率或节律的不规则性,在某些情况下,可在受试者的日常生活中偶尔发生。为了捕获这些不常见的事件,通常使用动态心电图设备来记录长期的心电图数据[2]。心电图波形检查有助于各种异常的诊断,是研究心脏病最重要和常用的手段之一。
目前心电监测的方法主要包含以下几种:人工监测、基于机器学习的监测[3]和基于深度学习的监测[4]。由于人工观测心电图的步骤繁琐,且需要大量的先验知识做积累,而且很容易忽略心电图中微小的波动变化从而导致判定出错。
近年来学者们主要使用机器学习和深度学习的方法来进行心电图的监测。深度学习方法在图像检测的问题上已经取得了较好的效果。Al Rahhal等[5]使用深度神经网络动态神经网络(Dynamic Neural Network,DNN)使用堆叠降噪自动编码器(Stack Denoising AutoEncoder,SDAE)从原始的两导联心电图数据中进行适当的特征表示。Zubair 等[6]使用蜂窝神经网络(Cellular Neural Network,CNN)对从MIT-BIH[7]数据库获得的44 个心电图信号进行记录,提取了R 峰的心电图节拍模式,用于3 层CNN 的训练,能92.70%准确地将心电图的搏动分为各自的类别。Kiranyaz 等[8]研究了仅用R 峰波的3 层CNN 心电监护系统。Acharya 等[9]使用9 层的CNN 算法可以对5 种不同的心电心跳类型进行分类,通过对有噪声的MITBIH数据库中的数据进行去噪和数据扩增处理,使得5种数据平衡化后检测的识别率达到92.50%,对数据不平衡的原始数据集进行判定时识别率下降到了89.3%。该方法能减少患者的等待时间,减轻心内科医生的工作量,降低医院心电信号处理的成本。Luo 等[10]提出基于时频表示和特定于患者的心跳分类,通过使用具有1 024 个神经元的一维编码器和一个softmax 形成的DNN 模型使得心电图识别识别率达到94.39%,其DNN 模型所需计算量较大,相同数据集下训练时间约1 h。Mathews 等[11]开发了一个基于CNN 的分类系统,它能自动从两导联ECG 数据中学习合适的特征表示,从而消除了手工制作特征的需要,但框架没有涉及任何QRS 波检测。在Acharya 等[12]的工作中,由11 层卷积神经网络处理分段ECG,使用短时程ECG 数据得到最大精度93.18%。Sun 等[13]利用8 682例多导睡眠仪数据集,构建了一个由卷积网络和长短时记忆网络组成的5 个深度神经网络,利用心电图和呼吸信号训练深层网络模型。
深层网络是“黑匣子”,研究人员不能完全了解深层网络的内部结构。本文算法相较于深度学习模型在调整超参数更改模型设计时更加简单。另一方面,医疗数据相对较少很难满足庞大的深层网络的需要。本文提出将合成少数过采样技术(Synthetic Minority Over-sampling TEchnique,SMOTE)对稀缺的心电异常数据做了数据平衡化处理[14],解决了医疗数据稀缺并且数据的种类不平衡问题,实验的结果证明平衡化后的数据可大幅减轻数据过拟合问题,提高分类器的性能。
1 模型设计
1.1 系统架构
本文堆叠分类器(Stacking Classifier)系统架构如图1 所示,通过小波变换得到每个心拍含有的25 个特征系数,从特征提取以后的心拍中随机取出其中的80%作为算法模型的训练集,其余的20%数据作为测试集,再通过SMOTE 算法把原始的不平衡数据进行数据扩增以达到每种病例数量持平的效果。

图1 Stacking Classifier系统架构Fig.1 Architecture of Stacking Classifier system
1.2 心电监测分类模型
堆叠分类器是一种集合学习技术,它是通过元分类器组合多个分类模型[15]。首先,通过完整的训练集来训练各个分类模型,再通过集合各个分类模型的输出而得来的元特征来拟合元分类器。元分类器可以根据预测类标签或来自集合的概率进行训练。
算法模型把训练集的数据分别送入不同的分类模型分类器中,通过多个不同分类器获得不同的预测结果,再通过元分类器迭代多个预测模型的分类结果,获得最终的预测结果,过程如图2所示。
首先把训练集分成N等份:train1,train2,…,trainN,然后构造一个初级机器学习器,它是由K最近邻(K-Nearest Neighbors,KNN)分类器、RandomForest 和极端梯度提升(eXtreme Gradient BOOSTing,XGBOOST)分类器三种基模型构成的,依次使用train1,train2,…,trainN作为验证集,其余N-1份作为训练集,交叉验证进行模型训练;再在测试集上进行预测。这样会得到在训练集上由KNN 模型训练出来的N份预测值和在测试集上的1 份预测值B1。将这N份纵向重叠合并起来得到A1。RandomForest 和XGBOOST 模型部分也运用类似的方法。
3个基模型训练完毕后,将3个模型在训练集上的预测值作为分别作为3 个“特征”A1、A2、A3,然后再通过逻辑回归(Logistic Regression,LR)模型进行训练,建立LR 模型,这个LR模型就是次级分类器。使用训练好的LR模型,用3个基模型在测试集上得到的预测值构建的3个特征值(B1,B2,B3),当没有概率时直接使用初级分类的输出作为初级分类器的输入,把初级分类器的结果均质化以后作为次级分类器的输入已达到叠加器的效果,进行预测可以综合各种机器学习算法分类器的优势迭代出相对较好的结果。
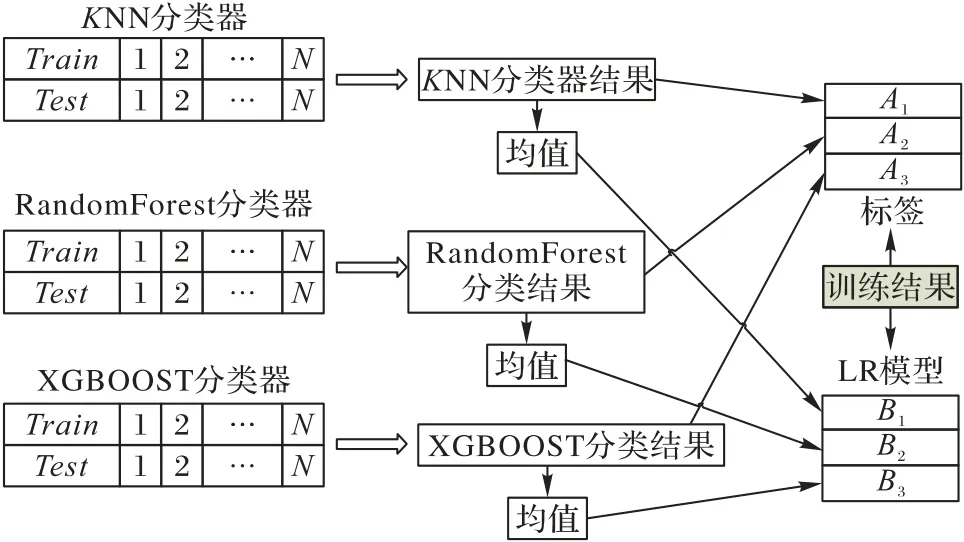
图2 Stacking Classifier计算过程Fig.2 Stacking Classifier computation process
1.3 样本扩展
类别不平衡问题(class-imbalance)是指在训练分类器中所使用的训练集的类别分布不均,数据集中存在某一类样本,其数量远多于或远少于其他类样本,从而导致一些机器学习模型失效的问题。心电数据就是一个典型的类别不平衡问题,正常的心拍数量远远多于异常心拍的数量,从而容易造成最终的分类结果不理想。为了解决该问题,本文采用SMOTE算法对数据集非平衡样本进行了扩充,该算法思想是在少数类样本之间进行插值来产生额外的样本,自提出以来受到学术界和工业界的一致认同[16]。对心电数据及堆叠模型而言,比起简单地将少数类别样本复制添加到样本集中等方式,该算法能够避免模型学到的信息过分特别,不够泛化,从而避免模型产生过拟合问题。
SMOTE 算法的描述如算法1 所示,算法可以获得新的少数类样本,通过对每个少数类样本a,从它的最近邻中随机选一个样本b,通过在a、b之间的连线上随机选一点作为新合成的少数类样本。SMOTE算法的描述如图3所示,(少量的数据样本)图表示少数类样本中的xi到少数类样本集中所有样本的距离,(生成新的样本)图为根据采样比例倍率,从xi的K近邻中随机选择若干个样本,分别与原样本通过算法中的公式构建新样本。
算法1SMOTE算法。
输入:数据集中的每个样本a;
输出:产生出的属于少数样本类中的新样本c;
算法描述:
1)通过欧氏距离,计算每个样本的K近邻样本b,得到K邻近值;
2)根据样本不平衡比例设置采样倍率C,从少数样本K近邻中随机选取b;
3)根据下式生成新的样本c。
c=a+rand(0,1)*|a-b|
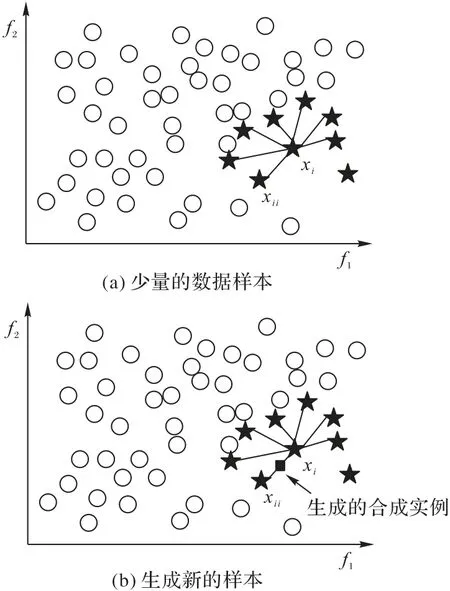
图3 SMOTE计算原理Fig.3 Calculation principle of SMOTE
2 实验结果与分析
2.1 实验环境与数据集
本文使用的是MIT-BIH 心律失常数据库[17],该数据库是麻省理工大学(MIT)结合国际标准并通过专家标注解释的心电数据库,是目前学术界心电监测领域最权威的心电数据库。
MIT-BIH心律失常数据库包含48个30 min长度双通道动态心电图记录片段,其中包含了十几种心律失常类型,总计超过十万多个心拍,当然其中大部分都是正常的心拍,异常心拍的种类包括房性早搏、室性早搏、束支阻滞、房颤等多类异常心拍。
算法被部署在具有双个E52620 CPU、1080TI 显卡的塔式工作站上,在深度学习模型中使用sklearn 平台架构和Python-3.7 实现本文算法。把整体的心拍通过交叉验证的方式分成N份,随机抽取其中的N-1 份作为训练集,剩下的1 份作为验证集得以应用到训练模型中来,使得本就稀有的医疗心拍数据得到充分的发挥,采用这样的方式就可以使得模型的训练精度得到了加强。这种交叉验证的方式不仅提高了训练结果的可信度,同时充分使用了所有的样本数据。
为验证分类效果,对实验结果计算多种评价指标值,包括召回率(Recall)又称敏感性(Sensitivity)、精确率(Precision)以及F1系数。
2.2 结果对比与分析
基于以上的模型和训练,将本文算法应用于公开数据集MIT-BIH 上进行了分类效果的测试。选取经典机器学习算法支持向量机(Support Vector Machine,SVM)、逻辑回归、随机森林和主流的集成学习算法极端梯度提升(XGBOOST)、梯度提升决策树(Gradient Boosting Decision Tree,GBDT),在同一个原始数据集上做分析比较,发现不同的机器学习算法在数据集上的表现不同,结果见表2、3。
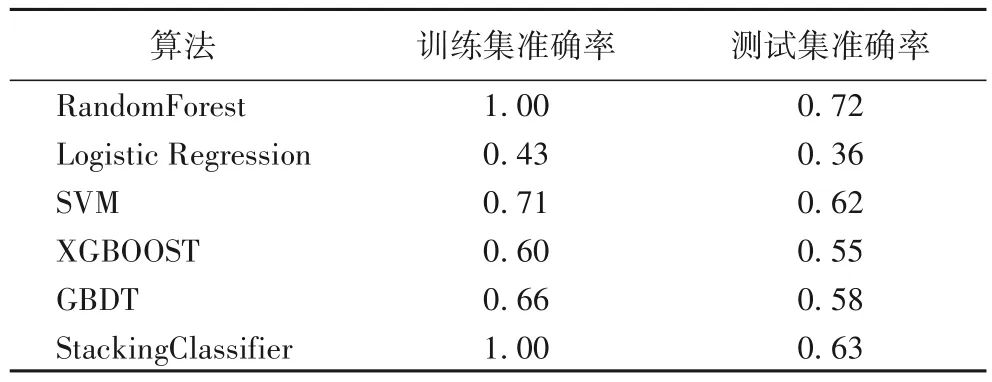
表2 原始数据集上不同算法准确率比较结果Tab.2 Accuracy comparison results of different algorithms on the original dataset
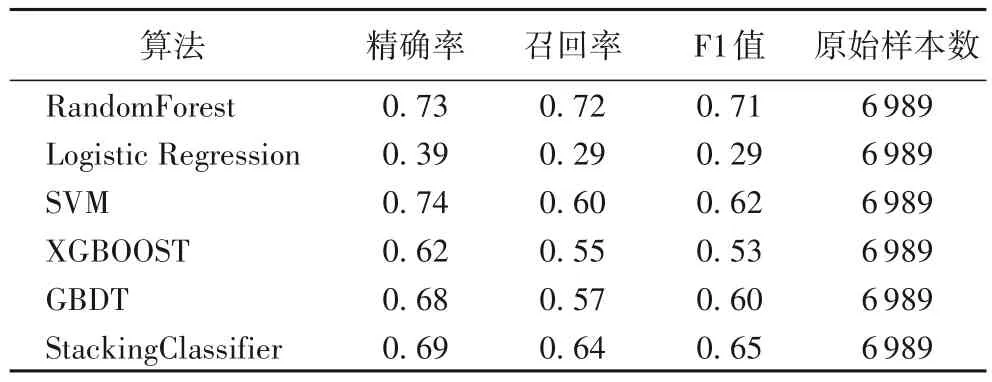
表3 原始数据集实验结果比较Tab.3 Comparison of experimental results on the original dataset
从表2 中可以看出,随机森林(RandomForest)和StackingClassifier 算法在训练集上的准确率都达到了100%,相较于逻辑回归算法、支持向量机(SVM)、极端梯度提升(XGBOOST)、梯度提升决策树(GBDT)表现要好很多;但就在测试集上的验证的准确率而言,随机森林算法的准确率明显高于StackingClassifier 算法,模型的精确率低于随机森林模型,StackingClassifier 算法在数据类型不平衡的情况下出现了过拟合问题。
从表3 中看出,在数据集中原始样本数(未经扩充的数据样本数)不均衡的情况下,StackingClassifier 的召回率和F1 值低于随机森林算法,出现了严重的过拟合现象,在训练集上达到效果100%的情况下,F1 值只能达到65%。实验训练时间128 s,优于相同数据集下深度模型训练时间[11]。
基于上面的实验结果,本文通过SMOTE 数据扩增算法得到类型趋于平衡的数据,然后用同样的算法再进行实验,实验结果的比较见表4、5。
从表4 中看出,在通过SMOTE 算法进行数据扩增以后,随机森林算法、逻辑回归算法、SVM 算法、XGBOOST 算法、GBDT 算法分类性能都获得了巨大的提升,特别是StackingClassifier 算法在测试集上的效果得到了显著的提升,在测试集可以达到86%的准确率。
从表5 中可以看出,StackingClassifier 算法在数据扩增以后的测试集上的召回率和F1值也得到了显著的提升,均达到了86%,其他的机器学习算法的表现也都有了显著的提高,表明对于不均衡的医疗数据而言,通过SMOTE 算法来消除数据不均衡的问题有利于精确度的提高。
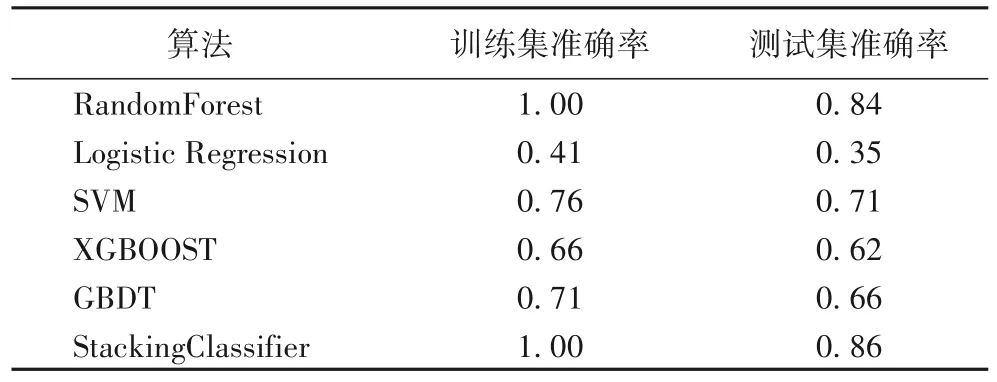
表4 扩增数据集上不同算法准确率比较结果Tab.4 Accuracy comparison results of different algorithms on the expanded dataset
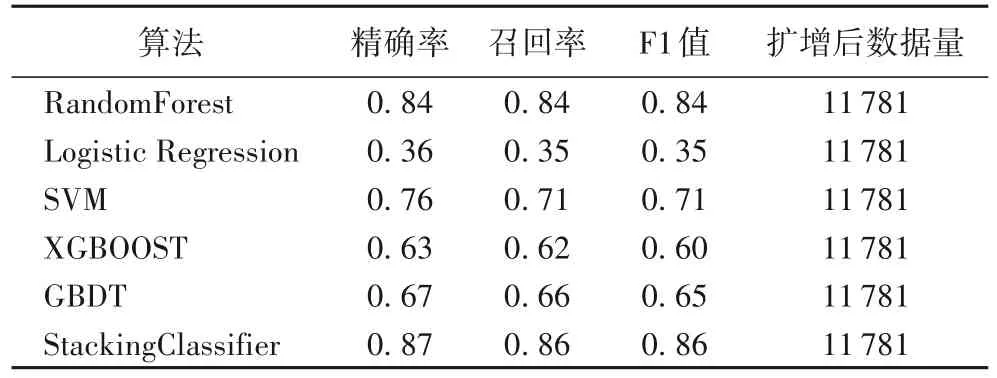
表5 扩增后数据集评价指标对比Tab.4 Comparison of evaluation indexes on the expanded dataset
3 结语
为了对监测的心电异常分类,本文提出了一种通过StackingClassifier 叠加分类器的算法模型,把多种机器学习算法的优势相结合,通过叠加分类器的方式集成起来,弥补了单个机器学习算法学习的局限性,提高了心电分类的准确性。通过SMOTE 算法扩充了数据集样本量,改善了数据非平衡性。接下来的工作可以结合深度学习的残差网络的算法对模型的精度进行进一步的提升。
猜你喜欢
现代电子技术(2022年21期)2022-11-03
模式识别与人工智能(2022年9期)2022-10-17
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机研究与发展(2022年1期)2022-01-19
计算机系统应用(2021年2期)2021-02-23
设计(2019年22期)2019-04-01
消费电子(2017年10期)2017-10-31
软件导刊(2017年4期)2017-06-20
心脑血管病防治(2016年6期)2017-01-16
