
基于双相机捕获面部表情及人体姿态生成三维虚拟人动画
2021-03-18 13:45
计算机应用 2021年3期
(四川大学计算机学院,成都 610065)
0 引言
随着虚拟现实技术走进大众生活,人们对虚拟替身的获取手段及逼真程度都提出较高要求,希望能够通过低成本设备,在日常生活环境下获取替身,并应用于虚拟环境[1]。
目前,动作捕获生成三维虚拟人动画的技术在动画影视、人机交互、虚拟现实等行业已得到广泛应用。商业领域已经成功运用复杂的设备及标记点的方法驱动模型,生成动画。例如,Vicon Cara System、OptiTrack Expression 等动作捕获系统,利用光学传感器,为人体贴上多个标记跟踪点,可对人类全身运动及面部表情进行准确捕捉,最优捕捉精度可达到20 μm。这类设备采集过程有侵入性、价格昂贵、应用场景复杂,难以进一步在日常生活中应用。
对普通用户而言,单目相机相对动作捕获设备价格更低,操作更灵活,能在大多数人机交互场景应用。因此,如何利用单目相机跟踪人体运动,生成自然逼真的动画,是近年来计算机视觉和人体运动仿真的一个研究热点。
围绕单目相机实时跟踪人体运动生成动画的问题,本文展开了深入的研究。首先,采用传输控制协议(Transmission Control Protocol,TCP)网络时间戳实现双相机时间同步,使用张正友标定法[2]实现双相机空间同步;然后,通过同步后的双相机分别采集面部表情及人体姿态,获得模型驱动数据;最后,在虚幻引擎4(Unreal Engine 4,UE4)中驱动三维虚拟人生成动画。从实验生成的虚拟人动画效果来看,本文提出的方法能实时捕获人体、面部的运动,可以获得姿态、表情动作一致的动画效果,有较好的用户视觉体验。
1 相关工作
近年来,研究者们对捕获人体姿态与面部表情生成动画问题进行了大量的研究。
人体姿态估计方面,Cao 等[3]设计了OpenPose,可以在一个图像中实时检测多个人体姿态,在多相机场景下预测关节点置信度和部分亲和场向量,并由2D 检测姿态结果匹配3D信息,取得了较好的鲁棒性。Güler 等[4]提出使用蒙皮多人线性模型(Skinned Multi-Person Linear model,SMPL)拟合密集三维人体方法,构建DensePose 网络对人体表面进行回归,将图像的人体像素映射成3D 人体表面。Mehta 等[5]提出基于单目相机实时稳定的姿态估计方法,该方法实时检测速度高;但部分场景下,对关节预测不够精确,无法解决肢体遮挡问题。王志勇等[6]提出利用Kinect 相机和彩色相机同步采集面部表情及身体姿态方法,使用Kinect Fusion 扫描得到人物模型,使用Robust Icp 方法实现姿态估计,重建人脸得到面部动画;但Kinect采集过程中易引入噪声,导致出现抖动情况。
面部表情动画方面,Cao 等[7-8]构建了FaceWarehouse 三维表情库,回归预测3D 特征点,实时跟踪人脸表情,配准生成3D 人脸,能结合BlendShape 生成逼真的人脸表情动画,提高了三维表情动画的精确度;但其离线训练阶段,需要对每一个人脸采集数据,且生成的人脸模型较为粗糙。
上述研究在人脸面部表情动画驱动及人体姿态估计方面取得了显著成果,但未考虑到使用单目相机同时采集面部及身体图像,提取运动数据的情况;且部分方法对头部运动采集效果较差,得到的数据驱动模型时,几乎无法还原头部运动情况。摄像头距离人体较远时,不易捕捉细微的表情变化;距离较近时,不能完整捕获人体的肢体信息。得到的数据驱动三维动画时,无法同时得到面部表情与身体姿态一致的动画效果,表达人体的行为及情绪。部分方法通过扫描或重建3D模型生成动画,不能利用数据驱动多种模型,模型通用性差,无法复用。因此本文提出了使用单目相机捕捉人体面部表情及身体姿态,生成同步的动作表情捕获数据,驱动建立的虚拟模型,得到三维动画的方法。
2 双相机同步捕获面部表情及人体姿态
2.1 相机同步
在人体姿态采集过程中,相机距离人体面部较远,处理细微面部表情的能力较差。为解决该问题,本文采用两个单目相机分别对面部和身体姿态数据进行采集;但是,两个相机同时采集会产生时间空间不同步问题,导致后续面部数据与姿态估计数据融合求解过程中产生误差,因此,需要对相机进行时间同步及空间对齐。
为了保证两个相机采集的人物数据的空间坐标保持一致,本文采用张正友标定法对两个相机进行空间标定;为保持时间同步,采用TCP 网络时间戳方法对面部和身体信息进行同步融合。
相机标定的目的是修正相机畸变参数,矫正图像。根据标定法,将两个相机对同一棋盘图片的不同方向拍照,得到相机各自的内参、外参及其畸变系数。
为了解决相机时间不同步问题,本文提出了一种使用TCP 网络传输时间戳的同步方法,将表情与姿态数据进行同步融合。TCP 是一种面向连接提供可靠有序数据传输的传输层协议,但在传输过程中可能存在丢包、粘包等情况。为解决程序发送接收过程中出现类似的问题,根据传输数据类型,始终在发送端将每个数据包封装为固定长度。根据处理帧率,在发送端调用sleep 方法,保证TCP 发送速率,在接收端设置相同的动画刷新速率,保证双方的接收情况。采用此方法后,由于同步后的传输能达到20 fps,即使丢失小部分数据,仍然能达到较为真实的效果,图1中展示了TCP传输流程。

图1 TCP传输过程Fig.1 TCP transmission process
首先,采集面部图像,利用TCP 网络,传输包含时间戳的数据结构至姿态估计程序;其次,对姿态估计部分得到的数据进行封装后,匹配面部表情数据对应的时间戳,按照先后次序整合为新的表情及姿态结构数据;最后,将融合后的数据传输至UE4 引擎,用于控制模型生成动画。由于单目相机采集图像估计3D 姿态时,帧率较低,为更好地利用姿态估计得到的数据,减少丢帧,本文使用平滑及预测方法处理面部表情行为单元数据,保证面部表情动画更流畅,通过预测也能使后续帧面部与身体行为保持同步。
2.2 实时捕获人脸面部表情
为从单目相机中得到清晰真实的面部表情动画,本文从图像中提取2D 特征点,利用2D 特征点回归得到面部行为编码系统(Facial Action Coding System,FACS)面部行为单元(Action Unit,AU)参数[9],根据行为单元参数与表情基线性组合,驱动模型获得面部表情动画。
从图像中提取有效特征点是对面部表情分析的核心步骤,获取的特征点可作为表情参数的基础数据。本文使用Baltrusaitis 等[10]提出的受约束局部神经域(Constrained Local Neural Field,CLNF)模型,检测面部特征点及跟踪面部。其模型构建阶段分为Shape 模型及Patch 模型构建过程。捕获人脸面部表情时,首先构建CLNF 模型,生成目标函数并得到面部特征点;然后,采用方向梯度直方图(Histogram of Oriented Gradient,HOG)[11]提取外观特征,用主成分分析法降低维度;最后,用支持向量机[12]检测面部行为单元AU 存在情况,使用支持向量回归估计AU 强度,得到表情的分类和回归效果。
由于面部表情采集过程平均帧率为30 fps,优于姿态估计效果,本文采用Holt 双参数指数平滑法对面部表情参数进行平滑及预测,匹配姿态估计得到的数据。期望利用当前人物表情状态先验信息,推断下一时刻的表情状态。通过该方法可以将面部表情数据变得更平滑,也能得到一定范围内的趋势预测,提高对面部表情的检测精度。式(1)为平滑方程:
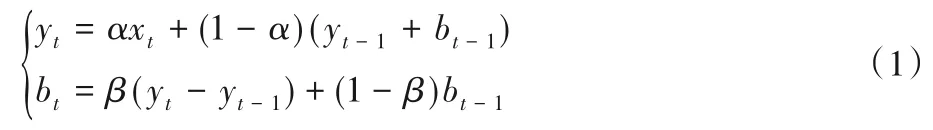
式(2)为预测模型:

其中:α为平滑参数,β为趋势平滑参数,yt为t时刻平滑值,xt为实际值,bt为t时刻的趋势值。经过Holt 算法平滑处理后,可以避免表情突变情况,获得更流畅自然的动画效果。使用预测模型能够合理预测一段范围内的表情状态。为验证其预测效果,本文采用平均绝对百分误差(Mean Absolute Percentage Error,MAPE)对该连续时间序列的整体预测结果进行评价,式(3)为计算公式:
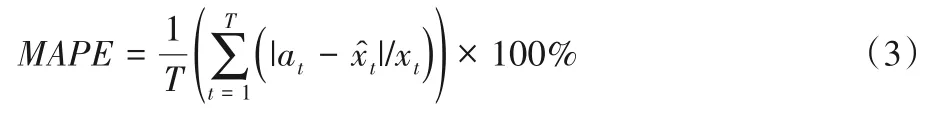
其中at和表示当前时刻预测值与实际值。误差越小,表示预测效果较好,接近真实值;反之则效果较差。针对表情行为单元中的9 个值进行评估,选取其中1 s 内25 个数据,预测未来5 帧的数据,MAPE结果都在10%范围内,表明预测结果能反映一定的变化趋势。
由于靠近人脸的相机能更准确地采集头部信息,为表现人体头部位置信息,本文在面部表情采集过程中采用高效n点投影(Efficient Perspective-n-Point,EPnP)算法[13]估计头部姿态。以标准头部3D 坐标值为基准,根据相机内参,可以得到人体头部的姿态估计信息。将头部坐标信息、表情行为单元和姿态估计信息匹配融合,能生成合理的人物姿态及表情驱动数据。
2.3 实时人体姿态估计
为从单目相机中得到清晰真实的虚拟人物身体动画,本文用相机捕捉人体姿态,获得人体关键点3D空间坐标及旋转角度数据,驱动三维动画角色的身体运动。使用Mehta 等[14]提出的遮挡鲁棒姿势图(Occlusion-Robust Pose-Map,ORPM)方法实现人体姿态估计。
ORPM方法是一种同时估计二维和三维姿态的方法,对于一张RGB 相机获得的图像I,计算图像中人体姿态,输出每个骨骼点位置、旋转角度等数据,即使在较强的局部遮挡情况下也能输出完整的姿态估计数据。将采集到人体的分为躯干、颈部、头部,以及肢干等人体关键点。使用Cao 等[3]的方法预测的热图H和部分亲和场实现2D关节点的关联。图2展示了ORPM 的网络结构[14],首先用ResNet50 网络对输入图像进行特征提取,然后将这些特征送入二维姿态估计网络,得到各关键点的热图H和部分亲和场,随后将这部分信息与基础网络得到的特征信息一起送入三维姿态估计模型中,得到三维姿态估计结果。这部分结果不光包括各关键点的热图,还包含pose-map 冗余信息,用来在最后修正最终的估计结果。通过冗余信息的加入,三维姿态模型得到了很好的遮挡鲁棒性。
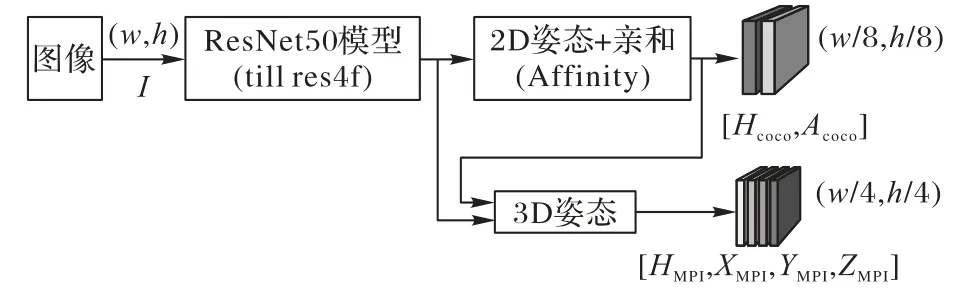
图2 ORPM网络结构Fig.2 Network structure of ORPM
在姿态估计过程中,如果图像中人体有明显遮挡,则定义躯干和颈部节点作为判断身体姿态的主要节点。若末端节点存在遮挡情况,则取其父节点位置估计该节点;若躯干中心节点被遮挡则根据主要节点位置保持基础姿态。这样能够保证无论是否存在遮挡情况,每组数据都输出包含完整关节点,防止出现由于缺失部分关节数据而生成不自然动画情况。
为防止数据抖动发生突变,应对数据进行平滑处理。具体表现为在得到节点数据后,添加平滑项,由式(4)表示,其中q表示当前帧运动情况。

不同的人体姿态在空间上可由模型骨架的位置和旋转角度表示。将骨骼点数据按照式(5)来表示:

其中:(xi,yi,zi)为位移信息,(θi,ψi,φi)为旋转信息。这样就得到了驱动三维人物肢体动画的人体姿态估计数据。
3 三维虚拟人动画驱动
目前驱动三维模型常用的变形方法有:基于BlendShape的模型差值变形、基于骨骼动画的子空间蒙皮变形、自由变形、基于物理的仿真变形等。
生成虚拟人身体动画时,由于骨骼点较为清晰、数量较少,通过控制骨骼点的相对位置即可产生相应的动画。生成面部表情动画时,需要驱动大量面部点、面部肌肉等来获得逼真的动画效果。如果驱动数据抖动或偏差较大,会导致生成的表情动画滑稽夸张。因此本文采用骨骼动画方法驱动模型身体姿态,使用BlendShape模型方法驱动面部表情,得到整体过渡自然真实的全身动画效果。
3.1 身体动画驱动
本文通过得到的姿态数据,在UE4 引擎中驱动虚拟人物生成动画,模拟人体姿态。根据捕获到的身体骨骼点,在UE4人物蓝图中建立动画人物关节点与捕获数据节点的映射关系,确定关节点位置。图3(a)表示姿态估计中采集的关节点信息,图3(b)表示UE4 引擎模型骨骼树节点信息。其中未匹配的骨骼在动画生成的过程中会保持相对父骨骼静止。
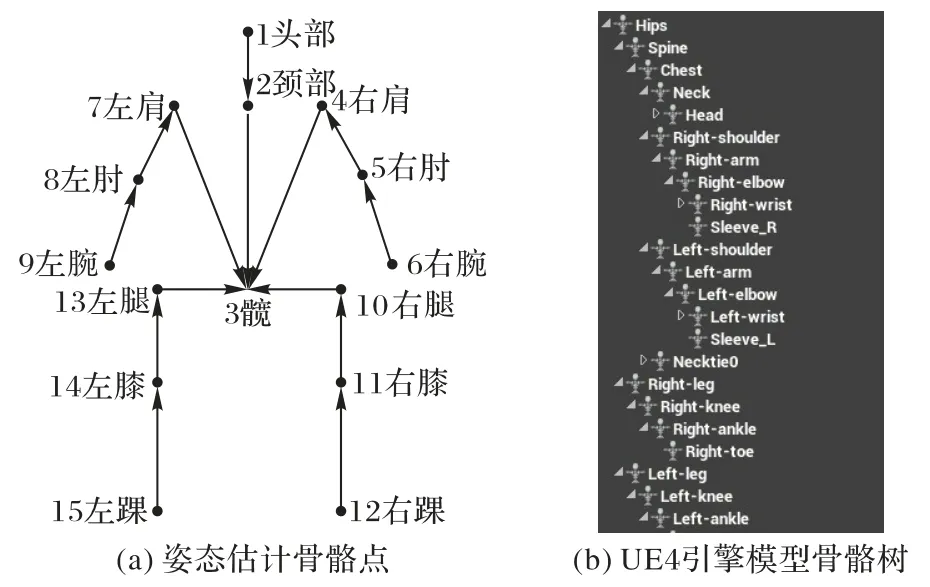
图3 姿态估计与UE4模型的映射关系Fig.3 Mapping relationship between pose estimation and UE4 model
初始情况下,采集到的身体特征点坐标系与UE4引擎坐标系存在差异,每个骨骼也有独立的局部坐标系,如果不转换坐标系,会导致骨骼点方向错误。因此在输入数据之前需要对坐标系进行统一。本文将三维模型、特征点局部坐标系、特征点世界坐标系均统一至UE4 世界坐标。在人物蓝图中将2.3 节得到的骨骼点数据M转换为UE4引擎中的Transform(Location X,Location Y,Location Z)及Rotator(Roll,Pitch,Yaw)数据。
由于人体骨架的各个节点之间有内在的关联性,直接指定各关节的平移和旋转值很容易产生不协调的动作。本文使用基于物理的人体模拟方法前向动力学(Forward Kinematics,FK)和逆向动力学(Inverse Kinematics,IK),来获得更加流畅的动画效果。
由于不同采集者身高比例不同,直接给出末端节点位置可能会导致模型穿模、相邻关节分离的情况。因此本文采用动画IK 处理模型身体末端节点(例如手腕、脚腕),即使用子节点牵引父节点运动。当末端关节的位置确定后,根据末端骨骼点的位置、旋转信息,计算中间骨骼点的信息。骨骼架构中对应的两个关节偏转角度可以通过雅可比矩阵确定。由于IK 动画计算出的中间骨骼具有多个方向,因此需要针对不同骨骼调节其动画蓝图中的节点目标位置(Joint Target Location)参数,保证骨骼的正方向。
身体主要支撑节点(例如髋、肩部等)使用动画FK,即用骨骼的父节点驱动子节点运动,确定核心骨骼相对于UE4 世界坐标系下的准确位置。
人物蓝图将骨骼数据传入相应的动画蓝图骨骼节点,按照发送帧率刷新动画,就能得到模型的身体动画驱动效果。
3.2 面部表情动画驱动
表情融合模型(Expression Blendshape Model)是一种数据驱动参数模型的方法,包括了一个用户在不同表情下的人脸形状,描述了该用户的一个线性表情空间[15]。不同的表情可以与模型中的表情基线性组合得到,因此,人脸的特定表情E可由式(6)计算:

其中:E0为表情基;ei为对应表情加权系数。对于部分中性表情,适当扩大或重新计算加权系数,能让部分细微表情表达得更清晰。例如,针对人物眨眼动作判断不准确的问题,采用得到的面部特征点位置计算上下眼睑开合程度重新计算对应表情系数,能得到更好的表情效果。
表情动画驱动过程中,首先,在3ds MAX中绑定好人物面部骨骼,使用Maya 设计模型BlendShape 表情控制器,导入UE4 引擎生成相应的变形控制器(Morph Targets)。然后,建立控制器与表情采集过程获得的行为单元参数AU 之间的映射关系。最后,使用TCP 网络传输AU 数据至UE4 引擎,根据表情权值驱动相应表情控制器。按照发送帧率刷新三维人物面部表情,即可得到实时面部动画效果。
3.3 三维虚拟人动画融合
在相机时间同步过程中,捕获得到的数据已被封装为结构体数据。其中面部表情模块包含17 个面部行为单元数据,姿态估计模块包含15 个骨骼点的位移坐标及旋转欧拉角数据。在驱动全身动画时,需要将面部表情数据与姿态估计数据进行匹配融合。
在面部采集过程和姿态估计过程计算了重复的头部坐标信息,其中面部采集无法获得真实的头部平移参数,姿态估计过程无法获得准确的头部旋转信息及表情信息。因此,本文借助头部节点(Head)将面部数据与身体姿态数据进行融合,修正头部姿态。融合姿态估计得到的平移坐标,与面部表情采集获得的头部旋转坐标、表情参数,表示完整的人体运动。最终的动画驱动数据表示为式(7):

其中:R为面部表情捕获得到的头部旋转坐标;E为面部表情;t为姿态估计过程得到的头部位移。图4 展示了动画驱动数据结构的完整信息。
在UE4动画蓝图中,利用TCP接收数据,绑定对应表情控制器及身体骨骼点,就可以得到3D人物骨骼动画及表情动画的重定向结果。
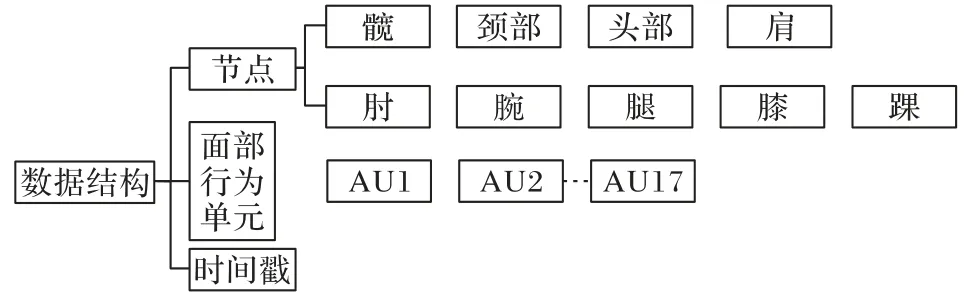
图4 动画驱动数据结构Fig.4 Animation-driven data structure
4 实验结果与分析
本文提出了一种使用双相机同步检测人体姿态及表情并驱动三维动画的方法。为检测方法的有效性,使用两个分辨率为720p 的Logitech 相机,Intel i7-8700K 处理器,NVIDIA GeForce GTX 1080 显卡进行了实验。首先,令表演者表演日常行为,包含肢体动作及多种面部表情。对相机同步后,实时采集表演者的动作,获得面部表情及姿态估计数据。其次,按照本文提出的方法处理得到驱动数据,建立绑定好面部表情控制器及身体骨骼点的三维模型。最后,使用TCP 网络传输数据,在UE4引擎中驱动模型,产生动画效果。在实验室环境下,同时捕获面部表情及身体姿态,并生成动画,处理帧率能达到20 fps,生成人体肉眼可接受的动画。
为了验证两个相机采集效果是否优于单独采集面部或姿态得到的动画效果,本文对比分析了采集部分人体运动获得的动画效果。
4.1 表情驱动动画
针对人脸面部表情驱动,本文使用第3 章中面部表情捕获方法,获得了人脸表情动画效果,如图5 所示,展示了不同表情及头部姿态得到的面部表情渲染结果。图5(a)为真实用户表情,图5(b)为驱动得到的动画表情,实时生成动画的帧率可达到30 fps。可以看出,本文提出的面部表情捕获方法能够快速捕捉用户面部表情,并实时驱动人脸表情动画。
4.2 身体姿态动画
本文的姿态估计结果如图6 所示,其中图6(a)为相机采集的人体图像,图6(b)为姿态估计结果,图6(c)为驱动得到的动画。根据结果图可以发现,本文提出的方法生成的动画能够快速模拟出人体行为,但对于面部及头部采集效果比较模糊,对人体面部表情采集情况较差,需要借助其他方法进一步采集细微表情。
4.3 融合结果
融合面部表情及身体姿态后产生的动画效果如图7 所示。图7(a)为相机采集的人体图像,图7(b)为姿态估计得到的结果,图7(c)为面部表情捕获结果,图7(d)为融合后生成的动画。可以看出,使用两个相机分别进行采集,能同时捕捉到更丰富的面部表情特征以及身体姿态信息,获得更加真实的虚拟动画效果。
对比图5、6 及图7 可以看出:单独捕获面部表情,仅能获得表情动画,不能反映人体运动信息;单独捕获姿态信息,仅能获得大尺度姿态动画,头部几乎没有动作。采集部分人体运动生成的动画中,角色的面部表情与身体运动的情感表达脱节,不能反映人的真实情绪;而同时捕获面部表情及身体姿态,得到的动画效果更加流畅,能够表达采集者的真实情感,头部姿态也更自然。

图5 面部表情动画驱动效果Fig.5 Facial expression animation driving effect

图6 身体姿态动画驱动效果Fig.6 Human pose animation driving effect
4.4 实验对比
为验证本文方法生成虚拟人动画的自然真实性,在视觉上,本文与直接使用Kinect相机采集面部表情及身体数据,生成的虚拟人动画效果进行了对比。图8 为使用Kinect 相机采集人体生成动画效果。图8(a)为Kinect 相机采集的人体图像,图8(b)为生成的动画效果。
对比图7 和图8 可以看出,本文提出的方法生成的动画,能达到Kinect采集数据生成的动画效果。虽然在估计骨骼深度信息时,Kinect 利用红外设备采集的骨骼深度数据优于本文提出的单目相机采集的骨骼数据。但是,在采集面部信息时,Kinect 仅能采集大尺度头部运动情况,而本文提出的采用两个相机同时采集的面部与姿态的方法能更好地检测人物表情,生成反映人的真实情绪的动画。

图7 融合动画实验结果Fig.7 Fusion animation experimental results

图8 Kinect动画实验结果Fig.8 Kinect animation experimental results
文献[6]采用的方法与本文一致,均为使用两个相机同步采集面部表情及身体姿态生成动画,因此本文对比两种方法的实验效果。本文方法采用两个单目相机采集人体信息,而文献[6]方法使用一个单目相机和一个Kinect 相机。本文方法处理图像,生成动画的帧率与文献[6]方法的实验结果如表1所示。

表1 不同方法生成动画帧率Tab.1 Frame rates of animations generated by different methods
从表1 中可以看出,本文采用的方法能更快地处理并实时生成面部表情及姿态动画。分析其原因在于:文献[6]方法采用三维重建的方式还原面部表情。在姿态估计部分,使用深度图像的基础上,添加了数据平滑、轮廓对齐和运动姿态先验项,姿态估计输出结果的准确性更高。同时身体重建部分没有进行速度优化,不适用于实时情况下的动画生成。而本文方法旨在实现实时环境下的同步采集与动画驱动,因此在帧率上更优。此外,文献[6]方法通过三维重建得到动画效果,使用Kinect Fusion 扫描和手动嵌入骨骼得到人物模型,并驱动动画。本文方法直接由数据控制三维模型,能够映射到不同的模型中,能适应更多的模型,得到更丰富的动画。
实验结果表明,本文提出的方法能检测人脸面部表情及基本的人体行为,并在UE4引擎中实时驱动三维模型,合成对应的动画,相较单独检测面部表情和身体姿态得到的效果,能得到更加自然真实的动画效果。
5 结语
本文提出了一种使用两个单目相机同步检测人体姿态及面部表情,驱动三维动画的方法,旨在解决利用计算机实时捕获人体面部及姿态,生成三维动画的问题。
考虑到相机靠近人脸能够更精确地采集面部表情及同步姿态问题,本文利用两个相机分别对面部表情及身体姿态进行采集。首先,使用张正友标定法对相机进行空间同步且使用TCP 网络时间戳实现对相机时间同步。接着,利用双相机分别采集面部表情和人体姿态,将得到的面部行为单元及身体骨骼点数据匹配融合,并统一世界坐标系。然后,建立包含面部表情控制器及绑定好身体骨骼的模型,在UE4 中创建数据到控制器和骨骼点的映射关系。最后,使用TCP传输数据,在UE4 中驱动模型生成动画。在实验室场景下,实现了人体姿态检测、表情检测和动画驱动,结果表明本文方法能够生成符合人体运动规律的动画效果,且可以达到用户可接受的帧率。总体来说,本文所提方法能够实现对人体面部表情及身体姿态的实时捕获,并驱动三维模型生成动画。
但本文方法也存在不足,该方法缺点之一是最终产生的部分动画效果不够真实,不能准确地描述部分人体行为,一些细节(例如手指、脚部)动画比较僵硬,还有较大的改进空间。由于单目相机捕获深度信息不够准确,导致部分关节点不能真实地描述人体运动。另一个缺点是姿态估计过程需要尽量减少环境噪声,对环境要求和用户活动空间仍有限制。此外,当前系统仅对部分表情进行判断,不能丰富地展现人物表情。因此,在未来的工作里,应考虑进一步如何跟踪人体手指等末端关节动作,提升深度信息精度,以提升动画效果。此外,改进面部表情采集方法,获得更加生动形象的面部表情数据,以得到更逼真的人物动画效果。
猜你喜欢
英语文摘(2022年4期)2022-06-05
汽车实用技术(2022年7期)2022-04-20
房地产导刊(2020年11期)2020-12-28
学生天地(2020年3期)2020-08-25
当代陕西(2019年8期)2019-05-09
当代工人·精品C(2016年6期)2017-01-12
诗选刊(2015年4期)2015-10-26
电影新作(2014年5期)2014-02-27
少年科学(2009年12期)2009-07-07
小哥白尼·趣味科学画报(2009年5期)2009-06-19
