
基于面部特征图对称的人脸正面化生成对抗网络算法
2021-03-18 13:45*
计算机应用 2021年3期
*
(1.中北大学大数据学院,太原 030051;2.山西省医学影像与数据分析工程研究中心(中北大学),太原 030051;3.山西警察学院刑事科学技术系,太原 030401)
0 引言
随着深度学习的发展,人脸正面识别的性能有了很大提升,而监控视频中获得的人脸图像往往同时受到偏转角和俯仰角的影响,对于这种包含多角度变化的侧脸图像,现有人脸识别系统的识别准确率较低。目前针对多角度侧脸识别主要有两种方法:一种是学习不受姿态影响的人脸身份特征[1-2];另一种是利用单一侧脸图像恢复出保留身份的逼真正脸图像,也称为人脸正面化[3-8]。就第一种方法而言,由于现有人脸数据集呈现长尾分布,在姿态变化上分布不均匀,因此很难学习到较为鲁棒的姿态不变性人脸特征[3]。第二种方法人脸正面化可以作为一种预处理操作部署在人脸识别系统中,使得现有性能强的识别系统不需要重新训练也可以在一定程度上提升识别准确率,同时在某些场景中,正面化的结果可以作为关键的参考材料,例如在刑侦领域,可以为办案人员提供参考。此外,人脸正面化在其他领域也具有重要的实用意义。
目前针对监控摄像头得到的侧脸进行正面化主要有两方面的困难:被遮挡信息的补全和保留身份问题。
对于解决多角度侧脸被遮挡信息补全的问题,现有方法可以分为两种:基于二维方法[4-8]和基于三维方法[9-11]。
基于三维的方法需要二维图像到三维模型的映射,这一过程会引入较大误差,且三维方法得到的正面化图像通常不够真实,会出现人工伪影和严重的面部纹理信息丢失情况,并且在大角度姿态下,三维方法的性能会严重下降[4]。
基于二维的方法在大角度姿态下相比三维方法性能较好,是目前人脸正面化算法中使用最多的。Kan等[5]利用自编码器提出堆叠渐进式自编码器(Stacked Progressive Auto-Encoder,SPAE),以渐进方式把大角度侧脸逐渐转换为小角度最终实现正面化。Yim等[6]提出包括主深度神经网络(Main Deep Neural Network,Main DNN)和辅深度神经网络(Auxiliary Deep Neural Network,Auxiliary DNN)的多任务学习模型,Main DNN负责生成目标姿态下的人脸图像,Auxiliary DNN 利用生成图作为输入来重建原始输入图像,以这种多任务方式保留更多的身份信息。但这些方法在训练时由于引入的约束较少,得到的生成图像较为模糊。近几年,生成对抗网络(Generative Adversarial Network,GAN)[12]提升了二维图像生成任务的视觉效果,很多基于GAN 的人脸正面化方法被提出。两路生成对抗网络(Two-Pathway Generative Adversarial Network,TP-GAN)[7]提出了双支路生成对抗网络,通过全局和局部两条路径分别处理侧脸图像,再将两部分结果进行融合得到最终的正面人脸,同时根据人脸对称性先验提出对称损失来补全被遮挡部分,但这是从图像层面上补全信息。人脸正面化模型(Face Normalization Model,FNM)[4]提出了一系列人脸注意力机制判别器来判别生成图的真实性,从而增加对生成器的惩罚,得到逼真的正面人脸图像。用于面部姿态分析的多偏转多俯仰高质量数据库(Multi-yaw Multi-pitch high-quality database for Facial Pose Analysis,M2FPA)[8]采用软注意力的方式利用人脸解析网络分割出头发、五官和皮肤,分别给每一部分增加判别器判别其真假,以补全丢失的面部信息从而实现正面化。上述这些基于GAN 的方法大多通过改进判别器结构,从而增大对生成器的惩罚,促使生成器生成被遮挡部分,但即使判别器能力强,多角度姿态的自遮挡问题使得输入图像本身有效的面部特征较少,造成生成器可利用的信息较少,使得生成过程困难。因此,为了增加可利用信息,缓解自遮挡问题,本文根据人脸对称性这一先验知识,设计了特征图对称模块,即根据鼻尖位置判断输入侧脸的朝向,然后将编码器卷积层提取的特征图依据人脸朝向进行镜像对称,从特征层面上补全被遮挡的关键人脸信息,帮助生成器生成缺失的面部信息。
对于保留身份问题,现有正面化方法[3-4,7-8]利用性能强的人脸识别网络提取生成图和真实图的深层身份特征,通过降低特征之间的感知距离使得生成图的身份信息保留,这种方法通过全局方式保留生成图的面部整体特征,但在局部特征保留上关注较少,文献[13-14]指出眼周区域即包含眼睛和眉毛的矩形区域是面部中具有高判别性的区域,因此本文在文献[3-4,7-8]提出的身份保留损失基础上,加入了眼周特征保留损失,分别从全局和局部的角度来提高生成图像的身份信息保留。
本文的主要工作如下:
1)本文提出了一个端到端的特征图对称人脸正面化生成对抗网络(Symmetric Generative Adversarial Network,Sym-GAN),可以根据单张大角度下的侧脸图像生成保留其身份的正面化图像。生成器中加入了特征图对称模块,可以对多角度变化的侧脸图像进行一定程度的信息补全。
2)为了使得生成图保留更多关键的身份信息,同时利用人脸全局特征和眼周局部特征,通过缩小生成图像和真实图像对在面部区域和眼周区域的特征向量距离,使得生成正脸图保留更多的身份信息。
3)即使Sym-GAN 未包含任何人脸识别网络,但它可以轻松地部署在人脸识别系统中,作为一种预处理操作来专门处理多角度变化的侧脸图像,以提高现有人脸识别系统的性能。
在公开数据集CAS-PEAL-R1[15]上进行了定性和定量实验,实验结果证明本文提出的Sym-GAN 可以有效提高人脸识别模型在多角度侧脸下的识别性能。
1 人脸正面化
目前基于生成对抗网络的人脸正面化方法主要包括TPGAN[7]、M2FPA[8]、双注意力生成对抗网络(Dual-Attention Generative Adversarial Network,DA-GAN)[16]。如图1 所示,TP-GAN提出包括全局和局部路径的双支路生成器,全局路径处理侧脸图像得到正面脸型轮廓,局部路径处理各五官图像块输出对应正面图像,最后将全局和局部路径的结果进行融合得到正面图像。TP-GAN 的生成器采用编-解码结构,同时加入跳层拼接利用编码器提取的侧脸特征进行特征融合,但侧脸特征包含的信息较少,使得解码器上采样过程中可用的有效特征较少。对于TP-GAN 的双路径生成器,网络结构庞大,生成图像受最慢路径影响,在训练和预测时效率低,针对这一问题,M2FPA 和DA-GAN 只采用全局路径的单支路网络也可以达到相同效果。对于生成图身份信息保留,TP-GAN、M2FPA 和DA-GAN 使用的身份保留损失是以面部全局角度提高生成图身份信息保留,对局部具有高辨别能力的五官信息关注较少。
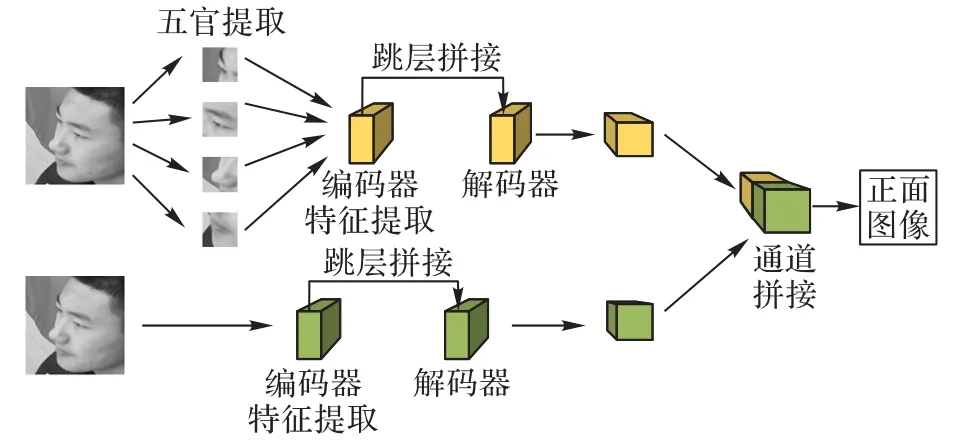
图1 TP-GAN网络框架Fig.1 Network framework of TP-GAN
2 Sym-GAN
本文提出的Sym-GAN 用于对受多角度变化的侧脸实现正面化生成,网络框架如图2所示。Sym-GAN 由生成器-判别器组成。生成器和TP-GAN 全局路径生成器一样采用编解码结构。编码器对输入侧脸图像提取特征,同时借助特征图对称模块,将侧脸特征依据鼻尖位置镜像对称;解码器将编码器提取的深层特征进行多次反卷积,在上采样过程中加入跳层拼接,将原始侧脸特征图、对称特征图、输入图像在通道维度上进行拼接,最终输出生成正脸图像。判别器采用深层卷积网络判定生成图和基准图的真实性,促使生成器生成逼真的正面图像。Sym-GAN 主要包含两个模块:特征图对称模块和改进的解码器跳层拼接模块。根据人脸对称性这一先验提出了特征图对称模块,应用于解码器跳层拼接,以补全丢失的人脸关键信息,从而缓解自遮挡造成的生成器对丢失部分生成困难的问题。改进的解码器跳层拼接是指对TP-GAN 解码器跳层拼接进行改进,在反卷积过程中拼接了编码器提取的侧脸特征图、对称特征图以及输入图,可以起到补全信息和增强面部细节学习的作用。此外,本文在身份特征保留损失的基础上,加入了眼周特征保留损失来训练生成器。身份特征从全局角度表征一些面部纹理特征和五官间的拓扑结构,眼周特征从局部角度表征眉毛、眼型和眼间距等局部身份信息,从而提高生成图全局和局部区域身份信息保留能力。下面将详细介绍特征对称模块和改进的解码器跳层拼接模块,眼周特征保留损失在3.2节眼周特征保留损失介绍。
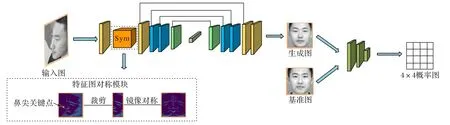
图2 Sym-GAN网络框架Fig.2 Network framework of Sym-GAN
2.1 特征图对称编码器
编码器的作用是将输入图像通过多层卷积提取特征,得到高维人脸特征表达向量,解码器对特征向量进行上采样恢复出正面图。对于多角度变化下的侧脸正面化任务,为了保证生成正面人脸逼真且保留足够多的身份信息,编码器一方面需要对输入图像进行信息过滤,滤去背景噪声和与人脸身份无关的角度信息,为解码器提供更为紧凑的面部特征向量;另一方面需要提供给解码器较为丰富有效的面部信息,以缓解自遮挡导致的人脸信息丢失问题。为了实现这一目的,本文在编码器对侧脸图像进行下采样过程中加入了特征图对称模块,首先使用预训练的人脸特征点检测器视网膜人脸(Retinaface)[17]对输入侧脸图像进行特征点检测,通过鼻尖点位置坐标来判断当前输入侧脸的朝向,将侧脸图像中信息包含较多的一侧以鼻尖横坐标为中心做镜像对称,编码器提取的特征图和对称后的特征图可视化效果如图3 所示,对称特征图应用于解码器跳层拼接,以补全丢失的人脸信息。编码器继续对侧脸特征图进行下采样得到256 维的深层人脸特征表达向量。

图3 特征图对称模块Fig.3 Feature map symmetry module
2.2 改进的解码器跳层拼接
解码器作用是将编码器得到的高层特征依次经过多个反卷积层进行上采样,直到生成图的分辨率和输入图一致。本文对TP-GAN 解码器跳层拼接做出改进,TP-GAN 在跳层拼接时只将侧脸特征图、输入原图和反卷积特征图进行拼接,如图4 所示。本文的改进方法为:在解码过程中,每层反卷积输入的特征图由编码器中对应尺度侧脸特征图、特征图对称模块得到的对称特征图、同一尺寸的输入侧脸图以及前一层反卷积的输出特征图拼接得到。相较于TP-GAN 的拼接方式,本文得到的对称特征图也参与了拼接,这种拼接方式不仅可以实现特征融合,也可以在特征层面上对丢失侧脸特征进行模拟和补全,以缓解生成器生成过程中能利用的有效面部信息较少的困难,从而生成出具有高细节保真的正面图像。

图4 改进的解码器跳层拼接Fig.4 Skip layer splicing of improved decoder
2.3 判别器结构
判别器的作用是判别生成图和真实图的真假性,从而对生成器造成一定的惩罚,使得生成器生成的结果更接近真实图像。本文采用的判别器结构如图5所示,由6层卷积层组成,其中在第4层和第5层卷积层之后加入残差块,使得网络层数加深,从而提取到更为抽象的面部细节特征,提高判别器的判别能力。从第5层到第6层采用1×1卷积核用于降低特征通道,最后输出4×4概率图。本文采用1×1卷积核代替全连接层,是因为全连接层会破坏图像的空间结构,而1×1卷积核可以保证在降低特征图维度的同时不改变图像的空间结构,即不破坏面部拓扑结构。此外,相较于传统生成对抗网络中判别器只输出一个标量值来表示生成图或真实图整幅图像的真实性,本文的判别器输出4×4概率图,其中每一个概率值对应图像中一个局部感受野,可以恰好将人脸五官位置进行分离判别,采用这种方法可以提高判别器对局部细节的判别能力,从而促使生成器生成高细节保留、高分辨率的正面人脸图像。

图5 判别器网络结构Fig.5 Network structure of discriminator
3 损失函数设计
3.1 整体目标函数
用于训练Sym-GAN 的目标函数Lsyn由一系列损失函数加权和组成,公式如下所示:

其中:Lip表示身份保留损失,以全局角度保留生成图身份信息;在Lip的基础上,为了增加对生成图局部身份信息的关注,本文提出眼周特征保留损失Leyefp;Lpixel表示多尺度像素级损失,确保生成图和真实图的内容一致性;Ladv表示对抗损失,使生成图在视觉效果上较好;Lsym表示对称损失,用于缓解自遮挡问题;Ltv表示总差分正则化,降低生成图的人工伪影,提高视觉效果;λ1、λ2、λ3、λ4、λ5、λ6为对应的权重参数。下面将详细介绍每一个损失函数。
3.2 眼周特征保留损失
为了保留生成图身份信息,文献[7-8]利用轻卷积神经网络(Light Convolutional Neural Network,Light CNN)[18]提取生成图和真实图的高维特征向量构成感知损失来确保生成图身份信息保留,这种方式是以全局角度关注生成图的身份特征,而对面部局部区域的身份信息关注较少;文献[13-14]指出眼周区域(即包含眉毛和眼睛的矩形区域)是面部最具有判别能力的区域之一,表明眼周区域相较面部其他五官,可以表征出更加独特的人脸身份特征。因此,为了提高生成图全局和局部区域的身份特征保留,在文献[7-8]身份保留损失的基础上,提出眼周特征保留损失,文献[19]分析了传统特征提取方法,如局部二值模式(Local Binary Pattern,LBP)[20]、方向梯度直方图(Histogram of Oriented Gradient,HOG)[21]、尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[22]和现有卷积特征在眼周图像识别效果,提出了现有的卷积特征在眼周图像上也有较好的识别性能,且实验表明使用残差网络(Residual Network,ResNet)[23]ResNet50 在眼周图像上的第73 层特征识别效果相对较好。因此,本文按照如图6所示设计了眼周特征保留损失,利用ResNet50 分别提取生成图和真实图的左右眼区域的第73层特征,然后分别计算对应特征之间的余弦距离,将两部分距离相加得到眼周特征保留损失,作为训练生成器损失函数的一部分,约束局部区域身份保留。

图6 眼周特征保留损失计算Fig.6 Calculation of preserving loss of periocular feature
眼周特征保留损失函数公式如下所示:

其中:φ(·)定义为ResNet50提取的第73层网络的特征和分别表示生成图像和基准图像分别表示I*的左右眼区域图像;dist表示余弦距离。
3.3 身份保留损失
为了保留生成图像全局身份信息,按照文献[7-8],使用预训练人脸识别网络提取的高维特征向量构成感知损失来保留生成图的身份信息。

其中:φ(·)定义为预训练的人脸识别网络Light CNN 提取的最后一层全连接层的特征,由于Light CNN 是在大规模人脸数据集上进行训练,它可以提取到更为普遍、更为显著的人脸特征表示向量2范数。
3.4 多尺度像素级损失
按照文献[7],加入多尺度像素级损失来确保生成图像Igen和基准图像Igt在内容上的一致性,此外也可提高生成图像Igen的逼真程度。

其中:i表示第i个图像尺寸,分别在图像尺寸为128×128、64×64、32×32大小的生成图Igen和真实图Igt之间计算像素值的L1距离;C表示图像的通道数,Wi和Hi分别表示对应分辨率图像的宽和高。
3.5 对抗损失
Sym-GAN 由两部分组成:生成器G 和判别器D。判别器D 的目的是从真实图和生成图中区分出真实图。生成器G 的目的是生成接近真实的图像以欺骗判别器。生成器和判别器之间的训练[12]可表示为:

对抗损失Ladv可以帮助生成图在视觉感官上产生较好的效果。
3.6 对称损失
文献[7]提出的对称损失,可以有效地缓解自遮挡问题以提高模型在大角度姿态下的正面化生成性能。

其中:W-(w-1)表示生成图Igen中w位置的对称横坐标。
3.7 总变分正则化
通常,GAN 模型生成的图像会产生许多的人工伪影,干扰视觉质量和识别性能,按照文献[3],在生成图像中加入了总变分正则化项以缓解这一问题。

其中:W和H表示最终生成图像的宽和高。
4 实验与结果分析
Sym-GAN 的核心目标是根据包含多角度变化的侧脸合成其逼真的正面人脸,同时能够保留足够的身份信息。在4.2节中展示了提出的Sym-GAN 在公开数据集上的定性正面化合成效果,在4.3 节中定量评估了Sym-GAN 对人脸识别网络的增强效果。在4.4 节中,针对Sym-GAN 不同结构变体和损失函数变体进行了消融实验,以分析其各自的作用。
4.1 实验设置
CAS-PEAL-R1 数据集是一个公开的大规模中国人脸数据集,它涵盖了姿态、表情、装饰物和光照等变化。该数据集总共包含1 040 个人的30 863 张灰度图像,其中男性有595人、女性有445 人。本文中只使用含有姿态变化的图像,包含7 个偏转角度(0°,± 15°,± 30°,± 45°)和3 个俯仰角度(0°,± 30°),共21 种角度变化。使用前600 人构成训练集,剩下的440人构成测试集。
使用人脸检测模型Retinaface 对图像进行预处理,将CAS-PEAL-R1 数据集中用于实验评估的所有图像裁剪到分辨率为128×128,并且为了保证正面化的效果,对所有基准正面图像进行对齐处理,即保证左右眼特征点处于同一水平线上,且确保两眼连线的中点落在裁剪后图像的中点上。用于计算身份损失的预训练人脸识别网络Light CNN-29在训练期间参数固定,眼周区域大小选取数据集眼周矩形框的平均尺寸。本文的模型采用Pytorch 深度学习框架实现。选择β1为0.9,β2为0.99 的Adam 优化器,学习率为2-4,图像分辨率为128×128 时设置batch size 为16。在一张NVIDIA Tesla P100 GPU(16 GB)上训练网络。在所有实验中,依据经验分别设置权重参数λ1,λ2,λ3,λ4,λ5,λ6为0.01,0.05,150,0.1,0.01,1。
4.2 人脸正面化效果
本文以侧脸图像作为输入图像,以偏转角和俯仰角都为0°的正面图像作为基准图像训练网络。图7所示为Sym-GAN在各个俯仰角的生成结果。可以观察到,生成图像和基准图像不仅在全局的面部结构上保持一致,同时在眉毛和眼型等局部细节上也与基准图像接近,证明了本文提出的眼周特征保留损失对局部区域特征保留具有一定的作用。

图7 Sym-GAN在CAS-PEAL-R1数据集上不同俯仰角的生成正面人脸图像Fig.7 Frontal images generated by Sym-GAN on images with different pitch angles in CAS-PEAL-R1 dataset
本文提供了一系列人脸正面化方法的生成结果与Sym-GAN 进行比较,包括TP-GAN[7]、完整表示生成对抗网络(Complete Representations Generative Adversarial Network,CRGAN)[24]、M2FPA[8]、DA-GAN[16],生成效果对比结果如图8 所示。由图8 可以看出,在眼周部分Sym-GAN 模型的生成效果相较其他方法与基准图像更为接近。此外,相较其他方法在判别器加入一些区域约束,会造成其他区域出现模糊的现象,本文方法使用相对简单的判别器结构,保证了面部整体细节的一致性。

图8 CAS-PEAL-R1数据集上不同方法的比较Fig.8 Comparison of different methods on CAS-PEAL-R1 dataset
4.3 姿态无关的人脸识别
人脸正面化可以作为人脸识别模型的一种预处理操作,所以使用人脸识别准确率作为评价指标来评估不同正面化方法的身份保留能力。识别准确率越高,人脸合成过程中保留下的人脸特征越多,正面化合成的效果越好。因此,本文在CAS-PEAL-R1数据集上定量验证Sym-GAN 模型“通过生成再进行识别”的有效性。把Sym-GAN 模型作为预处理操作,然后使用预训练人脸识别模型Light CNN 作为人脸特征提取器,并使用距离度量计算生成图像和真实图像对之间的相似度。表1 所示为不同方法在CAS-PEAL-R1 数据集上的Rank-1 识别准确率。从表1 中可以观察到,在一些极端角度上,本文的方法可以得到更高的识别准确率,证明了本文方法在侧脸正面化任务上的有效性。
4.4 消融实验
为了验证Sym-GAN 模型的优势以及其各个组成部分的贡献,进行了消融对比实验。图9为本文方法与其3个不完全变体在CAS-PEAL-R1数据集上的可视化比较结果。从图9可以看出,若消去总变分正则化损失,会产生更多的人工伪影;若消去身份信息保留损失,在脸型轮廓上和基准图像差距较大;此外,加入眼周特征保留损失,可以使眉毛和眼型上与基准图像更加接近,并且网络训练中有无眼周特征保留损失对身份信息保留损失收敛的对比如图10(a)和(b)所示,加入眼周特征保留损失有助于身份信息保留损失的收敛,从而对面部全局身份信息保留起到一定积极作用。表2 为本文方法与其3 个不同变体在CAS-PEAL-R1 数据集上的Rank-1 识别率,也可以展示出身份保留损失和眼周特征保留损失在身份信息保留过程中的有效作用。

表1 CAS-PEAL-R1数据集上不同方法的Rank-1识别率 单位:%Tab.1 Rank-1 recognition rates of different methods on CAS-PEAL-R1 dataset unit:%

图9 Sym-GAN模型及其变体在CAS-PEAL-R1数据集上的生成效果Fig.9 Generation results of Sym-GAN model and its variants on CAS-PEAL-R1 dataset

图10 身份信息保留损失曲线对比Fig.10 Comparison of identity information preserving loss curves

表2 CAS-PEAL-R1数据集上各消融结果的Rank-1识别率 单位:%Tab.2 Rank-1 recognition rates of ablation results on CAS-PEAL-R1 dataset unit:%
5 结语
本文针对多角度侧脸正面化问题提出了一种基于面部特征图对称和眼周特征保留损失的生成对抗网络模型。首先,根据人脸对称性这一先验知识,本文提出了特征图对称模块,用于缓解大角度姿态下人脸存在的自遮挡现象造成正面化生成较为困难的问题。此外,受益于眼周区域相较于面部其他五官,具有较高的判别能力,加入了眼周特征保留损失使得在生成过程中对眼周区域增大关注,从而提高生成图的身份信息保留程度。定性的正面化结果和定量的人脸识别性能的实验验证了本文方法的有效性。同时,将对面部各五官特征对人脸识别的贡献度进行调研,在眼周保留损失的基础上尝试加入面部其他高辨别区域的身份特征保留从而进一步提高生成人脸的效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
传感器世界(2022年3期)2022-05-24
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
数字技术与应用(2021年1期)2021-03-24
现代信息科技(2019年18期)2019-09-10
科技创新与应用(2017年26期)2017-09-12
中国信息技术教育(2016年13期)2016-09-10
米娜·女性大世界(2016年8期)2016-08-17
