
基于高斯差分特征网络的显著目标检测
2021-03-18 13:45,2*
计算机应用 2021年3期
,2*
(1.武汉科技大学信息科学与工程学院,武汉 430081;2.中冶南方连铸技术工程有限责任公司,武汉 430223)
0 引言
显著性检测旨在从图像中找出最吸引人类视觉注意的目标或区域,其研究成果已被用在众多计算机视觉任务中,例如目标识别[1]、图像分割[2]等。从1998 年Itti 等[3]的研究工作开始,计算机视觉领域的学者对于显著性检测模型的研究热情持续至今。考虑到显著区域在视觉表征上应当和周围有明显不同,一个很自然的想法是通过计算某个像素/区域与其周围像素/区域之间的差异性,即中心-邻域对比度(Center-Surround Contrast,CSC)来计算区域的局部突出程度。该思路在相当长一段时间内是显著性检测领域的主要线索[3-5]。Itti等首次提出了一个可计算的视觉注意力模型,其通过在多尺度的高斯差分(Difference of Gaussian,DoG)特征(强度、颜色和梯度)空间中计算某一像素的CSC值,并以其局部最大响应作为该像素的显著值,为了描述方便,本文称之为“DoG 金字塔特征整合模型”。考虑到尺度空间能够较准确地描述人眼在不同的距离上观测物体的感知情况,利用多尺度DoG 空间可以很好地模仿人眼检测目标的局部突出特性。因此,Itti等提出的模型有一定的生理学基础,对后续模型研究设计具有指导性意义。以此模型结构为基础,研究学者在多种特征空间以及不同的对比度测度上进行了创新[5-7]。此外,也有研究针对CSC 计算中邻域的选择问题进行了相关探讨[8-10]。然而,上述方法均采用手工定义的低层次视觉特征,无法有效地对图像中的上下文以及语义信息进行理解,导致在目标级别的显著性检测中难以取得满意的性能。
作为任务导向型学习方法,卷积神经网络(Convolutional Neural Network,CNN)通常能够根据具体任务从图像中学习到具有多层级视觉表征能力的特征。近些年,随着CNN 理论的快速发展,显著目标检测的研究工作逐渐从传统的、以人类经验定义视觉特征和采用经典线索的显著目标检测模型设计迁移到以CNN 为基础的模型设计中。得益于Long 等[11]在语义分割领域提出的全卷积神经网络(Fully Convolutional Network,FCN),考虑到显著目标检测可以看作是一种特殊的分割任务,基于FCN 的模型在显著目标检测任务中得到了广泛应用。FCN 虽然能够较好地保存空间信息,但由于深层特征通常缺乏图像中的细节部分,从而导致检测效果并不理想。为了解决这个问题,后来的研究提出了有效的多层特征融合结构。Li等[12]提出了一种由完全卷积流和分段空间池流组成的架构。完全卷积流可以直接从输入图像中得到像素级的显著性图,分段空间池流可以有效地提取各阶段特征,将两个分支架构得到的特征图相加融合后通过密集条件随机场来进一步优化检测结果。Chen 等[13]则将短接法[14]用于分割网络,同时使用残差模块来学习侧输出的特征,这种学习方法在保证检测效果的前提下使模型更加轻量化。然而,短接法在融合不同特征层时会不可避免地引入噪声,为了解决这个问题,研究学者提出循环细化的方法,通过逐步细化显著图以得到效果更好的显著性检测结果。例如,Wang等[15]提出一种多阶段的循环细化方法,其思想在于使用网络的低级特征来细化显著性图,通过不断更新显著目标的边界以实现高精度分割。
在分割任务中,准确理解图像中上下文信息的语义关系通常需要网络特征层具有较大的感受野。例如DeepLabv3+(encoder-decoder with atrous separable convolution for semantic image segmentation)[16]和 PSPNet(Pyramid Scene Parsing Network)[17]通过不同的金字塔池化过程以增大深层特征的语义表达能力。注意力模型则是解决该问题的另一种思路,其通过对像素的长距离空间信息进行编码以达到对目标上下文的理解[18-19]。例如,Ren 等[20]提出的金字塔自注意力模型(Pyramid Self-Attention Module,PSAM)通过在特征金字塔之后加入自注意力模块以获得更加丰富的深层特征,同时也为整个网络模型引入了更大的感受野。
本文发现DoG金字塔特征整合模型作为一种早期广泛使用的、基于注意力机制的显著性模型却在卷积神经网络中较少被使用。事实上已有少量方法在网络构造过程中部分使用了CSC线索。例如,Li等[21-22]串联某个超像素和环绕它的超像素的深度特征以学习其显著程度;然而,该方法并未明确计算中心超像素与其周围超像素的特征差异。Wang等[23]将深度特征与手工特征进行了融合,并在单个尺度上计算目标级别的对比度。然而,手工特征通常在语义表达能力上弱于CNN特征。
受上述问题的引导和启发,本文将DoG金字塔特征整合模型的基本结构引入CNN,并提出了一个基于DoG 特征的显著目标检测网络。该网络通过在多个尺度的深度特征上构造DoG金字塔结构以感知图像中显著目标的局部突出特性,进而用此差分特征对语义信息丰富的原始深度特征进行加权选择,最终实现对显著目标的准确提取。将本文算法与六种最新的显著目标检测算法在四个公用数据集上进行对比,实验结果表明,本文所提出的网络结构在多项指标上优于其他算法。
值得注意的是,Li 等[12]的方法也讨论了利用对比度特征来获取显著区域,但是该方法通过将中心区域和周围区域的特征连接起来以表征区域的突出特性,实际上并没有显式地计算区域的局部对比度。本文通过构建DoG金字塔在多个尺度上计算中心与邻域的特征差异来感知图像的局部突出特征,最终实现对目标的提取。
综上所述,本文的主要工作如下:
1)传统的DoG 特征金字塔整合模型具有生理学依据支撑,但受限于特征表达能力在复杂场景中,以及目标级别的显著性检测任务中表现不佳。本文验证可知,基于DoG 的CNN特征同样具有检测显著区域/目标的局部突出特性的能力,且一定程度上解决了传统手工定义特征难以有效表达上下文信息以及高级语义信息的问题。
2)提出了一种基于DoG 特征的显著目标检测网络模型。首先,通过在主干网络侧面输出的多尺度深度特征上构造DoG 金字塔以得到具有突出显著目标能力的差分特征;然后,利用基于注意力机制的非局部模型将差分特征和主干网络输出的完备特征进行融合以选择后者中有效的部分用于计算最终的显著图。
1 通用DoG金字塔特征整合模型解析
在这一章,本文首先对常见的DoG 金字塔特征整合模型进行简要介绍,并给出DoG 金字塔中参数的计算方法。如图1所示,对于一幅输入图像:
1)首先提取人工定义的视觉特征,例如颜色、纹理、梯度等密集特征类型。
2)对于每一种独立类型的特征F在尺度空间中进行表达,即构造多组高斯金字塔:
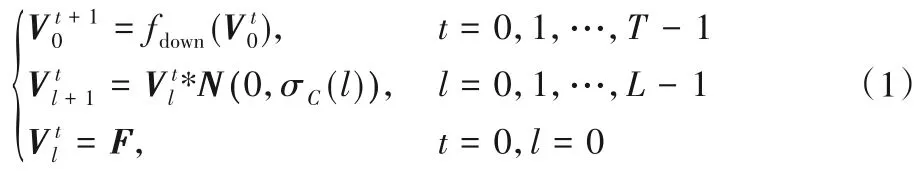
其中:T为高斯金字塔的组数;L为每组高斯金字塔中特征层数;fdown(⋅)为降采样操作函数;N(0,σC(l))为均值为零、标准差为σC(l)的高斯核函数。即针对每一种特征构造T组尺度,在每个尺度中包含L个经过高斯平滑后的中心特征。

并通过像素级的差分操作以获得当前层的注意力子图,并累积所有注意力子图作为最终的显著图像R。

类似SIFT(Scale-Invariant Feature Transform)[24],DoG 金字塔中σC(l)的计算采用以下方式进化:

其中,σC(0)和σS(0)为进化过程的起始种子参数,且满足条件σS(0)>σC(0),在实际计算时要预先确定。
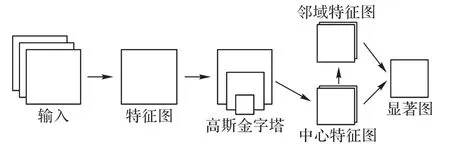
图1 基于DoG金字塔特征的显著性检测模型Fig.1 Saliency detection model based on DoG pyramid features
2 基于DGP的显著目标检测网络
正如引言中所述,DoG 金字塔特征整合模型在传统显著性检测中曾作为一种主流框架,但在目标级别的显著性检测任务中性能有限。本文认为其根本问题在于手工定义特征难以对大范围上下文以及高层语义信息进行有效编码,而CNN特征则能较好地弥补这个不足。受此启发,本文提出了基于高斯差分金字塔(Difference of Gaussian Pyramid,DGP)的显著目标检测模型。
2.1 高斯差分金字塔模块
如图2 所示的整体网络结构图,DGP 模块的输入来自主干网络侧方引出的四个输出,因此本文针对性地构造了四个金字塔组,表示为O=图3 给出了Ot的结构图,其使用一个3× 3的卷积层来调整输入特征的通道数,随后将特征送入多层DoG计算模块。以第l层为例,首先通过中心平滑层结构计算中心高斯平滑特征,并以此作为输入利用邻域平滑层结构计算邻域高斯平滑特征。值得注意的是,由于卷积核的尺寸一般都是奇数,即满足(2Y-1)×(2Y-1),其中Y为正整数,所以卷积核的高h和宽w满足h=w=2Y-1,同时由于高斯分布服从“3σ原则”,即随机变量的取值分布在区间(μ-3σ,μ+3σ)内的概率为0.997 3(μ、σ分别是高斯分布的均值和标准差)。所以为了让数值最大可能地落入所确定的范围内,就把模板范围取值为6σ,同时为了兼顾卷积核尺寸为奇数的特点,所以高斯核方差和对应卷积核参数有如下关系:
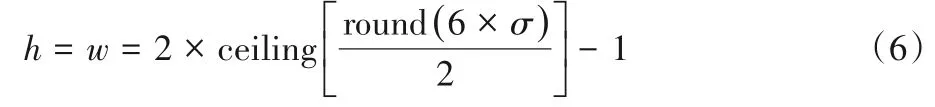
其中:h和w分别是标准差为σ的正态分布对应的卷积核的高度和宽度;ceiling(⋅)和round(⋅)分别表示向上取整和四舍五入的操作。可以看到,σ的进化过程会导致卷积核尺寸的扩大,进而影响网络训练和推理速度,因此,本文在中心平滑层和邻域平滑层中采用两个一维卷积来代替二维卷积操作,此操作不但不会改变卷积核的整体尺寸,同时还会降低卷积操作过程中的计算复杂度,这是因为在两个维度相互独立的条件下,二维高斯卷积核可以分离成两个一维的高斯核,并且卷积操作的计算复杂度将明显降低。另外如果使用二维高斯卷积,计算复杂度可以表示为(2Y0+1)次乘法和加法运算,其中Y0是正整数,转换成两个一维卷积之后,计算复杂度可以表示为2Y0次加法运算和Y0+1 次乘法运算[25]。图4 给出了当σC(0)和σS(0)分别取1.0 和1.7 时,l=0 即第一层高斯平滑子模块的内部结构。为了使参数始终维持高斯分布状态,本文在网络训练的反向传播过程中不更新其参数。特别地,本文在高斯平滑卷积后加入了两个如图5 所示的残差卷积单元结构,其目的是对差分特征进一步做非线性变换以增强其特征泛化能力,其中的BN(Batch Normalization)为批量归一化层;ReLU(Rectified Linear Unit)和sigmoid为激活层,且后者同时将特征幅值归一化到(0,1)。由于显著目标检测相当于对像素进行二分类,所以在此结构的输出部分使用了sigmoid 函数,同时为了防止由于梯度消失而导致的模型收敛停滞,也使用了多个ReLU 激活函数。最后,将Ot内所有层的差分特征进行逐像素相加,并通过通道注意力模块[19]来选择性地强调存在相互依赖的通道映射。
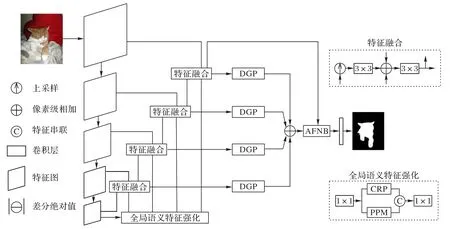
图2 网络结构Fig.2 Network structure
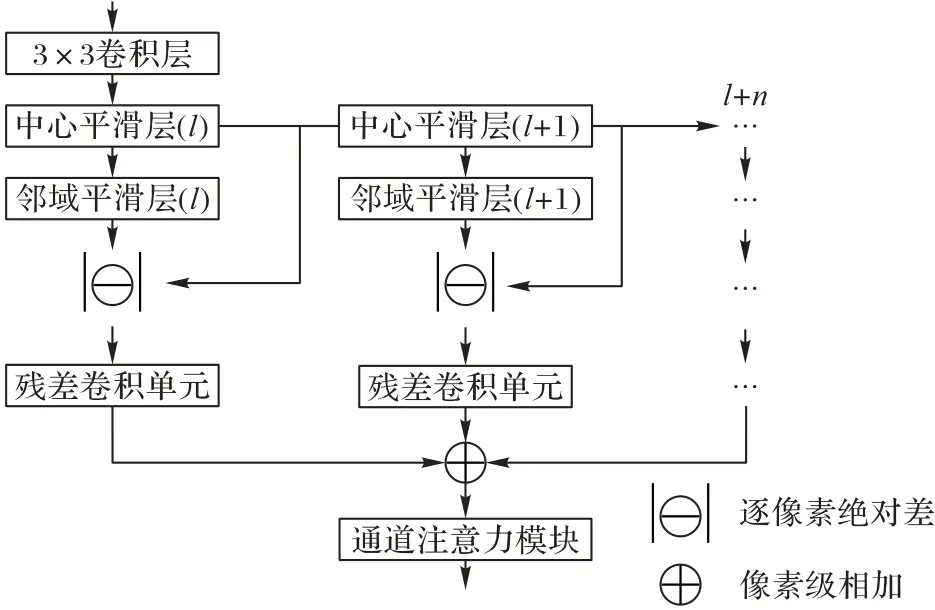
图3 高斯差分金字塔模块结构Fig.3 Difference of Gaussian Pyramid module structure
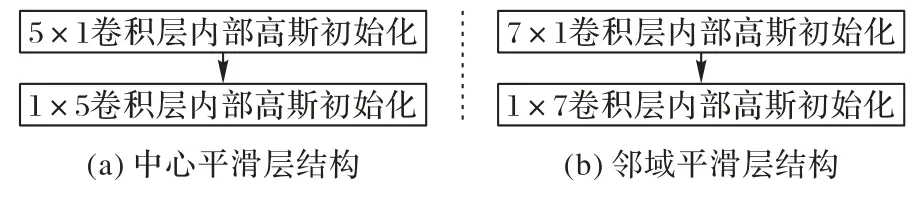
图4 高斯平滑模块结构Fig.4 Gaussian smoothing module structure
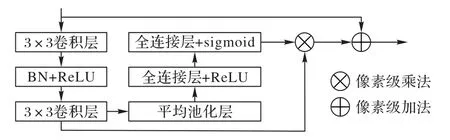
图5 残差卷积单元结构Fig.5 Residual convolution unit structure
2.2 网络整体介绍
本文提出的网络结构如图2 所示,其构型是以ResNet-50[26]网络作为骨架的U型结构。考虑到分割任务需要兼顾图像细节以及高层语义信息,因此选择特征金字塔网络(Feature Pyramid Network,FPN)[27]作为主干网络框架来提取输入图像的特征。为了加强网络对语义信息的有效抽象,在自上而下的路径顶部引入金字塔池化模块(Pyramid Pooling Module,PPM)[17]和链式残差池化(Chain Residual Pooling,CRP)[28]的并行结构,并与主干网络中多尺度的侧方输出特征进行融合作为DGP 模型的输入特征,即可以类比式(1)中的独立类型的特征F。融合后的特征依次经过本文所提出的DGP模块进行差分运算以获取图像中各个层次信息的局部突出特性,并最终通过注意力模块AFNB[18]来选择性地对主干网络U 型结构的顶层特征中的有效特征进行融合,进而送入分类层以获得最终的检测结果。
3 实验与结果分析
为了验证所提网络模型的性能,本章中选取了6 个显著性目标检测模型和本文所提出的模型在4 个公用数据集上进行实验并进行结果对比。同时为了验证所提出网络模型中各个模块对整体性能的影响和在整个网络模型中所起到的作用,本文也进行了多次消融实验。
3.1 数据集介绍
为了评估所提出的显著性目标检测模型的性能,本文在DUT-OMRON[29]、DUTS-TE[30]、Pascal-S[31]和SOD[32]4 个公用数据集上进行了实验。其中,DUT-OMRON 数据集包含了5 168张图像,最大边长为400 个像素,每张图像中具有一个或多个显著目标,且具有相对复杂的背景。DUTS 数据集包含了10 553 张训练图像(DUTS-TR)和5 019 张测试图像(DUTSTE),其中都包含了日常生活中非常重要的场景。Pascal-S 数据集共有来自PASCAL VOC 子集的850 张图像。SOD 数据集对BSD 数据集中显著对象进行了重新标注,共包含300 张图像。
3.2 评价标准
按照本领域通用评估体系,本文使用平均绝对误差(Mean Absolute Error,MAE)、F 度量值(F-measure)和精确率-召回率(Precision and Recall,PR)曲线三种评价标准来较全面地评估所提模型的性能。
PR 曲线的绘制数据是通过使用一系列固定阈值对检测结果进行分割所获得。具体来说,对于一幅具有8 位灰度范围的结果图像,使用所有可能的255 个分割阈值对图像进行分割,并记录每次分割结果与人工标注之间的差异性。该差异性通过精确率和召回率来量化,计算方式如式(7)、(8)所示:

其中:TP(True Positive)、FP(False Positive)和FN(False Negative)分别表示正阳性、负阳性和负阴性。即针对预测值和真实值中的每个像素来说,TP表示预测值为1,真实值为1,即正样本被预测为正;FP表示预测值为1,真实值为0,即负样本被预测为正;FN表示预测值为0,真实值为1,即正样本被预测为负。
F 度量值表示在非负权值β下精确率和召回率的加权调和平均值,可以比较全面地反映所提算法的性能,计算方式如式(9)所示:

其中:β是权重系数,用于平衡精确率和召回率之间的权重,β2的取值一般为0.3[33]。
平均绝对误差表示预测值与真实值之间绝对误差的平均值,可以反映预测值偏离实际值的具体程度,计算方式如式(10)所示:

其中:D表示一幅图像中像素点的总个数;yi表示第i个像素点的预测值;y表示第i个像素点的真实值。
3.3 网络参数配置
本文的模型在主干网络中采用ResNet-50 来进行图像的特征提取,同时采用在ImageNet 数据集上预训练的结果来进行主干网络的初始化,其余网络参数随机初始化。式(3)、式(4)和式(5)中的L取值3,σC(0)和σS(0)分别取值1.0和1.7。损失函数选用二分类交叉熵损失函数,网络采用Adam 优化器进行训练,Batch size的值设为4,学习率初始化为0.000 1。
3.4 结果分析
将本文所提算法和近年来的部分优秀显著性目标检测算法进行了定性和定量比较,对比算法包括NLDF(Non-Local Deep Features for salient object detection)[34]、DSS(Deeply Supervised Salient object detection with short connections)[35]、DGRL(Detect Globally,Refine Locally:a novel approach to saliency detection)[36]、PiCANet(learning Pixel-wise Contextual Attention Network for saliency detection)[37]、PAGE-Net(salient object detection with pyramid attention and salient edges)[38]、BASNet(Boundary-Aware Salient object detection)[39]。NLDF 是基于VGG16[40]模型提出的一个结合局部和全局特征的端到端神经网络。DSS 提出了一种有效的强监督短接结构,可以连接深层特征图和浅层特征图,从而可以更好地定位显著区域。DGRL 提出了一个新颖的RLN(Recurrent Localization Network)结构,以权重响应图的方式来利用上下文信息,使得显著性目标更加突出,同时也提出一个BRN(Boundary Refinement Network)来有效恢复图像边界。PiCANet 通过整合全局上下文信息和多尺度的局部上下文信息来提升显著性检测的性能。PAGE-Net 提出金字塔注意力模块和显著性边缘检测模块用于联合优化显著目标检测结果。BASNet 通过引入一个深度监督的编解码器和一个残差优化模块,并引入了一个新的混合损失函数等方法提高了显著性目标检测的性能。
3.4.1 定性评价
从图6各个网络得到的最终显著图可以看出,与其他六种算法相比,本文算法对复杂环境中小目标的检测更加准确,例如对于第一幅图像,其他算法都无法检测出雪地里靠近右边的汽车,但本文的算法则在一定程度上反映出了右边汽车的大致轮廓。本文算法也能够更好地分割出目标的细节部分,例如对于第三幅图像,仅本文的算法能够成功分割出运动员手中的运动器械。同时,在图像背景较为复杂且与显著目标在颜色、纹理等方面有较大相似的情况下,本文的算法也能得到较好的结果,例如对于第五幅图像,本文的算法在显著目标处于较大外界干扰的情况下,也能获得与人工标注最接近的结果。

图6 七种算法在四个公用数据集上部分图像的检测结果对比Fig.6 Detection results comparison of some images of seven algorithms on four public datasets
3.4.2 定量评价
表1 和图7 给出了本文算法和其他六种算法在四个公用数据集上的定量评价结果,包括MAE、F-measure 和PR 曲线。从表1 可以看出,本文的算法在两个常用评价指标的比较中一致地优于其他六种检测算法。从图6 给出的在四个公用数据集上的PR曲线可以看出,本文的算法也在至少85%的召回率范围上取得了最高的精度,表明本文算法可以适应绝大部分情况下的显著性目标检测并能够得到比较优秀的结果。
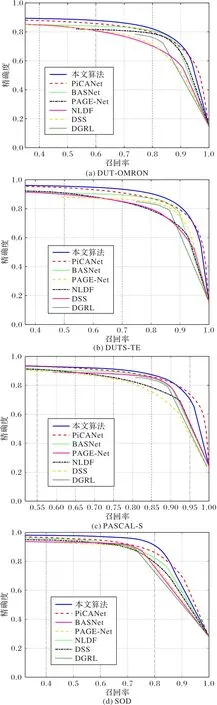
图7 七种算法在四个公用数据集上的PR曲线Fig.7 PR curves of seven algorithms on four public datasets

表1 七种算法在四个公用数据集上的定量比较Tab.1 Quantitative comparison of seven algorithms on four public datasets
3.5 消融实验
在本小节,将通过多个消融实验来验证本文所提出的DGP模块和其他部分结构在显著目标检测过程中所起到的作用和对最终结果的贡献程度(以下陈述中,baseline 表示移除DGP模块之后的网络结构),定量比较的结果如表2所示。
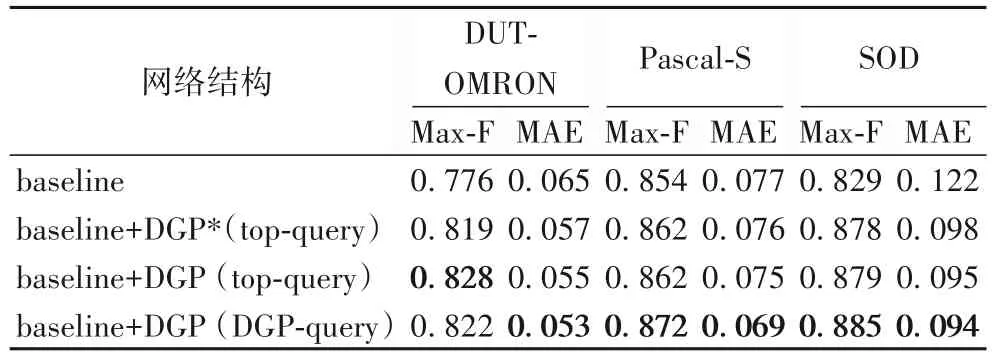
表2 不同模块的消融实验Tab.2 Ablation experiments of different modules
1)当网络结构为baseline 时,由于缺少了DGP 模块,整个模型缺少了构建高斯差分金字塔的部分,也就无法计算中心特征图和邻域特征图的差异。当加入DGP 模块之后,通过评估标准MAE 和F-measure 的数值可以发现,网络对显著物体的检测能力有了比较大的提升,尤其是在SOD 数据集上,F 度量值有5.91%的提升,平均绝对误差则有19.67%的下降。值得注意的是,本文在该实验中移除了残差卷积单元以更加直接地评估差分特征的功能。表2 中DGP*表示不包含残差卷积单元的DGP模块。
2)在1)的基础上,在DGP 模块中加入残差卷积单元之后,网络的性能又有了一定的提升,主要原因是:DGP 模块中的高斯核是线性核,无法解决较为复杂的问题,残差卷积单元可以为DGP 提供非线性能力,可以更好解决显著性检测中的复杂问题。
3)AFNB(Asymmetric Fusion Non-local Block)模块采用“查询-键值对”的方式融合差分特征和主干网络的顶层特征,因此,很自然地具有两种融合方式。本文认为,主干网络的顶层特征中包含了丰富的对显著目标检测有效的各类信息,而差分特征主要显式地描述了CSC信息。将差分特征作为“查询”项可以强化主干网络特征中关于CSC类信息的权重,同时也一定程度上保留了其他非CSC类的信息,实验结果如表2第4行所示。同时,本文也尝试将主干网络顶层特征作为“查询”项,其结果如表2第3行所示。实验结果也可以看出,利用差分特征作为“查询”项的设置下,除了在DUT-OMRON数据集的F度量值出现微小下降外,在其他数据集以及测度上均占优势。尤其是对Pascal-S 数据集,其平均绝对误差有8%的下降。表2 中top-query 表示采用主干网络的顶层特征作为“查询”项,DGPquery表示采用DGP模块的输出作为“查询”项。
4 结语
本文提出了基于DoG金字塔的显著目标检测网络。该网络利用特征金字塔来提取输入图像的特征,在自上而下路径顶部引入金字塔池化模块和链式残差池化模块的并行结构,以此来获取图像的高级语义信息。在网络自上而下的各阶段创新地引入DoG金字塔模块来提升网络对显著物体的检测能力。通过在四个公用数据集上与六种显著性目标检测算法进行比较,结果表明在平均绝对误差、F 度量值和精确率-召回率曲线等定量评价指标上,本文提出的算法具有更好的检测准确性,因此能够有效提高显著目标检测的能力。但是此算法的一个不足之处是对于异常大型的显著目标检测效果不太理想,检测能力还有待提升,可以作为进一步的研究方向。
猜你喜欢
环球时报(2022-09-19)2022-09-19
农业工程学报(2022年12期)2022-09-09
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年7期)2021-11-17
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
考试与评价·七年级版(2020年4期)2020-10-23
中国知识产权(2018年12期)2018-12-29
小学教学研究·新小读者(2017年9期)2017-10-25
