
基于数据挖掘的数据库语言查询过程分析
2021-03-17 08:13:04侯阳青
微型电脑应用 2021年2期
侯阳青
(福州职业技术学院 阿里巴巴大数据学院, 福建 福州 350108)
0 引言
数据库应用以及信息检索系统的普及,为用户带来方便的同时,也为数据库应用带来了一定的挑战。越来越多非专业用户的参与,用户对于数据库操作简单、查询界面要易于掌握的需求越来越明显。数据库传统查询接口为图形接口,具有较多的缺陷,例如操作过程复杂、对硬件要求高、耗费资源多和使用性能低等。这些缺陷导致数据库应用发展较为缓慢。鉴于此,自然语言查询接口重新出现在人们的视野之中,成了数据库应用领域研究的热点[1]。
数据库自然语言界面的出现,解决了非专业用户访问数据库信息的难题,用户可以依据人类语言向数据库发问,以此来获取自身所需要的信息与数据,大大地提升了人机交互的容易程度,降低了数据库系统应用的难度。自然语言查询界面实质上指的是用户通过自然语言对数据库发出各种操作指令,系统将其转换为数据库操作语言,从而在数据库中查询到正确的信息,将其反馈给用户。这种查询方式避免了现实世界与机器世界对信息不同理解的难题,具有重要的研究价值[2]。
近几年,国内外均对数据库语言查询过程进行了深入的研究与分析,并取得了一定的成果。国外代表性研究成果为LIFER系统与基于模糊集理论的语言查询系统。LIFER系统具有通用性以及极高的自然语言处理速度,被多个领域所应用;基于模糊集理论的语言查询系统可以定性分析语法不完整的查询语句,提高了系统的人性化,增加了数据库系统的易用性。但现有数据库语言查询过程分析方法由于词法切分有误,导致复杂查询语句存在着查询准确率低的问题。为此本研究提出基于数据挖掘的数据库语言查询过程分析方法研究,数据挖掘是指在通过算法在大量数据中搜索隐匿信息的过程[3],通过数据挖掘的引用,可以提升数据库语言查询的准确率。
1 数据库语言查询过程分析方法研究
1.1 查询语句结构分析
处理自然语言查询语句的首要任务就是要分析查询语句结构。依据调查研究发现,在数据库查询时,用户使用祈使句与疑问句的频率较高,多语句与省略句比例较小[4]。确定查询语句类型,如表1所示。

表1 查询语句类型表
其中,疑问句还可以细分为选择问句、正反问句和特质问句。需要注意的是,疑问句与是非问句在问法上存在着较大的不同,所以处理过程截然不同,故将其看作为两类查询问句[5]。
在语言查询过程中,最关键的就是分清查询目标与查询条件,为此,依据查询目标与条件为基础,划定查询语句结构。以数据库角度来看,查询语句基本成分包括疑问词、查找词、连词、语助词、标点符号、量词、条件类比较词、属性值、对象名称、格标和领域动词等。其中,属性值、对象名称和领域动词与具体应用相关,将其称为专用词类,剩下的基本成分称为通用词类。
在实际的数据库语言查询语句中,专用词类与通用词类共同构成了查询目标与查询条件[6]。通过分析得到查询语句结构主要有四种,具体情况如下。
第一种:一般祈使句结构。表示为:<查询条件1 查询条件2 …查询条件m><查询目标1 查询目标2 …查询目标n>;
第二种:特殊祈使句结构。表示为:<查询条件1 查询条件2 …查询条件m1><查询目标1><连词><查询条件1 查询条件2 …查询条件m2><查询目标2><连词>…<查询目标n>;
第三种:一般疑问句结构。表示为:<查询目标1 查询目标2 …查询目标n><查询条件1 查询条件2 …查询条件m>;
第四种:是非疑问句结构。表示为:<查询条件1 查询条件2 …查询条件m1><查询目标1><动词><查询条件1 查询条件2 …查询条件m2>。
1.2 查询语句分词
依据上述分析得到的查询语句结构为基础,结合自然语言的特点,利用最大匹配法分词处理查询语句,如图1所示。
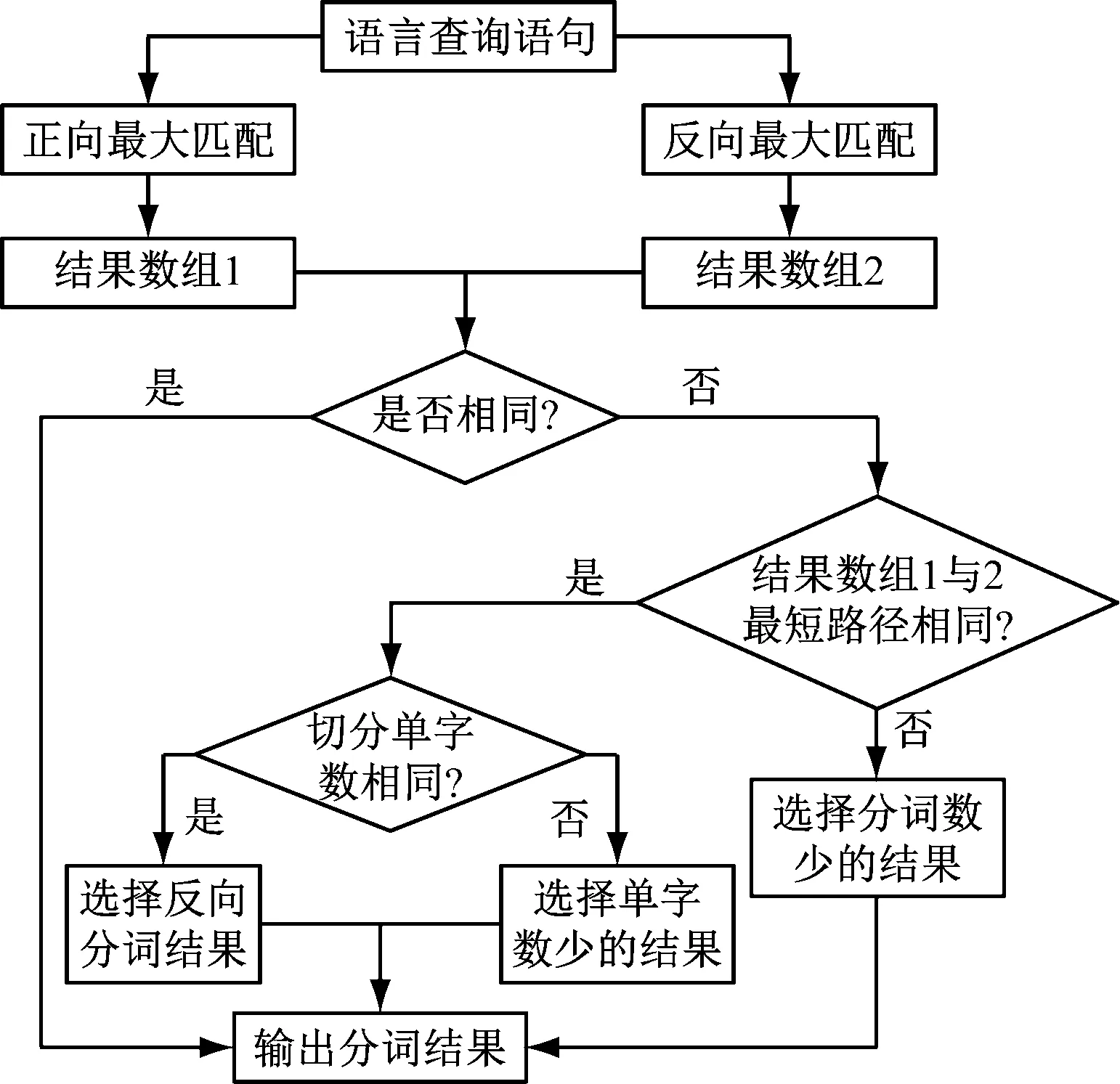
图1 查询语句分词流程图
依据图1流程得到查询语句分词结果,为了保障分词结果的准确性,需要消除歧义词,并实时更新分词应用过的知识库[7]。
1.3 查询目标与条件识别
依据查询语句分词结果,通过数据库语义分析来识别查询目标与查询条件。查询条件的功能是限定查询范围[8],查询条件主要分为显性条件与隐性条件。显性查询条件识别流程,如图2所示。
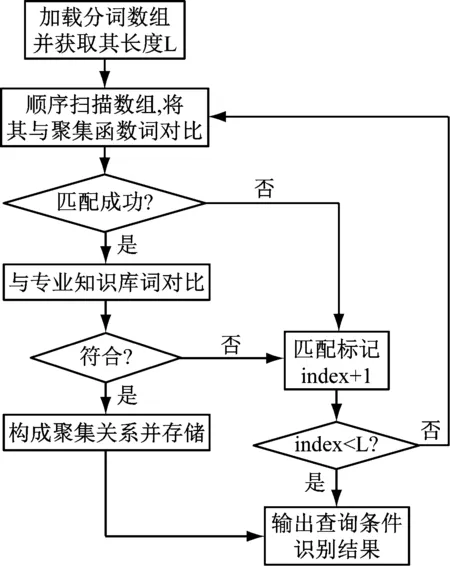
图2 显性查询条件识别流程图
隐性查询条件识别需要依据领域专业知识库的复合词汇文件以及映射文件去寻找,直至找到为止;若是查询失败,将其定义为新词,对系统接口进行更新。
查询目标识别实质上是寻找用户需求信息,查询目标与具体数据库具有紧密的联系,常规情况下,查询目标为属性名或其函数,包括属性词目标、疑问词目标、聚集目标以及复合推理目标[9]。
针对查询语句结构特征,得到查询目标获取算法步骤如下。
步骤一:加载语言查询语句分词结果数组;
步骤二:查询目标位置不确定,为此,以顺序扫描方式扫描数组的内容,将其与疑问词文件对比,若是匹配成功,执行疑问词与数据库属性信息对应,转至步骤五;若是匹配失败,转至步骤三;
步骤三:以逆序扫描方式扫描数组的内容,将其与领域专业知识库中的逻辑推理文件、映射文件和复合词汇文件对比,若是匹配成功,转至步骤四;若是查询语句没有确切的查询目标,数据库系统默认所有属性信息,转至步骤五;
步骤四:将步骤三结果与聚集函数文件对比,若是匹配成功,将查询目标合并为属性名,转至步骤五;若是匹配失败,直接将目标属性作为查询目标,转至步骤五;
步骤五:将获取的查询目标存储为结构体数组。
需要注意的是,在查询目标识别过程中,需要一定的规则支撑,例如标记符号消除规则等,由于篇幅限制,在此研究中不一一列出。
1.4 自然语言查询到SQL语句的转换
依据识别的查询目标与查询条件,构建语义依存树,划分为集合块,通过综合转换算法转换为SQL语句,为用户需求数据挖掘空间定位做准备[10]。
语义依存树构成,如表2所示。

表2 语义依存树构成表
语义依存树包含了查询语句的全部信息,为了简便自然语言查询到SQL语句转换的过程,将语义依存树划分为多个集合块。
语义依存树集合块划分算法如下。
输入:语义依存树DpRt;
输出:集合块的根SubRt;
过程:
步骤1.依据逆序形式遍历语义依存树DpRt,获取当前结点,顺序执行下述程序。
a.若当前结点是动词,并具备量词子结点,则返回集合块根SubRt;
b.若当前结点是比较操作符,则返回集合块根SubRt;
c.若当前结点依存父结点是动词,并且依存子结点是联系动词,则返回集合块根SubRt;
d.若当前结点是自参照属性,并且依存父结点是本身,则返回集合块根SubRt。
步骤2.返回语义依存树DpRt。
语义依存树集合块类型,如表3所示。

表3 集合块类型表
将划分得到的集合块转换为USQL语句,如式(1)。
SB=(O,C,T)
(1)
式中,SB表示语义依存树集合块的USQL语句表示形式;O表示集合块的数据库对象;C表示复合限定条件表达式;T表示集合块全部结点所属表的集合。
经过式(1)转换后,语义依存树表示多个集合块的线性图SBn-…-SB2-SB1,只需要将其展开即可得到查询语句相应的SQL语句。转换规则,如式(2)。
(2)
1.5 数据挖掘
依据上节转换得到的SQL语句,利用数据挖掘技术在数据库中定位用户需求数据,提取定位数据并反馈给用户[11]。
用户需求数据挖掘流程,如图3所示。
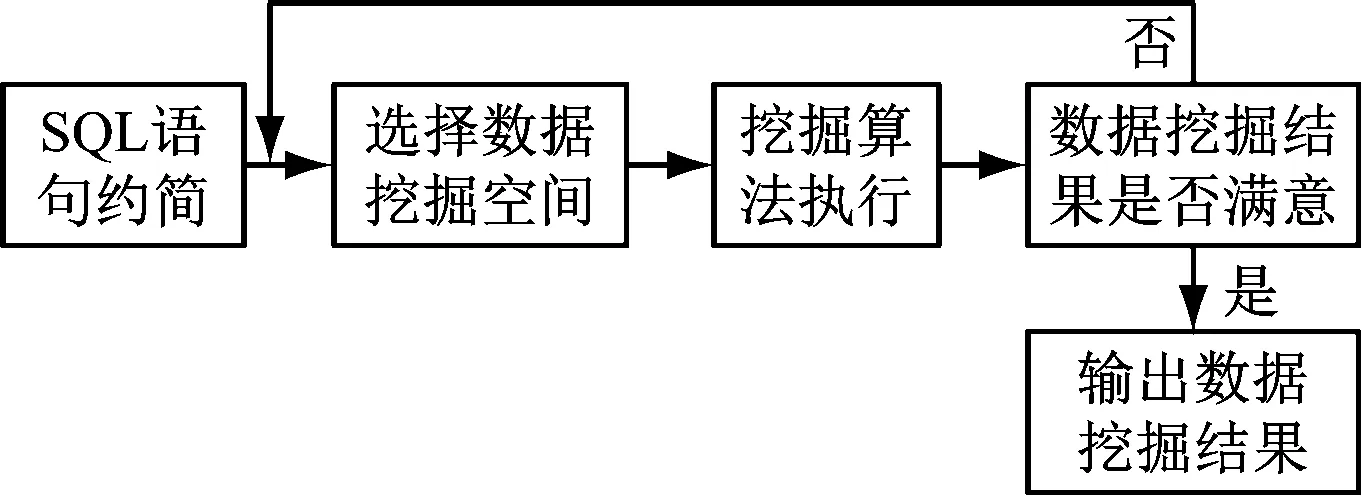
图3 用户需求数据挖掘流程图
首先,利用遗传算法约简SQL语句,简化数据挖掘过程[12]。假设每个SQL语句都是一个候选约简,定义适值函数,如式(3)。
(3)
式中,F(v)表示适值函数值;N表示SQL语句的长度;Lv表示v语句中的属性个数;Cv表示v语句区分对象组合的个数;m表示数据库对象个数。
依据式(3)进行不断迭代,直到满足终止条件为止,完成了SQL语句的约减。
以式(3)结果为基础,利用数据挖掘算法实现用户需求数据的查询。数据挖掘算法,如图4所示。
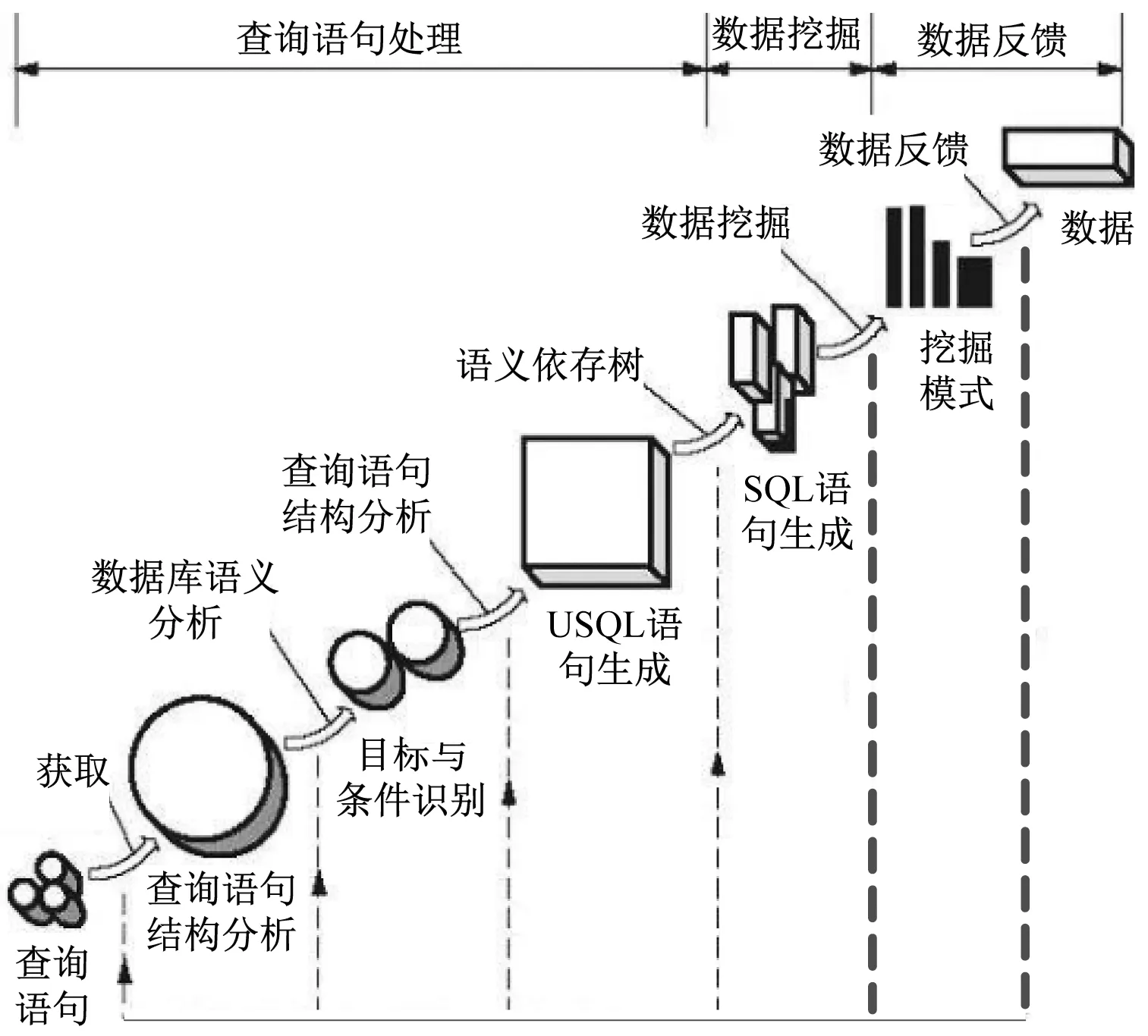
图4 数据挖掘算法示意图
通过上述过程实现了基于数据挖掘的数据库语言查询过程的分析,为用户提供更加优质、准确的服务,推动数据库应用领域的发展。
2 查询准确率仿真分析
为了验证提出方法的性能,本文在LFPW数据库上进行仿真对比实验,通过查询准确率判断方法的好坏,而查询准确率主要由查询目标与条件识别系数、SQL语句转换系数决定。其中,查询目标与条件识别系数指的是查询目标与条件识别的精确度;SQL语句转换系数指的是SQL语句转换的速率。常规情况下,查询目标与条件识别系数、SQL语句转换系数越大,表明方法的查询准确率越高。具体实验过程如下所述。
2.1 实验数据库选取
为了增加实验结果的公平性,选取20个数据库作为实验对象,具体情况,如表4所示。
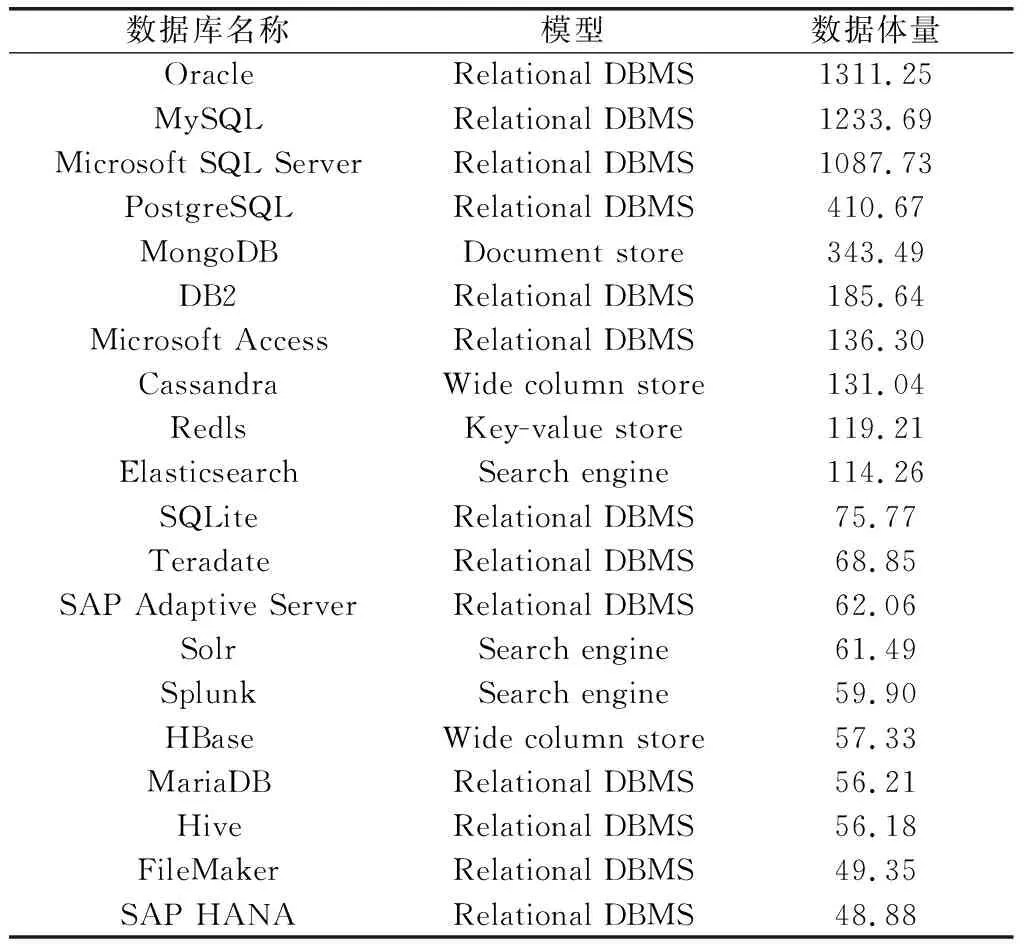
表4 实验数据库情况表
2.2 数据挖掘界面设计
基于语言查询的数据挖掘界面,如图5所示。
依据选取的数据库以及设计的数据挖掘界面进行仿真对比实验。
2.3 查询目标与条件识别系数分析
查询目标与条件识别系数范围为[0,1],通过测试得到查询目标与条件识别系数对比情况,如表5所示。
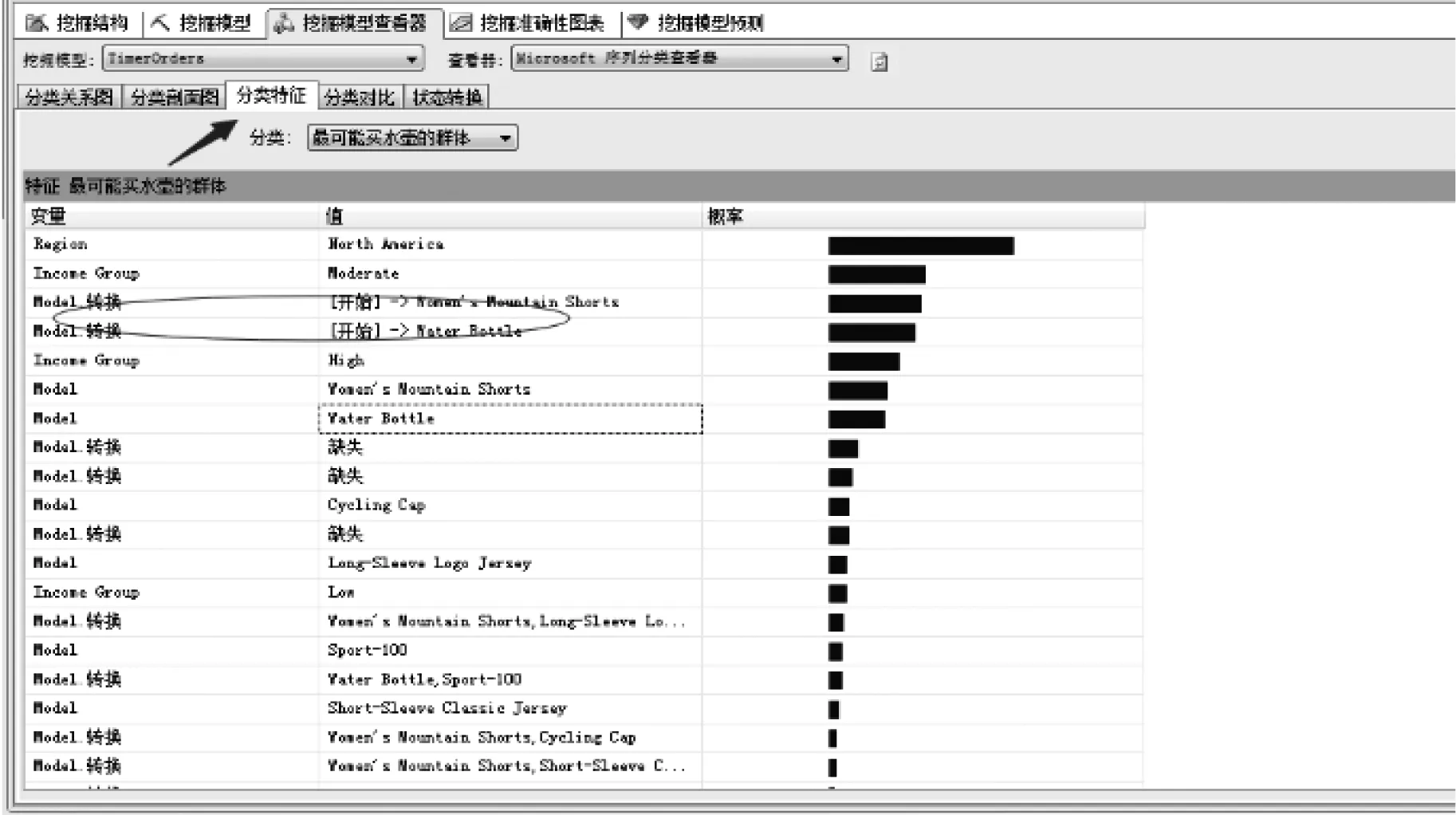
图5 数据挖掘界面示意图
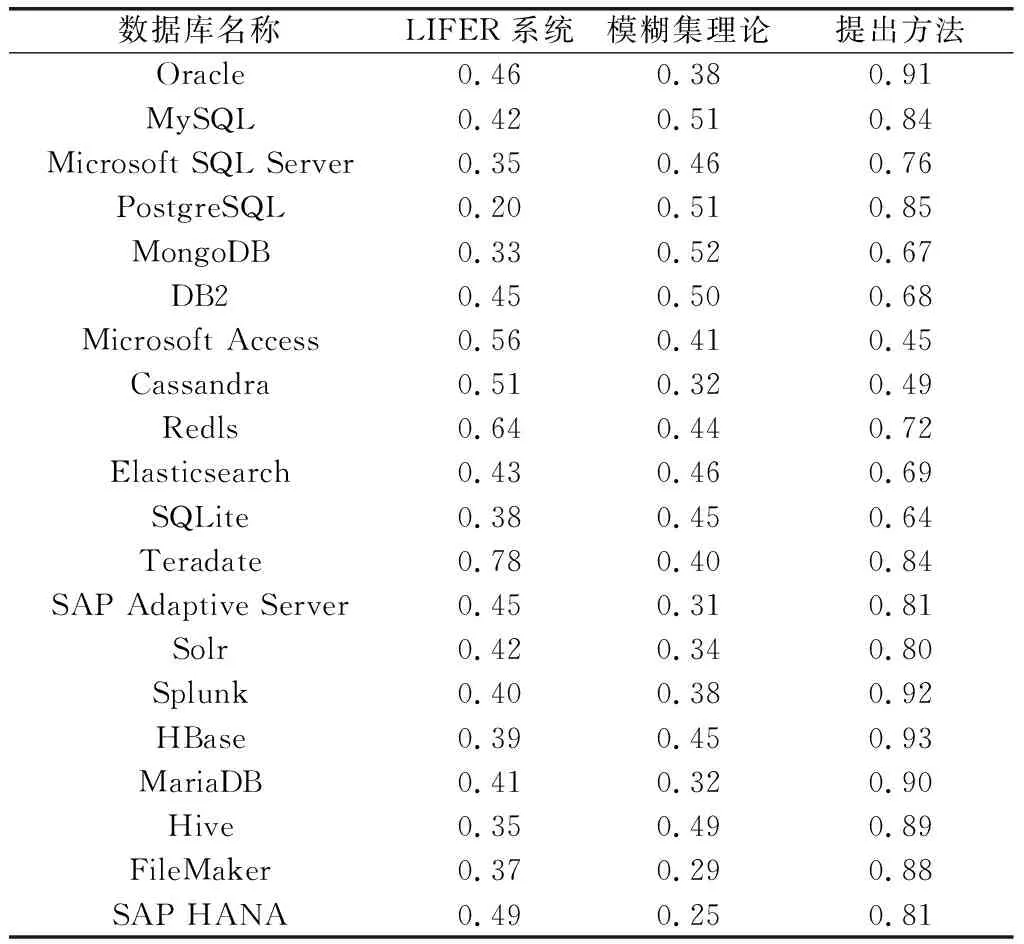
表5 查询目标与条件识别系数对比情况表
表5数据显示,提出方法的查询目标与条件识别系数远远高于现有代表方法,其最大值为0.93。
2.4 SQL语句转换系数分析
SQL语句转换系数范围为[1,10],通过测试得到SQL语句转换系数对比情况,如表6所示。
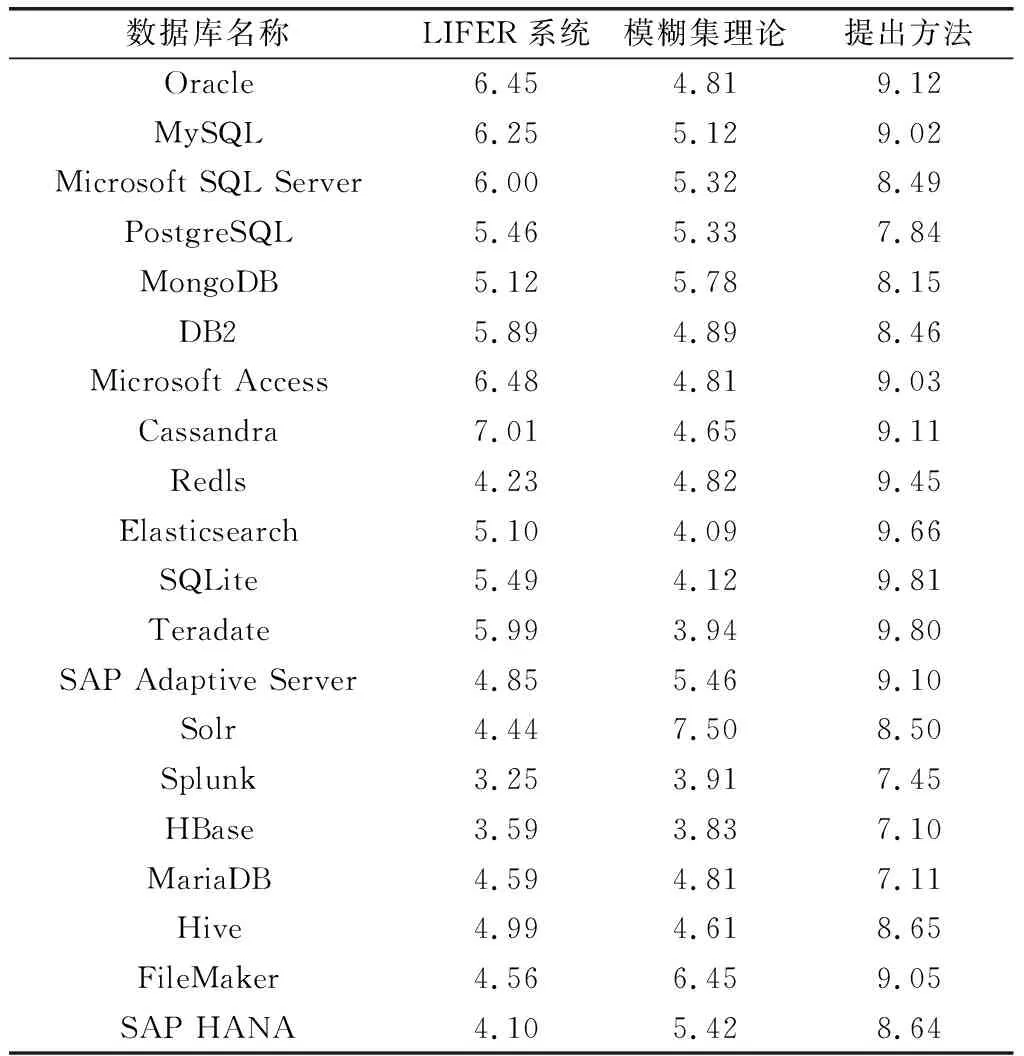
表6 SQL语句转换系数对比情况表
表6数据显示,提出方法的SQL语句转换系数远远高于现有代表方法,其最大值为9.81。
3 总结
由上述实验结果可知:本研究所提方法的查询目标与条件识别系数、SQL语句转换系数均远高于现有代表方法,说明通过数据挖掘的引用,可以提升数据库语言查询的准确率,为用户提供更加精准的数据服务。但本研究所提方法仍存在一些不足之处,如对查询语句执行过程中查询响应速度未考虑全面等。在保证数据库语言查询的准确率基础上,缩短查询语句执行过程中的响应速度是今后研究的重要方向。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
数学物理学报(2018年1期)2018-03-26 08:16:42
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
电力与能源(2017年6期)2017-05-14 06:19:37
信息通信技术(2015年6期)2015-12-26 01:16:46
语文知识(2014年4期)2014-02-28 21:59:52
电子设计工程(2014年18期)2014-02-27 12:00:13
电子设计工程(2014年12期)2014-02-27 11:58:23
苏州市职业大学学报(2010年1期)2010-01-29 02:26:40
