
基于级联深度神经网络的变电站作业安全帽识别技术研究
2021-03-16 08:40:40邵宇鹰刘睿丹李东宾
通信电源技术 2021年19期
邵宇鹰,刘睿丹,鲁 飞,李东宾,彭 鹏,柯 楠
(1.国网上海市电力公司,上海 200122;2.许继电气股份有限公司,河南 许昌 461000;3.华东送变电工程有限公司,上海 201803)
0 引 言
工程施工或作业现场通常都隐藏很多安全隐患,现场作业人员有时安全意识不够、偶尔懒散且抱有侥幸心理,监管人员数量有限,再加之疏忽管理,虽然出台了一系列安全保障措施,但是每年由于不正确佩戴安全帽导致的安全事故依然层出不穷。随着科技创新进步,采用大数据、机器学习算法、智能AI、数字图像处理技术等先进手段,通过机器代替人为监督管理,及时发现现场工作人员未佩戴安全帽违规行为,可以有效解决由于监督体系力量缺乏、全过程监督薄弱、监控水平低的难题。
早期安全帽识别的研究主要基于传统图像处理算法,文献[1]通过Hog特征提取算法检测行人,在行人图像上采用颜色特征提取和霍夫圆形几何识别确定安全帽佩戴情况。文献[2]利用传统机器学习算法检测安全帽,利用从确定人脸的区域中获取Hu矩特征作为安全帽特征信息。文献[3]通过可变形部件模型(Deformable Part Mode)方式构建部件模板匹配到行人特定区域。传统方式的准确度达到瓶颈后很难突破,目前研究方向更热衷于准确率更高的深度学习算法,如:VGG模型[4],ReNet网络框架[5]和Yolo模型框架[6,7]。文献[8]中的安全帽识别算法采用多尺度特征融合的Faster Rcnn模型框架,可通过融合特征层实现对网络模型的优化。文献[9]提出一种适合部署在移动端的轻量化的Yolov5模型,提取HourGlass特征,通过对模型进行剪枝量化实现运行速度的提升。文献[10]利用高精度、快速性的Fast RCNN模型检测可实时监测工人佩戴安全帽的情况。
上述文献的算法虽然对安全帽识别准确率提升有一定意义。但是现实场景下,佩戴安全帽的背景通常复杂多变,部分场景的目标仍会被误识别为安全帽,或被搁置安全帽或被人手拿安全帽均被误识别为人员佩戴的安全帽本。本文提出一种级联网络,Yolov3模型作为一级网络,在图像区域内获取作业人员和安全帽的特征及位置信息,然后连接Inception-v2二级网络模型,对作业人员ROI区域内,更精确地判断人员安全帽的佩戴情况,进一步提升安全帽识别准确率,减少由于其他背景干扰因素造成安全帽的误识别。
1 算法介绍
1.1 基于Yolov3的目标检测算法
Yolov3是一种通过端对端方式实现目标检测和识别的深度学习算法。Yolov3算法基于传统的CNN卷积网络模型框架,融合先验锚框(anchor box)、多尺度特征检测、边界框(bounding box)预测等改进方式,实现不同尺寸目标检测。Yolov3模型框架如图1所示。

图1 Yolov3模型框架
(1)Yolov3模型框架
Yolov3的主体特征提取框架采用Darknet-53主体模型,Darknet-53网络模型中通过连接多个残差网络模块,解决模型由于深层次训练易造成梯度消失的问题。其中,每个残差网络模块有两个卷积层和一个shortcut connection组成,整个Darknet-53网络采用步长strides为2的卷积层进行降采样[6]。
Yolov3 算法借助图像特征金字的思想,采用多尺度检测方式实现对大、中、小3种不同尺度目标预测。主干网络在下采样过程中,分别获取输出为输入图像大小的1/32,1/16,1/8倍的特征图,再和模型后面上采样特征图拼接形成三种不同尺度的预测结果,这3个不同尺度的特征图分别代表了不同感受野,下采样倍数越大、特征图越小、感受野越大,更适宜预测大尺寸目标。
(2)损失函数
Yolov3的损失函数由3部分损失累加组成,其中包括利用均方差损失函数对边框进行回归预测,利用交叉熵损失函数分别进行多类别预测和置信度的二分类预测。损失函数表示如下:

式中,λcoord表示位置预测的损失权重,λnoobj表示不包含目标的损失函数的置信度权重;xi,yi,wi,hi表示预测框的位置信息,表示真实框的位置信息;cij表示预测置信度,表示真实置信度;Pji表示目标类别的预测概率,表示输出的实际类别概率;Iijobi表示第i个网格,第j个anchor boxs为正样本输出为1,否则为0,Iijnoobj表示第i个网格,第j个anchor boxs为负样本输出为1,否则输出为0。
(3)预测机制
参考Faster Rcnn方法,Yolov3会预先利用k-means算法根据图像目标大小设定9种不同尺寸的先验锚框(anchor box)。Yolov3网络预测输出摒弃全连接层(softmax),用逻辑层(logisitic)取而代之,输出的多尺度特征图的每个单元格均可预测3种不同尺寸的边界框(bounding box)目标,每个bounding box包含3类信息:(1)目标框位置tx,ty,tw,th;(2)每个类别分数;(3)类别置信度。最后,通过以下公式计算得到预测边框的中心位置(bx,by)和宽高(bw,bh):


式中,(tx, ty)为预测目标框中心位置相对于所在特征图单元格的左上角位置;(tw, th)为预测目标框相对于先验锚框的宽高比;t0为预测目标框的置信度;cx, cy为预测框所在单元格相对于整图左上角的距离。
1.2 Inception网络模型
Inception网络模型是采用并行网络架构,每个并行模块的卷积层或池化层利用不同卷积核进行计算,从而获取图像不同尺度下的信息,连结每个模块线路上的输出,并传递至下一层网络。这种网络结果可以较好增加网络对特征多尺度的适应性。
本文采用Inception-v2网络模型,对Inception-v2网络是在Inception-v1基础上进行优化改进。Inception-v1中分别并行3×3、5×5和1×1窗口大小的卷积核运算。其中,加入1×1卷积层的目的是为了减少通道数,可以有效减低模型的复杂度。Inceptionv1还额外并行一条通道,窗口大小为3×3的池化层,后接1×1卷积层更改输出通道数。每个并行通道通过设置不同填充(padding)保证输出特征图一致。
Inception-v2 是在Inception-v1的基础上进一步优化改进。Inception-v2网络框架优化了由于学习率设置导致梯度消失或爆炸的问题,在模型结构上通过卷积分解提高计算效率。通过拆分各卷积层的卷积核,缩减卷积参数数量,如:卷积核为5×5的卷积层拆分为两个3×3卷积核的卷积层,将卷积核3×3的卷积层拆分为1×3和3×1两个卷积层串联。Inception-v2模型中针对池化层添加一个并行之路,即池化层由两条通道组成,一条通道为1×1的卷积层,另一条通道为池化层,最后拼接两通道的特征维度(如图2所示)。为了减少各层参数在训练过程中变化较大的影响,Inception-v2中加入正则化操作(Batch Normalization)。

图2 Inception-v2网络
1.3 级联网络结构设计
本文将Yolov3网络模型和Inception-v2网络模型串联组成,Yolov3作为一级网络主要通过获取行人特征信息,对行人目标进行精确定位和识别,除此之外,Yolov3模型还可从图像中初步预估到安全帽特征和位置,但是由于安全帽本身特征结构单一、受到背景复杂干扰等影响,初步检测的安全帽未必为所属行人特征佩戴的安全帽,部分目标被误识别为安全帽,或被搁置安全帽或被人手拿安全帽均被误识别为人员佩戴的安全帽,直接仅依据Yolov3模型输出结果判断易增加误识别风险。
Inception-v2网络作为二级网络主要从一级网络中获取的行人特征中更具针对性识别和训练人员佩戴安全帽特征。二级网络的安全帽特征信息作为一级网络的参考标准,结合一级网络的输出结果,从而最终确定人员是否佩戴有安全帽,级联网络的结构如图3所示。
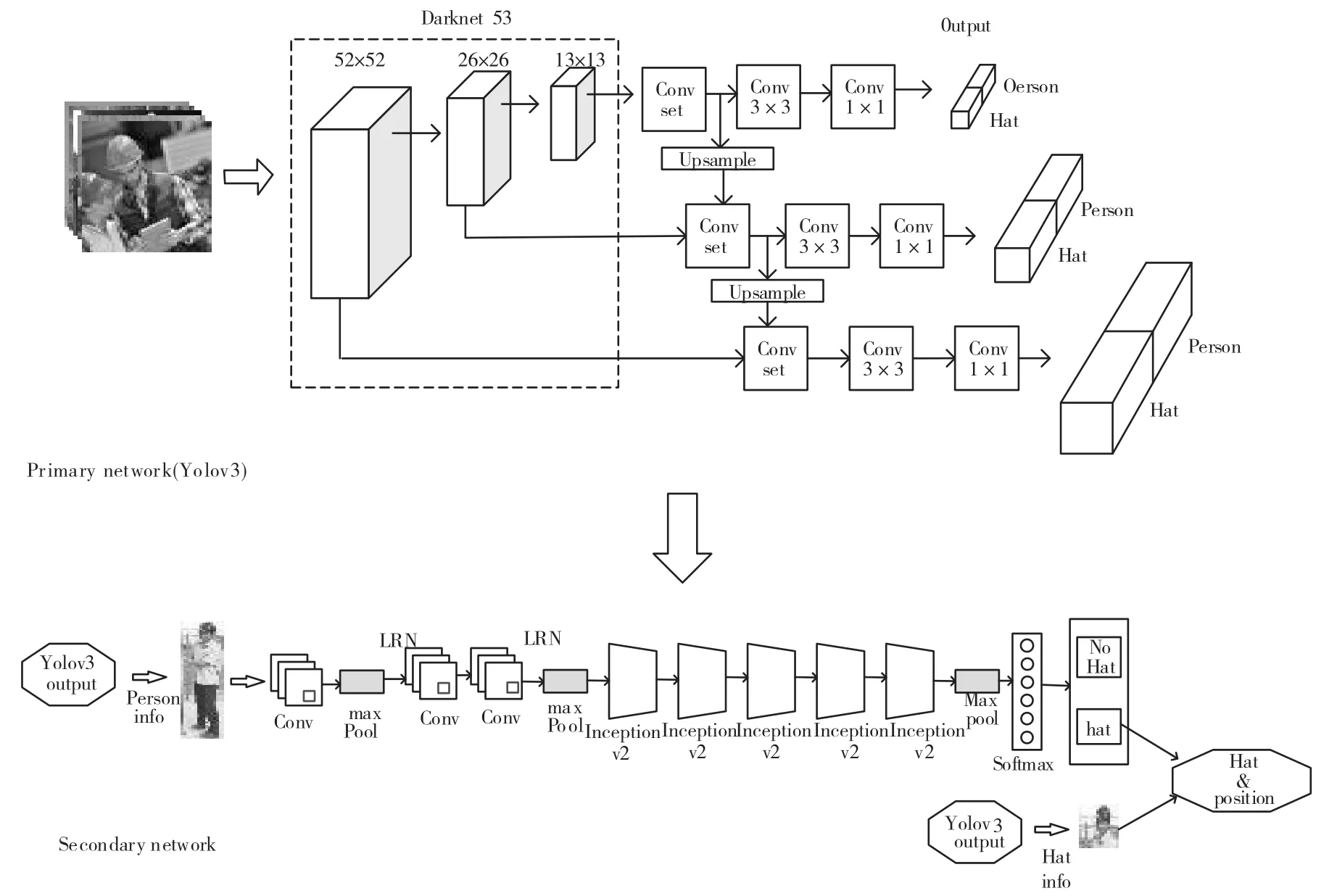
图3 级联网络结构
2 实验与结果分析
2.1 实验环境
本文实验在服务器下进行训练和测试,服务器的硬件配置为NVDIA 2080Ti 的GPU显卡,12G显存,开发系统为Linux,需要搭配开发环境包括CUDA11.1 ,python3.7,Opencv图像处理包,使用Pytorch 1.6.0搭建网络模型框架。
2.2 模型训练
(1)数据集分析
本实验采用包含行人和安全帽的开源数据4 000张,以及在作业现场采集的1 000张数据共5 000张图像数据,这些数据里包括不同颜色安全帽、不同环境、不同角度下采集的图像。其中,4 500张作为训练样本,500张作为测试样本。利用标注工具标注图像中的行人框及佩戴安全帽框,生成包含标注信息的xml文件。
(2)训练过程
本实验中采用Yolov3训练用于检测图像区域内作业人员和安全帽目标的模型,采用Inception-v2训练用于检测行人安全帽是否佩戴情况的模型。Yolov3的初始化参数如表1所示, 初始化设定学习率0.001,每批次输入图像32张。输入Yolov3模型图像大小尺寸调整为416×416,将预训练模型传出Yolov3框架中作为初始权重值,共迭代8 000次。

表1 Yolov3模型参数
然后,从数据中获取人员的ROI区域,用于训练二级网络Inception-v2模型,该模型共刺迭代5 000次,标签设置包含两类:佩戴安全帽和未佩戴安全帽。
2.3 结果分析
图4为通过一级网络Yolov3训练行人和安全帽目标检测的过程中损失值的变化情况,随着训练次数的增加,Yolov3训练模型的损失值逐渐下降,迭代4 000次后损失值基本趋于稳定,最终模型的损失值稳定在0.35左右。

图4 Yolov3模型训练损失函数
本实验通过计算准确率对模型性能进行评价,通过引入混淆矩阵中TP、TN、FP、FN(如表3)表示识别的准确程度,准确率表示模型中正确的数据占总数据的比例。数学表达式如下:


表2 混淆矩阵
矩阵中的利用通过Yolov3模型识别人员目标准确率为89.1%,安全帽检测目标的准确率为85.2%。通过对测试图像分析,之所以出现安全帽错检主要是由于被放置的安全帽和手拿安全帽的情况。因此,通过二级网络Inception-v2进一步对人员是否佩戴安全帽的情况进行判断,准确率提升至91.3%。
图5为仅采用Yolov3模型的测试人员安全帽的效果图,图6为采用本算法级联网络的检测人员安全帽佩情况的效果图。通过对比,在无特殊情况,人员正常佩戴安全帽的情况下,两种算法均可准确检测人员佩戴安全帽情况,如图5(a)和图6(a),但是若出现如图5(b)情况,仅利用Yolov3模型可能将手持安全帽情况也误检为佩戴安全帽情况,此时,通过本算法,对人员ROI区域二次检测,可有效排除这种误识别情况(如图6(b))。两种算法的效果图发现,采用级联网络模型可排除部分误识别(如:手持安全帽情况),表明通过二级网络可有效去排除由于误检造成安全帽识别率低的问题。

图5 基于yolov3模型的安全帽预测效果图

图6 基于级联网络模型的安全帽预测效果图
4 结 论
为了提升现在作业人员佩戴安全帽的识别率,减少由于现场复杂施工环境的背景干扰,本文提出一种基于Yolov3和Inception-v2的级联网络。通过Yolov3网络模型提出出行人和安全帽目标,然后,用二级级联网络Inception-v2模型在进一步精确验证安全帽佩戴情况。实验结果表明,安全帽佩戴检测的准确性有明显提高。因此表明,本文在该领域的识别中具有一定的参考和应用价值。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电子制作(2016年15期)2017-01-15 13:39:09
系统工程与电子技术(2016年2期)2016-04-16 05:16:51
电测与仪表(2014年1期)2014-04-04 12:00:34
电测与仪表(2014年1期)2014-04-04 12:00:28
电视技术(2014年19期)2014-03-11 15:38:20
