
基于SVM的盲文检测方法
2021-03-13 14:38:43卢利琼吴东
现代信息科技 2021年15期
卢利琼 吴东




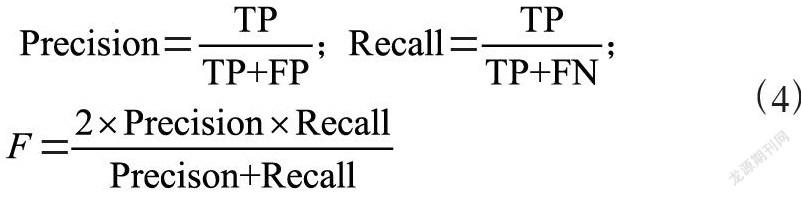


摘 要:盲文是视力障碍人士用来学习技能和了解世界的重要手段,盲文检测则是促进视力障碍人士和正常人士交流的关键技术。针对盲文扫描图像,利用HOG(Histogram of Oriented Gradient)特征和SVM(Support Vector Machine)提出了一种盲文检测方法,并在盲文扫描图像数据集DSBI上进行了验证,实验结果表明,所提出的方法能够有效检测盲文点信息。
关键词:视力障碍;盲文检测;HOG;SVM
中图分类号:TP391.4 文献标识码:A文章编号:2096-4706(2021)15-0131-03
Abstract: Braille is an important means for the visually impaired people to learn skills and understand the world. And braille detection is the key technology to promote the communication between visually impaired people and normal people. For braille scanned images, a braille detection method is proposed by using HOG (Histogram of Oriented Gradient) feature and SVM (Support Vector Machine), and verified on braille scanned image data set DSBI. The experimental results show that the proposed method can effectively detect braille point information.
Keywords: visually impaired; braille detection; HOG; SVM
0 引 言
我國目前视力障碍人士超过1 800万,平均每一分钟就会出现一位视力障碍人士[1]。盲文是这些视障人士用来学习和了解世界的重要手段。我国政府非常重视视障人士的生活和发展问题,提出了“特殊教育信息化”的总导思想。盲文检测旨在利用人工智能技术自动检测出整幅图像中的盲文信息,是诸多特殊教育产品应用能够落地的关键技术,如盲文书籍电子化、盲文自动阅卷、盲人与正常人的交流,等等。
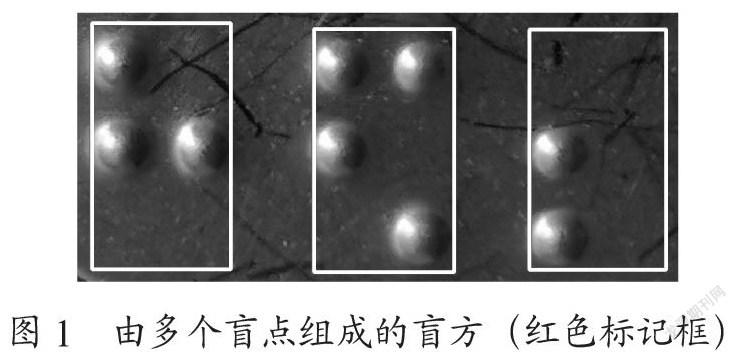
盲文由多个盲方组成,而每个盲方则由六个盲点按照固定顺序(共两列,每列三个盲点)和盲点是否出现进行排列[2],如图1所示。目前,盲文检测是先将盲文点检测出来,然后再组成盲方进行识别。现有的盲文点检测方法主要有两类,第一类是利用图像分割和盲点凸起的特性从像素的角度将每个像素分成凸点像素、凹点像素和背景像素三类,然后将相邻的凸点像素组合得到盲文点;第二类则是先利用滑窗的机制从图像中获取多个子图像,然后针对每个子图像来提取纹理特征作为机器学习方法(例如SVM,Adaboost等)的输入进行盲文点的检测。从实验结果来看,第二类方法的检测性能优于第一类方法[3]。
本文首先利用滑窗机制将盲文扫描图像分割成多个子图像,然后从每个子图像中提取HOG特征,紧接着将HOG特征作为SVM的输入对图像中盲点的位置进行检测,最后利用非极大值抑制(Non-Max-Suppression, NMS)算法过滤多个相似的检测结果得到最优结果。在数据集DSBI[3]上对本文提出的方法进行了验证,实验结果表明,该方法能够有效地从盲文扫描图像中检测出盲点的位置信息,与基于图像分割等方法相比,其检测性能有一定的提升。
1 基于SVM的盲文检测方法
1.1 HOG特征提取
HOG全称为Histogram of Oriented Gradient,即方向梯度直方图,是计算机视觉和图像检测中用来描述物体特征的特征子,也是目前使用最广泛的一种特征子。HOG特征通过统计和计算图像梯度和边缘的方向梯度来构成特征。在一幅图像中,HOG特征能较好地描述图像局部的表象和形状。HOG特征提取的边缘和梯度特征能很好地抓住局部形状的特点,对几何和光学变化具有不变性。HOG特征结合SVM分类器已经被广泛地应用于各类检测领域中,尤其是在人脸检测领域取得了巨大的成功[4]。
基于此,本文将HOG特征作为扫描文档图像中盲文点的特征子。本文提取HOG特征的具体步骤为:
(1)将所有的扫描盲文图像转换成灰度图,在水平和垂直方向以步长为2(像素)提取大小为20×20的子图像。
(2)利用式(1)计算子图像中每个像素的水平梯度和垂直梯度,其中针对像素(x,y),I(x,y)表示该像素的像素值,h(x,y)表示水平梯度,v(x,y)表示垂直梯度。
(3)利用式(2)计算每个像素的梯度和方向,其中g(x,y)表示梯度值,o(x,y)表示方向。
(4)从方向上将每个子图像分成18个范围(360度,每20度为一个范围),然后进行直方图的统计得到HOG特征。
(5)对所获取的HOG特征进行高斯平滑操作,将HOG特征存储在指定的路径下。
图2给出了盲文扫描图像以及从该图像中提取部分图像获得的HOG特征图示,从图2中可以看出,存在盲文点的地方,HOG特征方向和梯度信息非常明显,这也证明HOG特征可以很好地描述盲文扫描图像中的盲点信息。
综上所述,本文利用Python实现了某路径下所有图像的HOG特征提取,部分伪代码为:
#针对正样本提取HOG特征,并保存到指定路径
for 每张图像 in 所有图像:
im = imread(path) #读取图像
fdg = hog(im,18,20,20,visualise=visualize)
fd_name = getName(path) #获取特征的名称
fd_path = getPath(path,fd_name) #获取HOG特征保存路径
SaveFeature(fd, fd_path) #保存HOG特征到指定路径
1.2 标签设置
经过以上处理,每幅图像被分成了多个子图像,而每个子图像需要被分配一个标签0或者1。0表示该子图像不是盲点区域,反之,1则表示该子图像是盲点区域。在设置标签时,先利用式(3)来计算真实盲点区域面积(T)与子图像区域面积(C)的IOU值,如果IOU值大于0.8,则该子图像被认为是盲点区域,并且设置标签为1,否则设置标签为0。
1.3 基于SVM的盲文点检测
支持向量机(Support Vector Machine, SVM)是一种快速可靠的线性分类器,其最终的目的是找到一个最优超平面,从而对训练数据进行分类。关于SVM算法,可以借助图3来理解。假设二维平面上有一些方框和圆圈,需要找出一条最佳直线将这两类数据分开。显然,这样的直线可以找出很多条,但是最佳直线怎么寻找呢?SVM所做的就是找到一条直线(或超平面),它与训练样本的最小距离最大,比如下图中穿过中心的实线。在计算机视觉领域,由于数据不再是二维的,所以使用超平面来进行分类。
本文实验中,从文档扫描图像数据集中获取的正样本图像的个数远小于负样本的个数,故本文在训练过程中设定正负样本的比例为1:3,以便能更好地训练SVM分类模型。
在测试阶段,首先利用训练得到的模型预测每个子图像的类别(盲文点或者非盲文点),随后利用NMS算法[5]进行过滤和筛选后得到最终的盲文点检测结果。在实验过程中设定分类的阈值为0.8,NMS的阈值为0.4。
本文所有的代碼均使用python实现,训练SVM的主体伪代码为:
# 加载正样本
for 每个HOG特征 in 所有正样本HOG特征:
fd = GetFeature(hog) #得到每个HOG特征
hogs.setFeature(fd)
labels.setLabel(1) #设置标签为1
# 加载负样本
for 每个HOG特征 in 所有负样本HOG特征:
fd = GetFeature(hog) #得到每个HOG特征
hogs.setFeature(fd)
labels.setLabel(0) #设置对应的变为0
clf = GetSVMModel() #建立SVM模型
clf.fit(hogs, labels) #将训练数据放入到模型中,并开始训练
2 实验结果分析
2.1 盲文点检测性能指标
本文采用文本检测领域使用的准确率(Precision)、回归率(Recall)和综合指标F来表示盲文点的检测性能。此三个指标的计算方法如式(4)所示,其中TP表示预测正确的个数,FP表示预测错误的个数,FN表示漏检和检测错误的个数。
2.2 DSBI数据集上的实验结果分析
针对本文提出的HOG+SVM盲文检测方法,在DSBI数据集上进行了盲文点检测性能的验证。DSBI是由Li等人于2019年发布的一个盲文扫描图像数据集,该数据集中包含数学、杂志和小说等盲文文档扫描图像。本文提出的HOG+SVM方法在DBSI数据集上进行盲文点检测获得准确率(Precision)为0.978,召回率(Recall)为0.971,F值为0.974。与基于图像分割的方法相比,本文提出方法的检测性能提升明显,F值提升接近3%;与基于Harr+Adaboost的方法相比,通过本文提出方法计算的F值提升了0.4%。本文提出的方法与现有方法的对比如表1所示。
图4给出了部分盲文扫描图像的盲文点检测结果图。图4(a)是正反两面盲文扫描文档图像检测结果,从图中可以看出,大部分盲文点(凸点)都被正确检测出来了,有一两个反面的盲点(凹点)被误检成盲点。图4(b)是单面盲文扫描图像检测结果,基本上所有的盲文点都被正确检测出来了。
3 结 论
本文针对盲文扫描图像中的盲文检测问题,提出了基于HOG+SVM的盲文点检测方法。首先,利用滑窗机制从盲文图像中提取多个子图像,然后从这些子图像中获取HOG特征,将这些HOG特征以及对应的标签输入SVM分类器中,进行训练后得到检测模型,最后在测试集上利用训练后的模型对新的盲文文档扫描图像进行盲点检测。在DBSI数据集上对本文提出的方法进行了测试,并与已有的基于图像分割和基于Harr+Adaboost的方法进行了对比,实验结果表明,本文提出的方法在准确率(Precison)、回归率(Recall)和F值上均有提升。
参考文献:
[1] 中国青年网.有1800万人,在声音里寻找光 [EB/OL].(2020-12-06).https://baijiahao.baidu.com/s?id=1685329774912727962&wfr=spider&for=pc,2020.12.06.
[2] ISAYED S,TAHBOUB R. A review of optical Braille recognition [C]//2015 2nd World Symposium on Web Applications and Networking (WSWAN). Sousse:IEEE,2015:1-6.
[3] LI R Q,LIU H,WANG X D, et al. DSBI: Double-Sided Braille Image Dataset and Algorithm Evaluation for Braille Dots Detection [C]//ICVIP 2018: Proceedings of the 2018 the 2nd International Conference on Video and Image Processing. 2018.
[4] DALAL N,TRIGGS B. Histograms of oriented gradients for human detection[C]//IEEE Computer Society Conference on Computer Vision & Pattern Recognition.San Diego:IEEE,2005:886-893.
[5] NEUBECK A,GOOL LJV. Efficient Non-Maximum Suppression [C]//International Conference on Pattern Recognition (ICPR).Hong Kong:IEEE,2006:850-855.
作者简介:卢利琼(1980—),女,汉族,湖北崇阳人,讲师,博士,主要研究方向:文本识别;吴东(1981—),男,汉族,广东合浦人,副教授,硕士,主要研究方向:模式识别。
3207500338215
