
基于探空数据集成学习的短时强降水预报试验
2021-03-11 12:07周楚炫吕终亮
应用气象学报 2021年2期
韩 丰 杨 璐 周楚炫 吕终亮
1)(国家气象中心, 北京 100081)2)(北京城市气象研究院, 北京 100089)
引 言
短时强降水(小时降水量不低于20 mm)是主要的极端降水天气之一,主要由超级单体和中尺度对流系统(MCS)造成[1],具有局地性强、发展快、历时短、破坏性大等特点,是强对流天气预报中的难点之一[2-3]。由于在短时间形成大量降水,短时强降水常导致城市内涝和山洪、滑坡等次生灾害,给人民生命财产造成重大损失[4]。
根据气块法理论,短时强降水可以从深厚湿对流的三要素角度进行分析,即充足的水汽、静力不稳定和抬升机制。基于此,Doswell等[5]提出一种基于构成要素的暴雨预报方法,俗称配料法。张小玲等[6]利用数值模式产品分析有利于暴雨发生的物理“配料”,发展配料法暴雨落区预报方法。国家气象中心在此基础上制定了国家级强对流天气环境场条件分析技术路线[7-8]。
单站探空数据是分析局地强对流天气的重要数据之一。预报员常使用对流参数进行潜势预报[9-10]。王笑芳等[11]利用北京08:00(北京时,下同)探空数据建立强对流天气预报决策树,为强对流天气的短时预报提供思路和方法。刘玉玲[12]结合多个个例分析对流有效位能、风暴螺旋度等对流参数在强对流天气潜势预测中的作用。李耀东等[13]研究湿绝热过程中对流能量计算方法,通过多指标叠套技术实现强对流天气的潜势预报。刘晓璐等[14]以探空数据为因子,构建冰雹预报模型。雷蕾等[15]基于统计方法,分析北京探空站在强对流日的物理量,得到能够有效识别强对流天气类型的物理量取值范围和6 h变量。马淑萍等[16]使用探空数据分析雷暴大风的环境参量特征。田付友等[17]使用NCEP FNL分析场数据的物理量场,设计短时强降水相关物理量的敏感性试验,并得到几种重要物理量的阈值。曾明剑等[18]在统计分析大量历史个例的基础上,结合中尺度模式输出的对流参数预报,提出一种客观对流参数筛选和权重分配方案,构建分类强对流天气概率预报模型。
综上所述,利用探空数据分析中尺度对流系统发生发展的局地垂直环境,可有效判断短时强降水发生的潜势,构建客观预报模型。但面对不同气候背景的站点和不同的天气过程,对流参数选取和阈值确定在实际操作中存在很大的主观性[19]。此外,不同对流参数之间有一定相关性,且有各自的适用条件,并不存在一种普适的指数或者方法[20],这也给基于探空数据的客观诊断方法应用带来一定局限性。
为了解决上述算法的适用性问题,提高客观模型的预报能力,本文提出一种基于集成学习和探空数据的短时强降水预报模型,以XGBoost(extreme gradient boosting)集成学习框架为基础[21],将08:00 探空观测的大气层结和对短时强降水有指示意义的对流参数作为特征,构建集成决策树,利用长时间序列站点数据建立短时强降水客观预报模型(以下称预测模型)。
目前,人工智能尤其是新兴的深度学习方法已在气象预报任务上取得一定应用成果[22-25]。但纵观各类国际智能算法大赛不难发现,同类算法在气象领域中的应用效果往往大打折扣。从气象角度考虑,其原因主要有3点:天气发展具有一定的不可预报性,气象观测的局限性,天气预报事件的不均衡性。强对流天气预报中,不仅无法获得强对流天气发生前的大气真实状态,有时甚至无法确定强对流天气发生与否。这些都极大制约了客观预报模型的准确率。唐文苑等[26]指出对于致灾性强、极易造成经济损失和人员伤亡的强对流天气预报业务,在牺牲部分空报率的基础上提高预报的准确率,可以一定程度上有效提升预报服务效果,降低灾害性天气的影响。受其启发,本文提出一种面向高影响气象业务的人工智能模型优化思路,即在提升模型TS评分的同时,更加关注预测错误的样本分布。通过对模型的优化,在总体上不增加错误预测数量的基础上,减少漏报,增加空报,进而提高模型的TS评分和命中率,提升模型的实际预报能力。
综上所述,本文基于集成决策树,使用探空数据,构建短时强降水客观预报模型,提出并验证一种面向高影响天气的模型优化方案。
1 方 法
1.1 XGBoost集成学习框架
集成学习指通过集成准确且互补的基分类器,提高模型的泛化能力,获得更优的学习效果[27]。本文使用的XGBoost是一种基于GBDT(gradient boosting decision tree,梯度提升决策树)的集成学习框架[21],BDT(boosting decision tree,提升决策树)的模型优化通过不断增加决策树实现,其核心在于第n棵树学的是前(n-1)棵树预测结果和真实值的偏差(残差),通过减小残差,模型的学习能力得到提升。GBDT使用梯度下降法进行BDT模型训练,在训练过程中,每一棵新的决策树都在残差减小的梯度方向上构建,新决策树的构建使模型向提升准确率的方向进行优化[28]。
本文在GBDT集成策略基础上,通过优化损失函数,使模型更加关注预测错误的样本分布,进而在“宁空勿漏”的方向上构建新的决策树,最终在总体上不增加错误预测数量的基础上,减少漏报,提高模型的命中率和TS评分。
1.2 目标函数
XGBoost模型的训练过程就是通过最小化目标函数找到最佳参数组。其目标函数[21]为
(1)
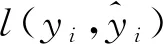
(2)
将式(2)带入式(1),可以得到模型在训练第K棵决策树时的目标函数为
(3)
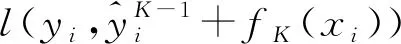
1.3 损失函数优化策略
损失函数是机器学习算法中最重要的要素之一,其核心是描述模型预测值和样本真实值之间的偏差,并驱动模型向损失值减小的方向优化。
表1给出的是模型预测值和样本真实值之间的关系。其中TP和FN表示预测正确,TN表示漏报,FP表示空报。唐文苑等[26]指出对于高影响的强对流天气,“宁空勿漏”的预报倾向,有助于提升预报服务的效果,降低灾害性天气影响。本文以此出发,考虑短时强降水预报任务的不确定性,当模型无法做出正确预测时,通过优化损失函数,使模型的错误预测更多落在FP区域,即增多空报,减少漏报(提升命中率),使模型在实际预报任务中更有应用价值。

表1 模型预测值和样本真实值的关系Table 1 Relations between labels and predictions
在此基础上,将损失函数写成分段形式。通过给不同变量取值范围增加权重系数的方式,调整模型预测的倾向性。模型输出结果为事件发生概率,选择0.5的预测值作为事件发生的概率阈值,超过阈值即判断为短时强降水发生。则分段权重损失函数如下所示:
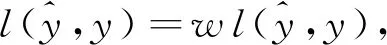
(4)
其中,wTP,wTN,wFP,wFN分别代表真实值和预测值落在TP,TN,FP和FN区域时的权重系数。当wTP,wTN,wFP,wFN相等且取值为1时,分段权重损失函数和原损失函数等价。减小wFN,当个例落在FN区间时,损失函数返回的损失值较小,使预测模型向倾向于预测发生方向优化,最终预测结果会出现TP和FP数量上升,TN和FN数量下降。相反,减小wTP,预测模型则向倾向于预测未发生的方向优化,最终预测结果会出现TN和FN上升,TP和FP数量下降。
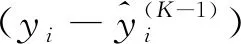
(5)
2 数 据
2.1 数据集
为了验证预测模型的地域适用性,本文选取我国119个探空站点作为试验对象,分别收集2015—2019年6—9月的探空观测和降水观测,形成试验数据全集。其中,每个探空站分别形成各自的站点试验数据集。
本文使用08:00探空数据预测未来12 h短时强降水事件(不低于20 mm·h-1)。采用点到面[16]的检验方式,即将探空站周边一定范围内的自动气象站作为检验站,统计目标事件的发生情况。在此种条件下,短时强降水事件是否发生取决于两个因素:搜索范围和出现短时强降水雨量站数量。基于Haklander等[29]和田付友等[17]的研究,本文确定搜索范围为以探空站为中心的2°×2°矩形大小,出现短时强降水雨量站的记录数阈值为2。以某日某个探空站的探空观测记为1站次,当该探空站周边2°×2°范围内,在未来12 h内,有两个以上自动气象站出现超过20 mm·h-1的降水时,记为1次短时强降水事件。
为了验证模型的泛化能力,本文选取区域气象中心周边的7个探空站(乌鲁木齐区域气象中心由于短时强降水个例过少,无法形成有效的数据集),分别利用2017年、2018年、2019年站点试验数据集构建站点试验数据子集,其中每个站点试验数据子集包括学习集和独立检验集,总共21个站点试验数据子集(表2)。

表2 各探空站点试验数据子集名称Table 2 Data subset of sounding stations
2.2 特征选取
本文选取的特征分为两个组成部分:探空观测的大气层结和对流参数。其中大气层结是业务中唯一基于直接观测的高空数据(包括温度、位势高度、露点稳定、风速和风向),在分析和诊断天气形势中有重要作用。对流参数选取和水汽、触发条件、层结稳定度相关的主要物理量[30-33]。同时,考虑到大部分的热力稳定度参数都有很强的相关性,为了避免模型的过拟合,本文排除一些参数,如SI指数。此外,特征中也包括一些不利于短时强降水的对流参数,如不同高度的水平风垂直切变等。最终得到48个特征,如表3所示。
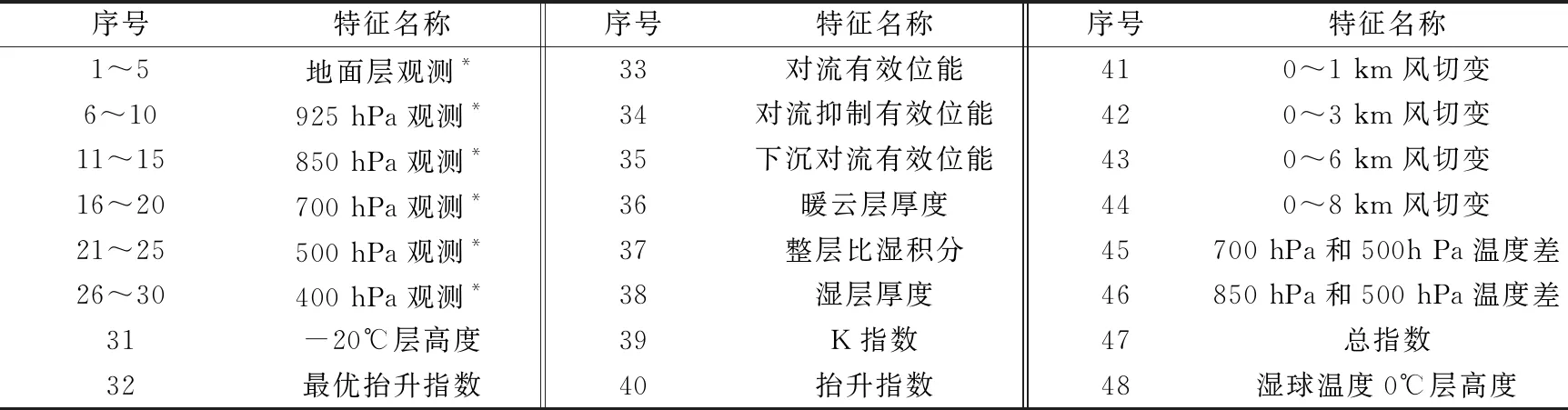
表3 特征量列表Table 3 Selected elements
3 结果分析
3.1 试验方案和检验方法
为验证损失函数中权重参数调整的有效性、泛化性,以及改进后模型对于短时强降水事件的预报能力。本文设计两组对比试验方案,分段权重损失函数权重敏感性试验和损失函数对比试验,和一组全国范围的预报试验。选用命中率、空报率、漏报率、TS评分对预报结果进行量化评估。本文在计算命中数(TP)、空报数(NP)和漏报数(TN)时,采用2.1节中介绍的点到面的检验方式。
XGBoost内置算法参数不在本文讨论范围内,故所有对比试验使用统一的算法参数。已调优参数如表4所示,其余参数为默认值。

表4 XGBoost模型参数Table 4 Parameters of XGBoost
3.2 分段权重损失函数权重敏感性试验
3.2.1 试验设计
本文设计权重参数的敏感性对比试验,以验证分段权重损失函数权重参数对模型预报能力影响。以标准MSE作为试验的对照组,分别独立改变wTP,wTN,wFP,wFN(步长为-0.1),进行预报试验。为消除数据集对于试验的影响,对比试验在北京(54511),上海(58362)、武汉(57494)、锦州(54337)、清远(59280)5个站点的15个站点试验数据子集上进行,共进行15组对比试验。
3.2.2 结果分析
图1为分段权重损失函数在不同权重系数下,预测模型在15个试验数据集上的检验结果,横轴为各权重系数的取值,纵轴为检验指标TS评分。对比wTP评分图可以看出,随着wTP减小,预测模型偏向保守型预报,即“宁漏勿空”。命中数和空报数减小,命中率和TS评分随之下降,由于命中数和空报数同时降低,故空报率没有明显变化。当wTP<0.5时,命中数和空报数减少一半,模型的预报能力比较差。当wTP在0.8~0.9取值范围内时,预测模型在基本维持命中率的基础上,空报数略有减少,TS评分略有上升。对比wFN评分图可以看到,随着wFN减小,预测模型偏向激进型预报,有明显的“宁空勿漏”倾向。命中数和空报数上升,命中率和空报率随之上升。当wFN在0.2~0.4的取值范围内,命中率普遍超过0.6,在一些数据集上,甚至超过0.9。此时空报率位于0.3~0.5,TS评分略有上升。对比wTN和wFP评分图可以看出,wTN和wFP对于预测模型的性能影响不大,这主要是因为在模型训练过程中,落在TN和FP区间的个例数相对较少,所以这部分损失值的变化很难影响到整个模型的训练结果。
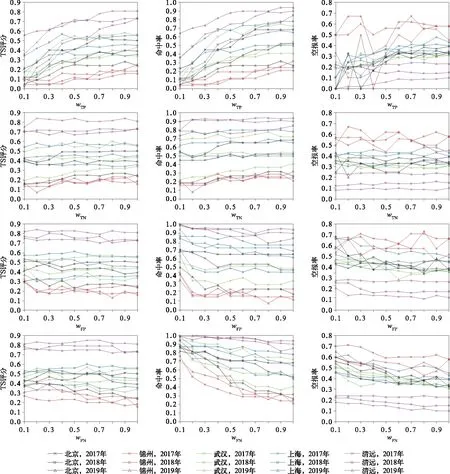
图1 分段权重损失函数权重敏感性分析试验检验结果Fig.1 Result of sensitivity analysis test of weighted piecewise loss function
综合对比图1可以看到,预测模型在15组对比试验中,均表现出相似的变化。这表明调整权重影响对于预测模型的倾向性具有一定泛化能力。其中,减小wTP会减少模型的命中数和空报数;减小wFN会提高模型的命中数和空报数;wTN和wFP对预测模型影响较小。
综上所述,wTP取值为0.8~1.0,wFN取值为0.3~0.5,wTN和wFP取值为1时,模型的空报率不超过0.5,命中率明显上升,TS评分略有提高,模型表现出明显的“宁空勿漏”倾向。同时,不同站之间的最优权重参数取值略有不同,实际训练模型时,可以在确定空报率阈值的基础上,针对具体站点进行进一步调优。
3.3 损失函数对比试验
3.3.1 对比试验设计
本文设计了损失函数对比分析试验。以XGBoost框架中常用的Logloss(对数损失函数,见式(6)和MSE损失函数作为试验对照组,验证分段权重损失函数(见式(4))模型的预报能力。为消除数据集对试验结果的影响,对比试验在北京(54511)、上海(58362)、武汉(57494)、锦州(54337)、清远(59280)、温江(56187)和渝中(52983)7个探空站的21个站点试验数据子集上进行,共21组对比试验。所有试验中,分段权重损失函数使用统一的权重参数配置方案:wTP=1.0,wTN=1.0,wFP=1.0,wFN=0.4。
(6)
3.3.2 结果分析
图2为损失函数对比试验的检验结果,表5给出的是以站点区分的平均检验结果。由图2a和表5可以看出,在21组对比试验中,有18组试验分段权重损失函数模型的TS评分都高于试验对照组。其中,渝中站改进最为明显,TS评分提高0.11,其他站点也有0.05左右的提升。由图2b和表5可以看出,分段权重损失函数模型的准确率在所有站点都有较大幅度的提升。由图2c和表5可以看到,分段权重损失函数模型的空报率略有上升(约0.05~0.1),但上升幅度明显小于命中率,除锦州站外平均空报率不超过0.5。对比图2和表5可以看到,改进后的预测模型在21组对比试验中,均表现出相似的优化结果,表明本文提出的改进方案具有一定的泛化性能。总体上看,渝中站和锦州站的TS评分较低,这主要是由于短时强降水个例偏少,模型无法学习到有效的特征信息所致。综上所述,改进后的预测模型,在TS评分略有升高、命中率大幅提升的基础上,空报率略有升高,预报能力明显加强。预测模型的改进符合对分段权重损失函数优化的预期,且表现出一定的泛化能力。
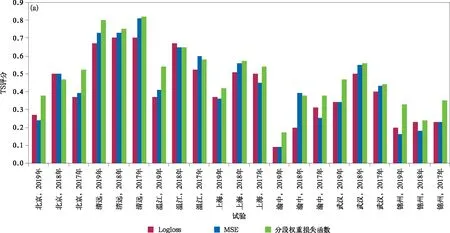
图2 损失函数对比试验检验结果 (a)TS评分,(b)命中率,(c)空报率Fig.2 Comparison test of loss function(a)threat score,(b)probability of detection,(c)false alarm rate
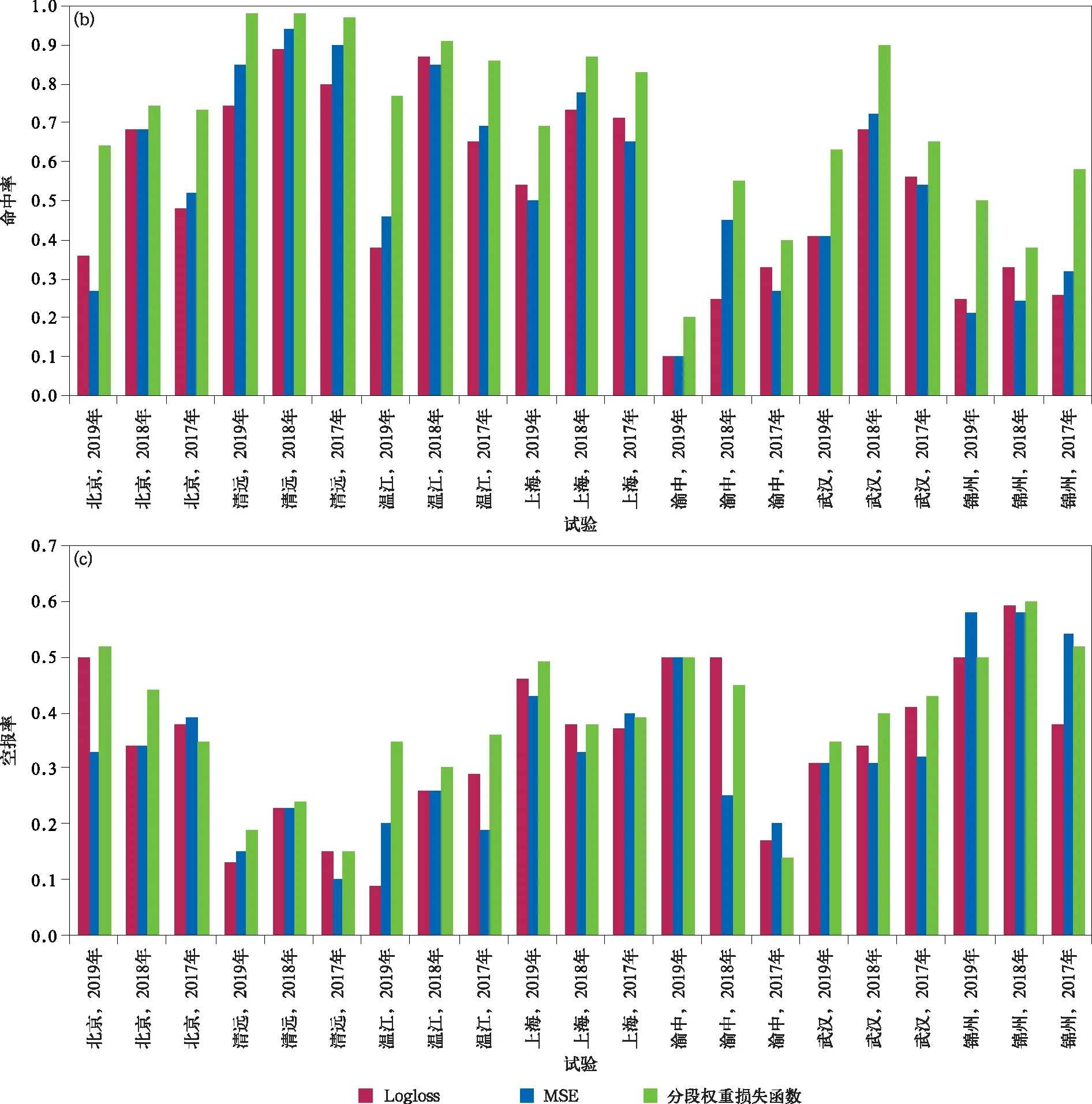
续图2
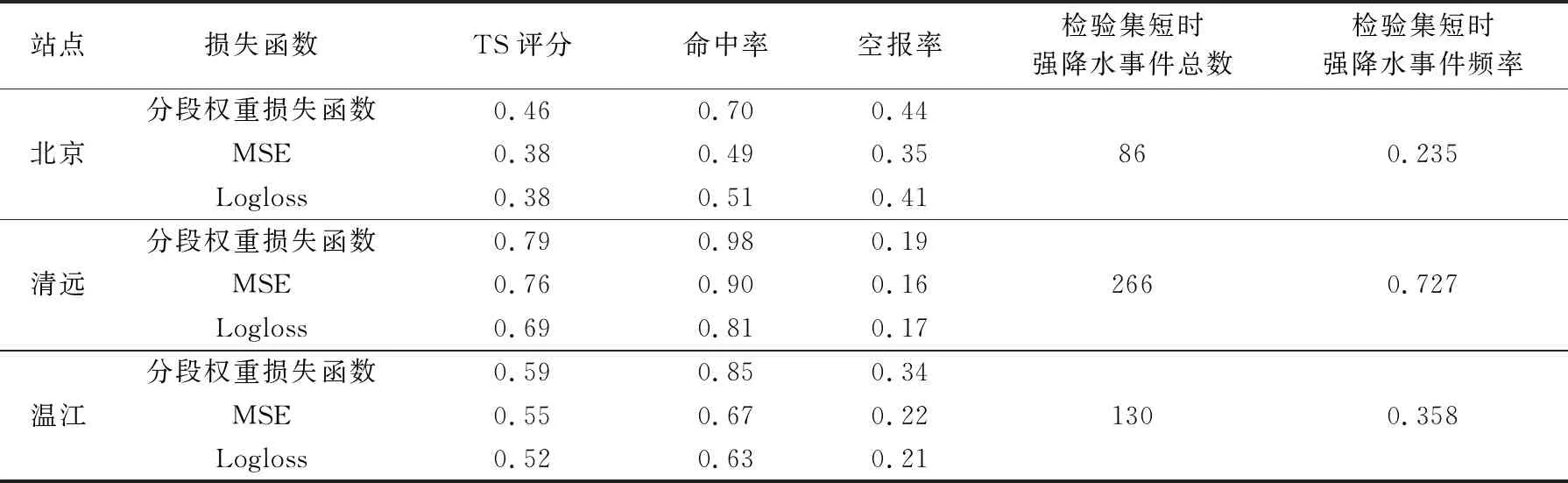
表5 站点平均检验结果Table 5 Average result of comparison test of loss function at each sounding station
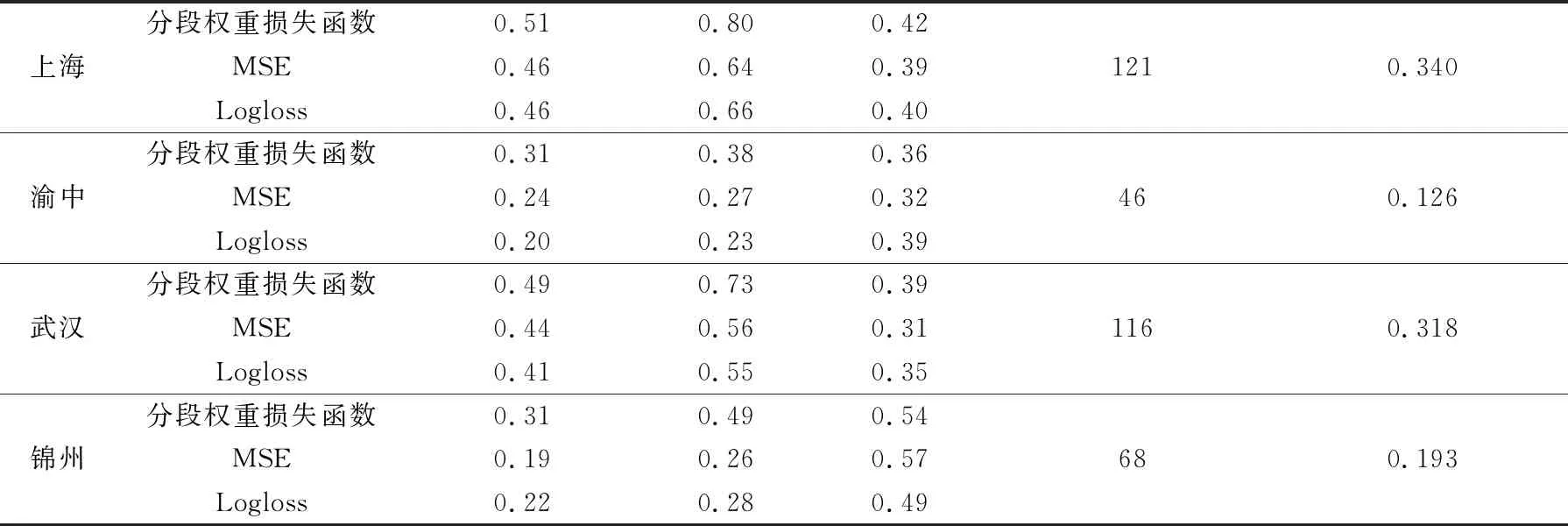
续表5
此外,改进模型在不同站点呈现出不同的优化能力,这可能是由于本文未针对指定站点进行参数优化。针对不同站点定制参数调优,可进一步改进效果。
3.4 全国预报试验
3.4.1 预报试验设计
基于改进的预测模型,使用“试验2019” 数据集对我国119个探空站分别建模,进行全国范围的短时强降水预报试验。所有站点的分段权重损失函数使用统一的权重参数配置方案:wTP=1.0,wTN=1.0,wFP=1.0,wFN=0.4。
3.4.2 个例检验结果
2019年6月20—25日,我国受到高空槽、低层切变线和低层急流的共同影响,在西南地区东部、黄淮西部、江南、华南等地,出现一次自北向南的区域性短时强降水过程[34]。图3为6月21—24日08:00 模型预测的12 h短时强降水预报和实况叠加图,图中浅灰色实心圆为未来12 h内出现20 mm·h-1以上降水的站点。综合图3可以看到,受大尺度天气系统影响, 21日短时强降水雨带位于长江中下游沿线,随着850 hPa切变线的南压,雨带整体向南移动,到23—24日雨带维持在东南沿海地区。对比模型的客观预报结果可以看到,模型对于主体雨带的预报较好,说明通过对历史数据的建模,模型具备一定的短时强降水事件预报能力。由图3a、图3b可以看到,模型的空报主要出现在东南沿海地区,这主要是由于本次过程前期,底层切变线维持在西南地区东部至长江南部,东南沿海一直处于西南气流中,大气湿度条件较好,且东南沿海站点的历史短时强降水日数较多,使预报结果出现一定范围的空报。图3还可以看出,漏报主要集中在主体雨带的西北部。另外,在本次过程中,模型对于零星的短时强降水点预报效果不佳。通过定量化检验,本次过程预报模型的命中率为0.64,空报率为0.38,漏报率为0.36,TS评分为0.46。
3.4.3 长时间序列检验结果
本文使用“试验2019”数据集,进行长时间序列的全国短时强降水预报试验,并给出同时间段08:00 起报的GRAPES_3 km短时强降水预报检验结果。在GRAPES_3 km检验时,先将GRAPES_3 km的格点预报转换到探空站点上,再使用2.1节的方法进行预报检验,具体方法:①首先在每一格点上,取GRAPES_3 km 1~12 h的小时降水量的最大值,得到未来12 h内最大的小时降水量预报场;②统计探空站周边2°×2°范围内,最大小时降水量预报超过20 mm的格点数,当格点数不低于2时,则记录为一次短时强降水预报;③使用2.1节中的方法,进行预报检验。
以某一日某个站的探空观测记录为1站次,则在 “试验2019”检验集中共得到14389站次数据,其中发生短时强降水事件2579站次,表6给出预测模型和GRAPES_3 km模式的2019年检验集检验结果。其中,预测模型命中短时强降水事件1693站次,命中率为0.66,空报短时强降水事件1004站次,空报率为0.37, TS评分为0.47。GRAPES_3 km,命中1806站次,命中率为0.7,空报2040站次,空报率为0.53,TS评分为0.39。通过对比可以发现,预测模型虽然命中数少113站次,但是空报少1036站次,TS评分较GRAPES_3 km提高0.08,总体上看,预测模型的短时强降水预报能力更强。
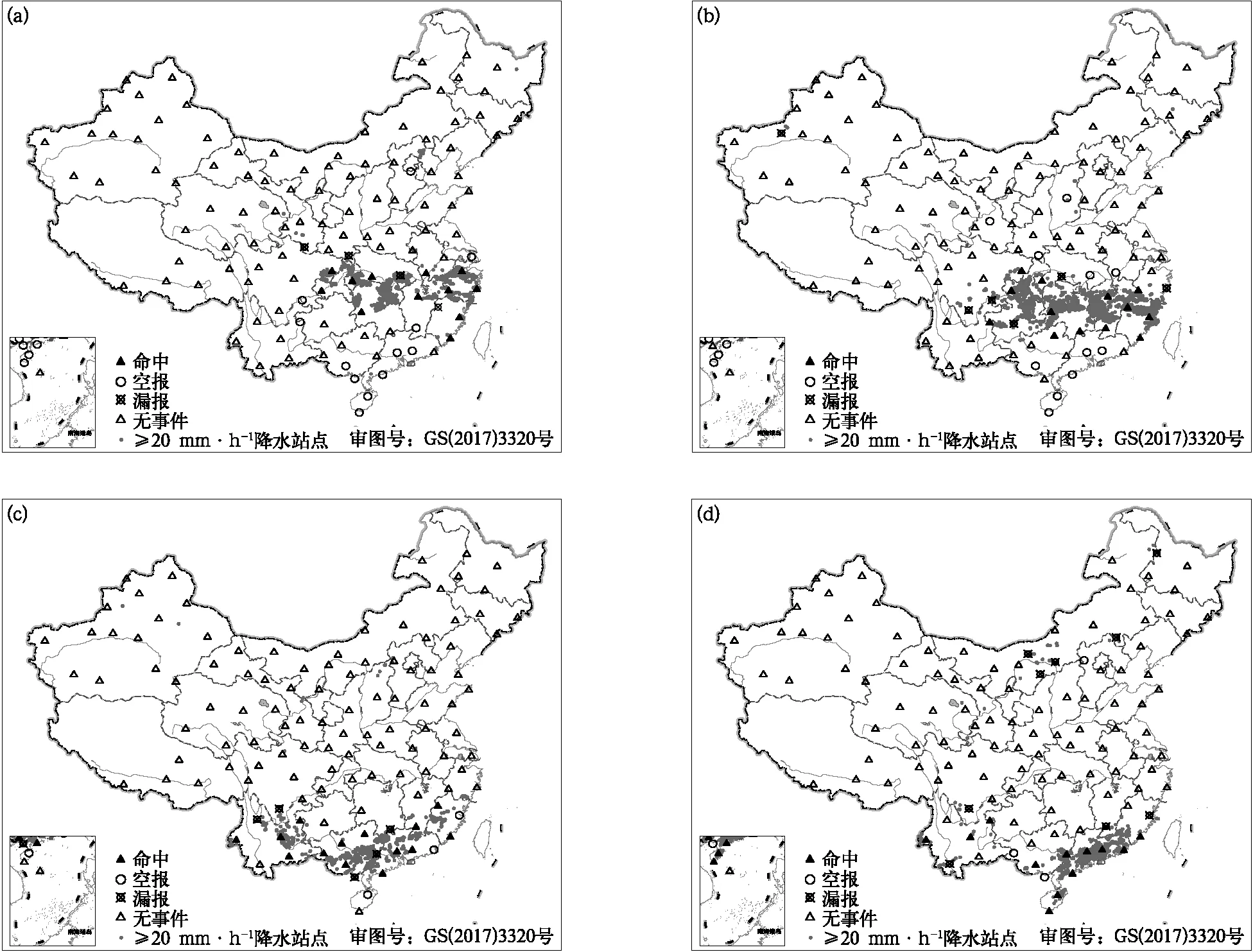
图3 2019年6月21—24日08:00 12 h短时强降水预报和实况对比(a)6月21日,(b)6月22日,(c)6月23日,(d)6月24日Fig.3 Comparison between observation and 12 h forecast at 0800 BT from 21 Jun to 24 Jun in 2019(a)21 Jun,(b)22 Jun,(c)23 Jun,(d)24 Jun

表6 2019年检验集长检验结果Table 6 Quantitative validation of prediction model on 2019 dataset
4 结论与讨论
本文介绍一种基于集成决策树的短时强降水预报模型。该模型以08:00探空观测和常用对流参数为特征,预报未来12 h短时强降水事件。在此基础上,提出一种面向高影响天气的模型优化思路,即通过分段损失函数调整模型“宁空勿漏”的预报倾向,在控制空报率不超过一定阈值的基础上,最大程度提升模型的预报命中率和TS评分。通过区域中心探空站的权重敏感性试验、损失函数对比试验,以及全国探空站的短时强降水预报试验,得到以下结论:
1) 使用分段权重MSE作为模型的损失函数,通过权重系数的调整,可以有效引导模型向倾向预测发生(positive)或倾向预测不发生(negative)的方向优化,进而使最终预测模型获得一定预报倾向。
2) 减小wTP会明显减少模型预测的命中数和空报数,模型有“宁漏勿空”倾向;减小wFN会明显增加模型预测的命中数和空报数,模型有“宁空勿漏”倾向;wTN和wFP对预测模型影响较小。
3) 通过7个区域中心探空站共21组试验数据验证,改进后的模型和常规模型相比,TS评分提高0.05~0.1,命中率提高0.10以上,空报率提高0.05~0.1,表现出明显的“宁空勿漏”预报倾向,预测模型的实际预报能力得到明显提升,且优化方案表现出一定的泛化能力。
4) 全国短时强降水预报试验的独立检验表明:改进后的预报模型在2019年独立检验集上,命中率为0.66,空报率为0.37,TS评分为0.47,该模型具备一定的短时强降水天气预报能力。
本文的预报试验存在以下局限性:08:00探空无法准确描述午后大气的垂直结构,导致预报试验本身存在一定的不确定性;通过多组试验发现,不同试验组构建模型的特征重要性差异较大,即便在同一站同一组数据中,使用不同模型参数可能得到大相径庭的特征,所以如何使用模型反推验证短时强降水机制还有待进一步研究。此外,本文方法所给出的短时强降水预报,具有范围大、预报时间长等特点。在实际预报中,还需要预报员利用雷达、卫星、闪电、自动站等多源数据进一步分析,以得到更为精准的预报落区。
在今后工作中,可从原始数据上继续优化模型,如使用14:00加密探空数据构建模型;或基于模式探空构建模型,形成格点化的预报产品;也可以考虑建立模型预测的事件发生概率值和实际短时强降水发生概率的映射关系,得到格点化的概率产品。
致 谢:感谢国家气象中心郑永光研究员和关良助理工程师提供短时强降水站点数据集。
猜你喜欢
成都信息工程大学学报(2021年5期)2021-12-30
成都信息工程大学学报(2021年3期)2021-11-22
成都信息工程大学学报(2019年4期)2019-11-04
电子制作(2019年14期)2019-08-20
国际呼吸杂志(2019年1期)2019-01-28
中国自行车(2017年1期)2017-04-16
故事会(2016年21期)2016-11-10
高原山地气象研究(2016年1期)2016-11-10
高原山地气象研究(2016年3期)2016-02-28
西藏科技(2015年3期)2015-09-26
