
基于BERT的安全事件命名实体识别研究
2021-03-11 06:04窦宇宸
信息安全研究 2021年3期
窦宇宸 胡 勇
(四川大学网络空间安全学院 成都 610065)
(douyuchen_jl@163.com)
随着网络技术的迅速发展,我国的互联网规模迅速增长,“上网冲浪”已经成为我们日常生活中获取信息的重要方式,但其中海量数据也带来了不少“信息重复”及“信息冗杂”等问题,抽取句子中的重要信息并准确定位公众关注的事件信息则尤为重要.在我们日常接触到的新闻、网页、微博、公众号及常见新闻等获取渠道中,每一篇文章甚至每一个句子都可能包含巨大的信息量,由于中文语义的复杂性及句子用词的随意性,使用人工方法区分关键信息工作量巨大.命名实体识别(name entity recognition,NER)正是解决这个问题的有效自动化方法之一.NER指从1段自然语言文本中找出特定类型的实体(如人名、组织名称、地点、时间及行为等),并标注其位置,是信息检索及关系抽取等工作的基础.前期研究人员经常使用的统计模型有隐马尔科夫模型(HMM)、支持向量机(SVM)、最大熵模型(ME)及条件随机场(CRF)等,这类方法通常是将实体识别任务转换为从文本输入到特定目标结构的预测,使用如上的统计模型来构造输入与输出的关联,并使用机器学习方法来学习模型的参数.但是这些方法均需要人工提取特征,不仅会导致研究人员在标注文本时承受庞大的工作量,也会使得提取的特征易丢失文本本身的情感信息,实体识别的效果欠佳.与传统的机器学习识别方法相比,针对文本信息中语义不明确且上下文关联不明晰的情况,命名实体识别的方案逐渐从需要大量人工提取特征的统计概率模型逐步转向深度学习领域,深度神经网络可以自动地从数据中提取有用的特征,将其应用于非结构化、模式多变的数据中具有显著优势,并可以更好地解决文本特征稀疏等问题.
在中文命名实体识别领域,2005年,向晓雯等人[1]采用隐马尔科夫模型进行词性标注,还对上下文相关的命名实体识别作了初步尝试.2011年,龚凌晖[2]针对现代汉语文本的特点,以人名、地名及组织名为核心内容的中文命名实体识别问题,基于LSA(潜在语义分析)实现对命名实体的歧义消解,实现了一个基于CRF的中文命名识别系统,验证了用算法建立一个有效实体库的可行性.2016年,朱丹浩等人[3]针对中文机构名结构复杂、罕见词多及识别难度大问题,采用RNN重新定义了机构名标注的输入与输出,在识别机构名实体的F1值上有一定的提升.2018年,李丽双等人[4]采用CNN-BiLSTM-CRF的模型,利用CNN训练单词形态特征的字向量,再组合语义向量输入至BiLSTM层,该模型应用在生物医学语料上取得了较好的结果.2019年,黄炜等人[5]使用BiLSTM网络完成语句的上下文关联语义分析后,接入CRF层添加约束的方法应用在涉恐信息实体识别领域,有效获取涉恐人员恐怖主义机构及暴恐实施地点等重要信息.2021年,范晓霞等人[6]设计了一个针对暗网市场文本的命名实体识别系统,使用卷积神经网络(CNN)进行字符向量化以学习单词形态特征,将双向长短时记忆神经网络应用于暗网市场文本的命名实体识别,并采用CRF模型实现序列标签之间的约束性,目前该系统在暗网市场文本命名实体识别领域内效果较佳,准确率达到98.59%.
上述方法中字向量为使用已经被大量语料训练完成的词嵌入(word embedding).词嵌入是自然语言处理领域早期的预训练技术,Bengio等人[7]提出了神经网络语言模型.Mikolov等人[8]对神经网络语言模型优化,提出Word2Vec,并提出2种语言模型——连续词袋模型(CBOW)和Skip-gram模型.Word2Vec能捕捉词语之间的相似性,可根据上下文预测中间的词汇,但没有考虑单词的词序问题.Pennington等人[9]提出Glove词向量,可获取全局信息,更容易并行化,与Word2Vec相比,在数据集较大时,Glove可更快地进行训练.
上述词向量可以在一定程度上提高模型准确率,但不同语境下的词向量相同,无法解决一词多义问题[10].同一个字或词语在1个句子中的语义不同,例如句子“你这着真绝,让他干着急,又无法着手应付,心里老是悬着.”4个“着”字在客观上表达的是不同的词意,但在Word2Vec,Glove等字向量表示方法中,4个“着”的字向量表示完全一致,这与我们正常理解这句话的含义不同.所以准确地描述当前词在上下文中的含义对于文本中提取字或词的向量十分重要.由于BERT预训练模型采用双向Transformer 编码器对上下文信息都进行了提取,融合左右2侧的语境,得到一个深度双向Transformer. BERT对单词及上下文关系作了充分描述,能有效实现多义词的消歧.所以本文选择使用BERT预训练模型替代传统的词嵌入方法,接入BiLSTM以解决一词多义的问题.杨飘等人[11]针对字多义性,使用BERT-BiGRU-CRF融合模型在MSRA语料中作的命名实体识别的效果好于目前最优的Lattice-LSTM模型.
为解决公共安全事件的命名实体识别问题,本文使用已被大规模中文语料训练完成的BERT模型作为双向长短时记忆网络的输入,获取汉字的语义向量表示,确保在识别标注的任务中的字向量具有多义性.在双向长短时记忆网络后接入CRF层,从而实现了对公共安全事件命名实体的自动识别.实验表明,该方法能够取得较好的效果,可以在一定程度上解决公共安全事件领域命名实体识别问题.
1 模型结构
本文将公共安全事件的文本输入至BERT预训练语言模型,获取每个字的向量表示.将字向量序列输入BiLSTM层用以提取特征,最后通过CRF层选择概率最大的标注输出为各字的标签,即将BiLSTM层原本的Softmax层替换为CRF层.本文中使用的BERT-BiLSTM-CRF模型整体结构如图1所示,模型包含以下4个部分:预训练层、BiLSTM网络层、特征提取层及CRF层.

图1 BERT-BiLSTM-CRF模型结构图
1.1 预训练层模型
在NER研究中的模型大多采用已预训练好的Word2Vec,Glove等获取文本的词嵌入向量表示,未使用预训练模型,在其研究上也能够达到不差的效果.用稀疏向量表示文本,即所谓的词袋模型在NLP有着悠久的历史.正如上文中介绍的,早在 2001年就开始使用密集向量表示词或词嵌入.Mikolov等人[8]在2013年提出的创新技术是通过去除隐藏层,逼近目标,进而使这些单词嵌入的训练更加高效.虽然这些技术更新本质上很简单,但它们与高效的Word2Vec配合使用,才能使大规模的词嵌入训练成为可能.但是使用这些词向量忽略了词的上下文关系,在不同场景下词的向量表示是相同的,缺乏消歧能力.本文使用基于BERT预训练模型,采用BERT官方的大规模中文语料训练模型,可包含大多数的词汇与场景,竭力解决一词多义问题.
从BERT的结构层面来看,它和GPT,ELMo一样都采用Transformer的结构,相对于GPT来说,BERT是具有双向Transformer的模型结构,BERT的模型结构如图2所示.BERT在预训练过程中提出了掩码语言模型与下一条句子预测,作用分别是作上下文预测与学习语料中数据的相关性.

图2 BERT模型结构图
在掩码语言模型任务中,BERT会随机选择1个句子中15%的词,用它们的上下文来作预测用以训练,而不是像CBOW一样将每个词都预测1遍,最终的loss只计算被[MASK]的15%的词.在随机[MASK]时将10%的单词替换为其他单词,10%的单词不作替换,剩余80%被替换为[MASK].
在下一条句子预测任务的目的是让模型理解2个句子之间的联系,例如句子A与句子B,B有一半的概率是A的下一句,输入这2个句子来预测B是不是A的下一句.
BERT模型的输入为3个向量,分别为词向量、分段向量及位置向量.词向量指当前词的词向量表示,第1个单词是[CLS]标识;分段向量是表示当前词所在句子的位置向量.位置向量是表示当前词属于哪个句子.样例如图3所示.在BERT模型中的输入可以为单一的句子或是句子对,实际输入是这些向量之和.将以上向量之和输入到12层的双向Transformer网络中,最后一层Transformer结构得到的即为BERT层输出.

图3 BERT输入向量表示
1.2 BiLSTM层模型
自RNN(循环神经网络)提出以来,被大量运用于NER等领域,具有记忆的能力,但由于RNN存在梯度消失或梯度爆炸的问题,在处理长序列的数据方面很困难,研究人员对RNN作出了一些改进,得到了RNN的另一种形态,它可以捕捉长期依赖关系,即LSTM. LSTM神经网络结构如图4所示,由于它长时间的记忆能力,在自然语言处理和语音识别等领域应用广泛.

图4 LSTM神经元结构图
LSTM模型的计算过程如下:
ft=σ(Wfhht-1+Wfxxt+bf),
(1)
it=σ(Wihht-1+Wixxt+bi),
(2)
ot=σ(Wohht-1+Woxxt+bo),
(3)
ct=ittanh(Wchht-1+Wcxxt+bc)+ftct-1,
(4)
ht=ottanh(ct),
(5)
其中,对于时刻t,ht-1,xt分别表示隐层状态及输入词;W表示LSTM的权重矩阵;b表示偏置;ft,it,ot分别表示LSTM的遗忘门、输入门、输出门,σ表示激励函数Sigmoid,tanh表示双曲正切函数.
单向LSTM由于按文本序列输入,无法编码从后到前的信息,只能处理上文的信息而忽略了下文信息.继而研究人员又提出了BiLSTM模型(如图5所示),也就是双向LSTM结构,对每一个训练序列分别训练一个向前LSTM和向后的LSTM网络.这种网络的结构可以将前后LSTM的输出拼接成一个完整的序列,从而提供每一个序列点完整的上下文信息.

图5 BiLSTM模型结构图
1.3 CRF层模型
CRF是给定1组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔科夫随机场.广义CRF的定义是:满足P(Yv|X,Yω,ω≠v)=P(Yv|X,Yω,ω~v).线性链条件随机场(其结构如图6所示)可以用于标注问题.此时在条件概率模型P(Y|X)中,Y是输出变量,表示标记序列,也可称为状态序列;X是输入变量,表示需要标注的观测序列.在模型学习时,对训练数据集进行正则化的极大似然估计得到条件概率模型;在预测时,对给定的输入地址序列,求出条件概率最大的地址标注序列[12].

图6 CRF链式结构图
2 实 验
2.1 实验环境
本文采用Tensorflow作为深度学习框架,数据集预处理使用Java实现.实验运行环境为Windows终端,在Windows 10 教育版64 b的操作系统下完成该实验,内存大小为16 GB,处理器型号为Intel Core i7,GPU显卡是GTX 1060,显存为5 GB.
2.2 数据集描述
本文采用的数据集是中文突发事件语料库[13](Chinese emergency corpus, CEC)由上海大学(语义智能实验室)所构建,他们从互联网上收集了5类突发事件的新闻报道作为生语料,然后再对生语料进行文本预处理、文本分析、事件标注以及一致性检查等处理,最后将标注结果保存到语料库中,CEC合计332篇.CEC 采用了XML语言作为标注格式,其中包含了6个重要的标记:Event,Denoter,Time,Location,Participant,Object,CEC语料库的规模虽然偏小,但是对事件和事件要素的标注却最为全面.
本文使用该数据集标记的Denoter,Time,Location,Participant作为本文的主要标记,记为ACT,TIME,LOC,PER,分别表示行为、时间、地点及参与者.数据的统计信息及标记的数量等如表1所示.数据标注示例如表2所示.

表1 数据集分布

表2 数据标注示例
2.3 实验设计
本实验分为4个部分,分别为数据预处理、数据预训练、输入BiLSTM层和输入CRF层,一共332篇文章,本文将数据集按7∶2∶1的比例随机划分,分别为训练集、测试集和验证集.
2.3.1 数据预处理
本文的数据集采用BIO序列标注法,即将每个元素标注为“B-XXX”,“I-XXX”,“O”,其中,“B-XXX”表示此元素所在的标注序列中属于XXX类型并且是这个标注序列的开头,“I-XXX”则表示此元素所在的标注序列中属于XXX类型并且在这个序列标注的中间部分.由于CEC语料库使用XML语言进行标记,获取其 Denoter,Time,Location,Participant标签作为序列标注的特征,分别提取为ACT,TIME,LOC,PER.由于该语料库已经被预处理过1次,不需要再进行停用词去除等操作.
2.3.2 数据预训练
本文使用Google大规模中文语料训练好的模型[14],调整运行batch_size并设置为16,将该模型载入BERT,再将BERT作为入口,输入作为预处理的训练集、测试集及验证集.
2.3.3 BiLSTM层
将预训练层输出的每个字的字向量输入BiLSTM层,提取文本特征.
2.3.4 CRF层
将BiLSTM层提取的特征的输出放入CRF层,经过序列标注后得到最终结果.实验具体参数见表3所示:

表3 超参数设置
2.4 实验分析
2.4.1 评价标准
本文采用常用的NER评价指标[15]来衡量实验结果:精确率P(precision)、召回率R(recall)和F1(F-measure)值.
(6)
(7)
(8)
2.4.2 实验结果及分析
为了证明本文方法的有效性,实验首先要证明BERT预训练模型是否能够消歧并解决一词多义的问题,本文使用BERT与其他2种常用的词嵌入模型作对比实验.目前常用Glove与Word2Vec获取预训练词向量,故分别使用Word2Vec和Glove与本模型对比,以获取词向量.将通过上述3种方法获取的词向量再输入到BiLSTM-CRF中进行实验,测试集实验结果如表4所示:

表4 不同预训练模型性能
从表4看出,常用的Word2Vec与Glove模型分别得到了0.691,0.703的F1值,不难看出这2种模型由于欠缺语义上下文的相关性分析,对于任务作业没有明显的提升.而本文使用的BERT模型在作业中的F1值达到了0.859,证明了具有消歧作用的BERT模型在该任务上具有更好的性能,克服了传统的一词多义问题.
其次,为了证明本文使用融合模型的性能,对CRF,BiLSTM,BiLSTM-CRF,BERT-BiLSTM-CRF这4种方法的总体精确率、召回率及F1值作对比,如表5所示:

表5 模型整体序列标注性能
从表5可知,上述4种方法得到的F1值分别为0.659,0.703,0.763,0.859.其中,本文使用的BERT-BiLSTM-CRF模型的3个指标均最高,其次为常用的BiLSTM-CRF方法,各方面性能与本文方法相差10%,说明了预训练模型BERT消歧的有效性.CRF与BiLSTM方法相差5%左右,说明BiLSTM在处理文本关系上的性能优于CRF模型.最终,可以得出结论:本文使用的BERT-BiLSTM-CRF模型在对公共安全事件命名实体识别整体性能优于其他3种方法.
最后选取本文模型与其中表现较好的BiLSTM-CRF模型对公共安全事件各个序列标注的F1值作细化对比,结果如表6所示:
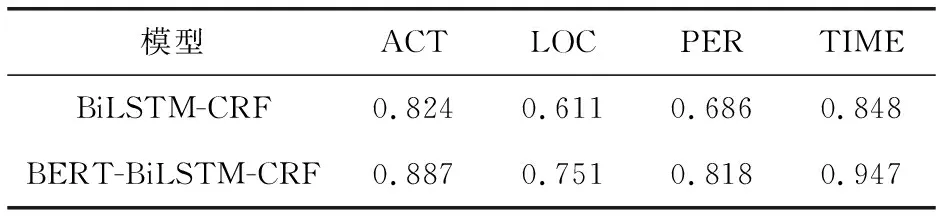
表6 BERT-BiLSTM-CRF与BiLSTM-CRF模型LOC标签F1值对比
从表6可看出,2种模型都对LOC(位置)标签的序列标注的误差相对其他标签较大,本文也通过多次实验得出每次训练得到的LOC标签的F1值均高于75%,本文模型在LOC识别的方面远高于另一模型.在PER(参与者)的标注序列中,显然本文使用的模型优于另一模型,高于其13%左右,归因于BiLSTM-CRF所使用的词嵌入模型缺少上下文分析,未能解决一词多义的问题.在ACT(行为)和TIME(时间)标签的序列标注中,上述模型均表现较好,F1值均达到80%以上.
基于上述对比实验可知,本文使用的BERT-BiLSTM-CRF模型可获得更优的效果.在BiLSTM-CRF模型标注的基础之上,使用BERT预训练模型提取特征向量,对多义词进行消歧,解决相同字词在安全事件领域的歧义问题,效果优于其他神经网络模型及机器学习方法.
3 结 论
本文对公共安全事件文本中的命名实体进行研究,针对公安全事件文本冗杂的特性及中文字词的多义性,在原有研究的基础上进行改进.在经过BiLSTM-CRF模型标注的基础上,加入BERT预训练模型,提高了实体识别的效果.使用BERT预训练模型获取词向量,解决了一词多义的问题,使用BiLSTM模型解决了特定领域严重依赖人工特征的问题.经过对比实验表明,本文模型具有较好的准确性,与其他模型相比有提升,F1值达到85%以上.由于实验的数据集规模较小,接下来将在增加语料的基础上对方法继续优化,进一步找出安全事件领域中命名实体之间的关系,并创建能被舆情分析或应急响应系统使用的安全事件序列标注的数据集是下一步要研究的重点.
猜你喜欢
江苏安全生产(2022年5期)2022-06-16
通信技术(2021年12期)2022-01-25
中国计算机报(2021年9期)2021-04-26
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中国质量与标准导报(2013年8期)2013-03-11
