
侧扫声呐识别沉船影像的迁移学习卷积神经网络法
2021-03-10 06:40汤寓麟金绍华张永厚
测绘学报 2021年2期
汤寓麟,金绍华,边 刚,张永厚,李 凡
海军大连舰艇学院军事海洋与测绘系,辽宁 大连 116018
海底沉船目标探测与识别是水下碍航物探测和海上应急搜救的重要内容[1],侧扫声呐作为声学探测设备,是海底目标探测的主要技术手段。目前,对侧扫声呐图像的识别一般采用人工判读的方式,但人工判读存在效率低、耗时长、资源消耗大及主观不确定性强和过分依赖经验等问题。当前,随着侧扫声呐在海底碍航物目标探测中的广泛应用,特别是在失事船只搜救方面的应用可快速探测海底目标,在障碍物核查以及失事船只搜救方面发挥了关键作用[2-6],如何客观、精准、快速、高效地识别侧扫声呐图像沉船目标显得愈发重要。为了弥补人工判读方式存在的问题,减弱人为主观因素的影响,国内外学者针对侧扫声呐图像自动检测与分类识别做了大量工作。主要是,首先利用图像处理的基本算法,包括基于脉冲耦合神经网络(PCNN)的图像处理算法、形态学图像处理算法,通过中值滤波、二值化处理、噪声抑制、增益负反馈控制、边缘特征提取、图像增强、图像分割等方式对侧扫声呐图像进行处理[7-15];然后基于颜色、纹理、灰度、形状、主成分分析等算法提取目标特征;最后利用人工提取的特征训练分类器,如隐马尔可夫模型、K近邻、支持向量机(SVM)、BP神经网络等分类器,实现水下目标的识别[16]。文献[17]提出一种基于DBN结构用于水下目标识别的深度学习框架,在40个类别的分类问题中达到90.23%准确率。文献[18]提出基于支持向量机对侧扫声呐图像进行目标识别分类的方法。文献[19]提出基于SVM算法和GLCM的侧扫声呐影像分类研究。文献[20]使用简单的BP神经网络对水下图像目标进行分类识别,人工选取特征后送入神经网络进行分类训练,正确率为80%。文献[21]通过属性直方图提取目标声影特征,再使用模糊聚类和BP神经网络对目标进行识别。这些方法尽管在一定程度上实现了海底目标的自动探测与识别,但受声呐图像质量、特征提取算法模型的针对性等影响,提取的特征参数的有效性、全面性和泛化性很难把握。
近年来,随着计算机算力的极大提高,卷积神经网络(CNN)作为深度学习的代表算法在计算机视觉与自然语言方面获得广泛的应用。不同于人工设计特征,CNN受到人类视觉神经系统启发,对特征进行不同层次的抽象化,学习的特征更适用于图像解析,尤其在图像识别领域取得巨大突破[22]。文献[23]采用卷积神经网络模型将MNIST数据集上的错误率降低到0.95%以下。文献[24]建立的AlexNet深层卷积神经网络模型在图像分类方面获得较好的效果,将测试错误率降低到16.4%。文献[25]建立的VGGnet网络模型的识别错误率仅为7.3%。文献[26]建立了金字塔卷积神经网络(pyramid CNN),在人脸验证上获得97.3%的准确率。卷积神经网络尽管在各个领域得到了广泛的应用,但其性能只有在网络结构比较复杂、训练样本数足够多的情况下才能得以展现,当训练样本缺失时,模型容易出现过拟合、陷入局部最优解以及模型泛化能力差等现象[27-28]。为了解决这一问题,一般采用目前在图像识别领域得到广泛应用的迁移学习方法进行训练[29-35]。
鉴于卷积神经网络在图像识别领域取得了巨大的成功,本文尝试将卷积神经网络算法引入侧扫声呐海底沉船图像识别。拟参照VGG-16模型,根据侧扫声呐沉船数据特点设计一个改进的卷积神经网络模型。同时,针对侧扫声呐沉船数据集样本过少的问题,提出采用迁移学习的方法训练并优化网络模型,以提高模型训练效率和侧扫声呐沉船图像自动识别的准确率。
1 数据集与预处理
本文试验用于训练和测试的侧扫声呐图像主要由国内外各涉海部门使用主要包括Klein3000、Klein3900、EdgeTech4200、Yellowfin、海卓系列和Shark系列等国内外主流侧扫声呐设备,在我国渤海、黄海、东海和南海相关海域以及太湖、千岛湖和鄱阳湖等内陆湖泊实测数据组成,为了进一步丰富样本数据,利用网络搜集部分侧扫声呐沉船图片。最终选择具有海底沉船目标的侧扫声呐图像1000张。卷积神经网络采用权值共享策略,可以降低网络模型的复杂度并减少权值的数量,适合于训练数据集较小的图像识别分类问题[36-39]。但对数据集的要求仍然是样本数目越大越好,以便卷积神经网络学习到的样本特征更多且更具有普适性,从而生成更准确的模型。鉴于海底沉船图像数量较少、背景复杂和目标区域占比少等问题,如果仅利用该数据集训练网络,可能会导致模型过拟合。针对这种情况,本文对数据集进行相应预处理。
1.1 特征标准化及归一化处理
由于海底沉船的图像来源较为复杂,存在很多异质数据(有的数据的一个特征在0—1范围内,另一个特征在100—200范围内),将其直接输入到神经网络中存在风险,可能引起网络较大的梯度更新而导致网络无法收敛。为了简化网络学习,防止梯度爆炸,以便加速网络收敛,输入数据应具有取值较小且范围大致相同的特征。因此,首先对整个数据集的像素进行标准化,将尺寸不一致的图像强制性统一为200×200。原图的灰度值编码为0—255范围内的整数,在将数据输入网络前,对其进行归一化处理,对样本的处理如式(1)和式(2)所示
(1)
(2)
式中,Xi表示该样本中第i个像素点的值;n表示该像素点的总数;μ表示均值;σ表示方差。归一化函数如式(3)所示
(3)

1.2 图像数据集扩充
机器学习的目的是得到可以泛化的模型,深度学习模型自主学习特征的能力依赖于大量的训练数据,图像特征越好,模型学习效率越高,效果越好。样本越少,特征信息价值越重要。为了扩充海底沉船图像数据集,获取明显的特征,本文采用数据增强方式,主要包括图像多尺度剪裁放大、图像平移、图像旋转、图像镜像、图像加噪等,为了保证图像目标的完整性和有效性,剪裁的方式采用手动操作。通过数据增强将输入的1000张图片扩充到5000张,其中训练集中的800张扩充到4000张,测试集中的200张扩充到1000张。部分数据增强后的图像如图1所示,其中最左列为原始图像,往右依次为镜像、旋转、剪裁放大和加噪处理后的图像。

图1 部分图像增强后图像Fig.1 Part of the enhanced image
2 模型与方法
2.1 改进的CNN模型
对于卷积神经网络,在数据和算法相同的前提下,采用不同的网络基础模型会有不同的识别精度,为此,对模型的选择必须综合考虑识别准确率和模型训练效率。本文选择在ImageNet数据集上性能较好且具于代表性的3个模型,分别是VGG-16、Inception-v3及ResNet-101。经比较,VGG-16模型综合性能更好。
VGG-16网络是牛津大学计算机视觉实验室与谷歌DeepMind公司共同开发的一款深度卷积神经网络结构,解决了ImageNet中1000类图像的分类和定位问题[40-41]。VGG-16模型结构由13个卷积层、5个池化层、3个基于激活函数ReLU的全连接层以及1个Softmax输出层组成,网络结构复杂,需要大量的数据集训练。一般来说,结构越复杂,规模越大,层数越深的网络模型识别精度更高,但相应的模型参数更多,当数据集不够充足时,容易产生过拟合的问题,同时训练难度更大,使模型难以收敛。
为了适应海底沉船数据样本少的特点,同时考虑到训练精度和训练效率因素,在VGG-16模型的基础上进行了改进,首先简化了模型结构,构建一个由8个卷积层、4个池化层、2个基于激活函数ReLU的全连接层和1个Sigmoid输出层组成的卷积神经网络模型。如图2所示。
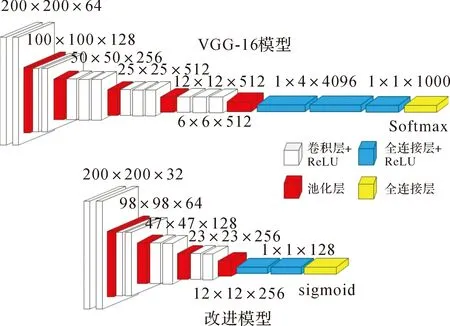
图2 VGG-16模型改进示意Fig.2 Diagram of VGG-16 model improvement
简化的模型和VGG-16模型一样采用大小为3×3的卷积核,通过使用3×3的小卷积核堆叠代替大卷积核达到使用更少的参数表征更多强力特征的目的,同时使用大小为2×2的池化核以保留更多的图像信息。卷积层通过卷积运算提取局部特征,再通过激活函数得到新的特征图。卷积层计算公式见式(4)
(4)
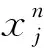
激活函数采用线性整流函数ReLU(rectified linear unit),如式(5)所示
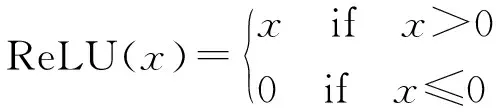
(5)
ReLU函数的作用是增加神经网络各层之间的非线性关系,通过单侧抑制把所有的负值都变为0,而正值不变,使得神经网络中的神经元也具有了稀疏激活性,能够更好地挖掘相关特征,保留图像的特征,拟合训练数据。传统VGG-16模型的输出层Softmax是一个1000类输出的分类器,而本文试验的识别对象仅有沉船和背景两种分类,是一个典型的二分类问题,所以本文采用目前公认的最适合用于解决二分类问题的Sigmoid函数作为输出函数,如式(6)所示
(6)
改进的模型具体结构如图3所示,由2个包含32个卷积核的卷积层+2个包含64个卷积核的卷积层+2个包含128个卷积核的卷积层+2个包含256个卷积核的卷积层+2个包含128个神经元的全连接层+1个Sigmoid输出层组成。为了进一步降低过拟合,在每层池化层后面添加Dropout,就是在训练过程中随机将上一个池化层的一些输出特征舍弃(设置为0),其核心思想就是在输出值中引入噪声,消除或减弱神经元节点间的联合适应性,降低过拟合,提高泛化能力。Dropout比率指被设为0的特征所占的比例,通常在0.2—0.5范围内,往往模型结构越复杂比率越高。根据本文卷积神经网络的模型结构,Dropout比率设置为25%。

图3 改进的卷积神经网络模型Fig.3 Improved convolutional neural network model
2.2 迁移策略与模型构建
由前所述,虽然卷积神经网络在各个领域得到了广泛的应用,但其性能只有在网络结构比较复杂、训练样本数足够多的情况下才能得以展现,特别是针对本文所讨论的侧扫声呐沉船数据集样本过少,模型容易出现过拟合、陷入局部最优解以及模型泛化能力差等现象,为此,本文尝试通过迁移学习的方法训练并优化网络模型,以提高模型训练效率和侧扫声呐沉船图像自动识别的准确率。
迁移学习是一种机器学习技术,是对一个在特定数据集上训练结束并用于某个任务的卷积神经网络进行改造或将已学习获得的知识迁移到一个不同的数据集中,重新用于第2个相关任务。迁移学习是一种优化,重新训练一个复杂的卷积神经网络需要海量的数据资源、大量的计算资源和时间资源,考虑当任务之间具有一定的相关性,先前任务中得到的知识可以经过微小变换甚至无须任何改动就可直接应用于新的任务中,当这些普遍有效的知识在新任务中使用少量数据很难获得,迁移学习可以将已经学到的模型参数通过迁移分享给新模型从而加快并优化模型的学习效率,减少重复劳动和对目标任务训练数据的依赖,提高模型性能。
通常来说,迁移学习的策略有两种。第1种是微调(fine-tuning),在基础数据集上使用预训练网络,并在目标数据集上以较小的学习率反向传播来微调预训练网络的权重,微调全部层参数。第2种是冻结和训练(freeze and train),移除预训练好模型的最后几层,冻结剩下的卷积层,保持权重不更新并作为应用于新数据集的固定不变的特征提取器,再基于新数据集训练移除的最后的卷积层和线性分类器。
针对不同类型的数据集特点采用不同的迁移学习策略,一般来说,当目标数据集与基本数据集相比较小,且图像相似时,使用treeze and train,且仅训练最后一层分类器。当图像不相似时,同样使用feeze and train,不过需要重新训练模型的最后一些层。当目标数据集较大时,一般使用fine-tuning方式。侧扫声呐沉船图像数据集虽然是小样本数据集,但是鉴于图像与ImageNet数据集图像的相似度无法定性的衡量,所以本文试验采取了两种迁移学习的策略。
第1种迁移学习方法采用Freeze and Train方式。卷积神经网络随着层数的加深,层学习到的特征将从浅层特征变得越来越抽象。因此本文试验冻结了在ImageNet上预训练完成的改进模型的前6层卷积层,在目标数据集上初始化并重新训练最后2个包含256个卷积核的卷积层、2个包含128个神经元的全连接层和Sigmoid输出层,具体流程如图4(a)所示。
第2种迁移学习方法采用Fine-tuning方式。首先将改进的模型在ImageNet数据集上进行预训练得到预训练模型,然后再用侧扫声呐沉船图像数据集对预训练后的模型进行参数精调,具体流程如图4(b)所示。
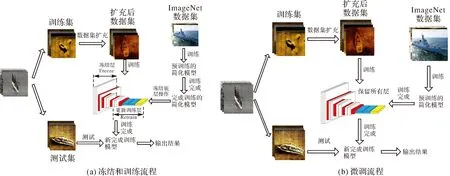
图4 两种迁移学习方法识别流程Fig.4 The flow chart of two transfer learning methods
3 试验与分析
本文试验训练和测试均基于TensorFlow框架下用python编程实现。试验环境:Linux Ubuntu18.04版本操作系统;CPU 为Inter(R) Xeon(R) CPU E5-2678 v3@2.50 GHz;GPU为NVIDIA TITAN RTX,24 GB内存。侧扫声呐沉船图像数据集经预处理后共有5000张,通过程序随机抽取4000张作为训练集,1000张作为测试集。为了让模型尽可能学习到更加精细的图像特征,获得参数解的最优值,模型训练时学习率初始值设置为0.001,采用小批量梯度下降法,即将所有图片分88批次输入模型训练,每批次输入训练(batch size)的图片为64张,共训练了100步(epoch)。
3.1 改进的VGG-16模型性能分析
将VGG-16、Inceptional-v3和ResNet-101这3种模型在上述条件下,即输入训练图片、学习率、训练方式以及计算机硬件等条件都相同的前提下进行训练。在训练过程中,为了有效避免模型过拟合,采用了early stoping策略,即当模型在验证集上准确率趋于稳定时停止训练,具体模型在训练过程中每5步进行一次验证,输出一次验证结果,3种模型的训练结果如图5,模型识别准确率及训练时间见表1。

表1 模型识别准确率及训练时间
图5显示了3种模型的训练结果,横轴为训练轮数(epoch),纵轴为模型在验证集上的准确率。从图中可以看出,3个模型的准确率均随着训练轮数的增加而不断上升,其中,VGG-16模型最终的识别准确率虽然略低于ResNet-101模型,但是模型的训练效率明显更高;VGG-16模型的训练效率虽然略有不如Inception-v3模型,但是最终的识别准确率明显更高。

图5 3种模型的训练结果Fig.5 Training results of the three models
为了证明CNN方法的有效性和可靠性,同时与经典的机器学习方法支持向量机(SVM)进行对比,各模型识别准确率及训练时间见表1。从表1数据可以看出,SVM在训练时间上有较大的优势,但是识别的准确率偏低,这是由于SVM需要靠人工提取全局和局部特征,需要足够的经验。而CNN通过模仿人类视觉神经系统,具有较高的识别准确率,其中VGG-16和ResNet-101模型的识别准确率相差不大,分别为90.03%和90.67%,但是VGG-16模型收敛更快,较ResNet-101模型节省了1825 s,训练效率更高。Inception-v3模型虽然训练效率最高,在训练5880 s后达到收敛,但是识别准确率仅为87.65%,明显低于另外两个模型。综合考虑模型训练效率和识别精度,为此本文采用了VGG-16模型。
另外,本文对传统的VGG-16模型和改进的VGG-16模型在相同的条件下进行训练,训练结果见表2。

表2 传统VGG-16与改进VGG-16模型识别准确率及训练时间Tab.2 Accuracy rate and training time of traditional and improved VGG-16 models
从表2数据可知,传统VGG-16模型在训练了85步,耗时7135 s后趋于收敛,且识别准确率达到90.03%;改进的VGG-16模型的识别准确率为90.58%,较传统模型提高了0.55%,最重要的是模型在保证准确率的前提下,仅训练了60步,耗时4740 s后便达到收敛,训练时间较传统模型提高了近30%,训练效率大大提高,证明了改进模型的有效性。为了验证改进的VGG-16模型的稳定性,在相同的条件下利用该模型进行10次训练,识别准确率误差优于±0.3%。
3.2 迁移策略效果分析
为了验证迁移学习策略能够提高模型对侧扫声呐沉船图像识别的准确率,分析比对了第1种迁移学习方法(Freeze and Train)和第2种迁移学习方法(Fine-tuning)以及全新学习方法(即初始化模型参数,在数据集上从头训练)的试验结果。
本文试验使用的评价标准为准确率(accuracy)、查准率(precision)、查全率(recall)和平均精确率(average precision,AP)。其中准确率表示正确识别的样本数占总样本数的比值,如式(7)所示
(7)
查准率表示识别为正样本中实际为正样本的概率,如式(8)所示
(8)
衡量结果的精确性;查全率表示正样本中识别为正样本的概率,衡量结果的完整性,如式(9)所示
(9)
式中,TP(true positives)表示正确识别的正样本;FP(false positives)表示错误识别的正样本;TN(true negatives)表示正确识别的负样本;FN(false negatives)表示错误识别的负样本。
AP是反映整个模型性能的指标,为P-R(precision-recall)曲线的面积值,也就是平均精度,AP定义如式(10)所示

(10)
通过实时观测3种方法的训练集与测试集的损失值发现,3种方法的模型均在训练100步内趋于稳定,损失值的变化在0.1以内,准确率的变化在1%内,因此,本文试验选择了训练100步同时保存训练集与测试集的评估结果,并记录训练后的模型测试的查准率、查全率及AP值,具体结果如表3所示。

表3 模型损失值和准确率以及识别性能
从表3可以看出在学习率设为0.001的情况下,第1种迁移学习方法在训练集上的损失值为0.56,在测试集上的损失值为0.61,不管是在训练集还是测试集上的损失值都明显低于第2种迁移学习和全新学习两种方法,说明第1种方法的模型拟合程度更高,更加具有普适性第1种迁移学习方法在准确率上也明显高于其他两种方法,在训练集上达到了97.36%,比第2种迁移学习和全新学习分别提高了9.34%和2.22%。同时在测试集上准确率达到了93.71%,比另外两种方法分别高了9.22%和3.13%。证明了第1种迁移学习方法的可行性,冻结的卷积层已得到充分的训练,能够很好地提取图像的通用特征,通过初始化并重新训练的高层参数能够很好地识别侧扫声呐沉船图像的抽象特征,从而达到很好的识别准确率。由于沉船数据集样本过少且图像存在一定特异性与ImageNet数据集差异较大,第2种迁移学习方法通过少量数据样本对整个网络模型的参数进行微调的效果不理想,识别的准确率甚至不如全新学习,证明第2种迁移学习方法存在一定的局限性。
第1种迁移学习方法、第2种迁移学习方法和全新学习的AP值及P-R曲线如图6所示。第1种迁移学习方法的AP值最高为92.45%,分别比第2种迁移学习方法和全新学习高了8.06%和3.06%,且模型在查全率达到93%的情况下查准率达到98%。而第2种迁移学习方法的识别性能在查准率95%的情况下查全率仅为86%,各项指标都不如全新学习,证明第1种迁移学习方法识别效果性能更佳。
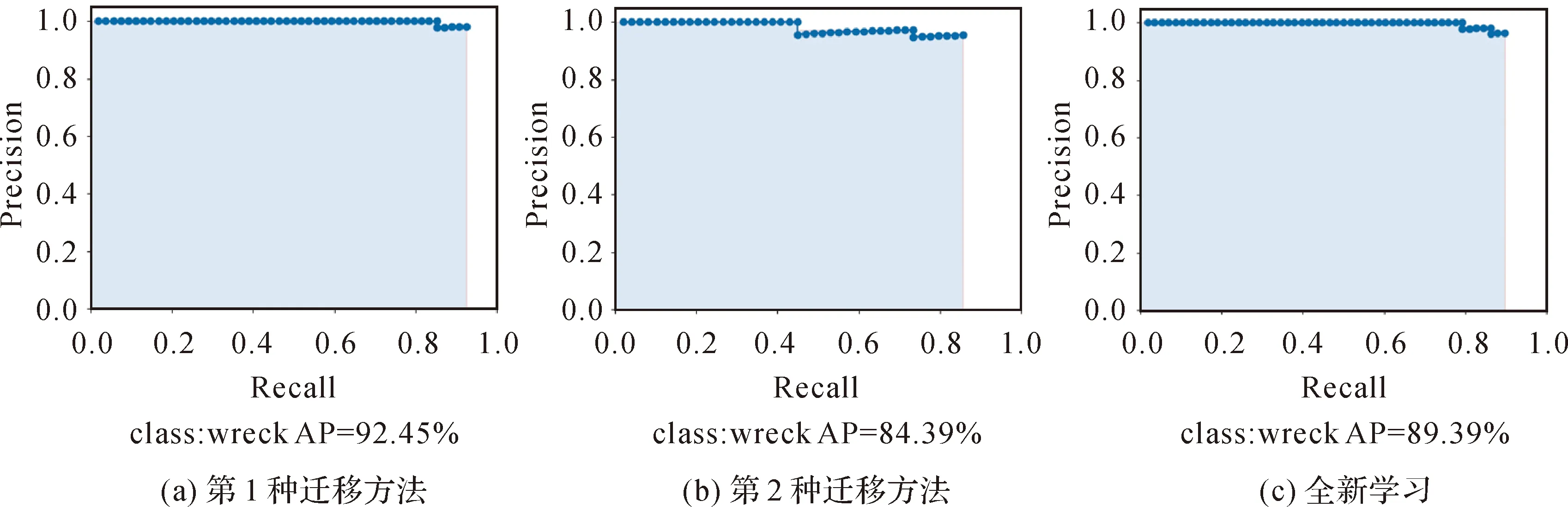
图6 3种方法的P-R曲线Fig.6 The P-R curves of the three methods
为了更好地反映模型训练的实时变化与拟合程度,每训练一步便会保存模型的评估结果,3种方法的训练集与测试集损失值和准确率如图7所示。
由图7(a)训练与测试损失值可以看出,第1种迁移学习方法收敛速度最快,在训练集上训练了20步之后便开始趋于收敛,全新学习方法在30步之后开始趋于收敛,而第2种迁移学习方法收敛速度最慢,在训练了90步之后才趋于收敛。另外,测试集也明显地反映出了训练集的特点,第1种学习方法在25步左右便开始趋于收敛,相比全新学习的35步和第2种方法的90步具有更快的收敛速度。
由图7(b)训练与测试准确率可以看出,3种学习方法的训练初始阶段的准确率分别为14.41%、10.03%和2.31%,在测试初始阶段分别为35.53%、24.58%和8.83%。两种迁移学习方法在初始阶段的识别准确率要明显高于全新学习方法,证明了迁移学习在模型建立之初便拥有了一定的识别能力,其中第1种学习方法的效果最佳。另外,在迁移学习的基础之上,第1种方法在训练集上快速学习,在经过15步之后就达到90%的识别准确率,40步之后便趋于收敛,达到了97%左右的识别准确率,而全新学习在训练了60步之后模型才趋于稳定,识别准确率为95%左右。第1种学习方式在测试集上经过55步训练模型达到收敛,识别准确率达到93%左右,而全新学习在测试集上训练了60步之后趋于稳定,且波动幅度较大,准确率低于第1种方法,达到90%左右。第2种迁移学习方法虽然在初始识别准确率上要高于全新学习,但是模型的整体学习效率不高,训练集在训练了65步之后才达到收敛,且最终的识别准确率为88.03%,低于全新学习的95.14%。在测试集上,第2种学习方式识别准确率波动幅度较大,模型难以达到收敛,在70步之后才趋于稳定,仅达到84.49%,低于全新学习的90.58%。

图7 训练与测试损失值与准确率Fig.7 Training and testing loss value and accuracy rate
结合表3和图6、图7,第2种迁移学习方法通过小样本数据进行全局的参数调整并不能达到很好的迁移效果,而第1种迁移学习方法可以加速网络收敛,相比全新训练方法,在模型的训练与优化上速度更快,可以节省更多的资源,具有更高的效率,同时在提高模型识别准确率和整体性能上具有明显的促进作用,证明了小样本侧扫声呐沉船数据集利用该迁移学习方式是可行的,具有一定的优越性。
4 结束语
针对传统侧扫声呐图像判图存在过分依赖经验、人为主观性强及判读效率低下等问题,以及侧扫声呐沉船图像属于小样本数据库的局限性,本文引进卷积神经网络算法,并根据数据集特点,参照VGG-16模型设计了改进的模型,提出了一种基于迁移学习的卷积神经网络侧扫声呐沉船图像识别方法。试验结果表明,与全新学习和第2种迁移学习方法相比,基于第1种迁移学习方法的模型在训练效率以及识别的准确率上都有很大的提升,模型收敛更快,节省大量的时间和资源,测试识别准确率达到了93.71%,相比全新学习和第2种迁移学习方法分别提升了3.13%和9.22%;AP值最高为92.45%,分别比全新学习和第2种迁移学习方法高了3.06%和8.06%。验证了基于迁移学习的卷积神经网络识别方法的有效性,同时证明该方法理论上可以有效应用于侧扫声呐对海上失事船只的搜救,具有一定的实际指导意义。下一步的研究重点是如何在进一步提高模型的识别准确率的同时提高识别的效率。
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
北京航空航天大学学报(2021年9期)2021-11-02
海洋信息技术与应用(2020年3期)2020-08-24
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
小学科学(学生版)(2019年10期)2019-11-16
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
数学物理学报(2017年5期)2017-11-23
声学技术(2014年1期)2014-06-21
