
一种基于大数据的政务专业人员系统的数据治理研究
2021-03-08 02:05:18仲亮
新一代信息技术 2021年15期
仲 亮
(上海市组织人事信息技术服务中心,上海 200000)
0 引言
随着目前互联网技术和大数据技术的飞速发展,数据处理能力也在不断的提升,同时数据内容的治理工作也显得越来越重要。对于大城市而言,人员量大且流动性异常快速,所以为了保障城市的核心专业人员的全方位管理,需要对专业人员数据进行分析和评估,促进人员资源供需对接与人员资源的高效配置。同时,由于人员数量庞大,人员数据信息量也很大,数据处理也会变得异常复杂,而且处理完的数据还会存在许多问题,就需要不断改进训练数据处理模型和加强人工数据处理工作。为了保障城市专业人员的合理规划,系统通过对各层次人员数据的综合统筹,实现对人员总体情况、行业分布情况、区域分布情况的动态掌握,结合经济社会与产业发展有关要求,对人员分布的合理性、人员市场供需、行业人员缺口、区域人员缺口等进行动态分析和预计,更好地促进人员信息交换共享,促进人员资源高效配置。另外,需要对专业人员数据进行及时分析,了解相关专业人员的需求和具体情况,构建一套针对专业人员政策文件知识库,为人员政策制定发布提供一些建议方案,保障专业人员需求得到及时解决。对于专业人员数据处理,采用神经网络学习模式,对专业人员数据进行训练学习,建立相关数据分析标签库,并对其进行纵向的时间序列的分析,并建立相关的模型对其进行合理的宏观分析,帮助更好的进行人员管理和预测。
1 大数据政务专业人员系统总体架构
基于大数据的政务专业人员系统的数据治理在考虑到系统总体需求功能性和后期系统的拓展性、兼容性等方面,系统总体架构主要分为基础平台层、数据处理层、服务层和应用层。基础平
台层主要负责底层硬件资源处理调度,移动网络收发功能,安全信息加解密模块、运维保障模块、数据处理核心模块等基础功能模块。数据处理层主要是分为数据处理和数据分析两个核心模块,数据处理主要是负责对数据进行存储访问等处理数据功能,数据分析主要是对原数据进行分析处理,并将处理后的数据形成报表和视图数据。服务层主要是对外输出数据治理能力服务接口和相关数据信息能力接口,供上层直接进行调用。应用层主要是服务于用户的交互功能层,主要分为专业人员分类管理,专业人员政策指导,专业人员数据处理,区域专业人员分析,专业人员数据异常处理等等基本的操作。另外,为了更好地指导专业人员政策的制定,系统针对区域中的专业人员会进行宏观的数据分析能力,对专业人员行业分类、专业人员区域分布、产业分布情况和专业人员团队分析等方面进行数据分析处理,帮助人员政策实现分层、精准化和个性化,实现人员政策的辅助设计,为专业人员数据分析提供合理化的服务能力。具体专业人员宏观分析示意图,如图1所示。
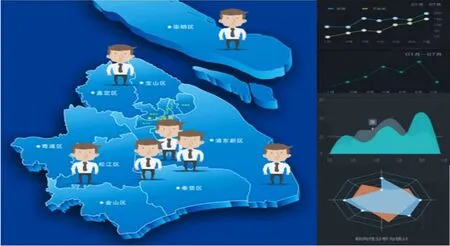
图1 专业人员宏观分析示意图Fig.1 professional macro analysis
2 大数据政务专业人员系统核心技术
本项目基于大数据的政务专业人员系统,主要对管辖区域中的专业人员进行合理分析和规划,利用大数据技术对相关专业人员信息进行采集、分析、学习,利用长短记忆神经网络(LSTM)训练构建出一套专业人员政策领域相关的知识图谱,最后还需要对分析得到的数据进行分析治理。
2.1 利用LSTM构建知识图谱
传统的神经网络进行训练学习,主要流程为输入层输入起始学习数据,学习得到的结果作为中间隐藏层的输入,层层往下,最终通过输出层输出学习的最终结果。LSTM 网络也是基于传统的神经网络进行演进而来的,由于传统的神经网络采用递归进行层层学习时,对于很长的序列,在学习时可能存在梯度消失这种情况,所以为了可以在很长的序列处理中拥有更好的效果,通过增加输入状态来优化学习流程。LSTM 网络内部主要有三个重要流程:(1)选择忘记流程,即对上层传入的输入值,选择忘记不重要的内容,但是对于重要的内容选择留下。(2)选择记忆流程,即对上层传入的输入值,对于重要的内容重点进行记忆,对于那些不重要的内容则少记一点。(3)输出流程,即决定最后选择哪些内容作为本层的内容向外输出。LSTM 模型结构图,如图2所示。
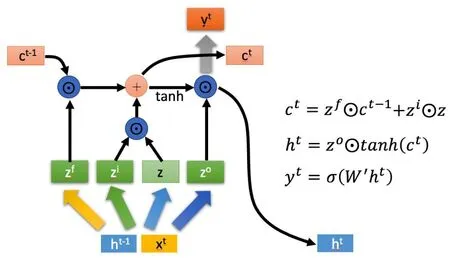
图2 LSTM模型结构图Fig.2 LSTM model structure diagram
2.2 自动化解读
利用机器学习技术进行非结构化文本识别解析,首先由相关领域内的专业人员对政策文本进行标注,形成原始标注文本,解读引擎将标注文本解读成结构化的数据,构建出一套数据样本库。机器学习引擎对样本库进行学习,训练成“识别模型”,然后,由识别引擎基于识别模型对政策文本进行自动化识别。在模型训练和识别引擎识别的过程中,必须有一个“领域知识库”作为支撑,才能对标准文本进行恰当的解释。另外为了提高训练和识别的精度,一方面领域知识库的知识越丰富、越精确,样本量越大,识别的精度越高。另一方面保证样本量充足,识别的精度也会得到提高,一般每一种标注的样本量要达到 50个以上,才能将识别精度提高到80%以上。识别模型的构造是一个持续的过程,首先是在完全人工标注的条件下进行训练。当识别模型具备一定识别能力后,就可以启动机器识别。为了提高识别引擎识别的精度,极大降低识别的歧义,需要保证政策解读的信息结构都是来自一系列的目标数据库结构,保证数据来源,最终才能产出根据领域语义构造的一个知识图谱。非结构化文本识别解析的技术框架图,如图3所示。
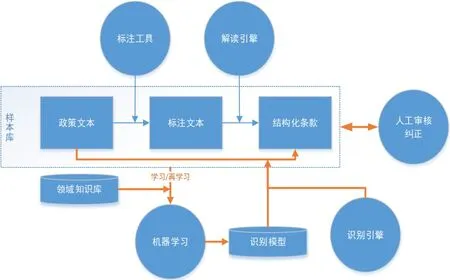
图3 非结构化文本识别解析的技术框架图Fig.3 technical framework diagram of unstructured text recognition and analysis
2.3 数据治理
由于人员信息数据来自不同系统的输入,会造成数据信息规范不同,以中文名为例,同一个人的英文名可能存在全拼、缩写,姓全拼名缩写、姓在前名在后和名在前姓在后等多种情况,这样在数据处理时,则会增加数据处理难度,提升识别难度,所以如何对采集来的数据进行准确的归属,保证这条信息是属于这个人,另外对于相似信息则归入人工处理池,等待人工进行处理。数据进行处理时,会给出一个相似阈值,当相似性达到一定阈值的,可以直接归入同一属主,相似性介于某一范围的,归入“疑似”同一属主,交给人工做合并处理。同时,对于已经入库的人员信息,进行相似性评价,疑似同一属主的信息,进行提示,由人工进行合并处理,新的人员信息进入系统时,要对其进行综合分析,然后与已有人员信息进行一一比对,形成相似性数据,对于疑似的情况,提示系统维护人员进行处理。另外,将各类数据质量不合格项予以规则化,通过规则执行引擎进行分析判断后,给出预警信息。在涉及干部人员的数据治理中一般可以分两个视角开展治理,一种是从干部人员、或者机构的角度出发,逐个处理;另一个是从规则特征的角度出发开展治理。数据治理示意图,如图4所示。
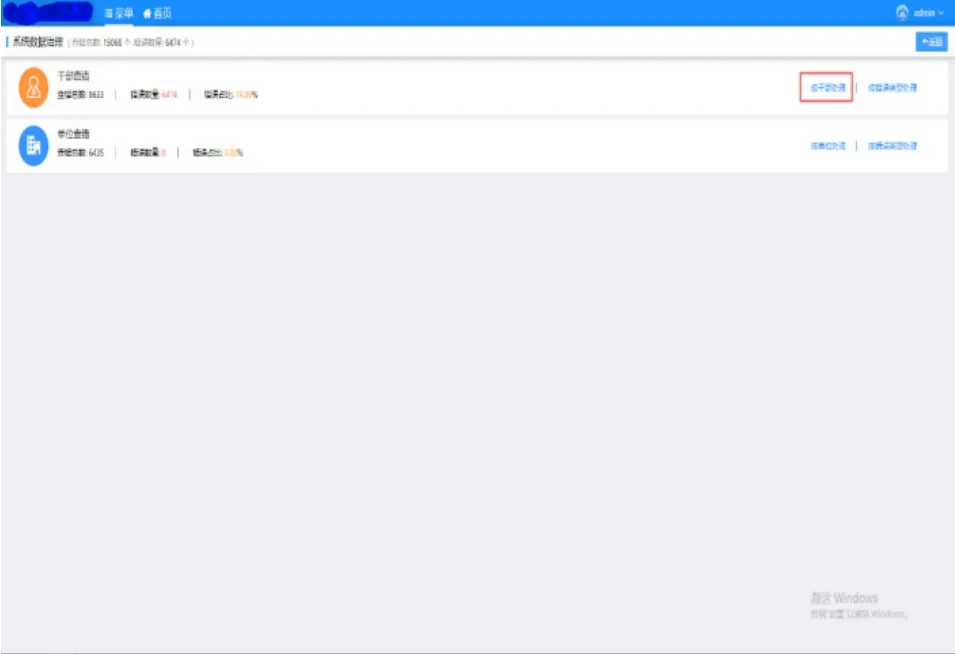
图4 数据治理示意图Fig.4 schematic diagram of data governance
3 大数据政务专业人员系统具体实践
为了更好的制定专业人员相关政策,需要系统的了解专业人员的相关信息,对专业人员进行量化评价。目前主流的针对科研人员和专家采用FWCI指数方法进行综合评价,对于金融、创业等行业也可制定类似于该方法的评价体系。主要由两个层面制定相关体系内容。第一个层面是先对行业或领域进行划分,针对每一个领域,研究制定能够反映人员的知识技能水平、实际贡献、社会影响力、发展前景等方面的综合性指标。初期的指标不要求非常严格、非常准确,具备一定的区分度即可。要随着大数据的发展、随着在人员评价工作中的实际运用,逐步改进,因此重点是指标体系设计要具备“可维护性”,即可以根据反馈情况,便于随时调整,并能方便地观察改进效果。第二个层面是对行业或领域的评价指标,进行标准化,或者“归一化”,实现对整个人员队伍中的每一个人,都可以采用一个标准进行衡量和评价。这个问题的合理性其实和单个领域内采用单一标准实现人员评价是一个道理。针对不同人员类别提供不同的评价指标体系,类别的设置可以交叉,也可以采用专门专才定制化规则。人员评价体系和评价工具图,如图5所示。
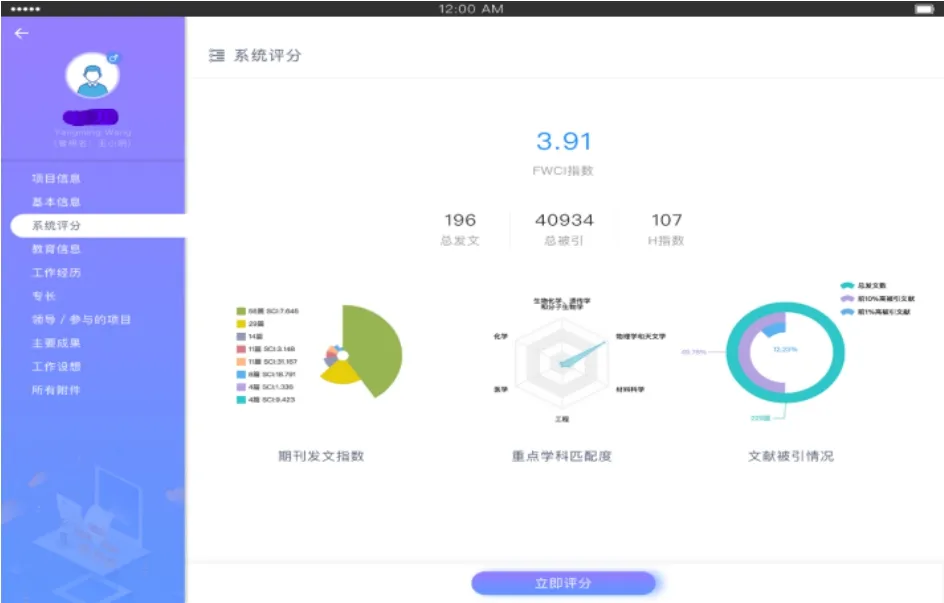
图5 人员评价体系和评价工具图Fig.5 diagram of personnel evaluation system and evaluation tools
为了精确的对区域内专业人员进行综合评估,需要对一个历史的时间跨度内,对各项指标进行全面的、动态的分析,以观察人员队伍在各方面的变化情况,预测变化趋势,对分析结果采用恰当的图表形式进行体现,以便更加直观地解释变化所反映的规律。目的是发现问题,寻找可调控的因素,为针对性提出改进措施,提供决策依据。对于专业人员流动性而言,可以充分利用位置系统的直观性,比如人员流动情况,既可以反映本市在全国范围内的流动情况,也可以反映本市范围内各地区、各行业之间的流动情况。针对专业人员流动性评估结果,制定相关专业人员政策,保证专业人员的留存率。人员流动情况图,如图6所示。
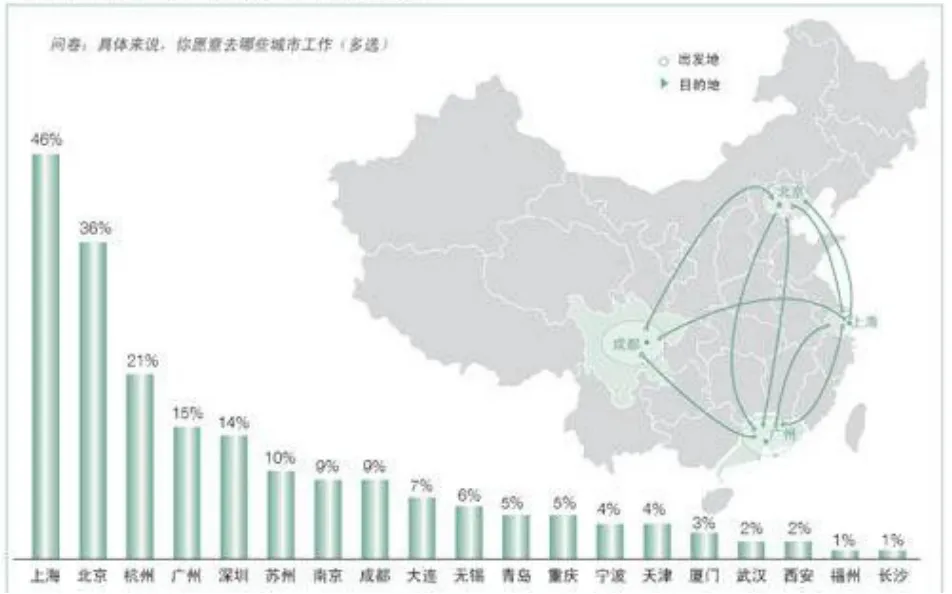
图6 人员流动情况图Fig.6 diagram of personnel flow
为了保障专业人员数据的精确性,对于大数据分析的数据结果,存在数据源异常和疑似池的数据,都需要人工进行审核,另外对于数据不存在的异常情况则需要后续进行人工补充,确保人员信息完整,便于后续管理。专业人员数据治理示意图,如图7所示。
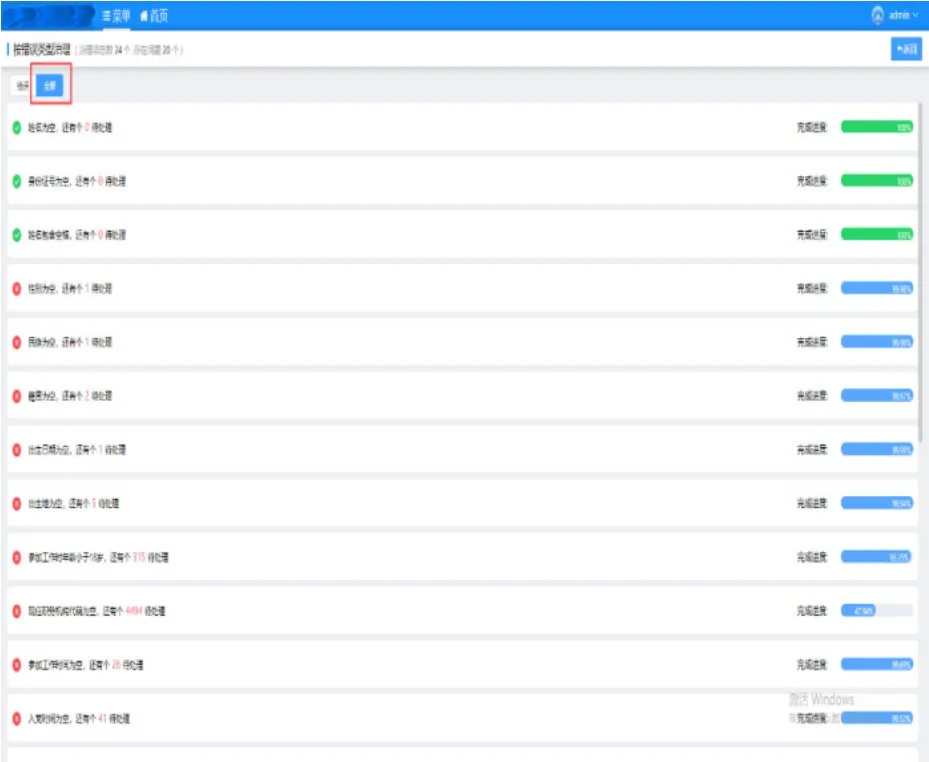
图7 专业人员数据治理示意图Fig.7 schematic diagram of professional data governance
4 结论
经过充分的调查和对大量资料的研究,本文分析了大数据政务专业人员系统的研究背景和现状,介绍了大数据政务专业人员系统的总体框架、关键技术、工作原理和设计思路,围绕着政务专业人员系统的实际需求,完成了政务专业人员系统的实现。文章先对大数据政务专业人员系统的总体架构进行研究,详细分析总体架构中的层级分布,分析每一层级的作用。接着讨论了大数据政务专业人员系统核心技术:LSTM 网络构建知识图谱功能,自动化解读非结构化文本功能,数据治理工作。最后,通过以上对大数据政务专业人员系统的核心架构的了解,分析了构建大数据政务专业人员系统的具体实践,并且给出了相关的人员评价体系和评价工具的具体实践思想,人员流动情况动态分析,专业人员数据异常治理具体实践思路。最后对建设过程中出现的问题进行了总结和改进。
猜你喜欢
工会博览(2024年8期)2024-03-31 03:53:14
心理学报(2022年4期)2022-04-12 07:38:02
水泵技术(2021年3期)2021-08-14 02:09:20
人民调解(2019年2期)2019-03-15 09:30:54
广东饲料(2016年5期)2016-12-01 03:43:19
广东饲料(2016年3期)2016-12-01 03:43:09
广东饲料(2016年2期)2016-12-01 03:43:04
广东饲料(2016年1期)2016-12-01 03:42:58
中国惯性技术学报(2015年1期)2015-12-19 13:12:17
中国卫生(2014年5期)2014-11-10 02:11:38
