
图谱报告PDF文件解析原理、示例与应用展望
2021-03-04 11:50刘羽,王辉,王贺
电脑知识与技术 2021年34期
刘羽,王辉,王贺





















摘要:目的:研究基于PDF文件解析的图谱数据提取方法,解决“数据孤岛”问题,实现数据的有效整合。方法:通过对PDF格式的图谱报告页面结构进行拆解、分析、归纳,逐步以示例展示PDF格式图谱文件的数据提取方法。一方面说明现有的PDF文本提取技术的原理,另一方面进一步研究对图谱曲线采用坐标变换进行还原以获得逼近原始数据真实值的数据的方法,并就处理后的图谱数据的应用方向进行了展望。结论:本文的研究结果表明,以PDF格式文件为媒介,可以将各类图谱报告的转化为自定义的数据,实现有效整合实验室资源,并为图谱报告的数据挖掘及AI应用创造条件。
关键词:PDF;图谱;Python;数据挖掘
中图分类号:R95 文献标识码:A
文章编号:1009-3044(2021)34-0134-07
1 引言
仪器分析是现代科学研究的重要手段,在研究中,通常会采用不同的方法(如液相色谱、气相色谱、质谱、核磁共振、热分析等)对同一目标从多角度进行研究,其产生的图谱直接或间接地反映出了被研究对象特定的物理化学性质[1-3]。这种研究策略在药学类的检验及研究领域极为常见。
现代分析仪器通常采用仪器+PC+工作软件/工作站的形式组成功能完整的系统:处理后的样品通过仪器上不同原理的传感器检测,获得模拟的电信号,经过模拟电信号/数字信号之间的转换,成为PC设备可以处理的二进制数据,再通过PC所搭载的工作软件/工作站中所包含相关函数的处理,得到可进行各类计算的图谱数据,并生成各类专属格式的数据文件,报告管理程序通过调用报告模板和图谱数据生成图谱报告。
商业化的工作软件或工作站通常因为工作目标、开发时间、编写语言的不同,形成了相对封闭的系统,其专有文件的数据结构无法被其他软件识别。
随着仪器分析及网络信息技术的发展,为了提高工作效率,面向数据整合与管理为目的的科学数据管理系统(SDMS:Scientific Data Management System)及由此拓展而开发的实验室信息管理系统(LIMS: Laboratory Information Management System)正逐渐普及[4-6],此类系统通常是由第三方开发的,与分析仪器的原生工作软件或工作站存在兼容性的问题,也无法直接使用专有格式的数据文件。
而各仪器厂商所推出的配套网络版数据管理系统仅对自有品牌的仪器进行支持,与其他品牌的仪器之间也存在兼容性问题。
大量的相关数据以不同的文件格式分布于各类的系统之中,形成了相互隔絕而又内容丰富的数据孤岛[7]。上述问题对数据的获取、集成与处理提出了挑战。
为了解决数据交换兼容性的问题,存在两种方案,一种是以许可授权的形式获得其他仪器企业的技术支持,从而获得接近原生仪器操作的用户体验。另一种是通过协调与推动通用文件的形式解决图谱数据交换的兼容性问题,例如从NetCDF发展而来的.cdf文件格式[8]。
但出于商业利益、技术壁垒、整合难度等因素,上述两个方案并没有得到广泛的支持。
2 PDF文件解析
2.1 PDF在实验室的应用
PDF文件作为独立于硬件、操作系统、应用程序的用于文件交换的电子文档,在实验室信息化的过程中得到了广泛的应用。报告管理程序通过PDF的虚拟打印功可以将各类图谱报告文件保存为统一的PDF格式。PDF以其便利性、高精度成为事实上的实验室报告传递通用文档。
在上述背景下,基于PDF文件解析的数据获取方案应运而生,对现有的第三方SDMS/LIMS进行功能改进和开发,通过对PDF这种通用的数据格式的图谱报告文件汇总、整理与解析实现对实验室检验数据的整合。与各类仪器厂商所提供的网络版工作站方案相比,该方案的优势在于:
1)技术难度低。利用现有的各类开源库和极少量的代码就可以实现对数据的抓取和管理。
2)投入少。在硬件上,不需要进行进一步的投入,例如增加专用的数据交换模块或是升级硬件以适配网络工作站的版本;在软件上,不需要购买网络工作站的授权;在管理上,可以采用一种方案适用于大多数应用场景,降低了开发和维护难度。
3)兼容性高。对于大多数不同类型,不同厂家,不同操作系统版本的仪器,能输出标准PDF格式的报告,具备局域网连接条件,就具备实施方案的可能性。
该方案的缺陷在于,目前只能对图谱报告中的结论性的部分文本信息进行抓取,不能够实现对图谱报告数据内容的充分利用。
2.2 PDF解析的基本原理
PDF格式其核心是由页面描述语言PostScript为基础发展而来的一种先进成像模块(Advanced Imaging Model ),可以以相对设备独立的方式描述影像,而不依赖特定设备特性为参照,避免了输出图像时对设备的依赖。可以实现高精度、高清晰度的图像输出。
作为一种特殊的文件格式,PDF文档并没有传统意义上的顺序数据结构。一个PDF文档是通过称为“对象”的模块组合而成。PDF的显著优势在于继承了PostScript语言的特点,通过页面描述指令在页面各个准确位置引用文件中的文本、图片、图形等对象实现内容展示。从这个意义上而言,PDF页面更类似于一种特殊的图片。
PDF其中各类对象的位置(position)、尺寸(size)、方向(orientation)的描述是通过建立页面坐标系实现[9]。
通过对PDF页面中各类对象的坐标系进行重建,可以获得相应的位置信息,通过对指定位置的对象属性信息进行解读就可以实现对图谱特定数据的获取。
2.3 图谱报告的形式和数据
常见的图谱报告可以归纳为三种基本形式:文本型、图型、图文混合型。如下图所示:
上述报告中的数据可以归纳为两类,一类为文本,一类为图形。因此通过解析图谱报告PDF文件其中的文本对象或图形对象就可以达到获得数据的目的。
2.4 图谱报告PDF文件的文本解析
PDF通过两种方式实现文本(Text)的应用展示:方式1,将字型(Glyph)以包括文本状态(Text state),文本對象和运算符(Text objects and operators),字体数据结构(Font data structures)组合的方式嵌入系统,作为文本对象与文件一同传输。这种文本应用的方式是以字符(Character)组合的形式保存字符串(String),以参数(parameters)的形式保存字体(Fonts),以字型(Glyph)方式进行页面描绘。
方式2, 对于特殊字型是采用矢量绘图的方式进行描绘。所展示出的字型不是以字符串和字体参数的形式保存,而是以绘图图形的形式保存。
通过上述两种方式可以最大程度还原版面的文字效果,实现打印页面的精确输出。而以方式1输出的PDF文件可以通过对文本对象进行对象属性分析获得对应的字符/字符串,经整理后而获得所需要的数据。
随着信息技术的发展,现有多种开源的软件可供选择,现以Pdfplumber为演示工具,以文本型报告实例为数据源,对文本数据抓取操作进行演示。
Pdfplumber是基于Pdfminer二次开发由Python语言编写的PDF文档解析库,尤其对 PDF文件中的表格内容进行了针对性的优化,使用方便。通过极少的代码就可以实现数据的读取。
以下是相关代码和解析效果示意图。
通过上述代码是通过默认的功能对PDF页面中的表格进行整体的识别和读取,并不具备对特定数据处理的功能。
通过变更解析模式,采用定位识别和读取导出的方式,就可以获得指定数据。示例采用导出到微软Office办公软件EXCEl中的方式进行演示:
以下为相关代码:
以下为代码运行结果:
在上述示例中,采用的是python语言编写的xlwings库作为数据导出工具,这是一种支持操作Excel文件的Python第三方库。同样的,通过引入支持数据库的应用工具也可以实现图谱指定数据抓取到数据库的功能。通过上述方法或类似方法就可以实现对图谱报告PDF文件的指定文本数据的抓取。
2.5 图谱报告PDF文件的图形解析
2.5.1 典型图谱的分解
图谱报告的PDF文件是通过一系列图形对象与文本对象的搭配实现图谱的输出。如下图所示:
通过将图谱进行归纳分析可知,典型图谱可以被归纳为两大类对象,文本对象及图形对象。
文本对象通常是对图谱的指示和说明,如样品信息,刻度单位,刻度值,这种文本说明可以便于图谱的使用者更有效的利用图谱。
图谱的图形是通过图形对象组合而来,其中的图形对象可以归纳为长方形、直线、曲线3类细分图形对象。例如作为整个图谱框架的长方形对象,描绘图谱的曲线对象,作为坐标轴和坐标刻度以及在某些情况下作为积分线的直线对象。
2.5.2 PDF文件中的路径对象与矢量图
PDF的显著优势在于继承了PostScript语言的特点,通过页面描述指令对指定区域进行着色绘制页面,可以通过路径描述的方式描绘出可以任意放大和缩小的矢量图。
常见的照片为位图,亦称为点阵图像或栅格图像,是由称作像素(图片元素)的单个点组成的。
而矢量图是通过数学公式计算获得,具有编辑后不失真的特点。微软Office办公软件EXCEl中通过表格数据所绘制的散点图就是通过矢量绘图的方式实现。
PDF文件中的矢量图通常是采用路径对象(Path Object)的形式实现,该类对象中又包含直线(Line),曲线(Curve)(含三次贝塞尔曲线(Cubic Bézier Curve)),长方形(Rectangle)等细分对象。这些路径对象包含一些绘图运算符(Painting operators)作为对象属性实现图像细节的描绘,如边框绘制(Stroke)或填充(Fill),其中还包括线形、宽度、颜色等细节参数。
矢量图是通过一系列的点通过线连接绘制而成。不同的点通过顺序组合描绘图形,点与点之间的先后顺序决定了图形的形状。各点之间连接的先后顺序发生改变,则相同坐标的点所组成的图形也会存在差异。
点是最基本的绘图元素。点的位置通过页面坐标的形式进行确定。对这些组成这些图形对象的路径点的解析就可以将所绘制的图形进行还原。
矢量图示例如图10所示。
通过采用Python语言编写的文档解析库Pdfminer作为演示工具,对上述矢量图形进行解析,通过对矢量图形(或称路径对象)的pts属性进行分析,可以获得生成矢量图的各点坐标,解析结果见图11。
其中的LTRect对应的是长方形对象;LTLine对应的是直线对象;LTCurve对应的是曲线对象。
由上述示例可知,示例1,3,5的规则图形和示例2,4的不规则图形都可以通过路径绘图的方式进行图形的输出,其路径点的坐标都可以被解析。
2.5.3 PDF页面的坐标系与对象框架
页面的绘图是基于PDF页面的坐标系进行页面定位。坐标决定了文本对象,图形对象,图片对象的位置(position)、方向(orientation)、尺寸(size)。通常采用的是以页面的左下角作为坐标系的原点(0,0),以横向的页面宽度和纵向的页面高度分别作为坐标系的纵向和横向坐标范围。
不同的对象根据页面排布情况依据相对原点的距离被赋予不同的坐标。可以采用x0,y0,x1,y1的数据赋值方式确定排布范围。其中 x0代表对象的左下角横坐标,y0代表对象的左下角纵坐标,其中 x1代表对象的右上角横坐标,y1代表对象的右上角纵坐标。
以(x0,y0)与(x1,y1)所定义出来的矩形范围即为对象的框架范围,框架作为对象的容器,决定对象的页面位置和的大小。各类对象都在框架中进行展示。
组成路径对象的路径点的坐标也是以上述坐标系为参照所设定获得。通过获得路径对象的坐标信息并加以整理就可以实现对图谱曲线数据的提取。
2.5.4 图谱的绝对坐标与相对坐标
对于图谱曲线的解析需要引入绝对坐标和相对坐标的概念。
绝对坐标指通过实验所获得的定位数据,这一定位方式所依据的是确定的实验数据之间一一匹配的关系,如X衍射法中的2θ角与衍射强度、液相气相等分离色谱测定法的保留时间与峰高、差热分析法中的温差和温度。
相对坐标指依据PDF页面的坐标系而获得的定位数据,是以对象所处页面位置通过算法折算获得的数据。随页面布局及排版的变化,其坐标也会发生相应的改变。
图谱曲线上,任意的绘图点在具有绝对坐标的同时,也存在对应的相对坐标。根据绝对坐标与相对坐标之间的这种一一匹配的关系,依据坐标变换的原理,寻找到坐标变换的规律就可以将数据从相对坐标转化为绝对坐标。
通过已知绝对坐标及对应相对坐标的两点就可以实现对其他任意已知绝对坐标或已知相对坐标的点与所对应的相对坐标或绝对坐标的变换[10]。
Xj1-Xj2=kh*(Xx1-Xx2)
Yj1-Yj2=kz*(Yx1-Yx2)
其中,Xj1,Xj2分别为已知的两点绝对坐标的横坐标,Xx1、Xx2分别为已知的两点相对坐标的横坐标。kh、kz分别为横坐标校正系数和纵坐标校正系数。
其中,Yj1,Yj2分别为已知的两点绝对坐标的纵坐标,Yx1、Yx2分别为已知的两点相对坐标的纵坐标。kh、kz分别为横坐标校正系数和纵坐标校正系数。
当任一点的相对坐标已知为(Xx0,Yx0),则可以通过已知条件进行推导,获得其绝对坐标(Xj0,Yj0)。
Xj0= kh*(Xx0-Xx1)+Xj1
Yj0= kZ*(Yx0-Yx1)+Yj1
通过上述的处理就可以实现将PDF文件页面上的图谱曲线的逼真还原。
2.6 图谱报告PDF文件的图形解析步骤示例
以常见的图文混合型图谱作为解析素材,通过PDF阅读软件福昕高级PDF编辑器及Python语言编写的Pdfminer库对图谱图形进行分析,步骤如下:
2.6.1 定位图谱图形位置
图谱一般是通过工作站或工作软件调用报告模板读取报告数据生成。在报告模板中对于图谱图形的调用,通常会存在图谱图形模块的框架。该框架在生成图谱PDF文件的过程中会以长方形对象的形式写入PDF页面中。在页面上通常表现为范围最大的长方形对象。
通过寻找这一范围框架,可以精确定位所需要提取分析的图谱曲线。这一范围框架的通常为整个页面上最大的长方形。通过筛选页面上符合这一条件的图形对象就可以得到。通过对这一范围的确定,可以提高分析效率。
2.6.2 图谱曲线初步分析
在本示例中,可通过PDF编辑软件对其进行初步的分析:图谱曲线是由三个曲线拼接组合而成,另有三条曲线以积分线的形式出现。
2.6.3 图谱曲线的进一步分析
对其中的一条曲线进行进一步分析,可得到下图:
明显可见曲线是通过顺序连接点串接构成。通过Pdfminer工具对该段曲线进行分析,读取该对象的.pts数据,可知组成该段曲线的点共计512个。
2.6.4 图谱曲线的特定点的分析示例
对曲线上的各点可进行进一步分析获得各点的位置信息,以上述图谱的峰位置为例:
通过筛选该段图谱曲线上的最高点,即纵坐标最大的点,就可以得知该点为512个绘图点中的第104个,坐标为(211.2,541.92)。
2.6.5 图谱曲线的特定点的绝对坐标与相对坐标
图谱曲线上,任意的绘图点在具有絕对坐标的同时,也存在对应的相对坐标。示例曲线所采用的是保留时间与峰高的匹配关系。以上述峰位置为例,其绝对坐标(4.101(保留时间),1273.69031(峰高))所对应的相对坐标为(211.2,541.92)。
这一绝对坐标在数据汇总表有相关的记录,可以通过对数据汇总表文本对象的解析获得。
通过获得两组或两组以上的绝对坐标/相对坐标的配对,就可以采用坐标变换的方法,推算曲线上其他已知相对坐标的点所对应的绝对坐标,从而完成对图谱曲线的解析。
2.6.6 坐标变换准确性评估
在所选择的演示图谱中有三个有记录的峰,按照坐标变换原理,可以通过已知绝对坐标及对应相对坐标的两点就可以实现对其他任意已知绝对坐标或已知相对坐标的点与所对应的相对坐标或绝对坐标的推算。
通过三点之间的相互推算,我们就可以得到实际坐标的理论值,通过理论值与实际值的差异来评估这个坐标变换的准确性。
通过对图谱的分析,可以获得示例中三个峰的绝对坐标和相对坐标的实际值。结果见表1:
通过三点之间的相互推导,我们就可以得到三个峰的绝对坐标和相对坐标的理论值。结果见表2:
通过计算获得理论值与实际值偏差(%)。结果见表3:
在表3 数据中,可以发现除一个点(峰3, 绝对坐标Y)外,其他点的偏差绝对值都在1%以下。这一情况是由于参与计算纵坐标校正系数kh的点之间纵坐标的差值过小导致。
通过比较可以得知,点(峰1,绝对坐标Y)与点(峰1,相对坐标Y)与同列的其他点相比偏差最小,而点(峰2,绝对坐标X)与点(峰2,相对坐标X)与同列的其他点相比偏差最小。
在计算横/纵坐标校正系数kh和kz时,参与计算的两点之间的坐标位置差异越大,则获得的偏差越小,相应的数据坐标变换越准确,还原度越高。
通过谨慎选择可以保证结果的准确性,上述方法进行坐标变换其偏差值在可接受范围内。
2.6.7 图谱曲线相关的文本信息分析示例:
可通过在图谱框架范围内进行文本对象分析获得文本的位置信息和内容信息。分析示例见图19:
文本对象的使用决定了其页面布局。根据其布局位置信息的规律性,可以识别并获得相关的文本内容信息。
此外,作为纵坐标/横坐标刻度标记的文本对象其中也包含有绝对坐标和相对坐标的信息,也可以用于计算横/纵坐标校正系数kh和kz。
在其中,由于峰标注采用的排版方式问题,其读取的内容信息存在一定的错误,这与进行文本对象分析时所采用的水平扫描方式有关,可通过进一步的优化加以改善。
2.6.8 图谱数据的输出
通过对上述图形对象和文本对象的解析,我们可以将原PDF文件中的图谱曲线分解为曲线坐标列表,积分线坐标列表,刻度标记及标注,样品信息等可归类的单独数据,可将这些解析出的数据汇总以自定义图谱的形式输出。所解析出的数据也可以供在Origin或者Excel中进行数据图谱的描绘。这将使得数据的使用及分析更加自由。
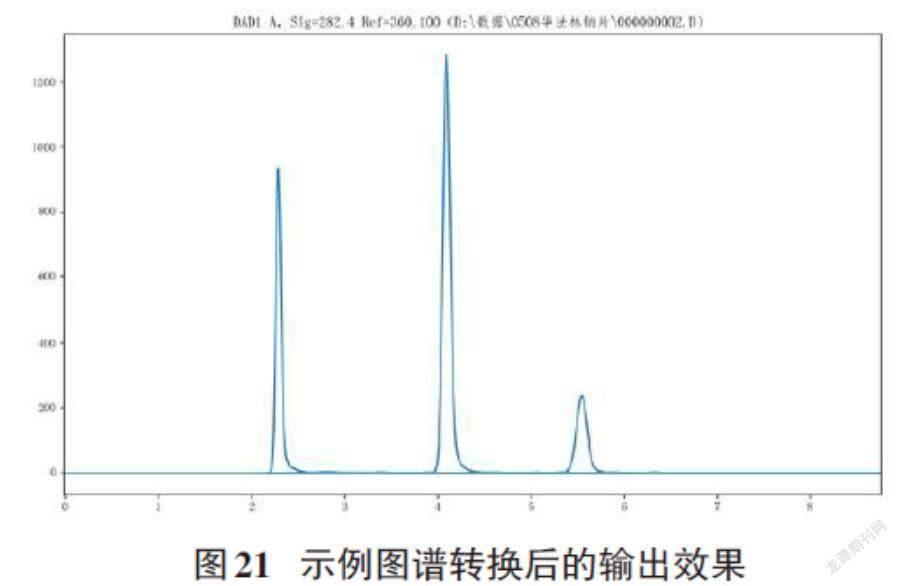
以下采用python语言编写的matplotlib库作为图谱的输出工具演示输出效果,实例可见图21:
所输出的显示效果与相关工作站软件所提供的离线浏览功能类似,可以通过鼠标移动获得曲线上的各位置信息,也可以放大、拖拉,可以更方便地解读图谱。
通过设定参数,也可以采用3D绘图的方式将原先的平面图形转换为可以拖动的3D图形进行分析。实例可见图22:
通过的编程处理,也可以将重叠图谱进行拆分、转换。实例可见图23、24。
3 应用与展望
本文所探讨的内容,是通过对PDF格式图谱文件的解析获得逼真的图谱数据,将各类私有数据格式转化为规范的、便于使用和交换的通用数据格式,为数据的进一步应用提供足够的便利性和自由度。使得图谱数据的分析可以不再受限于工作站和专用软件而困于一个个信息孤岛。通过与数据库的结合,为图谱数据的应用提供了新的发展方向。
在本文所述的研究中,对指定文本信息的提取技术较为成熟,已广泛应用于各类SDMS系统及由此拓展得到的LIMS系统,以Star-Lims较为典型,在药检所/院为代表的检验机构中多有采用。
而对于基于PDF文件的图谱图形数据提取的研究,鲜见相关文献的报道。而通过这一研究使得SDMS可以采集的pdf图谱文件的数据对象从数据汇总表中的检验数据文本对象扩大到图谱曲线图形对象,采集的数据更加全面。对可形成连续图谱曲线的实验报告(包括液相、气相、红外、紫外分光、差热分析)都可以通过此方法处理。
在图谱报告中,图谱曲线所蕴含的信息量要远多于数据汇总表中的记载,而这一研究可以提升图谱数据的利用效率。相比检验型的仪器分析,对于研究型的仪器分析,该项研究更具意义。
通过对报告功能的改进开发,采用该方案可以实现所输出的报告内容采用自定义的图谱曲线外观,使得报告整体风格更加的统一,而避免采用原始图谱附件的形式。可以满足实验室的出具报告、结果分析的基本需求。
通过数据库前端的进一步开发,就可以对图谱曲线数据进行检索、处理和比对,部分实现商业化仪器网络工作站的功能。这些功能的开发可根据自身情况,例如所采用的 LIMS编制语言、功能需求进行自行定制,在使用上具有更高的自由度。
仪器分析在中国的发展已经超过了20年。在使用单位的各类型仪器上都累积了大量的实验数据。以药检系统为例,每年各级药检机构的国抽、省抽任务及各类研究项目所涉及的检验数据量就非常可观。随着大数据研究及AI技术的日益进步,技术条件已成熟,对这些“沉睡”数据的有效使用必将促进研究的进一步发展。
作为辅助研究的有效工具,数据挖掘技术可将数据之中所蕴含的信息经过聚类分析、分类分析、相关性分析等手段应用于分析方法开发、风险趋势研究等方向,为将来的研究提供指导,从而提高研究的效率。
现有的累积数据也可以作为训练数据集应用于AI模型的开发,实现数据的自动判断和结果的自动输出,进一步提高工作效率。
规范的数据是实现上述应用远景的基础。以PDF文件为媒介,将各类私有数据格式转化为规范的,便于使用和交换的通用数据格式,可以实现跨仪器类型、跨生产厂家、跨研究机构的数据整合。这将使得针对数据研究可以在统一的资源环境下实施。
这种应用远景的配套条件也需要逐步完善,例如与图谱信息直接相关的样品信息、样品处理方法、检测条件、检测参数等图谱中不能完全反映的问题,也需要纳入对应的数据库中;此外还有数据来源合法性、数据交换规范、有效数据认可及机构间协作等事务性问题需要解决。
参考文献:
[1] 常周鑫,崔玉花,李洋洋,等.大型仪器检测无机非金属元素含量的研究[J].分析仪器,2021(5):59-65.
[2] 李蕾,黄鹏,阚家义,等.微量热法用于检出药品中污染金黄色葡萄球菌的可行性探讨[J].药物分析杂志,2021,41(2):300-305.
[3] 蒲婧哲,张亚中,朱夜琳,等.基于物种特异性PCR方法的鸡内金真伪鉴别[J].中国实验方剂学杂志,2019,25(17):142-147.
[4] 张玉歌,庞青云,郭洪祝,等.基于NuGenesis的仪器检测数据的科学管理[J].中国药事,2016,30(1):17-23.
[5] 林伟强.广东省药品检验所LIMS应用[J].今日药学,2008,18(4):88-90.
[6] 郑正,汪海宣,刘业飞.LIMS系统在食品药品检验检测机构中的实施[J].中小企业管理與科技(中旬刊),2017(7):139-140.
[7] Petter Moree.打破制药行业数据孤岛 实现数据完整性[J].流程工业,2020(4):46-47.
[8] ASTEM E1947-98(2014). Standard Specification for Analytical Data Interchange Protocol for Chromatograpgic Data[S].2014.
[9] PDF 32000-1:2008.Document management-Portable document format-Part 1[S].2008.
[10] 刘羽.基于PDF文件解析的图谱数据还原方法:CN112861821A[P].2021-05-28.
【通联编辑:李雅琪】
猜你喜欢
少先队活动(2020年12期)2021-01-14
中成药(2017年3期)2017-05-17
电力与能源(2017年6期)2017-05-14
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
杂草学报(2012年1期)2012-11-06
