
一种轻量级的处理器核性能分析框架*
2021-03-01 03:33雷国庆马驰远王永文
计算机工程与科学 2021年2期
雷国庆,马驰远,王永文,郑 重
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
通用微处理器作为信息系统的基石,其重要性不言而喻。近二十年来,国家大力支持国产中央处理器CPU(Central Processing Unit)研发,打造出了以飞腾、龙芯和申威等为代表的国产 CPU 品牌,开发了涵盖高性能计算、服务器、桌面终端和嵌入式等各个领域的 CPU 产品,并且在党政军地多个国产安全替代项目中批量应用,增强了国产化替代的信心。然而,现有的国产通用微处理器 CPU 也存在明显的不足,技术指标与国际先进水平差距仍然较大。以体现了 CPU 核心性能的 SPEC2006 基准测试为例,当前 Intel 主流CPU 的 SPEC2006 得分超过40分[1],而国产CPU的SPEC2006得分只有 15~20 分,这说明国产CPU的核心性能与 Intel 主流水平相比还有 3~5 倍的差距。为了提升国产CPU 的可用性,必须进一步提升 CPU 性能,缩短与国际主流 CPU 的差距。
为了提升处理器特别是处理器核的性能,需要从架构设计、性能建模、逻辑实现和性能分析等多个方面进行大量的工作。随着摩尔定律和 Dennard 缩放定律逐渐失效,单纯依靠先进工艺带来的性能提升越来越有限,架构设计在处理器中的作用越来越重要[2]。处理器架构特别是处理器微架构一般包含各种关键设计参数,如取指宽度、译码宽度、分派宽度、缓存大小(包括一级缓存、二级缓存、三级缓存等)、发射队列端口数、发射队列项数,执行部件数目和执行部件延迟等。为了获得优化的设计参数,工业界和学术界都十分重视使用模拟器来进行处理器性能建模和微架构设计空间探索[3]。然而,性能失准是模拟器建模存在的问题,为了更好地发挥模拟器的作用,需要在处理器的开发过程中不断地对模拟器进行性能校准和性能验证[4]。
模拟器主要用于架构探索和处理器的 RTL 设计完成之前的性能分析和软件开发。与模拟器相比,处理器的RTL模型准确度高,直接决定了最终芯片的实际性能,因此基于RTL模型进行性能分析是实际处理器设计中性能分析的重点。从处理器设计和实现的流程来看,处理器的设计和实现一般包括概要设计、详细设计、前端RTL 设计编码、功能验证、性能测试、RTL signoff、物理设计、流片、硅前和硅后测试等过程。在实际流程中,处理器的RTL性能验证在上述开发流程中处于中后期,并且在实际中一般以系统级的性能验证为主。如果在系统级验证中发现影响比较大的性能缺陷,则需要返回到前端修改RTL设计,设计修改较大时可能会导致重启所有的功能验证和性能验证流程,使得研制进度严重滞后。因此,在系统级性能验证之前,如何提前发现和快速定位 RTL 设计中引入的性能缺陷就显得十分重要。
为了及时发现RTL设计中引入的和预期不符的性能缺陷,本文提出了一种轻量级的基于RTL 仿真的处理器核性能分析框架,在处理器核的RTL 代码基本功能稳定以后,通过输入轻量级的裸机测试激励,即可基于该框架对新一代处理器核(New Core)的RTL设计实现的性能预期进行验证,从而在核级验证的早期及时发现性能设计缺陷。
2 相关工作
由于处理器的研制周期长,在处理器实际芯片生产完成之前,采用性能建模是处理器性能分析的一种重要方式。文献[5]针对超标量微处理器的结构特点,提出了适用于大数据集基准程序的性能分析模型 MAMO(Mircroprocessor Analytical MOdel),采用指令窗口模型、功能部件受限模型、分支误预测事件模型、指令和数据 Cache 失效模型等计算微处理器各个部件对程序CPI(Clock cycles Per Instruction,执行一条指令所需的平均时钟周期数)的贡献,从而估算处理器的实际性能。文献[6]提出了一种使用高级语言对硬件建模的方法,并进一步建立了一种更高层的性能模型 Sim-godson。除了建立了高级语言性能模型,还建立了相关的性能分析环境,包括 RTL 和 FPGA 仿真环境以及一些辅助的软件工具,主要用来验证高级语言模型。性能建模存在的问题是模型准确度和实际测试之间存在偏差。文献[5]对MAMO 模型和基准模拟器进行了对比校验,指出对于 SPEC CPU2000 定点程序使用该模型进行 CPI 估算的平均误差约为 8.53%。文献[3]对体系结构模拟器在处理器设计中的重要作用进行了论述,并且对性能模拟器的校准方法进行了总结。
文献[4]提出了一种单元级、核级和系统级整合的层次化的性能验证方法学,从多种层次识别和解决性能缺陷。在单元级建立了参数敏感的性能模型和覆盖率驱动的激励,在核级给出了面向实现的性能校准和基于 RTL 模拟的基准测试,系统级则建立了原型和基于计数器的性能分析。文献[7]给出了一种工具来对 Intel x86 指令的延迟、吞吐率和端口使用进行可信建模,从而为预测、解释和优化软件的性能提供依据。
性能测试和分析离不开测试程序,典型的来自真实应用的综合性能的基准测试程序包括 SPEC CPU2006、SPEC CPU2017和PARSEC等[8]。这些测试程序通常规模较大,运行时间较长,但是使用广泛。还有基于常用程序统计分析而设计的合成测试程序,如测试整数性能的 Dhrystone和CoreMark,测试浮点计算能力的 Whetstone 等。有的测试程序则是从科学计算中提取的核心循环代码,如用于测试矩阵操作的Linpack、测试浮点运算能力的 Livermoore 等[9]。除了基准测试程序以外,研究人员也会针对自己的需求开发特定的性能测试程序。比如 IBM 公司面向 PowerPC 处理器开发了 alpha、beta和gamma 等一系列测试程序,龙芯团队针对龙芯处理器性能分析开发了 Godson-Microbench 测试集,支持分支预测、部件资源利用率和计算延迟等分析[5]。
处理器性能建模需要从多种实现层次中对性能建模进行性能校准与分析,提升性能模型精度,从而为设计更高性能的处理器提供指导。与采用模拟建模并进行性能校准的方法不同,本文对处理器核性能提升研制中的基准处理器核(Base Core)和新一代处理器核2种处理器核 RTL 模型的性能进行对比分析,从而发现 New Core RTL设计实现中引入的性能缺陷。
3 性能分析总体框架
图 1 给出了基于 RTL 仿真的轻量级性能分析框架,该框架主要包括激励生成环境、模拟仿真环境和性能分析环境3个部分。其中激励生成环境负责生成用于性能测试分析的测试激励,包括生成测试程序源码和编译生成可执行二进制程序;模拟仿真环境用于对2种不同的处理器核执行模拟仿真,性能分析环境用于对仿真结果进行对比分析。
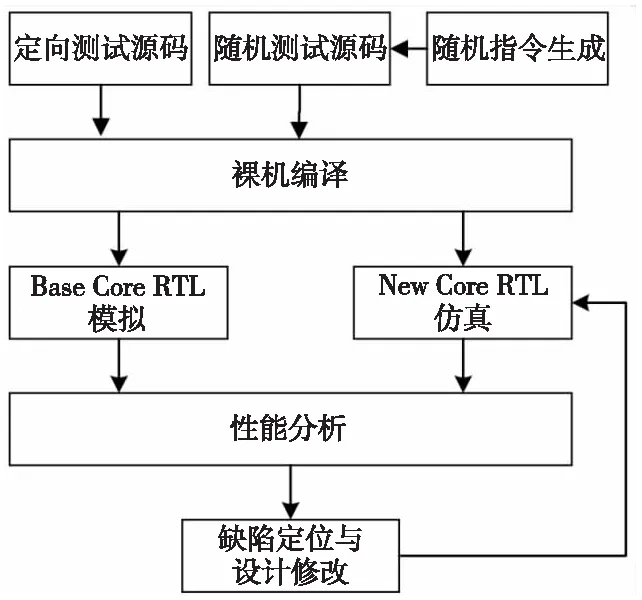
Figure 1 Overview of performance analysis framework
3.1 激励生成环境
测试激励类型包括定向测试激励和随机测试激励2种类型。定向测试激励是指针对特定的微架构性能敏感参数编写的特定测试程序。定向测试程序的标准以针对性能参数敏感为有效,具体可以采用手工编写汇编程序或者高级语言程序如C程序,也可以参考来自标准基准测试程序或者一些微基准测试程序来进行编制。随机测试激励主要是指根据指令模板采用随机数生成的方式对指令模板进行实例化,从而生成一系列随机汇编指令流。为了加速模拟速度,使用裸机编译环境对测试激励程序进行编译和链接,并生成可执行二进制文件。相比依赖于操作系统环境生成的可执行文件,裸机测试激励具有小巧、轻量的特点。裸机编译环境包括交叉编译环境、裸机环境下需要的基本函数库等。
图2给出了一种典型的测试激励程序框架,图2a中给出了该框架程序入口Main函数,Main函数首先对测试激励需要的地址和数据空间进行初始化;然后调用Test_kernel函数实现测试。图2b给出了Test_kernel函数的2种实现方式:一种是采用手工编写汇编代码的方式实现定向测试;另一种则为随机生成的汇编指令流。通过使用计时器Timer,实现对Test_kernel的执行时钟周期或者执行时间进行统计,用于对测试性能进行比较和分析。

Figure 2 Programming framework of test stimulus
3.2 模拟仿真环境
模拟仿真环境包括 RTL 仿真软件、Base Core 和 New Core 的 RTL 设计源代码、协同模拟验证环境、若干编译和运行脚本等。模拟仿真环境的输入是源代码文件和测试激励二进制文件,输出包括仿真波形文件、运行过程中产生的踪迹文件等。波形文件的作用是发现功能和性能缺陷时方便设计师进行调试和分析。踪迹文件则记录了处理器核执行的所有指令流信息。对于每条指令,踪迹文件需要记录该指令的 PC 地址、指令编码和汇编形式、指令分派和提交的时刻,以及指令读写寄存器操作数的结果。为了支持踪迹信息的打印,模拟仿真环境需要支持对处理器核关键模块信息的抓取。为了实时对计算结果进行验证,模拟仿真环境需要支持协同功能验证,能够将每条指令的计算结果和参考模型计算结果进行比较,如果结果计算错误,则退出仿真,打印相关错误信息,以便设计师调试和分析。
图3给出了处理器核仿真框架,该框架的顶层Testbench由Core和Memory实例化、设计协同仿真(Cosim env)、踪迹打印(Trace print env)和波形dump等几个模块构成,仿真环境还依赖于仿真工具(Simulation tools)和协同仿真库(Cosim lib)等。当仿真正常结束或者发现指令错误异常终止,设计协同仿真环境都会输出一个验证结果。为了加速仿真速度,实际过程中可以关闭协同仿真验证环境和采用并行仿真加速。如果开启了踪迹打印或者波形输出选项,仿真框架会生成模拟的踪迹文件或者波形文件,以供分析和调试。
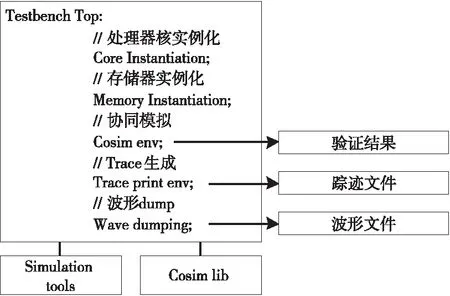
Figure 3 Simulation framework of processor core
3.3 性能分析环境
性能分析环境主要用于对Base Core 和 New Core 运行相同测试激励生成的踪迹文件进行信息提取和分析。对关注的指令执行时间区间进行分析,可以获得关注指令区间所有指令执行的总的时钟周期数,根据指令的条数,可以获得相关指令的延迟、指令的吞吐率和CPI 信息等指标。除了踪迹分析以外,性能分析环境还包括性能分析模块,用于设置性能事件并对性能进行辅助分析。根据 New Core 和Base Core 的一些指令延迟、吞吐率等对比数据,如果发现与性能预期不符的情况,则需要进行性能调试和缺陷定位,必要时要对RTL设计进行修改。基于本性能分析框架,从修改RTL设计完成到编译、运行、完成模拟仿真并获得分析结果的时间一般在 15 min以内,轻量级的性能分析框架使得进行快速的性能分析和设计迭代成为可能。
图4给出了指令吞吐率的计算方法,首先根据关注的时钟周期区间计算得到区间内时钟周期数,然后统计该区间内指令的条数,最后将指令条数除以时钟周期数可以近似得到该时钟周期区间内该指令的吞吐率。为了提升测试的准确度,关注的时钟周期内应尽量执行多条同类型的指令,并减少其它类型指令的执行。
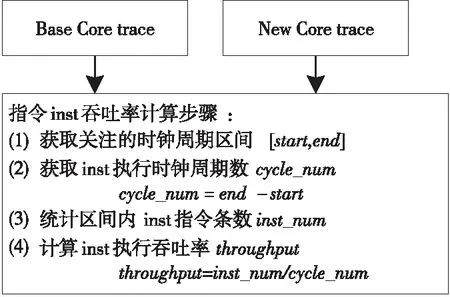
Figure 4 Computing method of instruction throughput
4 典型性能分析应用场景
基于表 1 给出的Base Core 和 New Core 的主要体系结构参数对比,结合本文所提出的性能分析框架,从Cache容量、指令延迟和吞吐率等方面对处理器核的性能进行分析。
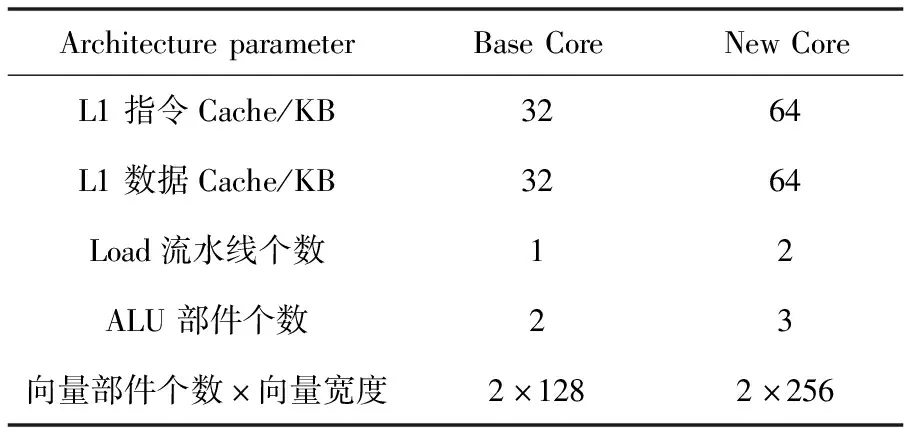
Table 1 Comparison of architecture parameters for Base Core and New Core
4.1 Cache容量扩展性能测试
根据表 1 给出的参数,和Base Core相比,New Core在L1指令Cache和数据Cache 容量方面均是Base Core的2倍。一般地,大容量的L1 Cache 在Cache 失效率方面将比小容量 Cache 要低,因此可以预期具有大容量 Cache 的New Core 在执行相同程序时的执行时间将比Base Core 要短。为此,本文提出了基于顺序指令执行和连续数据读取的测试方法来分别对 L1 指令Cache和数据 Cache 进行性能测试,测试方法分别如图 5a和图5b所示。当指令 Cache 和数据Cache 载入容量超过 32 KB 时,Base Core 将会出现Cache 失效,导致性能下降,New Core 的性能应高于 Base Core的。如果实际过程中发现,相比 Base Core 性能,New Core 性能相当或者下降,那么就有可能存在与 L1 Cache 相关的性能缺陷。
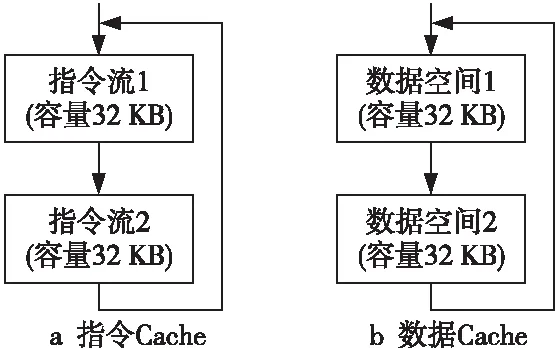
Figure 5 Performance test of L1 Cache volume extension
对于 L1 指令 Cache 和数据 Cache 容量测试,Base Core 和 New Core 分别同时循环多次执行 64 KB 容量大小的指令(每条指令大小为 4 B)和执行 64 KB 容量大小的数据载入操作,统计每次循环的执行周期数,并取平均进行比较。如图6所示为L1 Cache扩容性能测试加速比。当 L1 指令 Cache 容量从 32 KB 扩展到64 KB 时,执行图5a所示的指令测试流,New Core 的性能提升可以达到 7% 左右;而数据 Cache 容量从 32 KB 增加到64 KB时,执行图5b所示的数据load操作,New Core 的性能提升可达 50%左右(New Core有2条load流水线)。由此可见L1 Cache容量扩展带来的性能提升与预期总体上相符。
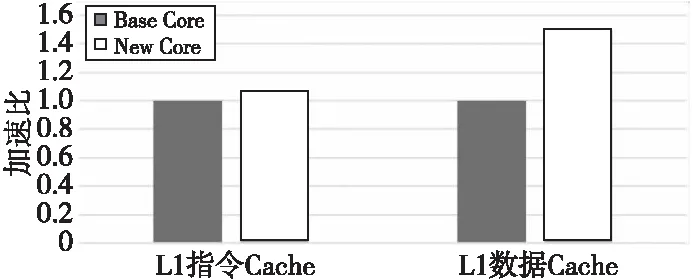
Figure 6 Performance test result of L1 Cache volume extension
4.2 指令延迟和吞吐率测试
指令延迟和吞吐率是处理器核性能的2种直观性能指标。通过减少执行部件的执行延迟和增加计算部件数量能够显著优化指令延迟和提升吞吐率。例如,为了提升整数指令的吞吐率,现代微处理器普遍采用添加 ALU 数量的方式来增强整数计算能力。对于不同指令的延迟和吞吐率的测试,可以编写定向或者通过随机指令生成的方式产生相关指令的测试激励,通过模拟结果分析得到踪迹中指令执行区间的时钟周期数和指令条数,进而计算得到指令的平均执行延迟和吞吐率等相关信息,从而对性能预期进行验证。
在表1中,相比Base Core,New Core增强了ALU和load部件的数目,ALU部件的个数从2个变为3个,load部件从1个变为2个。由此可知,ALU或者load相关指令理论上的最大吞吐率将为3或者2。基于这个基本的性能预期,利用本文提出的性能分析框架就可以对相关指令的吞吐率进行测试。特别地,双精度浮点乘加指令的吞吐率体现了单个处理器核的峰值浮点计算性能,为了测试峰值计算性能的可达性,可以构造全部由双精度浮点乘加指令构成的定向或者随机测试激励,统计从第1条乘加指令到最后1条指令完成的时钟周期数和乘加指令条数,从而可计算出乘加指令的实际吞吐率,通过对实际吞吐率进行测试就可以对浮点计算的峰值性能可达性进行测试。
实际测试中本文选取双精度乘加指令 FMLA 进行测试,测试结果如图7所示。随着 FMLA 指令执行条数的增加,FMLA 的吞吐率也随之增大,最终趋近于最大吞吐率 2。由此可知,通过测试FMLA的吞吐率,验证了浮点计算峰值性能的可达性。
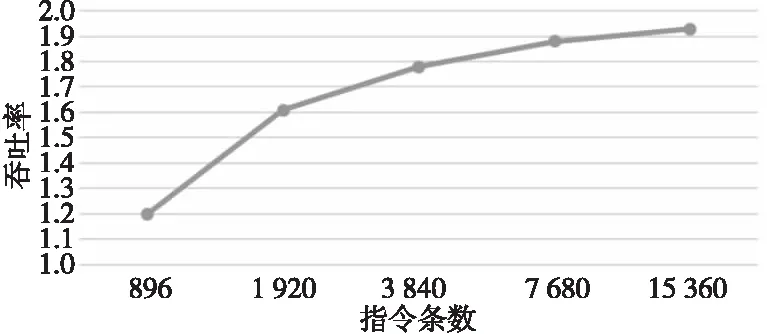
Figure 7 Throughput test result of FMLA instruction
5 结束语
本文针对处理器核性能提升研制过程中新一代处理器核RTL设计可能出现的性能缺陷,提出了一种基于RTL仿真的轻量级性能分析框架,并基于该框架给出了典型应用场景下的性能分析测试方法,从而在核级功能验证的初期快速发现RTL设计中可能引入的与预期不符的性能缺陷,有效加速了新一代高性能处理器核的研制进程。未来我们将继续对该框架进行完善,包括设计用于支持更多类型架构参数测试的测试激励,对性能预期进行量化,并设计支持多种类型的性能分析和结果展示等。
猜你喜欢
测控技术(2018年5期)2018-12-09
数字技术与应用(2018年4期)2018-08-18
电脑知识与技术(2017年5期)2017-04-08
数字通信世界(2016年11期)2016-11-29
电信科学(2016年10期)2016-11-23
中国高新技术企业(2015年24期)2015-06-25
科技传播(2015年20期)2015-03-25
电子设计工程(2015年12期)2015-02-27
汽车零部件(2014年1期)2014-09-21
西安航空学院学报(2014年5期)2014-07-13
