
基于BERT融合多模块的方面级情感分析
2021-03-01 08:59:42黄建民王雪绒李聪聪
井冈山大学学报(自然科学版) 2021年6期
黄建民,李 强,2,王雪绒,李聪聪
基于BERT融合多模块的方面级情感分析
黄建民1,*李 强1,2,王雪绒1,李聪聪1
(1.兰州财经大学信息工程学院,甘肃,兰州 730020;2.兰州财经大学电子商务综合重点实验室,甘肃,兰州 730020)
现有的BERT模型大多关注初始层到中间层的语法信息,而更高层的语义信息往往被忽略。由于判断句子情感是需要语义的,本研究在BERT模型的基础上加入并行聚合和层次聚合两个模块,分别用于方面抽取(AspectExtraction, AE)和方面情感分类(Aspect Sentiment Classification, ASC)。同时选择条件随机场(Conditional Random Fields,CRF)作为序列标记任务,从而提取到更多的语义信息。在SemEval 2014、SemEval 2016数据集上的实验结果显示,微调后的模型准确率和F1值均优于对比模型,证实了该模型的有效性。
BERT;序列标注;微调;情感分析
与句子级、篇章级情感分析任务[1-2]不同,方面级情感分析是一种细粒度情感分析任务,其目的是确定句子中目标的不同方面(也称“属性”,本文用“方面”表示)所表达的情感极性,其两个主要任务为方面抽取和方面情感分类。方面抽取任务的目标提取产品的特定方面,并在评论中表达一些情感。例如,在“There is a kettle on the table”这个句子中,kettle一词是被提取的方面。这个任务可以看作是一个序列标记任务,从三个字母集合{B, I, O}中给单词分配一个标签,序列中的每个单词可以是aspect term 的开始词(B),也可以属于aspect term之间 (I),或者不是aspect term (O)。方面情感分类是对某个对象的情感极性进行分类。任务描述可描述为给定一段文本 S = {w1, w2,…, wn},文本中包含 K 个 aspect terms(K ≥ 1),每个 aspect term = {wa_1, wa_2,…, wa_m} 都是文本 S 中连续的子序列。方面情感分类任务目标是预测某一个 aspect term 在文本 S 中的情感极性。
近年来,在自然语言处理中有大量的工作将BERT[3](Bidirectional Encoder Representations from Transformers)模型应用于文本分类[4]、问答系统[5]、摘要生成[6],特别是在方面级情感分析任务中。 BERT是当前语言建模中最先进的模型之一,BERT主模型由嵌入层、编码器、池化层构成。BERT模型首先通过预训练得到主模型的参数,当应用到下游任务时,就在主模型后接个跟下游任务配套的模块,然后将预训练的参数应用到主模型上,接着下游任务模块进行随机初始化,最后根据参数进行微调。Zhang等[7]在BERT 模型基础上引进语义角色标注模型,它以 BERT为基础骨架网络,融合上下文语义信息。该模型简单有效且易于理解。但是,角色标注器标注出的语料本身存在一定的错误,这对后续任务很不友好;同时该模型从外部注入相关信息,有可能使模型内部的效果与原始 BERT 相差不大,从而在一些特定任务上引发欠拟合。为了更好地利用BERT,一些研究将传统的ABSA任务视作句对分类任务。Sun等[8]设计了四种方法,为原始单句评论构造辅助句,从而构成“原始句-辅助句”的句对。对于有多个方面、多种情感极性的句子,往往可以为其构造多个辅助句,因此作者的方法也起到了数据增强的作用。作者在两个数据集上分别进行了方面抽取和情感极性预测的实验,证明了其方法的有效性。但是该方法的使用需要依赖任务语料良好的结构性,对于一些特定任务仍不能达到良好的效果。
目前许多下游任务的模型都是直接对BERT模型微调得到的。由于下游任务差异性较大,许多模型都没有特定任务的先验知识和缺乏对具体任务的适应性。为了提高模型的性能,Xu等[9]减少了由于预训练大规模语料带来的偏差,并且融合具体领域的知识,提出了一个具有一般性的post-training策略来考虑领域知识和任务性质模型(BERT-PT),实验结果表明该模型性能在方面抽取和方面情感分类任务中都得到较大的提升。由于BERT模型的特殊体系结构,可以在其之上附加额外的模块,Li 等[10-13]通过添加RNN和CRF层,以端到端方式执行情感分析,最终也提升了F1值,其中心思想为采用预训练和微调方式进行,达到是优化下游任务效果的目的。
受以上研究方法启发,通过在BERT上加入并行聚合和层次聚合两个模块,分别应用于方面抽取和方面情感分类任务,以此获得高层次的语义信息。为了获取更多的语义信息,选择条件随机场(CRFs)作为序列标记任务,并使用隐藏层进行预测。在SemEval 2014数据集上的实验结果显示,微调后的模型准确率和F1值均优于对比模型,证实了模型的有效性。
1 模型
深度模型的隐藏层可以更多的用来提取特定区域的信息。我们在BERT的基础上加入了两个模块:并行聚合(BERT-P)和层次聚合(BERT-H),分别用于方面抽取和方面情感分类。模型结构如图1、图2所示。
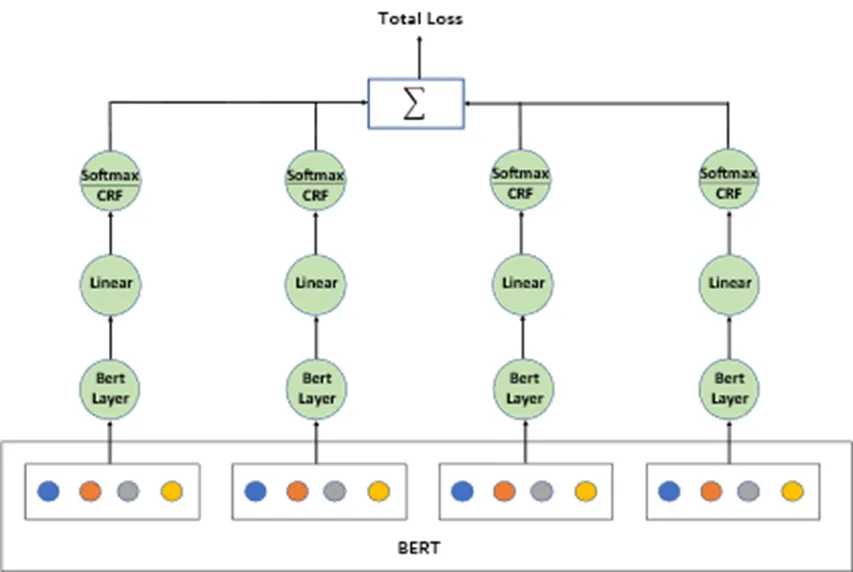
图1 BERT-P模型结构框架
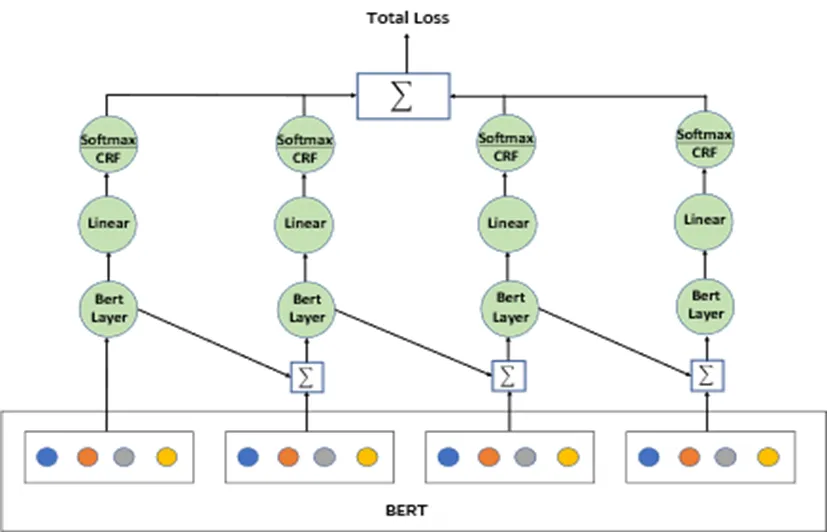
图2 BERT-H模型结构框架
BERT-P模型应用于方面抽取任务。BERT-P模型在BERT的基础上添加一个额外的BERT层,BERT最后四层的每一层都对额外层进行预测,从而得到更深层次的语义信息。将每层学习到的语义信息经过聚合后接入Softmax函数得到概率分布,最后将这些得到的语义信息组合可以产生更丰富的语义表示。
BERT-H模型应用于方面情感分类任务。两个模型原则上是相似的,但在实现上略有不同。差异点在于BERT-H模型最后四层在对隐藏层预测后还需要在另外输出支路进行预测,然后将损失累加。这是因为在方面情感极性的判断中,需要计算出支路语义信息对抽取方面的权重,保证所抽取信息是特定抽取方面所需要的。
在机器学习中有许多损失函数可以用,例如欧氏距离,sigmoid函数,softmax函数等。对于方面情感分类任务,为了模型在训练数据上学到的预测数据分布与真实数据分布越相近,采用了交叉熵损失函数,其计算公式为:
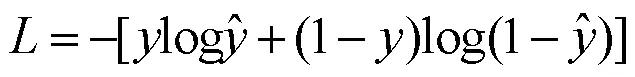
对于方面抽取任务,考虑到序列中之前的标签是非常重要的,本文采用CRF作为损失函数。CRF是随机场的一种,与其他随机场不同,条件随机域可以增加细粒度的特征,从而可以应用在后续自然语言处理任务中。序列标记中各标签联合概率的公式为:



其中是定义在边上的特征函数,称为转移特征,依赖于前一个和当前位置;是定义在节点上的特征函数,称为状态特征,只依赖于当前位置;,是对应的权重。和都依赖于位置,所以都是局部特征,通常取值为0或者1,满足特征函数取值1,不满足取值0。序列词之间关系可以很强,也可以很弱,或者根本不存在,其完全由特征函数和权值决定。
CRF层可将方面抽取任务视为序列标记,有助于保存句子中各方面之间的位置关系,从而丰富语义信息,CRF预测句子结构如图3所示。
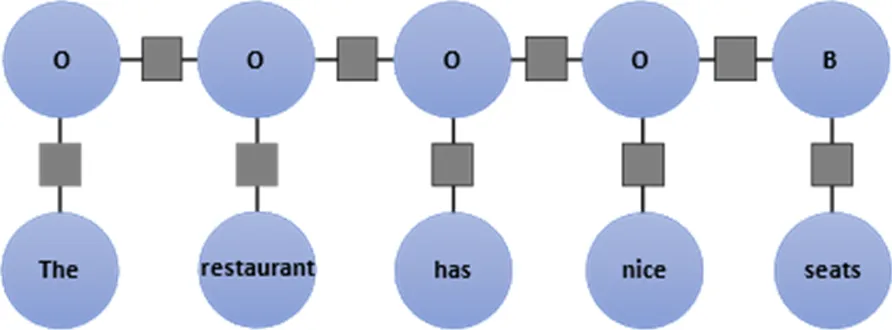
图3 用CRF预测句子
方面抽取任务可以看做一个序列标记任务[11]。将CRF层作为模型最后一层可以得到训练数据中的约束性的规则,确保最终预测结果是合法的,从而降低序列标记中非法序列出现的概率,提高模型预测准确率。
2 实验和结果
2.1 实验数据集
本设计在国际语义评测大会提供的SemEval 2014和SemEval 2016数据集上验证模型有效性。分别采用SemEval 2014中的Laptop数据集和SemEval 2016中的Restaurant数据集进行方面抽取任务,数据集训练、测试样本划分情况如表1所列。采用SemEval 2014中的Laptop和Restaurant评论数据集进行文本的方面的情感分析,数据集训练、测试样本划分情况如表2所列。

表1 用于AE任务的数据划分

表2 用于ASC任务的数据划分
本实验环境硬件方面相关配置信息为:Ubuntu18.04系统、i7-7500 CPU、GTX2060Ti显卡、16G内存;软件环境方面,使用Python编程语言及Pytorch深度学习框架进行相关模型构建。
2.2 评价指标
准确率Accuracy是反映模型预测正确数量所占总量的比例,使用准确率Accuracy和F1值来验证模型性能优劣。由于查准率和查全率仅能反映相关应用的倾向于某方面的重要性程度,F1值则是查准率和查全率调和平均数,能更好地反映出模型预测性能。

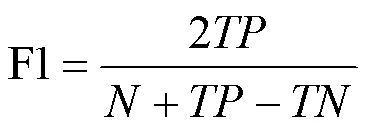
其中,为真正例样本数,为真负例样本数,是数据集样本总数。
2.3 实验参数设置
为使得模型达到最优的预测效果,对模型实验参数进行设置。模型的输入为“[CLS]”+上文词+方面词+下文词+“[SEP]”+方面词+“[SEP]”。使用基于梯度下降算法的Adam优化器进行模型的相关训练,学习速率为3e−5,batch_size=4,epoches=30,同时从训练数据中选取12个例子作为验证数据。为保证评估模型有效,所有模型在同一环境下运行。
2.4 实验及结果分析
首先采用SemEval 2014中Laptop数据集探究BERT模型的每一层在ASC任务中的表现。
从图4中可以看到,随着层次的加深,模型的准确率越高。因此,将并行聚合模块和层次聚合模块添加到模型的最后四层上以获得更优性能。不同模型实验结果数据如表3所示。
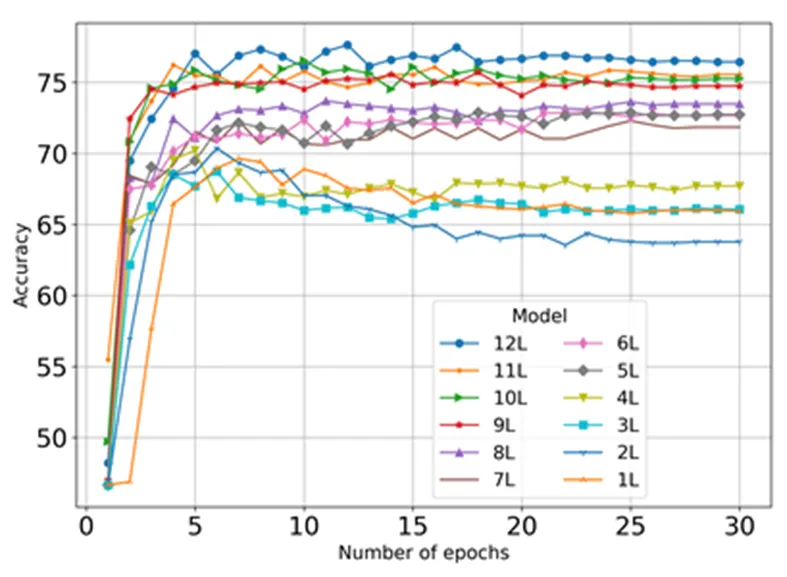
图4 BERT模型不同层数训练结果
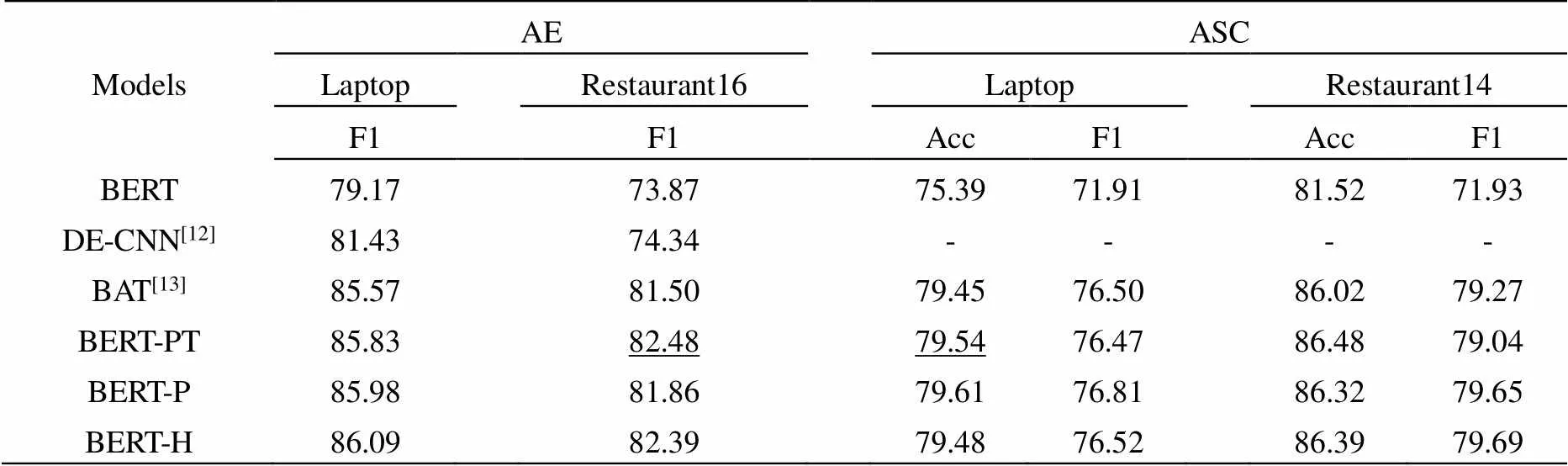
表3 不同模型实验对比结果
从表3可以看出,BERT-P和BERT-H模型不论是在AE任务还是在ASC任务中比BERT模型都有了较大幅度的提升。在AE任务中,BERT-H模型在Laptop数据集中的F1值比次优模型BERT-PT还高了0.26,但是在Restaurant16数据集比最优的BERT-PT上低了0.09,产生这结果的主要原因是这是因为Restaurant16数据集上句子的语法信息比较复杂,本模型未能够很好的获取文本特征,导致实验效果差点。在ASC任务中,两个模型在两个数据集中的F1值均比次优模型BERT-PT要高。而在准确率方面,BERT-PT模型在两个数据集的表现却要比本文模型高一点。总体来看,研究设计采用的BERT-P和BERT-H模型在数据集上的表现效果好,证明了模型的有效性。
3 总结
考虑到BERT高层所表达的丰富的语义信息,在BERT模型上进行微调,融合了并行聚合和层次聚合两个模块、应用到方面级情感分析的下游任务中。一次以并行方式聚合用于方面抽取任务,一次按层次结构聚合应用于层次聚合,微调模型对每个隐藏层进行预测再联合计算损失值。最后采用CRF层作为最终最后一层,对处理好的数据进行规制约束,进一步提高模型性能。实验结果表明,本研究提出的方法对于预测准率有较为明显的提升。
[1] Peng H, Cambria E, Zou X. Radical-based hierarchical embeddings for chinese sentiment analysis at sentence level[C]. Proceedings of the 13th International Florida Aritificial Intelligence Research Society Conference, California America:AAAI,2017:347-352.
[2] Mishara C, Abhijit M, Kuntal D, et al. Learning cognitive features from gaze data for sentiment and sarcasm classification using convolutional neural network[C]. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics,Vancouver, Canada:ACL, 2017:377-387.
[3] Devlin J,Chang M W,Lee K,et al. BERT:Pre-training of Deep Bidirectional Transformers for Language Understanding[J].NAACL-HLT, 2018:395-407.
[4] 王思丽,杨恒,祝忠明,等.基于BERT的领域本体分类关系自动识别研究[J].情报科学,2021,39(7):75-82.
[5] 武钰智,常俊豪.基于BERT的民事相关问答问句分类[J].电脑知识与技术,2021,17(1):4-7.
[6] 谭金源,刁宇峰,祁瑞华,等.基于BERT-PGN模型的中文新闻文本自动摘要生成[J].计算机应用,2021,41(1):127-132.
[7] Zhang Z, Wu Y, Zhao H, et al. Semantics-aware BERT for language understanding[C]. Association for the Advance of Artificial Intelligence, New York America: AAAI, 2020:9628-9635.
[8] Sun C, Huang L Y, Qiu X P.Utilizingbert for aspect-based sentiment analysis via constructing auxiliary sentence[J].NAACL-HLT,2019:380-385.
[9] Xu H, Liu B, Shu L, et al. BERT Post-Training for Review Reading Comprehension and Aspect-based Sentiment Analysis[J].NAACL-HLT,2019:2324-2335.
[10] Li X , Bing L D , Zhang W X, et al. Exploiting bert for end-to-end aspect-based sentiment analysis[C]. Proceedings of the 5th Workshop on Noisy User-generated Text.Hong Kong China:EMNLP, 2019:34-41.
[11] Zeng X,Zeng D, He S, et al. Extracting Relational Facts by an End-to-End Neural Model with Copy Mechanism[C]. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers).Melbourne Australia, ACL,2018: 506-514.
[12] Xu H, Liu B, Shu L, et al. Double Embeddings and CNN-based Sequence Labeling for Aspect Extraction[C]. Meeting of the Association for Computational Linguistics. Melbourne, Australia:ACL,2018:592-598.
[13] KarimiA,Rossi L, Prati A , et al. Adversarial Training for Aspect-Based Sentiment Analysis with BERT[J].ICPR , 2020:8797-8803.
ASPECT-LEVEL SENTIMENT ANALYSIS BASED ON BERT FUSION MULTI-MODULE
HUANG Jian-min1,*LI Qiang1,2, WANG Xue-rong1, LI Cong-cong1
(1. School of Information Engineering, Lanzhou University of Finance and Economics, Lanzhou, Gansu 730020, China; 2. Key Laboratory of Electronic Commerce, Lanzhou University of Finance and Economics, Lanzhou, Gansu 730020, China)
The existing BERT models mostly focus on the syntactic information from the initial layer to the middle layer, while the higher level semantic information is often ignored. Because of the semantics requirement in judging sentence emotion, two modules as parallel aggregation and hierarchical aggregation were added on the basis of BERT model, which were applied in Aspect Extraction (AE) and Aspect Sentiment Classification (ASC), respectively. At the same time, Conditional Random Fields (CRF) was selected as sequence marking task to extract more semantic information. Experimental results on SemEval 2014 and SemEval 2016 data sets showed that the accuracy and F1 values of the proposed model were better than those of the comparison model, which confirmed the validity of the proposed model.
BERT; sequence annotation; fine-tuning; emotion analysis
1674-8085(2021)06-0064-05
TQ324.3
A
10.3669/j.issn.1674-8085.2021.06.012
2021-09-15;
2021-10-16
甘肃省自然科学基金项目(17JR5RA177)
黄建民(1997-),男,江西赣州人,硕士生,主要从事自然语言处理研究(E-mail:Huangjm97@163.com);
*李 强(1973-),男,甘肃兰州人,教授,硕士,主要从事电子商务数据挖掘,机器学习研究(E-mail:18794809280@163.com);
王雪绒(1997-),女,甘肃白银人,硕士生,主要从事情感分析方面的研究(E-mail:cjdxsys506@163.com);
李聪聪(1996-),女,陕西咸阳人,硕士生,主要从事机器学习研究(E-mail:lcc1017416868@163.com)。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
成都信息工程大学学报(2022年3期)2022-07-21 09:35:30
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01 06:27:42
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
开放教育研究(2020年2期)2020-03-31 01:54:14
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
现代语文(2016年21期)2016-05-25 13:13:44
文理导航·教育研究与实践(2015年12期)2015-12-04 00:49:23
大连民族大学学报(2015年2期)2015-02-27 08:28:11
