
一种高效的基于互学习的在线蒸馏系统
2021-02-28 07:27安徽理工大学
电子世界 2021年23期
安徽理工大学 胡 干
安徽理工大学 安徽理工大学环境友好材料与职业健康研究院(芜湖) 梁兴柱
蒸馏是一种让较少参数的学生模型学习大型教师模型知识的有效方法,然而这样高性能的教师模型往往很难获得。因此,一些研究人员提出了一种让每个学生模型相互学习的策略,以取代传统的师生学习范式。虽然这种方法最近取得了良好的效果,但学生网络之间的相互学习很容易提前达到饱和。故此提出了一种基于互学习的在线蒸馏系统(MLS)用于在线知识蒸馏,该系统为每个学生模型提出了一个权重评估机制(LFS)和一个虚拟教师。虚拟教师是通过计算得到的权重结合学生网络的输出来构建的,这样学生就可以在下一阶段从表现更好的同伴网络那里学到更多知识。通过将所提出的方法应用于三个公共数据集CIFAR10、CIFAR100和Tiny-ImageNet,实验结果表明,本文模型是有效的,可行的。
深度神经网络近几年在解决一些问题时展现了它的优越性,性能强的大型模型往往运行缓慢、笨重并且占据大量内存,这限制了神经网络在移动端的应用。为了解决这一问题,很多方法被提出,比如二值化,剪枝,轻量化模型设计以及知识蒸馏等等。知识蒸馏是一种两阶段模型压缩方法,一般步骤为预先训练一个功能强大的教师模型,然后将处理过的教师知识传递给学生模型。但是现实生活中往往得不到教师网络,所以基于互学习的在线蒸馏方法被提出。该方法通过多个学生网络之间的相互学习从而逼近甚至超过教师模型的精确度,并且分为基于子网络和基于子分支两种形式。在以前的大多数研究中,忽略了子模型之间的差异性,即使是同一种网络结构性能也有所不同。一些研究证明,将多模型系统中的子模型区别对待,并且利用其在训练过程中表现出的差异性指导学习能提高模型的泛化性。在此研究基础上,本文提出了一种改进的基于互学习的在线蒸馏系统(MLS),通过学生网络间的相互学习替代了预训练的教师网络,并且通过自定义的权重评估机制(LFS)利用学生网络之间的差异性指导训练。最后,本文在一些常规数据集上证明了本方法的高效性。
1 传统的知识蒸馏
知识蒸馏(KD)是指在强大的教师网络的监督下对学生网络进行训练,并使用KL散度来拟合教师和学生之间的软化输出。假设有一个分类任务需要处理,则知识蒸馏的总损失为:
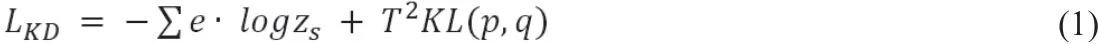
其中e是标注的标签分布,zs是学生模型最后一层输出经过softmax分类层之后的结果。其中p和q表示学生网络和教师网络产生的软化概率分布,T为温度参数。然后记zt作为老师最后一层的输出。软化概率分布p = softmax(zt/T)以及q=softmax(zs/T)。
2 改进的基于互学习的在线蒸馏系统
传统的知识蒸馏分两阶段进行,需要提前训练一个教师模型,教师模型往往很难获得。本文使用在线蒸馏代替教师-学生蒸馏模式,并且利用学生网络之间的差异性指导训练。如图1所示,MLS是一个新型的基于互学习的在线蒸馏系统,通过评估每个模型来指导模型训练。LFS是在学习过程中根据模型的性能进行动态评价的关键模块。学生网络产生的输出被LFS产生的权重加权,形成一个虚拟教师,然后学生通过标准的蒸馏从虚拟教师那里学习。为了便于表示,将所有子模型的标记为1到m。
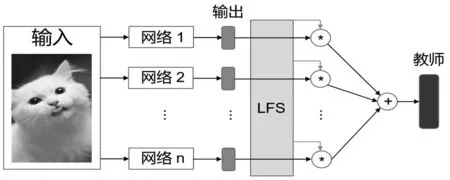
图1 MLS系统结构示意图
2.1 蒸馏系统目标函数
虚拟教师(Virtual teacher)是在学习过程中动态生成的,由LFS模块产生的权重和不同子模型的输出组成:

其中Vi,n是第i个周期第n个batch虚拟教师的值,αa,i,n是第a个子模型在第i个周期第n个batch由LFS模块评估产生的权重,za,i,n是第a个模型在此时的输出。LFS模块的内部运行细节会在后面给出,则整个在线蒸馏系统的总目标函数为:
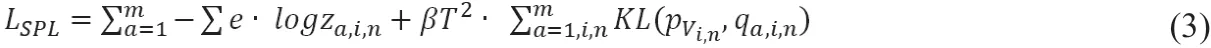
其中β是调节软硬标签的超参数,是虚拟教师软化后的值,是第a个模型在第i个周期第n个batch经过软化后的值。
2.2 LFS模块
LFS模块是本文提出的在线蒸馏系统中的关键组成部分,它的作用是根据各个子模型在当前训练阶段所表现出的性能给出权重,表现越好的模型权重越高,然后以此组成虚拟教师。LFS模块在上一个周期结束时会根据模型在测试集的表现给出子权重ba,i-1,然后再结合当前周期上一个batch上的表现给出子权重ca,i,n-1,并按照一定的比例进行加权求和得到当前batch最终权重αa,i,n。
综上所述,LFS的总权重计算公式为:
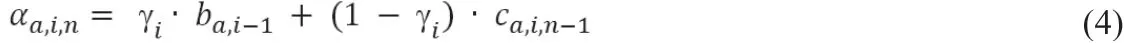
其中ba,i-1与ca,i,n-1分别为LFS在测试集以及训练集上计算而得的子权重。γi是一个随训练进行而自动调节的超参数,在实验前半段调高测试集的比重,后半段缓慢提升训练集的比重从而在各个子模型之间传递更多知识,提高模型的泛化性。ba,i-1与ca,i,n-1是测试集和训练集上各个子模型的准确率通过softmax函数计算后得到的值。
2.3 MLS的运行过程
MLS的运行过程如表1所示,其中ca,i,n-1是由训练集上的各个子模型准确率通过softmax函数计算所得,ba,i-1是由上一周期结束时测试集上的准确率计算所得。

表1 MLS的运行过程
3 实验结果及分析
3.1 实验准备
本部分将在三个数据集(CIFAR-10/CIFAR-100以及Tiny-ImageNet)上证明所提出的MLS的高效性,所采取的骨干网络包括VGG-16,ResNet-110以及MobileNet-V1三种。实验数据中m设置为3,为250,T和分别为3和0.7。选取SGD为优化器,学习率初始为0.1并且每80周期减少为原来的十分之一。实验在CIFAR数据集上的batchsize设置为256,在Tiny-ImageNet上为512。
3.2 实验结果分析
由表2和表3可知,MLS在CIFAR10上较两种基础网络性能提升了约15%到24%,在CIFAR100上为5%到8%。这可以证明本文提出的MLS在线蒸馏系统适用于当前主流的骨干网络并且得到良好分类性能的网络。具体来说,MLS与其它已有的先进算法相比,在CIFAR10上性能提升了大约8%,在CIFAR100上为3%。当面对更加复杂的Tiny-ImageNet数据集时,MLS仍然相对于DML有8%的性能提升,这更一步证明了MLS的高效性。实验结果表明,利用差异性指导模型的训练能传递更多的知识从而提高模型的泛化性,训练更加高效的模型。
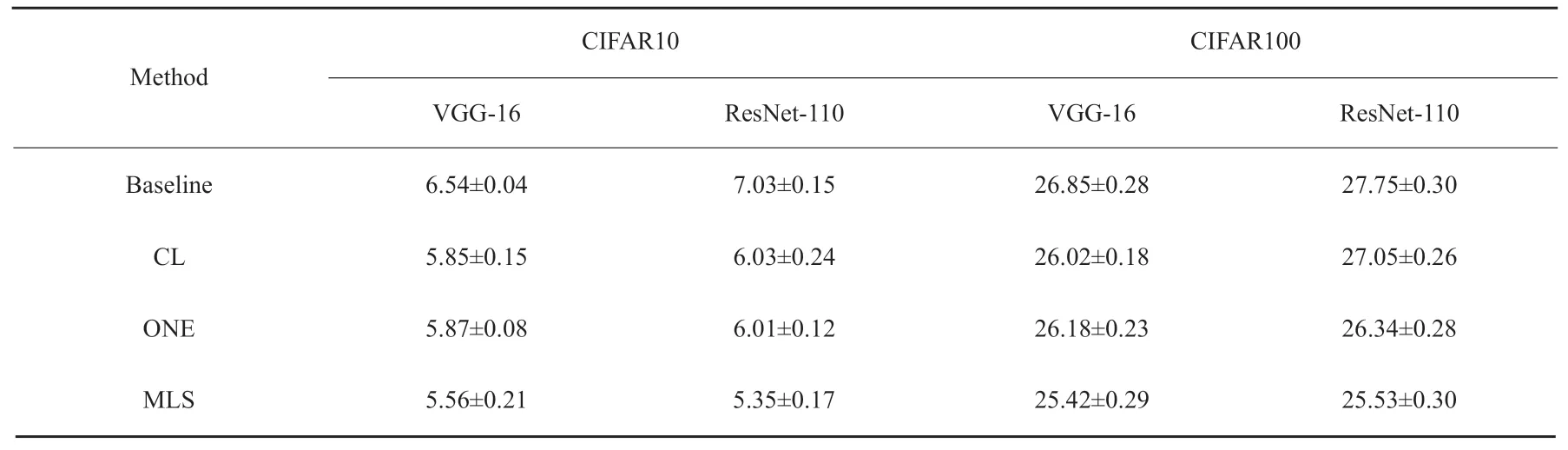
表2 不同基于子分支的算法在CIFAR-10/CIFAR-100上的错误率
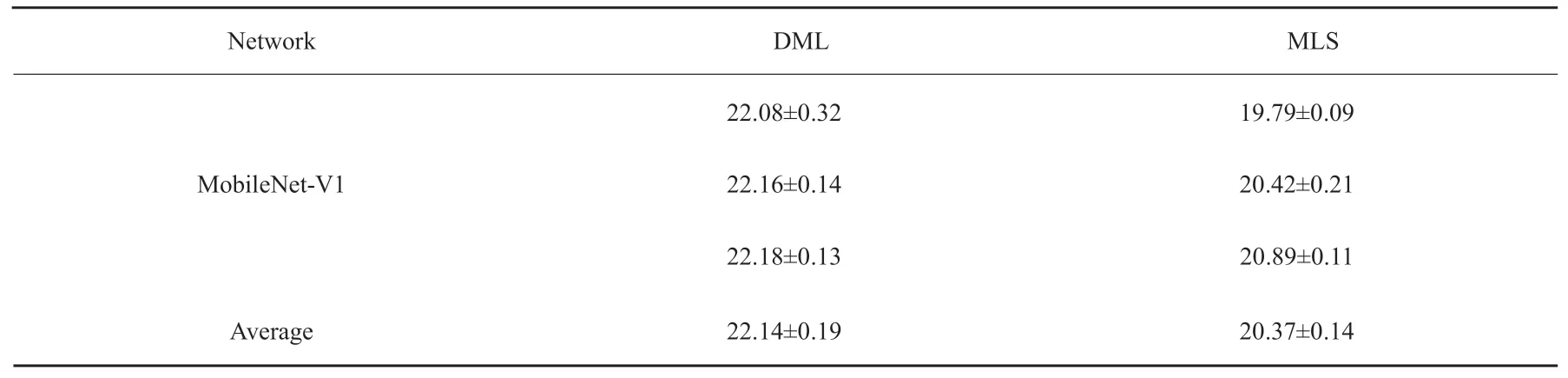
表3 不同基于子网络的算法在Tiny-ImageNet上的错误率
本文提出了一种高效的基于互学习的在线蒸馏系统(MLS),可以在不需要预先训练教师模型的情况下训练高效的学生模型。MLS的核心是LFS模块,MLS根据各子模型在训练过程中表现出的性能表现给出权重,它们的输出加权生成一个虚拟教师指导学生训练。然后本文通过将三种骨干网络应用在三个常见数据集(CIFAR10,CIFAR100,and Tiny-ImageNet)上证明了MLS的优越性,能得到比其它算法更加高效的学生模型,并做出了对比与分析。
猜你喜欢
当代陕西(2020年17期)2020-10-28
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
家庭影院技术(2019年8期)2019-08-27
人大建设(2018年5期)2018-08-16
燕山大学学报(2015年4期)2015-12-25
应用科技(2015年5期)2015-12-09
中国塑料(2015年4期)2015-10-14
火炸药学报(2014年1期)2014-03-20
