
说话人辨认系统的研究与实现
2021-02-28 02:37陈奕成殳国华匡政睿余玟铮沈泽宇
电气自动化 2021年6期
陈奕成, 殳国华, 匡政睿, 余玟铮, 沈泽宇
(上海交通大学 电子信息与电气工程学院,上海 200240)
0 引 言
随着信息技术不断发展,微信、QQ等手机APP和计算机应用中包含了越来越多的个人和财产信息,一旦账号被盗取,后果不堪设想。因此人们越来越注重个人信息和财产安全问题。然而,传统的密码识别方式存在被遗忘或泄露等风险,具有一定安全隐患。因此,生物特征识别技术逐渐兴起,从指纹识别到人脸、声纹识别,该技术已经越来越多地渗透到日常生活中。
声纹是携带语音信息的声波频谱[1]。一方面,声纹具有唯一性,任何两个人的声纹都有或多或少的差异;另一方面,声纹采集方便,只需要一个录音装置就可以得到声纹识别所需要的数据。因此声纹识别技术具有广阔的应用前景和较高的市场价值。目前该技术已作为社保中的身份认证手段[2],并应用在了金融安全领域[3]中。
声纹识别分为说话人辨认和说话人确认[4]。前者指根据一段语音来辨别属于哪位说话人,属于N选1的识别方法;后者指根据一段语音来确认这段语音是否是声称的某人所说,属于1对1的识别方法。说话人辨认又分为文本相关和文本无关。文本相关要求所有说话人的训练语音和测试语音采用一样的文本内容,而文本无关则没有此要求。本文研究的是说话人辨认系统,即在一个闭集的说话人集合中进行文本无关的说话人辨认。
1 总体设计思路
本文所实现的系统框图如图1所示。
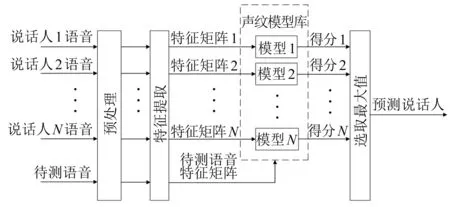
图1 说话人辨认系统框图
在说话人辨认系统模型的建立过程中,首先需要在系统中进行声纹录入,利用计算机麦克风为每个说话人录入10段时长约5 s的语音,加入训练语音库,并对每一段语音进行预处理,接下来提取其梅尔频率倒谱系数(MFCC)特征矩阵,建立说话人声纹的高斯混合模型,加入到声纹模型库中。在测试过程中,说话人需录制一段长约5 s的测试语音,经过预处理、特性提取后得到待测语音特征矩阵,与之前建立好的声纹模型库进行匹配打分,根据匹配不同说话人模型得到的最大似然分数,选取最大值,从而确定说话人身份。
2 软件算法设计
系统软件算法包括了语音信号预处理、声纹特征提取和声纹模型建立与匹配三个部分。
2.1 语音信号预处理
语音信号是由人类声带振动或嘴唇发出的声音或气音,在工程上可建模为一个时间域上连续的波形函数。语音信号预处理流程如图2所示。下面对预处理的步骤作详细介绍。
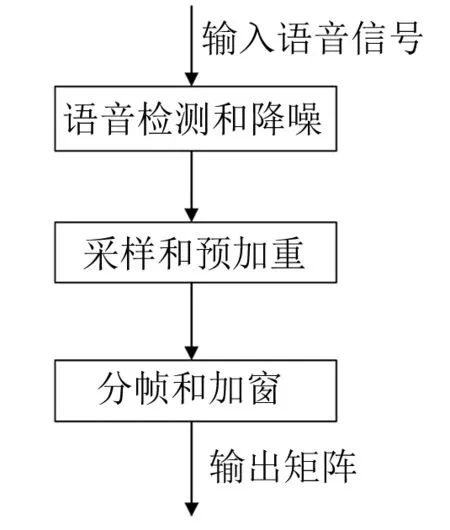
图2 语音信号预处理流程
2.1.1 语音检测和降噪
麦克风采集的语音不能直接用于特征提取,因为语音中会有说话人或长或短的停顿,而且录音环境中难免有噪声干扰,给声纹特征模型带来污染。因此,在建模和识别语音信号前,需要先进行语音端点检测(EPD)[5]和降噪处理[6]。
语音端点检测采用时域的方法,主要根据能量大小进行检测,通过设定阈值来判断语音的有效部分。语音降噪算法采用频谱相减法,它假设噪声是加性噪声,即直接加在语音上的,只要将其减去就可以得到干净语音。频谱相减法不仅降噪效果好,而且计算量小,易于实时实现。
2.1.2 语音信号采样和预加重
为了将连续的语音信号变为离散的数字信号,需要对信号进行采样,等间隔地取出连续信号上的点。
一般来说,人类正常说话声音基频在50~500 Hz范围内,高于800 Hz的部分,信号功率会以6 dB/倍频程跌落[7]。为了减少语音信号高频部分信息的损失,需要对其进行预加重,该过程可以通过一个高通滤波器来实现。高通滤波器的传递函数为:
H(z)=1-μz-1
(1)
式中:μ为预加重系数,可以取0.9~1之间的值,一般取0.96。如果时刻n的采样值为x(n),那么完成预加重之后的信号为:
y(n)=x(n)-μx(n-1)
(2)
2.1.3 分帧和加窗
数字语音信号是随时间变化的离散函数,在短时间内可以认为基本不随时间变化,具有短时平稳性,因此可以将语音信号分为若干小片段进行处理,其中每个小片段叫作帧。在音频处理中,一帧的时长约为10~30 ms。为了使帧与帧之间平稳过渡,两帧之间会有部分重叠,一般重叠部分与帧长之间的比值取0~0.5。分帧后需要对每一帧进行加窗操作,加窗的作用是使每一帧开始和结束的时候渐变到0,可以提高后期傅里叶变换结果频谱的分辨率。本文选用汉明窗。
2.2 声纹特征的提取
声纹特征提取是声纹识别过程中的核心环节。目前已有的研究包括线性预测系数(LPC)、线性预测倒谱系数(LPCC)和梅尔倒谱系数(MFCC)[8],本文采用MFCC提取声纹特征矩阵。
2.2.1 MFCC
梅尔倒谱分析是基于声音频率的非线性梅尔刻度的对数能量频谱的线性变换。梅尔倒谱的频带是在梅尔刻度上等距划分的,它比正常的对数倒频谱中的频带更能模拟人类的听觉系统。MFCC的提取流程如图3所示。
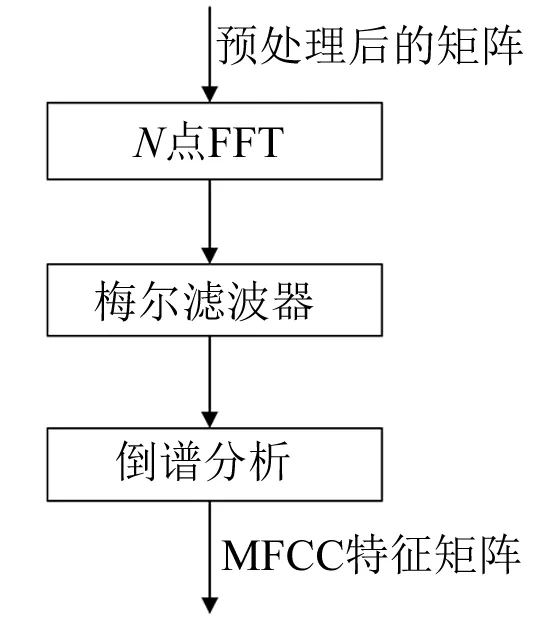
图3 MFCC提取流程
具体分为以下几个步骤进行:
(1) 傅里叶变换。首先要对每一帧进行N点快速傅里叶变换(FFT)转换为线性频谱X(k),k=1,2,…,N-1。在声纹识别应用中,可以忽略FFT结果的相位信息,只取幅度|X(k)|进行接下来的步骤。
(2) 梅尔滤波器滤波。梅尔滤波器是一系列(M个)三角带通滤波器Hm(k),其中心频率为f(m),m=1,2,…,M。对每一帧信号加上M个三角滤波器之后,可以将这一帧信号由线性频率转换到梅尔频率上,通常M取30左右。梅尔频率和线性频率的映射关系为:
(3)
式中:fMEL为梅尔频率;fLIN为线性频率。根据上述关系可以得到三角滤波器的传递函数为:
(4)
将M个此函数加在经过N点FFT变换后的每帧信号上,然后将每个三角滤波器的结果累加起来,最终得到M个值,记为S1,S2,…,SM。
(3) 倒谱分析。由于人的听觉在动态范围内呈现对数压缩,因此需要把每一帧的M个对数滤波器频谱值log10(Sm)利用离散余弦变换(DCT)转换为L个倒谱系数。DCT变换函数为:
(5)
经过DCT变换得到L个特征值,这L个特征值即为MFCC特征向量,一般来说L取12,当n=0时,c0代表的是一帧语音信号的平均对数能量,通常把c0和L个系数值一起组成一个13维的向量MFCC。假设一个语音信号由T帧组成,那么最终得到的一段语音的MFCC是一个T×(L+1)的二维矩阵。
2.2.2 高阶MFCC
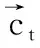
(6)
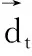
2.3 声纹模型的建立与匹配
提取出声纹特征矩阵后,需要对其进行训练建立模型。目前机器学习领域在声纹识别方面已有很多研究,常用建模方法有支持向量机(SVM)[9]、高斯混合模型(GMM)[10]和卷积神经网络(CNN)[11]等。对于闭集说话人辨认系统来说,使用GMM即可得到很好的识别效果。
1) GMM原理
高斯概率密度函数即正态分布。自然界事物大多并不遵循正态分布,但是将多个正态分布函数按一定权重混合起来,可以精确地表示一个事物。高斯概率密度函数表达式为:
(7)
式中:μ为期望值,决定了曲线位置;σ为标准差;决定了分布的幅度。
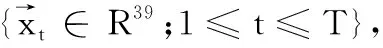
(8)
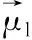
(9)
2) EM算法
GMM三个参数(权重、均值和协方差)的选择需要用期望最大化(EM)算法进行优化。
该算法采用K-means的方法生成高斯混合模型各项参数的初始值,并将期望值作为已知量,根据最大似然估计得到该分布的参数,假设这个参数比原先的参数更能表达真实分布,即得到一组更好的参数。再通过这个参数确定的分布求隐含变量的期望,再求最大值,得到另一组更好的参数,这样迭代下去,直至收敛。
设样本集X=x1,x2,…,xN,p(xi|θ)为概率密度函数,表示抽到xi的概率,θ为待求参数。因此同时抽到N个样本的概率就是它们各自概率的乘积。
(10)
对上述似然函数求对数logL(θ)得到:
(11)
式中:z为模型中的隐变量;p(x(i),z(i)|θ)为变换后的概率密度函数。在EM算法中此函数取:
Qi(z(i))=p(x(i),z(i)|θ)
(12)
式中:p(z(i)|x(i),θ)为隐变量z对应的隐分布。
似然函数最大化得到新的参数值为:
(13)
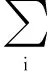
(14)
(15)
(16)
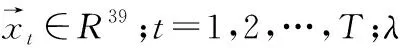
3) 匹配打分
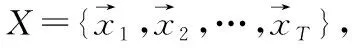
(17)
式中:P(λj|X)为X与每个说话人模型的后验概率,概率最高者即为预测的说话人。
3 试验过程与结果分析
试验的测试环境为基于Windows操作系统的计算机,其中CPU为Intel Corei71.8 GHz,内存为16 GB。语音库中共采集30位说话人(20名男性,10名女性)数据。每人通过计算机麦克风录制10段语音,每段平均时长约为5 s,语音内容为随机中文语句。
在本地主机进行试验时,根据不同训练语音长度来测试识别准确率。本文分为以下五种情况进行试验:训练语音5句,测试语音1句;训练语音6句,测试语音1句;训练语音7句,测试语音1句;训练语音8句,测试语音1句;训练语音9句,测试语音1句。测试结果如表1所示。
由表1试验结果可以看出,当训练语句减少为7句(总时长35 s)时可以达到30/30的识别准确率,并且所用时间是所有试验中最短的。因此本系统最少可以使用7句语音进行模型训练,即可以保证识别准确率的条件下识别速度最快。
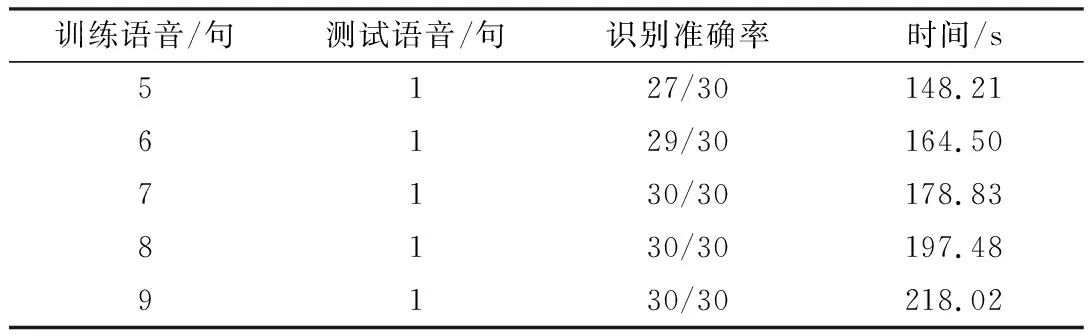
表1 不同训练语音长度情况下识别结果
4 结束语
本文利用Python在Windows操作系统搭建了一个利用高斯混合模型识别梅尔倒谱系数的具有降噪功能的说话人辨认系统,包括了语音信号预处理、声纹特征提取和声纹模型建立与匹配等过程。语音库中共采集30位说话人数据,每人通过计算机麦克风录制10段语音,其中最少5句用于训练,1句用于测试。经过试验,此系统在闭集说话人测试集中可以达到30/30的识别准确率。相比于传统说话人识别系统,该系统增加了降噪功能,应用场景更加广泛,并且训练语音长度最短仅需要35 s即可达到30/30的识别效果,具有识别速度快、识别精度高的特点,为未来的生物特征识别技术提供了新思路。
猜你喜欢
哈尔滨工业大学学报(2022年5期)2022-04-19
红领巾·探索(2019年2期)2019-04-19
语言与文化论坛(2019年3期)2019-04-13
通信产业报(2018年32期)2018-11-24
畅谈(2018年17期)2018-10-28
电子技术与软件工程(2017年24期)2018-01-17
智能计算机与应用(2016年6期)2017-05-08
电脑知识与技术(2016年12期)2016-06-14
浙江大学学报(工学版)(2015年1期)2015-03-01
祝您健康(2009年4期)2009-04-08
