
基于FP-Growth算法的计量主站告警分析研究
2021-02-28 02:37余飞娅叶文波
电气自动化 2021年6期
余飞娅, 叶文波
(贵州电网有限责任公司,贵州 贵阳 550000)
0 引 言
随着大数据、云计算和物联网等新一代信息技术的快速发展,南网加快公司各类业务与新一代信息技术的融合,挖掘数据价值,实现从业务驱动到数据驱动,对于促进“数字南网”建设具有重要意义[1]。当前,计量主站告警数量日益激增,并且存在大量无效告警,加重了运维人员的工作压力[2]。面对计量运行过程中存在的海量告警数据,如何对监控告警进行分类筛选,发掘有业务价值的告警,并直接分析出告警根源仍是亟待解决的问题。近年来,关于关联规则挖掘的研究一直受到国内外学者的重视,并展开了大量的研究[3-6]。文献[7]通过改进FP-growth算法,无需生成FP-tree,解决了云平台数据量过大导致处理效率低的问题。文献[8]针对入侵检测系统产生的相互孤立的告警数据,通过改进FP-growth算法,挖掘稀疏数据的关联关系,提高了数据处理效率。在电力系统中,文献[9]采用灰色关联规则分析方法对变压器故障信息数据进行挖掘,揭示了变压器故障与特征量的相关程度。文献[10]采用FP-growth算法挖掘变电站二次设备存在的缺陷及其原因的关联规则,为智能变电站二次设备运维提供支持。当前,针对单个计量无效告警事件,已经有相当规范的处理方法。但是计量系统运行情况繁杂,单一告警事件的处理方式难以满足实际业务应用需求,缺少多个告警之间的关联,经常造成误报、漏报等问题。因此,本文基于计量系统中的历史告警数据,通过引入库尔钦斯基(Kulczynski, kulc)度量及不平衡比,改进FP-Growth算法,排除关联规则挖掘过程中无意义关联规则的影响,确定计量主站告警的识别方法。
1 计量主站告警规则分析建模
1.1 计量主站告警规则分析建模流程
为解决电网运行过程中存在的大量无效告警,提高异常问题处理的准确性和及时性,本文采用FP-Growth算法对计量主站出现的历史告警数据进行关联规则挖掘,分析计量主站告警产生的原因。计量主站告警关联规则分析模型构建过程如图1所示。
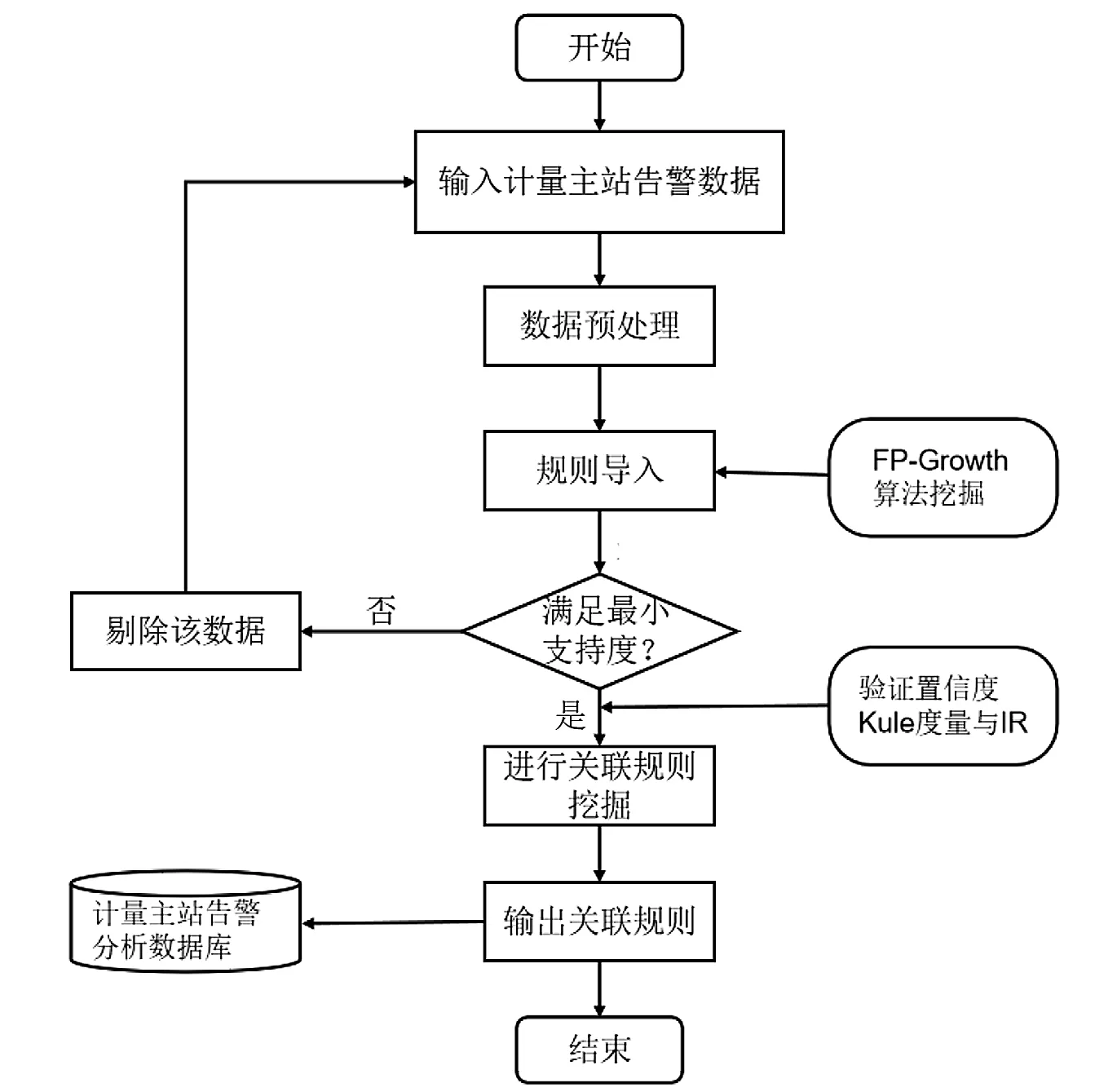
图1 计量主站告警规则分析建模流程图
1.2 FP-Growth算法挖掘关联规则判定条件
由于传统关联规则挖掘Apriori算法需要通过构造候选集,多次扫描原始数据才能挖掘出频繁项集,导致系统运转速度较慢,降低了工作效率。因此,选取不产生候选集,仅扫描两次数据库的FP-Growth算法,对计量主站告警数据的关联规则进行挖掘。关联规则判定主要包括支持度、置信度、Kulc度量以及不平衡比(imbalance ratio,IR)等指标,以项目集N为例,分析事物X与事物Y之间的关联规则。
(1) 支持度(support)作为关联规则的约束条件之一,是衡量关联规则出现频繁程度的重要指标,即在全部事务中,{X,Y}出现的可能性,其表达式如式(1)所示。
(1)
式中:N为事务的数量;σ(X∪Y)为事务X与事务Y的交集。支持度主要目的是通过设定最小支持度阈值(minsup),剔除出现较少的无效规则,保留出现频繁的关联规则,进而筛选得到频繁项集Z,其表达式如式(2)所示。
s(Z)≥minsup
(2)
(2) 置信度(confidence)表示在事务X发生的前提下,事务Y发生的概率,即确定事务Y在包含X的事务中出现的频繁程度,其表达式如式(3)所示。
(3)
(3) Kulc度量为将事务X和事务Y作为置信度的均值,不用计算支持度,进而不会受到不含任何项集的事务影响,其表达式如式(4)所示。
(4)
(4) 不平衡比(IR):揭示事务X和事务Y之间真实的关联规则,其表达式如式(5)所示。
(5)
式中:若IR接近于0,表明事务X和事务Y的关联规则十分平衡,即事务X发生后事务Y很有可能会发生,反之亦然;若IR接近于1,表明事务X和事务Y的关联规则十分不平衡,即事务X发生后事务Y有可能发生,但反之却不成立。
1.3 FP-Growth算法挖掘关联规则流程
FP-Growth算法挖掘关联规则的核心步骤是构建FP-tree树节点,减少所需项集的数量。令I={i1,i2,…,id}为数据中所有项的集合,而T={t1,t2,…,tN}是所有事务的集合。每个事务ti包含的项集都是I的子集。其具体挖掘流程如下:
(1) 事务获取。假设告警序列为I1、I2、I5、I2、I4、I2、I3、I1、I2、I4、I1、I3、I4、I5、I2、I3、I6、I1、I3、I1、I2、I3、I5、……。将告警序列划分为事务级,设置窗口初始大小为1,最大长度为4,得到事务集合列表,如表1所示。
(2) 构建FP-tree。扫描原始数据库,统计每个项目出现的次数,设定最小支持度为2,以降序排列方式重新排列项目集,得到整理后的事务集合列表,如表2所示。
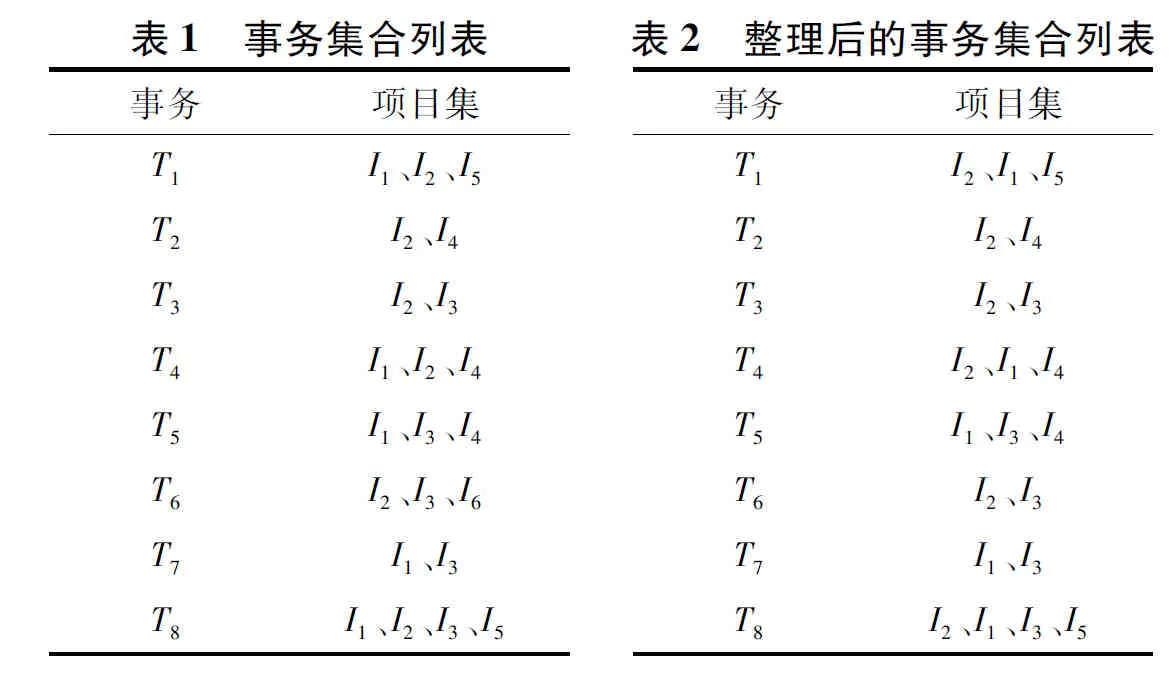
根据整理后的数据列表,按照表2给出的序号依次将8条项目集加入FP-tree中,得到如图2所示的树状图。
(3) 频繁项集挖掘。从FP-tree中挖掘频繁模式,对于每一个项目,梳理得到基础模式项,即以所查找项目为结尾的路径集合。以I5为例,其基础模式项为{(I2I1:2),(I2:2),(I1:2)},进而递归调用FP-Growth算法,得到模式后缀为I5的所有模式,递归调用结束。最终模式后缀I5支持度大于2的所有频繁模式为:{I2、I5:2,I1、I5:2,I2、I1、I5:2},同理可以得到其他项目的频繁相集模式,如表3所示。

表3 挖掘出的频繁模式
由表3可知,在I2事件发生的情况下,I1和I3都出现的频率较高,说明它们之间存在强关联关系。
2 实例分析
以南网某电网公司的计量主站2020年6月2日至2020年6月30日统计的告警数据为例,主要包括:序列号、设备类型、设备编号、告警详情、告警级别、告警时间、告警标志、告警类型、告警设备地址和告警区域等字段信息,对计量主站运行过程中的告警信息进行分析。通过原始告警数据中的重复告警或闪断/自愈告警对数据进行删除,筛选出322.98万条告警数据用于数据挖掘,分析计量主站告警及相应的电流不平衡、断相、失压、表盖开启和电能表飞走告警之间的关联规则。以2020年6月2日至2020年6月24日的248.52万条数据作为训练样本集,建立计量主站告警关联规则分析数据库,采用FP-Growth算法对179.52条训练样本数据进行挖掘,设置最小支持度为40%,最小置信度为70%。部分强关联规则如表4所示。

表4 部分强关联规则
由表4可知,挖掘出的部分频繁项集在满足最小支持度、最小置信度以及Kulc度量的同时,IR均小于0.1,表明该事务具有强关联关系,且属于有意义的关联规则。如10 kV水盘高速Ⅰ回线002受到电能表飞走的影响,导致出现告警,从而能够指导供电局对此条线路加强维护力度,降低告警事件的发生,提高供电的可靠性。
为验证计量主站告警关联规则分析的准确性:以2020年6月24日至2020年6月30日的74.46万条数据作为测试选择集,即从中每天随机选取100条告警数据进行计量主站告警关联规则的匹配与验证。告警准确率等于通过模型测算出的关联告警与实际发生告警数量之比。验证流程如图3所示。
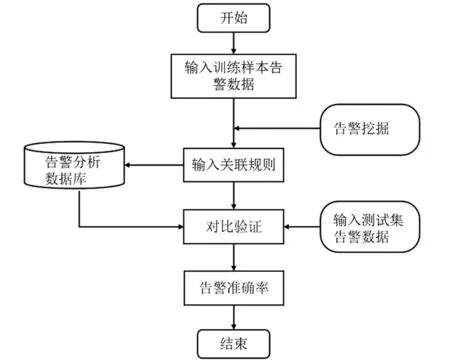
图3 验证流程图
对比没有引入Kulc度量和不平衡比的传统FP-Growth算法,本文提出的算法可以有效地排除无意义关联规则的影响,提高计量主站告警关联识别的准确性。采用前文所述的测试集进行测算,对比传统算法与本文算法的准确率差异,如表5所示。
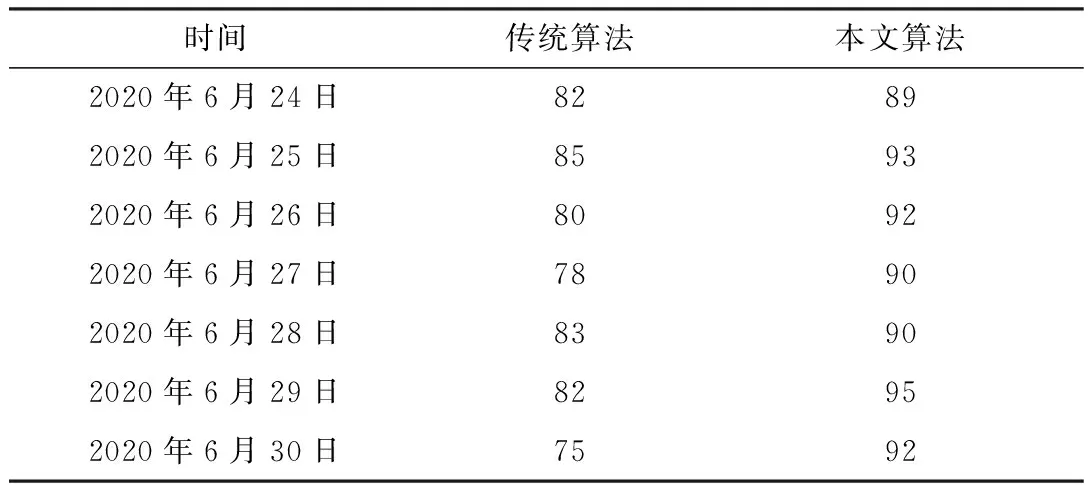
表5 传统算法与本文算法的准确率对比表 %
经过实际查找验证,本文提出的算法准确率较高,总体准确率达到了91.2%,明显高于传统算法,验证了本文提出的FP-Growth算法挖掘关联规则的准确性和有效性。
3 结束语
本文采用FP-Growth算法挖掘计量主站告警的关联规则,为排除关联规则挖掘过程中无意义关联规则的影响,引入Kulc度量以及不平衡比来确定强关联规则及重要程度,确定计量主站告警的识别方法。结果表明:FP-Growth算法挖掘计量主站告警的关联规则准确率达到了91.2%,算法准确度较高;构建的FP-Growth算法挖掘计量主站告警关联规则具有较高的实际应用价值,剔除外部干扰因素的影响,协助电网公司更加精准定位计量主站告警源,高效排查并解决计量主站告警,保障电网稳定运行。但是计量主站告警诱因较多,仅基于本文提到的告警诱因无法进行完整描述。因此,下一步将在完善指标体系等角度入手,提高告警原因挖掘能力和告警识别的准确性。
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
河南水利年鉴(2020年0期)2020-06-09
天津科技大学学报(2018年4期)2018-08-22
计算机应用(2018年5期)2018-07-25
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
轴承(2015年2期)2015-07-25
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
网络安全与数据管理(2010年1期)2010-05-18
