
参与式感知系统中用户累积行为信誉计算①
2021-02-23 06:30张晓滨张嘉诚
计算机系统应用 2021年2期
张晓滨,张嘉诚
(西安工程大学 计算机科学学院,西安 710048)
共享经济和移动技术的广泛普及推动了参与式感知的发展,大量基于智能手机的参与式感知系统被人们重视并应用到现实生活中[1],如任务分配[2]、数据转发[3]、在线社区[4]、昆虫监视[5]、空气污染监测[6]等.由于感知数据是由普通参与者自愿收集并共享,因而错误操作或恶意贡献者很大程度上会降低数据质量.如何提高感知数据质量及数据使用率越来越引起学者重视和研究.
在感知数据质量方面,部分学者主要针对低质量数据问题展开研究,文献[7]建议使用信誉管理对所收集的数据进行分类,以向数据分析员提供有用信息;文献[8]在处理低质量数据的同时考虑私人数据的机密性,提出了线性盲回归建模方式,该模型在不了解本地私有数据的情况下既可以收集参与者感知数据又可以有效地建立全局线性回归模型的最佳估计,以帮助检测感知数据;文献[9]提出基于累积声誉模型提高数据质量,该模型通过对参与者历史感知数据质量及参与频率的积累,识别并减少不良影响以获得较准确的感应结果;文献[10,11]等基于低质量数据研究进行了深入探索,以便能够很好地区分高质量与低质量数据.但上述研究并没有考虑将数据质量与影响数据质量的参与者关联,以减少恶意贡献者或数据篡改者对数据真实性的影响.部分学者针对可能影响数据质量的参与者展开研究,文献[12]以参与者行为为研究起点,从时间、空间两个方面分析感知用户的行为及感知活动空间,但未分析行为因素与参与者自身或感知数据质量之间的联系;文献[13]通过考虑参与者的时空可用性解决参与者选择问题,以选择有效的参与者继而提高数据质量;文献[14]主要针对影响参与者贡献度的激励机制和隐私问题提出了一种通用的隐私感知激励方案,以减少用户对隐私泄露的担忧,提高用户主动参与性.上述研究虽对数据质量或影响数据质量的参与者因素展开了研究,但在进行参与者研究时,也可以考虑通过对用户可信度的分析提高对信赖参与者的选择,从而提高数据质量.
为提高感知用户可信度分析的真实性与可靠性,本研究提出了基于用户累积行为的信誉计算模型.首先,该模型在考虑实现感知环境累积行为信誉计算时参与者数量庞大、分布广泛的前提下,采用OPTICS算法在降低对输入参数敏感度的同时对行为数据集进行聚类处理,实现场景定义;其次,考虑到实际应用中感知用户行为的多样性,为避免用户单一行为的伪装对信誉判断的错误影响,提出融合多行为的累积行为信誉计算模型;最后,考虑用户行为对信誉判断的影响度可能随时间增加而降低,通过引入时间戳标记抛弃部分旧行为实现信誉更新.
1 场景定义
在实际感知环境中,由于参与用户数量庞大、分布广泛.因此,在进行信誉计算时如何高效、精确地选取所需用户成为感知信誉研究中需要解决的首要问题.通常,用户分类或场景定义通过发现用户之间的潜在联系解决分布广泛的问题,帮助选择具备某些特征或符合条件的用户.学者们针对场景分类问题展开了一系列研究并提出多种可用方法[15–20],但针对感知环境中的用户复杂性、行为多样性以及核心用户不确定性等特殊问题,本文使用OPTICS 聚类算法对用户进行场景分类,该算法可以降低数据集对输入参数的敏感度,帮助获取不同邻域半径的簇集,有助于选择合适的用户及行为集进行累积信誉计算.
OPTICS 算法在对行为数据集进行聚类时,首先遍历样本集X,寻找所有符合其ε-邻域内样本点数大于邻域最小点数MinPts的样本点,并将这些样本点加入核心对象集合.其次,随意选择一个未处理的核心对象xi,通过对xi与其ε-邻域内未访问的样本点(xj)间的可达距离排序得到有序列表决策图.最后,通过决策图可以得到 ε取不同值时的行为数据聚类结果.(可达距离是指xi的核心距离和xi>与xj欧几里得距离间的最大值,核心距离是指使xi成为核心对象的最小距离).算法伪代码如算法1.

算法1.OPTICS 算法输入:样本集X,邻域半径,-邻域最小点数MinPts,种子集合Seeds输出:有序样本点varepsilonε 1.初始化核心对象集合;Ω=∅2.遍历X 的元素,如果是核心对象,则将其加入到核心对象集合 中;X≠∅Ω3.while doΩ4.for 中所有核心对象,随机选择一个未处理的核心对象 并标记为已处理,同时加入有序列表p;xi ε x jx j xi 5.计算 与-邻域中所有 的可达距离,并将 插入到根据可达距离排序的种子集合Seeds 中;S eeds=∅6.if执行步骤4;else 选择Seeds 中可达距离最近的点seed,标记为已处理同时将其压入有序列表p;7.if seed 不是核心对象执行步骤6;else 将seed 的所有邻居点加入到种子集合,重新计算可达距离,执行步骤6;8.end 9.end
2 累积行为信誉模型
2.1 累积行为信誉计算
采用OPTICS 算法得到不同场景下的行为数据集,定义上述获得的场景集Beha={bi1,bi2,···,bkx}(i=1,2,···,k表示共有k个场景),每一场景下的行为集UserBeha=(m=1,2,···,m表示第m个行为)中可以得到x用户的m个行为.对比同一场景中同一行为下不同用户的执行结果,通过每一个结果的出现率和偏差率给出对该行为真实性与可信度判断的初步分值,并存入行为分值集S=中,使用稳健平均值迭代算法[10]计算每一行为分值在信誉计算中所占权重wm,所有行为的权重集可以表示为W={w1,w2,···,wm}.具体计算方法如下:

其中,wi初始值为,ε是一个用来改进算法的较小数值[21],稳健平均值求权重算法如算法2.

算法2.稳健平均值求权重UserBeha={b111,···,bmix}输入:行为集,行为分值W={w1,w2,···,wm}S={s111,···,smix}输出:行为权重1.for i=1 to m wi=1 2.初始化;wmi−wm−1i 3.while 收敛 do m 4.式(1)~式(3)计算,;5.end 6.end w wi
通过算法2 得到每一行为分值在信誉计算时所占的权重,再使用式(4)计算用户信誉.

2.2 信誉的更新
用户行为的时效性主要体现在其在信誉计算中的影响度可能随时间的增加而降低,因而本文在进行累积行为计算时引入时间戳标记信息,减少旧行为对信誉的影响并及时更新用户信誉.
研究中将时间轴划分为若干个长度为t0的时间窗口,定义每一行为的初始时间为tini,计算信誉的当前时间为tend,|tend−tini|时间段内存在j个时间窗口且用户在这一时间段内行为i(i=1,2,···,m)的发生频数为k,则基于时间因素更新用户信誉的计算函数如下:

其中,Repg表示第g个时间窗口的用户信誉.为时间衰减函数,λ为可主观设定的时间调节系数[21],g越大距离当前信誉计算时间间隔越长,时间衰减函数值越小,则该时间窗口的信誉值在用户信誉更新时所占比重越小.
通过对累积行为信誉计算模型中场景定义、信誉计算、信誉更新的描述,得到累积行为信誉算法如算法3.

算法3.累积行为信誉算法输入:样本集X,邻域半径,-邻域最小点数MinPts,种子集合Seeds,行为集,行为分值Rep−n={Repnew1,Repnew2,···,Repnewn εε UserBeha={b111,···,bmix}S={s111,···,smix}输出:用户信誉值}1.执行算法1,场景定义;∉UserBeha 2.if 新行为执行步骤1;3.else 执行算法 2;4.if 经历t0 时长5.式(5)更新用户信誉;6.end
3 实验分析
实验采用SNAP 公布的Bitcoin Alpha trust weighted signed network 数据集[22,23].该数据集信息来源Alpha平台下5 种不同网络环境下比特币交易的用户信誉信息,包含3783 个用户节点,24 186 条用户交互边,每条边的权值从−10 到10 不等,其中积极数据集占总数据集的93%.本文选取任意一个网络下的用户交互信息进行实验,实验先对这些数据进行统一处理,形成包含源用户ID、目标用户ID、源用户对目标用户的行为分值和用户初始信誉4 个字段的数据集.
为验证累积行为及时间戳概念能够较准确的计算并更新信誉值,首先使用OPTICS 算法对随机选取数据集中的500 条行为数据进行聚类处理,得到有序列表决策图和可视化分类图,结果如图1所示.
图1(a)图为有序列表决策图,图1(b)为可视化聚类结果图.从决策图可以看出实验数据集被分为5 个类别(决策图的每一个凹槽代表1个类别).从这5 个类别的行为数据集中随机选取a、b、c 三组进行以下两组对比实验.
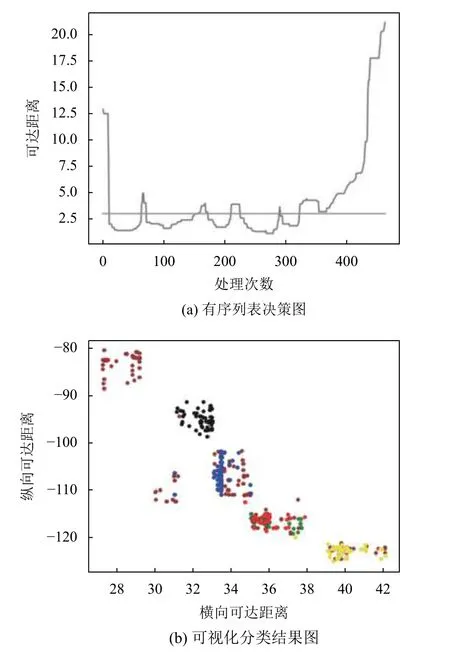
图1 场景分类结果图
(1)对比单一行为、累积行为计算的用户信誉及用户的真实信誉.
从图2信誉计算对比图可以看出,使用累积行为计算用户信誉更贴近真实信誉.从图2(a)可以看出,a 组数据中仅有7.36%的单一行为信誉比累积行为信誉更贴近真实信誉,相反,有92.64%的累积行为信誉更贴近真实信誉;从图2(b)可以看出,b 组数据中有10.27%的单一行为信誉比累积行为信誉更贴近真实信誉,3.63%的单一行为信誉与累积行为信誉相等,但有86.1%的累积行为信誉更贴近真实信誉;从图2(c)可以看出,c 组数据中仅有2.46%的单一行为信誉比累积行为信誉更贴近真实值,而有97.54%的累积行为信誉更贴近真实值.
(2)对比未引入时间戳的用户信誉及引入时间戳的信誉更新值.
从图3信誉更新对比图可以看出,引入时间戳概念对用户信誉进行更新,能够减少旧行为的不恰当影响,得到较为准确的信誉值.从图3(a)可以看出,在a 组数据中仅有2.46%的更新信誉值与未更新信誉值相等,而有62.38%的更新信誉值更贴近真实信誉值且有36.69%的更新信誉值与真实信誉值相等;从图3(b)可以看出,在b 组数据中仅有2.46%的未更新信誉值更贴近真实信誉,但65.36%的更新信誉值更贴近真实信誉值且有33.78%的更新信誉值与真实信誉相等;从图3(c)可以看出,在c 组数据中所有更新信誉值的效果均优于未更新信誉值,且有30.27%的更新信誉值与真实信誉相等.
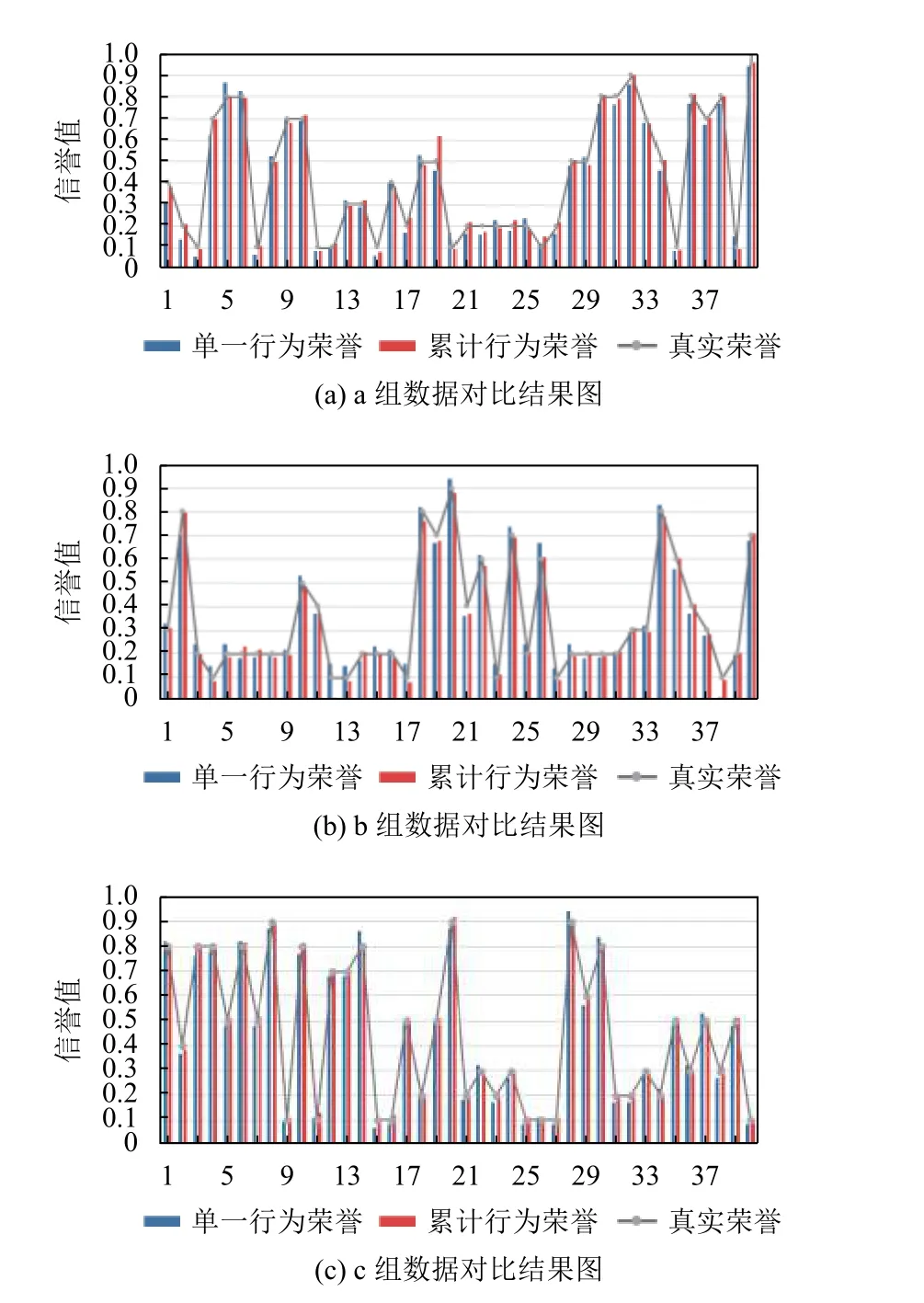
图2 信誉计算对比图
4 总结
本文针对感知用户信誉计算过程中行为多样性的影响和信誉更新的问题,提出基于累积行为的信誉计算模型.该模型结合OPTICS 算法对用户行为场景定义,基于用户分类结果再使用稳健平均值迭代算法调整每一行为在累积信誉计算中的比重,最后引入时间戳标记剔除较久发生的行为,实现用户信誉更新.
该信誉计算模型能够考虑到用户行为的多样性及时效性,对用户信誉有一个较为准确的判断,使感知用户的信誉计算更加具有客观性,符合实际生活规律,有助于感知环境中的参与者选择.后期可考虑根据所更新的用户信誉进行可信赖社区探索.
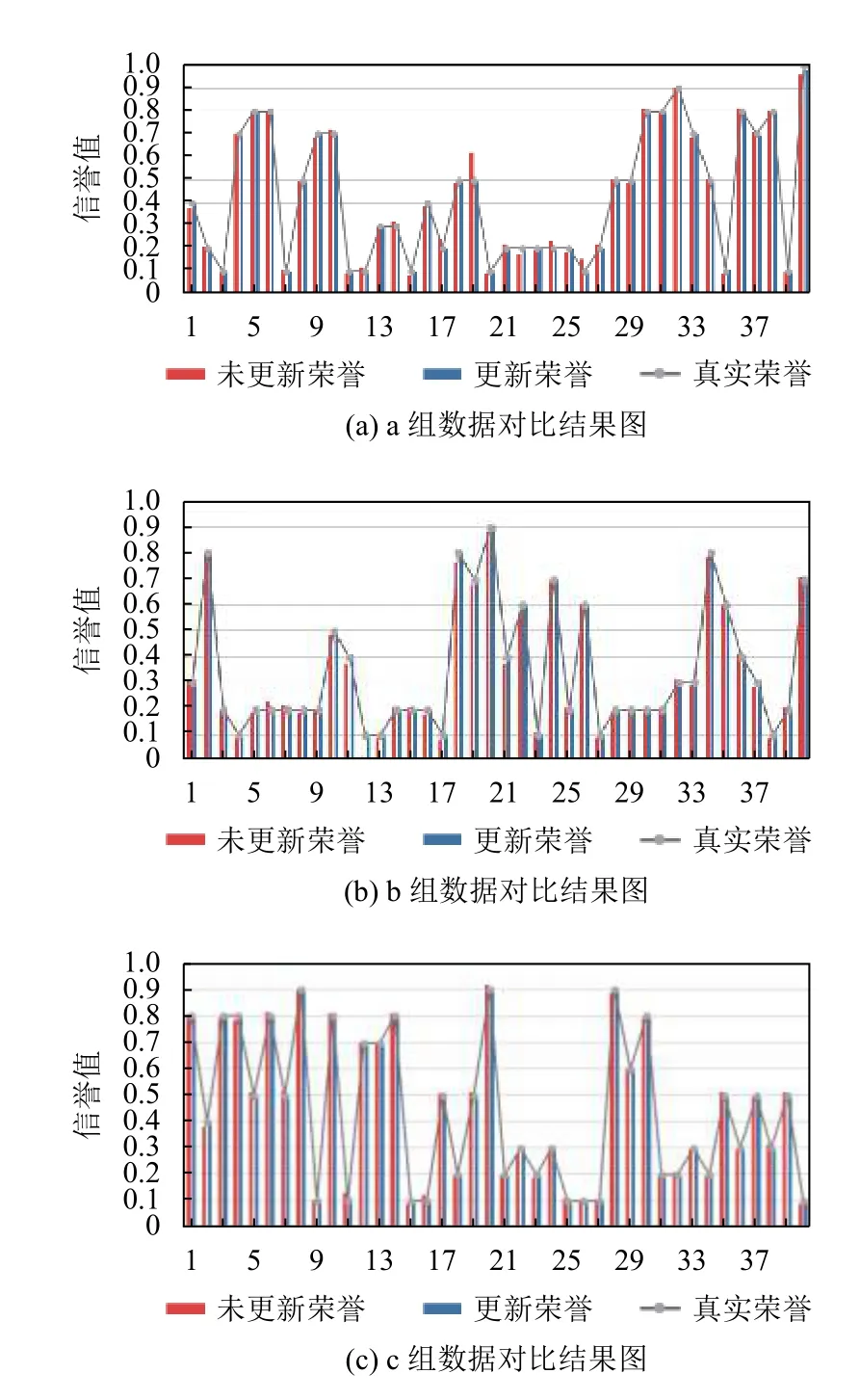
图3 信誉更新对比图
猜你喜欢
农业工程学报(2022年7期)2022-07-09
计算机应用文摘·触控(2022年8期)2022-05-25
华人时刊(2019年13期)2019-11-26
电子技术与软件工程(2019年8期)2019-07-16
青少年科技博览(中学版)(2017年4期)2017-06-13
养生保健指南(2017年4期)2017-05-26
37°女人(2016年12期)2016-12-09
中国质量万里行(2014年7期)2014-08-09
知识力量·教育理论与教学研究(2013年11期)2013-11-11
环球时报(2009-09-21)2009-09-21
