
基于SAC算法的矿山应急救援智能车快速避障控制
2021-02-22 02:39单麒源张智豪张耀心余宗祥
黑龙江科技大学学报 2021年1期
单麒源,张智豪,张耀心,余宗祥
(黑龙江科技大学 矿业工程学院, 哈尔滨 150022)
0 引 言
煤矿瓦斯灾害的突发性与继发性是事故救援考虑的重要因素。救援队伍可迅速到达事故矿井,但若冒然救灾,易受到二次爆炸等安全威胁。“3.29”事故吉林通化八宝煤矿连续发生了6次瓦斯爆炸,造成了21名救护队员牺牲,带来惨痛的救援教训。救护队员快速救灾与救护队员生命安全已形成明显矛盾,为提高救援效率和保障人员安全,开展矿山应急救援智能车的相关研究是十分必要的。灾后第一时间将救援智能车投入受灾矿井,采集灾后环境信息、排查潜在安全隐患。救援智能车需躲避灾后井巷内的各种障碍物,如变形的矿车、垮落的岩石等,才能到达事故发生地点开展工作,这就要求救援智能车具有一定的反应式避障能力。
反应式避障是指机器人通过如激光雷达、深度摄像头或者其他传感器观测到障碍物的距离,通过对距离的计算,紧急避开障碍物的算法[1]。传统避障算法,如模糊控制法等,面对动态且未知环境时依靠人类专家指定的方案做决策,存在灵活度差以及普适性不足的缺点[2],提出深度强化学习(Deep reinforcement learning)的避障算法。笔者将深度强化学习算法应用在基于阿克曼结构的矿山应急救援智能车(智能体)上,使其在灾变矿井多障碍环境下具有反应式避障能力。
1 Soft Actor-Critic算法
1.1 马尔科夫链
马尔科夫链是一个对现实世界抽象的模型[3],用来描述智能体和环境互动的过程,马尔科夫链被广泛使用强化学习领域。马尔科夫链流程如图1所示。

图1 马尔科夫链Fig. 1 Markov chain
在环境中,智能体观察到状态s1,后经过计算,选择动作a1;动作a1使智能体进入另外一个状态s1,并返回奖励r给智能体,依此类推。如果想使智能体避免某个动作,那么当这个动作发生时就进行惩罚,即负奖励;如果鼓励智能体坚持某个动作,那么就进行奖励;智能体根据奖励r调整自己的策略,故智能体会不断朝奖励最大的方向优化,这是SAC算法与环境交互的核心思想。
1.2 SAC与最大熵框架
SAC(Soft actor-critic)深度强化学习算法是第一个将离线策略(Off-policy)、演员评论家算法(Actor-critic methods)和最大熵框架(Maximum entropy)结合的深度强化学习算法[4]。SAC具有稳定性高和样本利用率高的优点,相比其他智能算法(DDPG、SVG等)在处理复杂任务上有三个优势:一是可应付更复杂的任务。通过最大熵,智能体可以得到多种解决问题的方法;二是拥有更强的探索能力,智能体更容易在多模态回报函数下找到更好的策略;三是具有更强的鲁棒性,智能体通过不同的方式来探索各种解决问题的方法,在面对干扰的时更易做出调整。
熵首次在信息论中提出,指获取信息的不确定程度,熵越大则说明信息越不确定[5]。SAC算法将最大熵框架与强化学习算法结合,要求智能体即追求最大奖励r,也追求每一次动作熵(Entropy)最大。在迭代期间,算法在奖励和动作熵之间的不断取舍,动作熵的增加代表智能体趋于探索更多情况,避免陷入局部最优值;奖励的增加代表智能体趋于最优动作,故算法在训练后期的收敛速度会大幅提高。
SAC算法由一个Actor(演员)网络,两个Critic(评论家)目标网络和两个Critic(评论家)网络组成。评论家网络对当前状态下的动作价值进行评估,而演员网络根据评论家的评估对自身动作进行修正。SAC算法在推理时仅需Actor网络输出,将过程中(st,at,r,st+1)保存在记忆池D中以供后续网络更新即可,更新迭代过程较为复杂,由于部分网络在迭代过程中重复使用,故SAC网络结构简述图如图2所示,图中部分参数定义在后文仿真环境中配有详细说明。
在更新迭代过程中,先将首次更新的网络为Critic网络,即图2中流程③,Critic网络输出的Q值代表其对原环境状态st下动作at的价值评估;而更新的依据为Critic目标网络的Q值输出、Actor网络的动作熵输出和奖励r共同计算得出的Qs,即图2中流程①和流程②,Qs可类比监督学习中的标签,目的是为了让Critic网络的Q值同时考虑动作熵和奖励r。而对Actor网络的更新相对简单,此处使用KL散度来评估Actor网络动作与Critic网络价值差距,以进行更新,即图2中流程④和流程⑤。

图2 SAC网络结构Fig. 2 SAC network structure
1.3 最大熵框架下各个网络的更新策略
1.3.1 动作熵的计算
由图2中流程①可知,算法中的动作熵是基于当前的策略与其输出的动作计算出,在初始动作中同时计算动作熵,计算公式为:
H(π(·|st+1))=-logπ(at+1|st+1),
(1)
式中:at+1——以新环境状态st+1为输入的Actor网络动作输出,如图2流程①所示;
π(at+1|st+1) ——在环境状态st+1下输出动作at+1的概率。
由图2中流程②可知,算法中将动作熵作为价值函数的一部分,这样就可以和由Critic目标网络估计的动作价值,通过建立贝尔曼方程转换成状态价值V(st+1)。
推导过程为

(2)
式中:V(st+1) ——st+1的状态价值;
r——奖励值,来源于记忆池D;
Qπ(st+1,at+1) ——在状态st+1下动作at+1的动作价值;
α——熵的权重;
φt j——两个Critic目标网络的参数;

1.3.2 Critic网络的损失值计算
由图2中流程③可知,SAC拥有两个Critic网络,其结构与Critic目标网络一致;Critic目标网络可类比监督学习中的标签,两者相互配合可以保证Critic网络的稳定更新[6]。
两个网络分别输出对动作价值at的估计,计算与Qs差距,即Q价值损失函数,并更新,损失函数为:
L(φi,D)=E(st,r,st+1,at)~D[(Qφi(st,at)-
Qs(st+1))2],i∈{1,2},
(3)
式中:E(st,r,st+1,at)~D——变量(st,r,st+1,at)提取自记忆池D;
φi—— 第i个Critic网络的权重,i∈{1,2};
Qφi(st,at)—— 第i个由φi为权重的Critic网络输出,对原环境状态st下动作at的Q值估计。
1.3.3 Actor网络的更新
在对Critic网络不断迭代更新后,其对Qs(r,st+1)的价值估计会收敛接近真实值。由图2中流程⑤可知,此处使用KL散度来评估Actor网络动作与Critic网络价值差距。推导后的结果为:
(4)
式中:Es~D——变量st提取自记忆池D;
θ——Actor网络的权重;
φj——第j个Critic网络的权重,j∈{1,2};
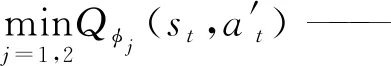

1.3.4 Critic目标网络的更新
通过参数ρ按照比例更新各个目标Critic目标网络,此过程为滑动平均值更新[7]。更新公式为
φt i←ρφt i+(1-ρ)φi,i∈{1,2}。
(5)
算法流程如下:
初始化SAC参数
初始化Critic目标网络以及Critic网络参数,初始化Actor网络参数
初始化记忆池D
for 训练场数=1,Xdo
for 训练步数=1,Ydo
根据当前状态,Actor网络的输出选择动作at~πφ(at|st)
从环境中获得奖励r和下一状态st+1
将(st,at,r,st+1)保存在记忆池D中
end for
if 可以进行更新
for 迭代次数=1,Zdo
从记忆池D获取定量数目的经历保存到
B={(st,at,r,st+1)}
计算Critic目标网络对Q值的估计:
αlogπ(at+1|st+1))
更新Critic网络参数:
Qs(r,st+1))2,i∈{1,2}
更新Critic目标网络参数:
φt i←ρφt i+(1-ρ)φi,i∈{1,2}
end for
end if
end for
2 仿真环境与训练参数
文中采用机器人操作系统,在F1tenth-simulator环境基础上,选取灾后煤矿采区中部车场和下部车场作为虚拟仿真环境,分别用来训练与验证,通过RVIZ三维仿真软件实现可视化。
2.1 车身环境状态与动作定义
矿山应急救援智能车车身结构为阿克曼结构,通过舵机转向和速度操控行驶,且车首装有激光雷达测距装置。
良好的输入及输出数据处理,可减少神经网络训练时间,加速神经网络收敛。将激光雷达测距数据定义为智能体环境状态,将舵机的转向角度和速度定义为动作。对1 080个激光雷达测距数据进行分组,每组30个取平均值,可在一定程度上减少雷达异常的数据的影响,此时环境状态输入维度为(36,1)。
Actor网络输出动作的两个数据,分别对应舵机转向和速度,由tanh函数处理后,分布在[-1,1]之间。舵机转向和速度的数据需要进行限制,因此对其再处理,使其分别保持在[-0.418 9,0.418 9]和[0,3]之间,速度过快会导致在转向时漂移。车身参数设置如表1所示。

表1 车身参数
2.2 奖励策略与训练参数
奖励策略是用于判断当前状态下做出动作的好坏[8]。奖励函数的奖励值与该动作下智能体速度呈正相关,当智能体和障碍物发生碰撞就给予惩罚值,见式(6)。基于深度强化学习算法的趋利性,可预知智能体的速度会越来越快,直到最大速度。

(6)
训练参数如表2所示。其中,UPDATE_ITR表示在每次触发更新的条件时,对网络进行梯度更新的次数。记忆池用于存储智能体所获得的经历,存储格式为(st,at,r,st+1,done),其中done表示智能体是否躲避障碍物。在初次使用梯度更新网络时,智能体需要提取多个经历,PRE_TRAIN_EPISODE设置让智能体在一定场次自由探索以获取经历。

表2 训练参数
2.3 仿真环境
煤矿井下巷道环境复杂,通常是结构化地形环境和非结构化地形环境的综合,灾前巷道环境如图3所示。灾后巷道内常分布着轨道、人行道、机电设备、冒落岩石、掀翻矿车等障碍物。

图3 模拟矿井Fig. 3 Simulated mine
文中训练环境模拟矿井中部车场,矿山应急救援智能车在中部车场中,随机选择起始位置,如图4所示。训练环境雷达数据等值线图,如图5所示。

图4 训练环境-中部车场Fig. 4 Training environment-middle yard

图5 训练地图雷达数据等值线Fig. 5 Isoline map of lidar data of training course
3 实验与SAC算法优化
实验环境:操作系统为ubuntu18.04,ROS版本为Melodic,CPU型号为i7-8750H,GPU型号为RTX2080,编程语言涉及C++和Python,深度学习框架为Tensorflow。
3.1 SAC算法训练智能体
训练过程中智能体的奖励值图6所示,可以发现在170场左右发生了剧烈波动,随后不再稳定,故对其进行分析。

图6 优化前每场训练的奖励Fig. 6 Rewards for each training before optimized
通过对记忆池分析,发现大量被错误标记的经历被保存在记忆池中,在智能体极度逼近障碍物时,智能体虽然已经做出近似最优的动作,如转向角取最大值,但由于现有速度和惯性及之前一系列的错误动作,导致智能体依然会撞上障碍物,此时智能体会将该环境状态和该状态下所做出的动作当作负面经历,而实际上该经历并非负面经历。后期此类被错误标注的经历越来越多,神经网络的多次迭代已无法提升智能体避障性能,导致了后期奖励值骤降。
3.2 输入的优化与训练
针对上述问题进行分析,并提出优化方案。因为错误动作来自经过神经网络处理的环境状态,因此,将Actor网络和记忆池的环境状态维度改为(36,n1),n1表示动作发生前的环境状态个数,其默认值为3。由于其他四个Critic类网络同时需要动作和环境状态作为输入,环境状态数据占比过高可能使得网络收敛速度降低,故进行如图7所示的优化。
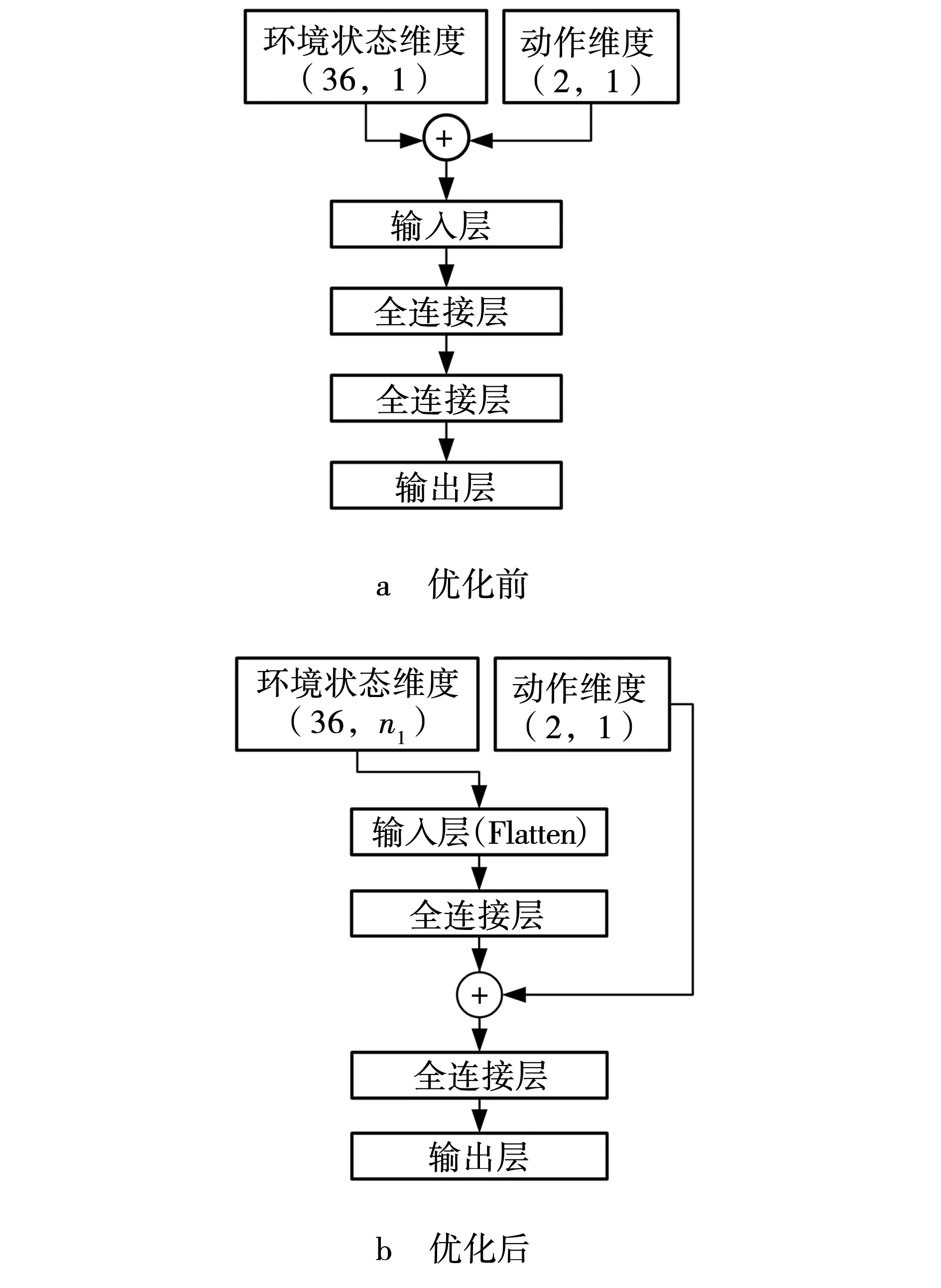
图7 对输入优化后的Critic网络Fig. 7 Critic network after optimized input
训练过程中Critic网络的Q值损失函数的损失值图8所示,损失值的不断减少表明智能体在稳定提升。
由图8可见,训练前期因为探索时期,且Actor网络未完全迭代出优秀的神经网络,经常发生碰撞,所以每场训练的损失值较高。但随着不断的训练,智能体在经历50场训练后,每场训练的损失值迅速下降;在200场接近极限值,初步具备躲避障碍物能力。

图8 训练过程中Q值函数的损失值Fig. 8 Loss function of Q vaule during training
训练过程中智能体的奖励值图9所示。因为奖励函数的设计,Actor网络对速度不断优化,试图逼近最大奖励值,在150场达到奖励值提升速度有些减缓。优化后仍然在150~300场之间出现了少许奖励值波动,其波动原因:
(1)奖励函数与速度成正比,智能体不断追求高速度,在高速训练过程中,GPU计算动作和更新网络时间约为0.12 s,此时GPU计算速度已经无法和智能体的速度匹配。
(2)速度越来越快,需要对转向有着精准的控制,而SAC算法在训练过程中是需要添加噪声以提升鲁棒性,这也在某种程度上导致了波动。

图9 优化后每场训练的奖励Fig. 9 Rewards for each training after optimized
3.3 算法优化前后对比
优化前后每场训练的奖励值对比如图10所示。在25~100场间,由于训练的数据量相比优化后增加,神经网络拟合速度较慢,故优化后的奖励值上升趋势较缓和。在对比之下可以发现,扩大环境状态维度的方法,虽然在一定程度上大幅减轻了波动,但并没有从根本上解决波动问题,不过在250~300场之间,优化后智能体所获的奖励值不断趋于稳定,改善了先前智能体越训练奖励值越低的问题,避障性能有了大幅度提升。

图10 优化前后每场训练的奖励值Fig. 10 Each training optimized for reward before and after
3.4 智能体验证
根据灾后煤矿采区下部车场现场条件建立仿真环境,如图11所示。

图11 测试环境-下部车场Fig. 11 Test environment lower yard
将优化后SAC算法训练出的智能体放入该仿真环境中,对其避障性能进行验证测试,如图12所示。
在图12验证过程中,测得GPU计算动作仅耗时0.08 s,且奖励值一直大于0,代表智能体在行驶过程中没有发生碰撞,大部分时间奖励值处于0.18附近,代表智能体全程高速行驶,表现十分优异。

图12 验证过程中每步的奖励Fig. 12 Rewards for each step during test
4 结束语
提出了一种基于SAC的反应式避障算法,算法中考虑了现实环境的惯性力、加速度、减速度等因素,在此基础上合理地对雷达数据和SAC算法做出优化,并分析其奖励值波动原因,最后在RIVZ三维可视化仿真环境中,验证了优化后智能体的避障性能。
综上,优化后SAC算法训练出的智能体避障表现优异,但应用到现实环境中仍需考虑许多变量,如神经网络预测速度和雷达数据获取的延迟,其次神经网络需要救援智能车的更多状态,如当前速度、舵机角度、方位角等。
猜你喜欢
小猕猴智力画刊(2022年4期)2022-05-25
小学生学习指导(低年级)(2021年12期)2021-12-31
中学生百科·大语文(2021年4期)2021-05-12
阅读与作文(英语初中版)(2019年8期)2019-08-27
领导文萃(2019年8期)2019-04-19
读友·少年文学(清雅版)(2018年12期)2018-04-04
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
智慧少年(2016年2期)2016-06-24
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
