
基于语义分割的非结构化田间道路场景识别
2021-02-19 06:18孟庆宽杨晓霞关海鸥
农业工程学报 2021年22期
孟庆宽,杨晓霞,张 漫,关海鸥
基于语义分割的非结构化田间道路场景识别
孟庆宽1,杨晓霞1,张 漫2※,关海鸥3
(1. 天津职业技术师范大学自动化与电气工程学院,天津 300222;2. 中国农业大学现代精细农业系统集成研究教育部重点实验室,北京 100083;3. 黑龙江八一农垦大学电气与信息学院,大庆 163319)
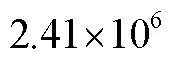
机器视觉;语义分割;环境感知;非结构化道路;轻量卷积;注意力机制;特征融合
0 引 言
当前城市化进程不断推进,农村青壮年劳动力向城镇转移,造成农业劳动力资源日益减少,在一定程度上制约了农业生产的质量和效率[1]。提高农业生产过程的机械化、自动化、智能化水平,降低农业生产对农业劳动力的强依赖性,对于促进农业现代化建设、加速农业生产方式供给侧结构改革具有重要作用[2]。智能农业装备系统能够自主、高效、安全地完成农业作业任务,具有良好的作业精度与效率,已在播种、施肥、除草、收获等领域得到广泛应用[3-6]。
环境信息感知是智能农业装备系统的关键技术之一,决定了农业装备的自主导航能力和作业水平[7]。机器视觉系统具有探测范围广、获取信息丰富等特点,是智能农业装备进行田间信息获取的主要传感设备之一[8-9]。基于视觉的农业田间道路场景识别解析属于环境信息感知的重要组成单元,主要任务是检测可通行区域、识别动静态障碍物类别,为后续的路径规划和决策控制提供依据。快速、精准地实现田间道路场景识别对于保证智能农业装备在非结构化道路环境下安全可靠运行具有重要意义。
在道路场景识别解析研究中,Coombes等提出一种基于颜色特征的机场道路语义分割方法,采用超像素块对图像进行分割,训练基于颜色的贝叶斯分类器对每个分割聚类标注语义类别,将亮度信息与颜色分类器相结合识别飞机跑道上的引导线[10]。Scharwachter等将颜色、纹理、深度等低层级特征进行组合,基于随机决策森林法实现街区场景像素级语义分割[11]。陶思然等将道路影像转换到HIS颜色空间分割出道路灰度一致性区域,结合空间梯度信息对分割结果进行细化[12]。上述研究通过人工设计特征方式基于颜色、纹理、形状等表层特征中的一种或多种的组合进行道路场景识别解析,对结构化道路具有良好的适应性,但缺乏对图像深层特征和高级语义信息的提取与表达,容易受到道路形态、光照变化、路面干扰物的影响,难以应用于复杂非结构化田间道路场景检测。
近些年深度卷积神经网络在图像分类、目标识别、语义分割等领域表现出优异的性能[13-14]。基于深度学习的语义分割技术是进行复杂图像场景识别解析的重要方法之一[15]。轩永仓等设计了基于全卷积神经网络的大田复杂场景语义分割模型,具有较好的分割效果,不过全卷积神经网络没有充分考虑像素之间的关系,缺乏空间一致性,对图像中的细节不敏感,导致分割结果不够精细[16]。李云伍等构建了基于空洞卷积神经网络的丘陵山区道路场景语义分割模型,通过在模型前端模块和上下文模块中融入空洞卷积并对空洞卷积层进行级联,提高了对丘陵道路场景预测的准确性,但连续的空洞卷积运算容易产生空间间隙,导致信息丢失[17]。张凯航等基于SegNet深度学习框架,构建编码-解码深度卷积结构,针对非结构化道路可行驶区域进行语义分割,实现自动驾驶车辆在非结构道路行驶时的场景理解[18]。上述研究基于深度卷积神经网络在像素级别进行图像语义分割,能够取得较好的效果,但也存在权值参数多、计算复杂度高、推理速度慢等不足,同时未充分考虑图像上下文信息,对于全局特征利用率低,导致复杂场景的分割精度不高。
本文以非结构化农业田间道路为研究对象,提出一种基于通道注意力结合多尺度特征融合的轻量化语义分割框架,采用轻量卷积神经网络提取图像特征,引入混合扩张卷积(Hybrid Dilated Convolution,HDC)和通道注意力模块(Channel Attention Block,CAB),通过空间金字塔池化模块(Pyramid Pooling Module,PPM)将多尺度池化特征进行融合,得到完整的全局特征表达,以增强对复杂道路场景识别的准确性。
1 材料与方法
1.1 非结构化田间道路场景特点与对象分类
基于语义分割的道路场景识别解析是对图像中的每个像素定义对应的语义类别,预测输出目标元素的形状、位置和种类等信息,进而实现对场景的完整理解。根据环境感知系统对周围环境对象的关注类别和建模结构差异,自动导航系统的行驶道路可分为结构化和非结构化2种形式[19]。结构化道路具有边界规则,车道线清晰、道路宽度一致等特点,通常包括高速公路和城市主干道。非结构化道路是指没有明显边界区域,缺少车道标识线,可通行区域不规则的园区道路、乡村道路或农业田间道路。
农业田间道路的非结构化特点具体表现为:1)道路边缘模糊、曲率变化大、形状不规则;2)路面平整性差,存在阴影噪声及多种多样的障碍物;3)不同光照或天气条件下同一材质的道路在图像中出现不同的颜色特征与纹理形态。这些复杂特征给农业导航系统进行道路场景识别带来了困难,需要分割模型具有较强的鲁棒性和泛化能力。
本文根据农田道路环境中对象的动、静态属性进行类别划分。动态对象2类,分别是行人,车辆(自行车,农用车,汽车);静态对象9类,包括建筑物、标识牌、天空、植被(树木,杂草,作物)、土壤、道路(水泥道路,沥青道路、硬质化土路)、水域(河流,池塘,路面水洼)、线杆、覆盖物(落叶、地膜、积雪);上述类别之外的对象设置为背景类,因此田间道路图像中的对象类别共分为 12 种。动、静态对象分类可以使导航系统在后续的行驶过程中根据对象属性制定对应的路径规划措施和动态避障策略,进而控制系统安全、高效运行。
1.2 图像采集与处理
图像采集于天津、河北、广东等地,采集时间为2020年1-12月,选用 OKAC120 型相机进行拍摄,图像分辨率为1 920像素×1 280像素。为提高数据样本的多样性,分别在不同天气条件、不同光照强度、不同环境背景下采集860张有效图像,可以较好地反映自然环境下田间道路真实特点。在原始图像基础上将图像尺寸缩放为512 像素×512像素,以减小后期网络模型特征提取时对硬件产生的压力。图1为获取的田间非结构化道路图像示例。
由于获取的图像数据难以完全覆盖所有场景并且存在不同类别样本数量分布不均衡的情况,因此本文通过几何变换(平移、旋转、缩放)与颜色变换(亮度、饱和度、对比度)进行数据增强。增强后的图像共23 220 幅,按照8∶1∶1比例划分为训练集、验证集和测试集。训练集用于训练深度网络模型参数权重;验证集用于训练过程中对模型的超参数进行调优;测试集用于训练完成后评估模型在实际应用场景中的泛化能力。
本文田间道路场景语义分割模型属于全监督学习类型,需要使用人工精细标注的语义图像作为训练样本。采集的图像本身没有标签和语义,利用Lableme工具对图像中需要训练的类别进行语义标注,标注后的文件以.jason格式存储,然后通过批量转换文件将标注文件转换为.png格式的标签图像。
2 田间道路场景语义分割模型构建
通用的语义分割模型由编码器和解码器构成,编码器利用卷积、池化、线性整流函数等操作构成特征提取网络,编码输入图像特征和像素位置信息;解码器利用反卷积或者上池化运算将编码器输出的低分辨率特征映射到高分辨率像素空间,得到密集的像素预测分类。本文模型的编码器单元采用轻量卷积神经网络获取图像特征,引入混合扩张卷积和通道注意力模块,实现特征提取速度与准确性之间的平衡,同时利用金字塔池化模块融合不同区域特征,获取更加有效的全局场景上下文信息,增强模型的分割性能;解码器单元将空间金字塔池化模块的输出特征进行上采样并与特征提取网络最后阶段特征拼接,经过卷积操作完成特征融合与通道调整,最后通过上采样和像素分类运算得到预测图像。图2为田间道路图像语义分割模型结构示意图。
2.1 轻量特征提取网络
传统的卷积神经网络通过扩充网络深度和广度,提高网络模型准确性,但也存在复杂度高,运行速度慢等问题。相比于深度卷积,轻量卷积神经网络具有结构简单、计算量低、学习推理速度快等优点。MobileNet系列网络是由谷歌公司提出的高性能轻量化卷积神经网络,可以应用于计算能力和内存资源有限的嵌入式系统或移动设备[20-21]。MobileNet V2引入具有线性瓶颈的倒残差结构,先通过扩展层增加通道维度,在高维空间进行深度可分离卷积操作提取特征,然后利用投影卷积进行降维以减少后续操作计算量,最后为避免网络层数增加引起的梯度消失采用跨连接层将输入特征与输出特征相加,使整个网络具有较高的准确性和实时性。MobileNet V2是针对图像分类任务设计的卷积神经网络,语义分割属于像素预测问题,采用的特征提取网络与图像分类网络有所不同,需要对MobileNet V2网络结构进行修改。
本文去掉MobileNet V2网络的全局平均池化层与特征分类层,采用前5个阶段(Stage)卷积神经网络进行图像特征信息提取,如图2所示,轻量特征提取网络经过4次下采样,最终输出特征图尺寸为输入图像的 1/16。其中,Stage5是在Stage4的基础上仅扩充特征通道数量,没有进行下采样操作。
2.2 混合扩张卷积
本文将混合扩张卷积融入到特征提取网络的Stage4、Stage5中,Stage4中的6个线性瓶颈倒残差模块(Inverted residuals and linear bottlenecks block,IRLBB)被分为2组混合扩张卷积运算单元,每个单元组中的深度可分离卷积扩张率设置为1、2、3,Stage5中的4个线性瓶颈倒残差模块选择前3个为1组,扩张率设置为1、2、3。图3为混合扩张卷积融合特征提取网络结构示意图。
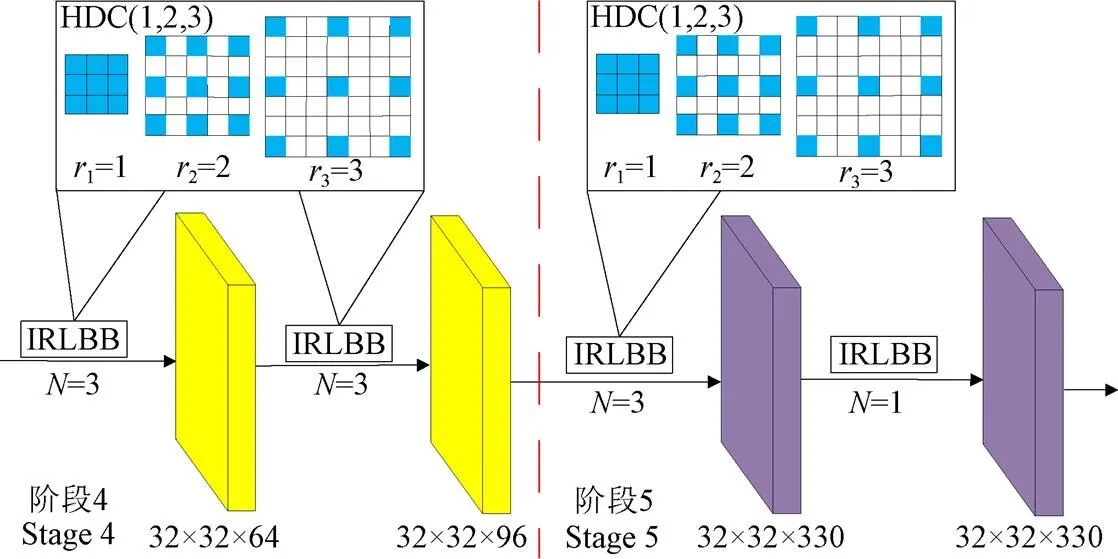
注:N为线性瓶颈倒残差模块执行次数;IRLBB为线性瓶颈倒残差模块;(i=1,2,3)表示卷积核的扩张率依次为1,2,3。
2.3 通道注意力模块
针对复杂场景或者较大区域进行语义分割时,经常会出现将同一对象的不同区域预测为不同类别的情况,即类内预测的不一致性,这是由于不同尺度特征图的判别能力不一致导致[24]。特征提取网络中,不同阶段特征图感受野不同,具有不同的特征判别能力。在低级阶段,网络编码具有精细的空间信息,但由于感受野较小和缺乏高级抽象特征,导致语义一致性缺乏;在高级阶段,特征像素具有较大感受野,语义一致性高,不过由于缺少足够的空间信息,预测结果较为粗糙。基于以上分析,将不同阶段特征进行融合可以有效提高特征利用效率和预测准确性。一些研究采用特征通道相加的方法实现不同阶段的特征融合,这种方式忽略了不同阶段特征通道的差异性。特征提取网络的一个阶段由若干特征通道构成,常规卷积运算默认各特征通道权重相同,实际上不同特征通道具有不同的重要程度,提升有用特征比例,降低非重要特征比例,可以提高整个阶段的判别特征强度。本文采用通道注意力机制将不同阶段特征融合,利用高级阶段的强语义信息指导低级阶段对内部特征通道根据重要程度重新标定,使之产生更优的预测,图4为通道注意力模块结构。
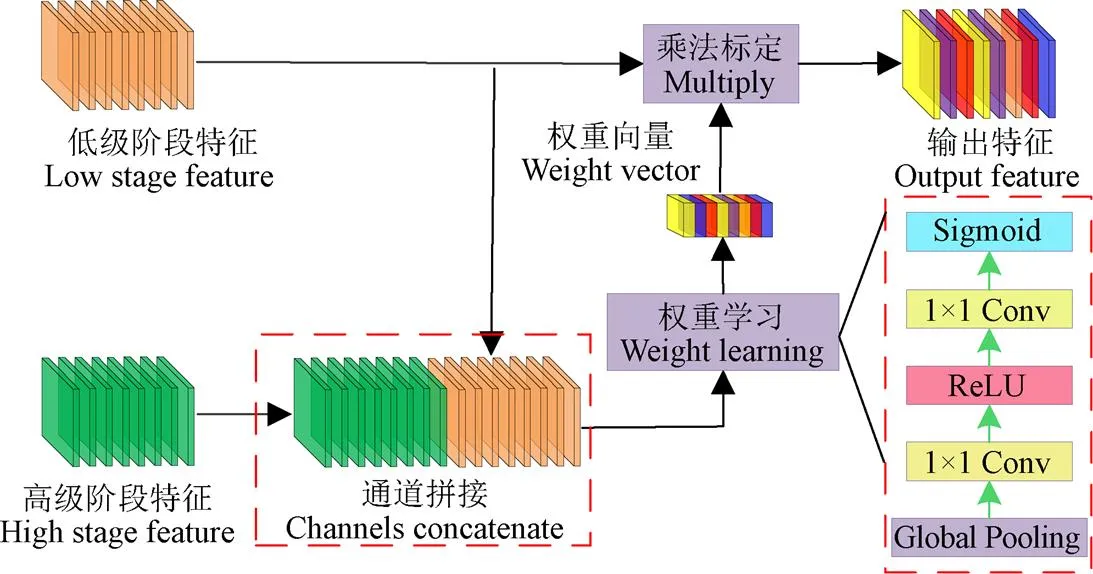
注:Global pooling将特征图压缩为一维向量;Sigmoid为激活函数。
图4中浅色模块代表低级阶段特征,深色模块代表高级阶段特征,将高级阶段与低级阶段进行通道拼接,通过权重学习模块获取每个通道重要程度,生成新的权重向量,采用乘法形式对低级阶段特征通道权重重新标定,提高重要特征权重,降低非重要特征权重,进而增强整个阶段的判别特征。利用通道注意力模块可以强化各阶段判别特征,实现类内一致性预测,提高预测精度。
2.4 金字塔池化模块
感受野是卷积神经网络每一层输出特征图的像素点在原始图像上映射的区域大小,其大小表示提取特征所包含信息的多少,可以大致反映模型利用图像上下文信息的能力,获取具有全局图像特征的感受野能够提高复杂场景下语义分割的准确性。语义分割中出现的一些错误,例如类别混淆、分割不连续和不同尺度物体分割精度不均衡等问题都与感受野获取的上下文信息是否全面有关[25]。文献[26]采用全局平均池化操作获取图像级别上下文信息指导局部信息进行分类,一定程度上提升了分割模型的性能,不过这种方法无法覆盖场景图像全部重要信息,因为通过全局平均池化将全部像素融合为1个特征向量会损失像素的空间信息并导致歧义的产生。本文引入金字塔池化模块,聚合不同尺度子池化特征,获取更加有效的全局场景上下文信息,提高语义分割模型的性能。
2.5 损失函数设计
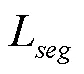
3 模型搭建与训练
3.1 试验平台
试验平台采用台式计算机,CPU 型号为 Intel Core i7 8700,16 GB内存,500 G固态硬盘,NVIDA GTX2070显卡,8 G显存;基于Windows10操作系统,采用Python语言在Tensor Flow深度学习框架下进行编程,统一计算设备架构选择CUDA 10,深度神经网络加速库版本为CUDNN V10.0。
3.2 模型训练及参数设置
本文模型训练分为2个阶段,第1阶段对MobilnetV2增加混合扩张卷积与通道注意力模块构成特征提取网络,部署在ImageNet数据集上进行预训练。ImageNet数据集包括135万张图像,涵盖1 000个类别对象是图像分类网络常采用的训练集。为提高训练速度和效率,将数据图像转换为TFRecord格式,TFRecord文件的每个字段记录了图像名称、维度、编码数据和标签定义等信息。训练时网络参数采用均值为0、标准差为0.01的高斯分布进行随机初始化,权重衰减系数为0.000 5,BatchSize设置为32,初始学习率为0.025,动量因子为0.9。为使模型训练尽快进入到稳定的学习状态,训练开始阶段进行学习率热身,在前1 000个Batch训练时学习率由0线性增加到0.025,随后学习率随着迭代次数的增加采用分段常数方式衰减。
第2阶段将预训练的特征提取网络去掉平均池化层和分类层,加入金字塔池化网络与像素预测分类网络,冻结特征提取网络前4个阶段卷积层,初始化新增加网络参数。基于道路图像训练集采用批量随机梯度下降法训练,设置BatchSize为8,动量因子为0.9,学习率为0.001,衰减系数为0.8,训练周期数为50,每个epoch迭代次数为2 322;迭代完成后解冻特征提取网络前4个阶段,对整个模型进行全部训练,学习率为0.000 1,衰减系数为0.5,训练周期数为50。训练过程中每经过2个epoch衰减一次并保存模型,以避免长时间训练过程中出现断电、异常退出等情况导致训练模型出现损失。模型冻结训练策略运用了迁移学习的思想,先冻结预训练网络部分阶段,能够使模型共享底层结构权值参数,克服不同数据集的差异性;然后解冻剩余阶段对整个模型全部训练,可以使训练损失收敛于较小的值。图5为语义分割模型训练集与验证集损失曲线。
图5中前50个周期冻结部分网络单元,通过较大的学习率对深层网络训练,训练集和验证集损失迅速下降;后50 个周期解冻剩余特征提取网络,利用较小学习率训练整个模型,训练损失与验证损失缓慢下降,最后收敛于0.1附近。整个训练过程中训练损失与验证损失同时收敛,没有出现发散或者停滞的情况,表明模型网络结构设计的有效性。
3.3 评价指标
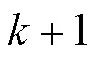
2)像素准确率PA(Pixel Accuracy):正确预测像素数量与图像像素总量的比值,计算公式为
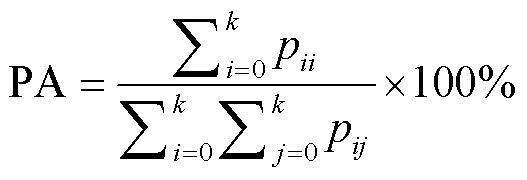
3)平均像素准确率MPA(Mean Pixel Accuracy):每类正确预测像素数量与此类别全部像素数量的比值,然后求取所有类别平均值,计算公式为
4)平均区域重合度MIoU(Mean Intersection over Union):每类预测像素数量与真实像素数量交集与并集比值,然后取所有类别的平均值。平均区域重合度反映了预测结果与图像真实结果的重合程度,是语义分割模型常采用的准确率度量标准,计算公式为
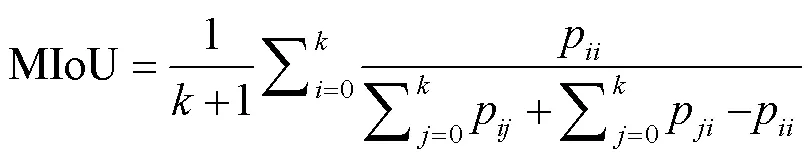
4 结果与分析
4.1 模型有效性验证
为测试本文语义分割模型的有效性,设计消融试验分析各功能模块对模型性能的影响。构建基础语义分割模型(由MobileNetV2网络、常规扩张卷积、上采样单元构成),在此基础上逐步加入混合扩张卷积、通道注意力模块、空间金字塔池化模块构成扩展模型,通过单类别像素准确率、像素准确率、平均像素准确率、检测速度、参数数量对模型性能进行分析。表1和表2为测试集在各版本模型上运行结果。
由表1可知,道路、天空、建筑、植被、土壤、水域等对象具有明显的纹理、颜色、形状特征,识别准确率较高;车辆、行人属于动态障碍物,距离远近、运动方向都会对分割效果产生影响,准确率较前几类对象偏低;地面覆盖物在不同季节和不同环境下外观形态变化较大,特征信息复杂多样导致准确率较低;线杆在图像中面积区域较小,经过多次下采样操作后,特征图的分辨率不断降低,部分像素的空间位置信息丢失,通过上采样法难以完全恢复,容易产生分割不完整或者目标丢失的情况,因此识别准确率最低。
由表2可知,采用HDC代替普通扩张卷积使模型的PA与MAP提升到89.82%、85.68%,表明HDC通过增加感受野并保存更多的像素空间位置,能够提高像素预测体系结构性能;通道注意力模块使模型的PA与MAP达到92.46%、88.72%,表明利用高级阶段强语义信息指导低级阶段获取有效的判别特征,能够增强类内预测一致性并提升模型的分割效果;金字塔池化模块通过聚合不同区域信息使模型拥有获取全局上下文的能力,从而产生高质量的像素级别预测结果,模型的PA与MAP最终达到94.85%、90.38%。不过,随着功能模块的加入,分割模型包含的参数不断增加,检测速度逐渐降低。其中,基础模型的参数数量最小,检测速度最快,HDC模块的加入使基础模型参数量增加5.35%,检测速度降低10.70%;CAB 模块的增加使包含HDC模块的模型参数量增加39.28%,检测速度降低22.25%;PPM模块的融合使具有HDC+CAB模块的模型参数量增加54.48%,运行速度降低31.41%。基于上述数据定性分析,可以得出HDC模块对模型的运行效率和计算开销影响最小,CAB模块次之,PPM模块影响最大。图6为模型在不同环境条件下田间道路场景分割效果图。
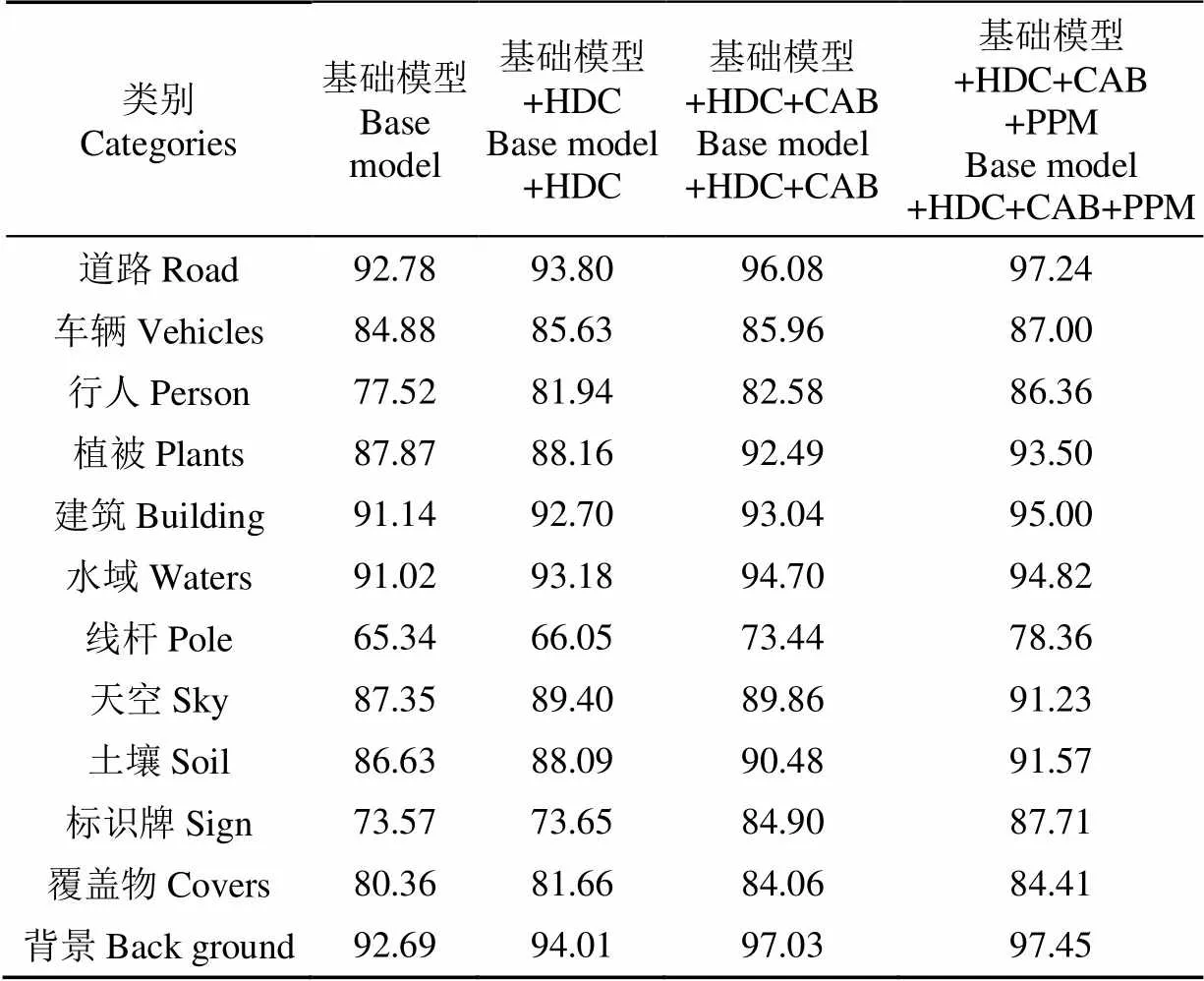
表1 不同功能单元配置的语义分割模型单类别像素准确率
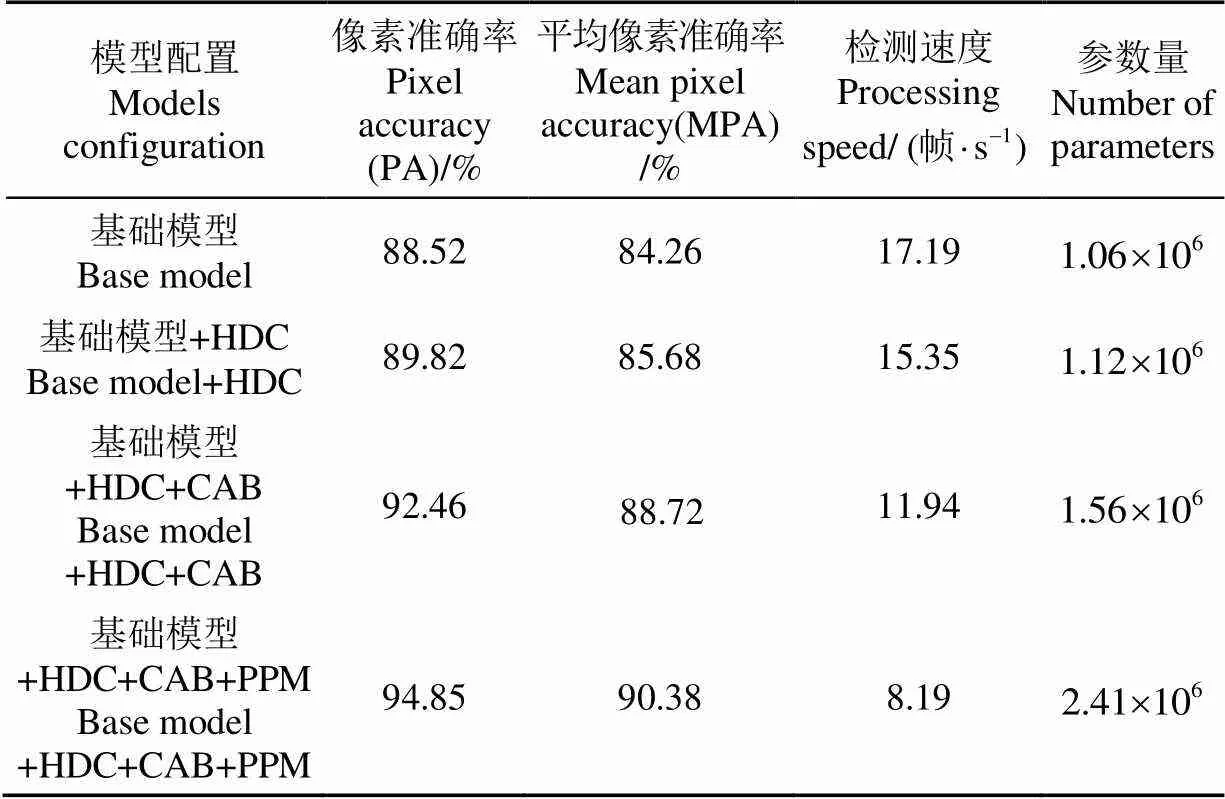
表2 不同功能单元配置的语义分割模型性能
由图6可以看出,硬质化土路图像中的道路、天空、植被、土壤、河流等类别被有效分割,部分线杆由于距离较远以及面积较小出现漏分割与分割不连续的情况;沥青道路图像中,土壤潮湿且部分区域覆盖积雪,植被枯萎呈棕褐色与土壤颜色接近,道路曲率变化范围大,部分道路边缘与泥土交叠导致边缘像素颜色模糊,这些复杂环境因素容易对分割造成不良影响,但从语义分割预测结果可以看出各类别对象被准确地分割出来,对象交界边缘连续,分割效果精细,说明本文模型具有较高的鲁棒性;水泥道路图像中,道路没有受到散落泥土的影响,路面分割完整,具有较好的抗干扰性;行人道路图像中行人、自行车、道路、天空、植被、土壤等类别被有效识别,道路尽头的建筑物(暖棚)分割完整,可以准确反映出建筑物区域。车辆道路图像中,汽车分割清晰,远处的绿色苫布被预测为背景而没有错误的分割为植被,说明本文模型具有较好的泛化性能。
4.2 模型性能对比
选择FCN-8S、SegNet、DeeplabV3+、BiseNet等模型与本文模型进行对比测试,通过平均像素准确率、平均区域重合度、检测速度、参数数量等指标对模型性能做出评价。上述模型分别基于田间道路训练集进行训练,在测试集上计算相关度量指标。表3为不同语义分割模型性能参数对比。
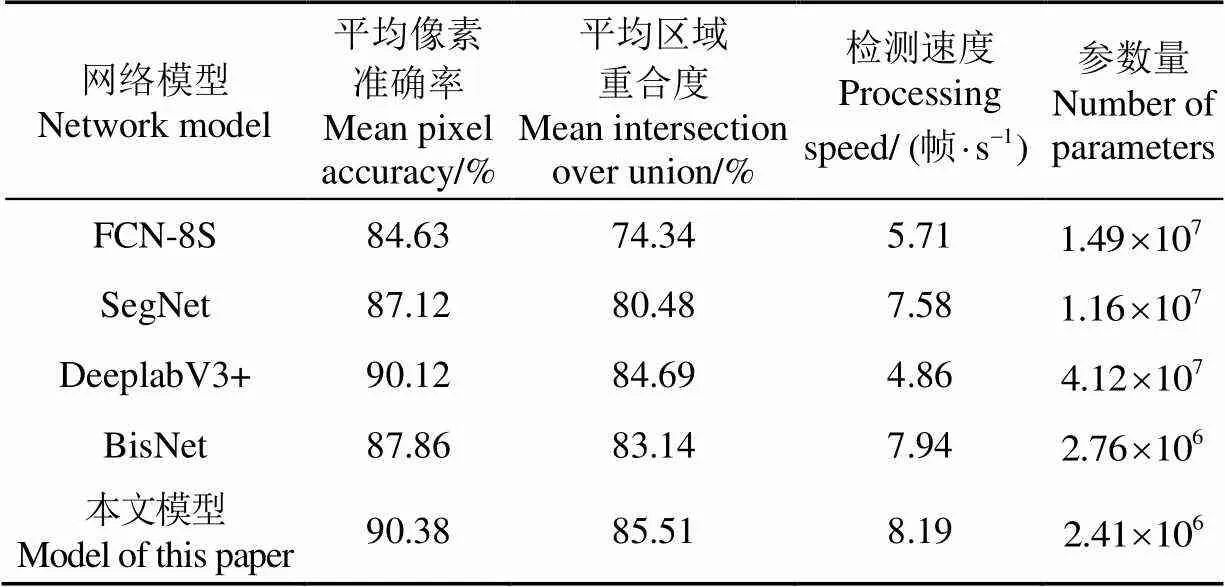
表3 不同网络模型性能对比
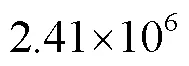
从图7中看出,本文模型可以完整、精细、准确的对道路场景中的语义对象进行分割解析;FCN-8S由于采用池化层下采样导致部分细节信息丢失,对小物体分割效果不佳,如图7第1行场景中“线杆”对象和第3行路面“水洼”对象没有被分割识别;此外图7第2行场景中的车辆之间的路面区域被错误分类为“车辆”对象。SegNet模型存在对象边界分割不连续、分割结果粗糙的情况,如图7第2行场景中“道路”与“土壤”对象交界边缘不连续,第5行场景中部分被树木包围的建筑区域错误分割为植被,产生以上情况的原因是SegNet分割过程未能有效考虑图像上下文信息并且存在类内预测不一致性导致。DeeplabV3+模型具有良好的分割准确性,在效果上与本文模型接近;BiseNet模型由于空间路径网络与上下文路径网络缺少扩张卷积运算,难以实现特征图高分辨率与大感受野之间的平衡,导致部分场景分割效果粗糙,如图7第2行道路和天空的一些区域被误分割为背景。
5 结 论
1)设计基于编码器-解码器结构的语义分割框架模型,编码器单元由轻量特征提取网络、混合扩张卷积、通道注意力模块、金字塔池化模块构成,用于图像特征提取与融合;解码器单元对编码器输出信息上采样,经过卷积运算、像素分类运算得到分割预测图。
2)采集不同道路场景图像建立数据集,根据道路环境中对象的动、静态属性划分为12种语义类别。
针对不同环境条件下田间道路图像进行测试,试验结果表明模型的像素准确率和平均像素准确率分别为94.85%、90.38%,对道路、植被、建筑、水域、天空、土壤等语义对象的分割准确率达到90%以上,具有准确率高、鲁棒性强、泛化性能好的特点。
[1] 王泽尤,严铠,任志雨,等. 农业技术进步和农村劳动力转移对农民增收的影响[J]. 农业展望,2020,16(9):20-26.
Wang Zeyou, Yan Kai, Ren Zhiyu, et al. Impacts of agricultural technology progress and rural labor force transfer on farmers' income[J]. Agricultural Outlook, 2020, 16(9): 20-26. (in Chinese with English abstract)
[2] 刘成良,林洪振,李彦明,等. 农业装备智能控制技术研究现状与发展趋势分析[J]. 农业机械学报,2020,51(1):1-18.
Liu Chengliang, Lin Hongzhen, Li Yanming, et al. Analysis on status and development trend of intelligent control technology for agricultural equipment[J]. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51(1): 1-18. (in Chinese with English abstract)
[3] Chattha H S, Zaman Q U, Chang Y K, et al. Variable rate spreader for real-time spot-application of granular fertilizer in wild blueberry[J]. Computers and Electronics in Agriculture, 2014, 100: 70-78.
[4] Onishi Y, Yoshida T, Kurita H, et al. An automated fruit harvesting robot by using deep learning[C]// Tokyo: The Proceedings of JSME annual Conference on Robotics and Mechatronics (Robomec), 2018: 6-13.
[5] 陈建国,李彦明,覃程锦,等. 小麦播种量电容法检测系统设计与试验[J]. 农业工程学报,2018,34(18):51-58.
Chen Jianguo, Li Yanming, Qin Chengjin, et al. Design and test of capacitive detection system for wheat seeding quantity[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(18): 51-58. (in Chinese with English abstract)
[6] 孟庆宽,张漫,杨晓霞,等. 基于轻量卷积结合特征信息融合的玉米幼苗与杂草识别[J]. 农业机械学报,2020,51(12):238-245,303.
Meng Qingkuan, Zhang Man, Yang Xiaoxia, et al. Recognition of maize seedling and weed based on light weight convolution and feature fusion[J]. Transactions of the Chinese Society for Agricultural Machinery, 2020, 51(12): 238-245, 303. (in Chinese with English abstract)
[7] 张漫,季宇寒,李世超,等. 农业机械导航技术研究进展[J].农业机械学报,2020,51(4):1-18.
Zhang Man, Ji Yuhan, Li Shichao, et al. Research progress of agricultural machinery navigation technology[J]. Transactions of the Chinese Society for Agricultural Machinery, 2020,51(4): 1-18. (in Chinese with English abstract)
[8] 王荣本,李琳辉,郭烈,等。基于立体视觉的越野环境感知技术[J]. 吉林大学学报:工学版,2008,38(3):520-524.
Wang Rongben, Li Linhui, Guo Lie, et al. Stereo vision based cross-country environmental perception technique[J]. Journal of Jilin University: Engineering and Technology Edition, 2008, 38(3): 520-524. (in Chinese with English abstract)
[9] 汪博. 基于机器视觉的农业导航系统[D]. 杭州:浙江理工大学,2016.
Wang Bo. The Agricultural Navigation System Based on Machine Vision[D]. Hangzhou: Zhejiang Sci-Tech University, 2016. (in Chinese with English abstract)
[10] Coombes M, Eaton W, Chen W H. Colour based semantic image segmentation and classification for unmanned ground operations[C]// International Conference on Unmanned Aircraft Systems (ICUAS). Arlington, VA USA, 2016: 858-867.
[11] Scharwachter T, Franke U. Low-level fusion of color, texture and depth for robust road scene understanding[C]// 2015 IEEE In Intelligent Vehicles Symposium (IV), 2015, 599–604.
[12] 陶思然. 顾及梯度和彩色信息的高分辨率影像道路分割[J].科学技术与工程,2019,19(31):263-269.
Tao Siran. Road segmentation of high-spatial resolution remote sensing images by considering gradient and color information[J]. Science Technology and Engineering, 2019, 19(31): 263-269. (in Chinese with English abstract)
[13] Duong L T, Nguyen P T, Sipio C D, et al. Automated fruit recognition using EfficientNet and MixNet[J]. Computers and Electronics in Agriculture, 2020, 171: 105326.
[14] Jiang H, Zhang C, Qiao Y, et al. CNN feature based graph convolutional network for weed and crop recognition in smart farming[J]. Computers and Electronics in Agriculture, 2020, 174: 105450.
[15] Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolutional encoder-decoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(12): 2481-2495.
[16] 轩永仓. 基于全卷积神经网络的大田复杂场景图像的语义分割研究[D]. 杨凌:西北农林科技大学,2017.
Xuan Yongcang. Research on the Semantic Segmentation of Complex Scene Image of Field Based on Fully Convolutional Networks[D]. Yangling: Northwest A&F University, 2017. (in Chinese with English abstract)
[17] 李云伍,徐俊杰,刘得雄,等. 基于改进空洞卷积神经网络的丘陵山区田间道路场景识别[J]. 农业工程学报,2019,35(7):150-159.
Li Yunwu, Xu Junjie, Liu Dexiong, et al. Field road scene recognition in hilly regions based on improved dilated convolutional networks[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2019, 35(7): 150-159. (in Chinese with English abstract)
[18] 张凯航,冀杰,蒋骆,等. 基于SegNet的非结构道路可行驶区域语义分割[J]. 重庆大学学报,2020,43(3):79-87.
Zhang Kaihang, Ji Jie, Jiang Luo, et al. The semantic segmentation of driving regions on unstructured road based on signet architecture[J]. Journal of Chongqing University, 2020, 43(3): 79-87. (in Chinese with English abstract)
[19] 刘家银. 非结构化环境下自主式地面车辆环境感知关键技术研究[D]. 南京:南京理工大学,2018.
Liu Jiayin. Research on Key Technologies of Autonomous Land Vehicle Perception in Unstructured Environment[D]. Nanjing: Nanjing University of Science and Technology, 2018. (in Chinese with English abstract)
[20] Howard A G, Zhu M, Chen B, et al. MobileNets: Efficient convolutional neural networks for mobile vision applications[Z]. [2020-07-03], https: //arxiv. org/abs/1704. 04861.
[21] Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 4510-4520.
[22] Chen L, Papandreou G, Kokkinos I, et al. DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(4): 834-848.
[23] Wang P, Chen P, Yuan Y, et al. Understanding convolution for semantic segmentation[C]// 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Tahoe, 2018: 1451-1460.
[24] Yu C, Wang J, Peng C, et al. Learning a discriminative feature network for semantic segmentation[C]// 2018 IEEE Conference on Computer Vision and Pattern Recognition(CVPR). Salt Lake, UT, USA, 2018, 1857-1866
[25] Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI, USA, 2017: 6230-6239.
[26] Liu W, Rabinovich A, Berg A C. Parsenet: Looking wider to see better[C]// In International Conference on Learning Representations, 2016.
[27] Jadon S. A survey of loss functions for semantic segmentation[C]//2020 IEEE Conference on Computational Intelligence in Bioinformatics and Computational Biology (CIBCB), 2020: 1-7.
Recognition of unstructured field road scene based on semantic segmentation model
Meng Qingkuan1, Yang Xiaoxia1, Zhang Man2※, Gan Haiou3
(1.,,300222,;2.,,,10083,; 3.,,163319,)
Environmental information perception has been one of the most important technologies in agricultural automatic navigation tasks, such as plant fertilization, crop disease detection, automatic harvesting, and cultivation. Among them, the complex environment of a field road is characterized by the fuzzy road edge, uneven road surface, and irregular shape. It is necessary to accurately and rapidly identify the passable areas and obstacles when the agricultural machinery makes path planning and decision control. In this study, a lightweight semantic segmentation model was proposed to recognize the unstructured roads in fields using a channel attention mechanism combined with the multi-scale features fusion. Some environmental objects were also classified into 12 categories, including building, person, vehicles, sky, waters, plants, road, soil, pole, sign, coverings, and background, according to the static and dynamic properties. Furthermore, a mobile architecture named MobileNetV2 was adopted to obtain the image feature information, in order to reduce the model parameters for a higher reasoning speed. Specifically, an inverted residual structure with lightweight depth-wise convolutions was utilized to filter the features in the intermediate expansion layer. In addition, the last two stages of the backbone network were combined with the Hybrid Dilated Convolution (HDC), aiming to increase the receptive fields and maintain the resolution of the feature map. The hybrid dilated convolution with the dilation rate of 1, 2, and 3 was used to effectively expand the receptive fields, thereby alleviating the “gridding problem” caused by the standard dilated convolution. A Channel Attention Block (CAB) was also introduced to change the weight of each stage feature, in order to enhance the class consistency.The channel attention block was used to strengthen both the higher and lower level features of each stage for a better prediction. In addition, some errors of semantic segmentation were partially or completely attributed to the contextual relationship. A pyramid pooling module was empirically adopted to fuse three scale feature maps for the global contextual prior. There was the global context information in the first image level, where the feature vector was produced by a global average pooling. The pooled representation was then generated for different locations, where the rest pyramid levels separated the feature maps into different sub-regions. As such, the output of different levels in the pyramid module contained the feature maps with varied sizes, followed by up sampling and concatenation to form the final output. The results showed that the objects in the complex roads were effectively segmented with Pixel Accuracy (PA) and Mean Pixel Accuracy (MPA) of 94.85% and 90.38%, respectively. Furthermore, the single category pixel accuracy of some objects was more than 90%, such as road, plants, building, waters, sky, and soil, indicating a higher accuracy, strong robustness, and excellent generalization. An evaluation was also made to verify the efficiency and superiority of the model, where the mean intersection over union (MIoU), segmentation speed, and parameter scale were adopted as the indexes. The FCN-8S, SegNet, DeeplabV3+ and BiseNet networks were also developed on the same training and test datasets. It was found that the MIoU of the model was 85.51%, indicating a higher accuracy than others. The parameter quantity of the model was 2.41×106, smaller than FCN-8S, SegNet, DeeplabV3+, and BiseNet. In terms of an image with a resolution of 512×512 pixels, the reasoning speed of the model reached 8.19 frames per second, indicating an excellent balance between speed and accuracy. Consequently, the lightweight semantic segmentation model was achieved to accurately and rapidly segment the multiple road scenes in the field environment. The finding can provide a strong technical reference for the safe and reliable operation of intelligent agricultural machinery on unstructured roads.
machine vision; semantic segmentation; environmental perception; unstructured field roads; lightweight convolution; attention mechanism; feature fusion
孟庆宽,杨晓霞,张漫,等. 基于语义分割的非结构化田间道路场景识别[J]. 农业工程学报,2021,37(22):152-160.doi:10.11975/j.issn.1002-6819.2021.22.017 http://www.tcsae.org
Meng Qingkuan, Yang Xiaoxia, Zhang Man, et al. Recognition of unstructured field road scene based on semantic segmentation model[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(22): 152-160. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2021.22.017 http://www.tcsae.org
2021-06-01
2021-09-16
国家自然科学基金项目(31571570、62001329);天津市自然科学基金项目(18JCQNJC04500、19JCQNJC01700);天津职业技术师范大学校级预研项目(KJ2009、KYQD1706)
孟庆宽,博士,讲师,研究方向为精细农业和农业信息化技术。Email:373414672@qq.com
张漫,博士,教授,研究方向为农业电气化与自动化。Email:cauzm@cau.edu.cn
10.11975/j.issn.1002-6819.2021.22.017
TP183
A
1002-6819(2021)-22-0152-09
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
长江学术(2016年4期)2016-03-11
CHIP新电脑(2016年3期)2016-03-10
人间(2015年21期)2015-03-11
