
基于FPGA 的油棕检测和硬件加速设计及实现
2021-02-05 18:10柴志雷
计算机与生活 2021年2期
袁 鸣,柴志雷,甘 霖
1.江南大学物联网工程学院物联网技术应用教育部工程研究中心,江苏无锡 214122
2.国家超级计算无锡中心,江苏无锡 214122
3.清华大学计算机科学与技术系,北京 100084
棕榈树是世界上非常重要的经济作物,精准的棕榈树检测和分析对于改善种植、产量估算和精准农业具有非常重要的意义。随着卫星遥感技术的快速发展,高分辨率的遥感图像得到广泛应用,基于高分辨率的遥感图像变得更易获得,包含的信息更多,数据量更大,促进了遥感图像检测的发展[1]。近些年,深度学习的突破推动了图像分析的快速发展,基于卷积神经网络的深度学习在目标检测方面表现出了卓越的性能。
现有的基于卷积神经网络的目标检测技术主要可以分为两大时期,早期的基于深度学习的遥感影像目标检测研究主要使用滑动窗口方法进行候选框的生成,再使用卷积神经网络模型对候选框进行分类,具有典型代表性的算法分别为RCNN(region convolutional neural network)[2]、Fast RCNN[3]、Faster RCNN[4]、Mask RCNN[5]等。后期的研究是基于端到端目标检测算法,具有代表性的算法有YOLO(you only look once)系列[6-8]、SSD(single shot multi-box detector)[9]。此外,对于多尺度的目标检测,虽然目前已经有一些研究,但在有严重的背景杂斑和光照变化高分辨率遥感图像中,待检测的目标的尺寸只有几像素,现有的算法模型还无法对小目标做出高质量的检测。此外为了满足深度学习不断提高的高强度计算能力的需求,大量的数据中心和服务器端都会部署大量的ASIC(application specific integrated circuit)芯片以及高性能GPU(graphics processing unit)加速卡来进行数据处理。但随之而来的能耗等问题,对数据处理平台提出了更高的要求。而兼备低功耗和高性能特点的FPGA(field-programmable gate array)则可以很好地满足该需求,并且其可重构的特点完美契合当前深度学习日新月异的演变速度。
本文以马来西亚种植园油棕榈树检测为例,以鲲云科技的人工智能加速平台为硬件基础,在提高算法准确度的同时设计一套基于其硬件架构的卷积计算引擎。以目前被业界广泛应用的YOLOv3[7]目标检测模型为算法平台,充分挖掘带检测目标的关键特征,进一步加大多尺度特征融合力度。在设计硬件加速器时,充分利用了硬件平台数据并行、通道并行、加速器引擎并行的特点,将卷积计算全方展开。此外,为了减少计算资源的消耗,提出了一种对模型参数进行高效量化的方案。在精度误差只有0.83%的情况下,基于FPGA的模型运行速度可以达到30帧/s,远远高于传统的CPU 平台,能效比是Nvidia 推理段专用加速器P40 的1.2 倍。
本文的贡献如下:
(1)提供了一套基于棕榈树的树木类别、位置和大小的有效的检测分析方法,构造了一个基于遥感影像的不同分辨率下的可供深度学习训练和测试的棕榈树检测的数据集。
(2)在模型改进过程中,取消了特征提取网络早期下采样操作,以增强特征提取网络对图片的关键部位的局部纹理信息敏感度。其次,由于网络低层特征具备高分辨率以及高层特征具备高语义的相关特性,采用了加大上采样的力度进而融合不同层的特征。
(3)设计了一个基于FPGA 的高效卷积计算核心,以向量化并行运算的方式完成网络模型所有层的推理计算。充分考虑神经网络模型中权重在数值精度上的鲁棒性,采用了整形8 位的量化方法,降低了网络模型对存储资源的消耗。此外,改进了加速器架构中的输入和输出模块,有效提高了总线带宽的实际利用率。
1 相关工作
基于复杂环境下的遥感影像的物体检测,Chen等人[10]提出了一种基于高分辨率遥感影像的车辆检测方法,该方法采用滑动窗口和混合卷积神经网络,通过将最终卷积层和合并层划分为多个阈值块的变量来提取可变尺度的特征;Han 等人[11]提出了一种基于Faster R-CNN[4]的高分辨率遥感图像目标检测框架,该方法通过使用预训练、迁移学习策略和区域提议来共享特征提取层,极大地提高了效率;Long 等人[12]提出了一个新的目标定位框架,它由三个过程组成:区域建议、分类和目标精确定位。同时,他们提出了一种无监督的基于评分的边界回归算法,以提高定位精度;Deng 等人[13]提出了一种增强的深度卷积神经网络,用于遥感图像中的密集物体检测,由于Faster R-CNN[4]对密集对象的检测效果较差,Tang 等人[14]首次将YOLOv2[8]模型应用于无人机图像车辆识别,他们提出了新的数据标记方法,如CSK 跟踪等并通过数据增强提高了模型的泛化能力。
而基于FPGA 的卷积神经网络加速已有很多研究。Zhang 等人[15]通过SIMD(single instruction multiple data)将输入和输出特征图数目进行二维展开,并且对加速器设计空间进行有针对性的探索实验,提出了一种采用Roofline 的策略。Vinieris 等人提出fpgaConvNet:对给定CNN 模型网络结构进行分析,将其映射到FPGA 上。亮点在于,第一次提出将FPGA 的动态可重构和CNN 加速器相结合的可能性。虽然每次都对整片FPGA 重构,极大地增加了重构时延,但对于结合FPGA 动态可重构特性与神经网络加速器的研究仍具有重大意义[16-17]。Han 等人提出一种对神经网络进行压缩编码的方式,对全连接层进行加速设计,和Titan X 相比,在性能和能效上分别是其13倍和3 400倍[18]。现有的工作均从单一的角度考虑,而从硬件角度去探索算法改进的工作相对很少。
2 基于改进YOLOv3 网络的油棕目标检测
2.1 研究区域及数据集简介
本实验中选取马来西亚南部作为研究区域,如图1 所示,使用Quick Bird 高分辨率卫星影像作为研究数据,构建了一套完整的深度学习训练和测试棕榈树数据集。
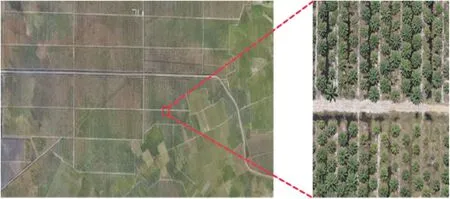
Fig.1 Presentation of research samples图1 研究样本展示
对于面向大尺度卫星影像的油棕识别,首先构造了一个基于遥感影像的不同分辨率下的可供深度学习训练和测试的棕榈树检测的数据集。其次,使用图像上采样和有重叠划分方法,避免了部分油棕树冠被划分到不同的子图像中,无法被正确识别出来的现象。为了保证图像数据集和训练数据集中的样本图像分辨率一致,实验中使用和训练区域相同的双线性插值方法,将完整的卫星影像放大4×4 倍。接着,采用有重叠划分的方法,将放大后的卫星影像划分为500×500 像素的子图像。最终在实验中,选择100 像素作为图像数据集的相邻子图像重叠区域的宽度,保证放大4×4倍后的每棵油棕都能被完整包括在至少一个子图像上。相应地,为了避免有重叠划分造成的油棕重复检测问题,在得到每个子图像的预测油棕坐标后,采用了基于最小距离滤波的后处理策略。
2.2 YOLOv3 网络
YOLOv3 是一种高效的单阶段目标检测模型,通过在YOLOv1 和YOLOv2 的基础上进行一系列的改进以及借鉴特征金字塔网络模型的特点,获得更高的目标检测准确率和更快的检测速度。YOLOv3模型的基础网络为DarkNet-53,采用全卷积网络结构并引入残差结构。与特征金字塔网络类似,YOLOv3 模型对不同层得到的不同尺度的特征图进行上采样和特征图融合,在得到的不同尺度的特征图上进行目标检测,从而可以极大提升对小目标的检测效果。
YOLOv3 继续沿用上一版本YOLOv2 中的Kmeans 聚类的方式来做Anchor Box 的初始化,而这种典型的先验知识对于目标边界框的预选有着很大的帮助。因此,YOLOv3 在COCO 数据集上,首先设定输入图像的尺寸为416×416,之后可以得到9 种不同的聚类尺寸,分别为(10×13),(16×30),(33×23),(30×61),(62×45),(59×119),(116×90),(156×198),(373×326)。而卷积神经网络在每一个单元格上会为每一个边界框预测4 个值,即坐标x,y与目标的宽w和高h,分别记为tx、ty、tw、th。若目标中心在单元格中相对于图像左上角有偏移为cx、cy,并且锚点框具有高度和宽度为pw、ph,则修正后的边界框为bx、by、bw、bh。

在训练过程中,使用二元交叉熵损失(binary cross-entropy loss)作为损失函数(loss function)来训练类别预测,而YOLOv1 和YOLOv2 均采用了基于平方和的损失函数。YOLOv3 网络中使用逻辑回归来精准预测锚点框中是否包含待测物体的概率,使用端到端目标检测中常用的交并比为评价方式,如果锚点框与真实目标边界框的重叠率大于任何其他锚点框,则这个锚点框的概率为1;而如果锚点框与真实目标的边界框的重叠率大于0.5,却并非最大值,则模型会忽视该预测。
2.3 基础特征网络改进
与计算机视觉领域的目标检测问题相比,本研究中的油棕目标面积相对较小,在0.6 m 分辨率的影像上仅有17×17 像素,于此同时,COCO 数据集上小目标尺寸大致在100×100 像素。因此,在本研究中,需要一个更为精细的特征提取网络,以充分挖掘油棕目标信息。而正如5.4 亿年前,寒武纪生物大爆发的一个主要原因是眼睛的出现。构建一个准确捕捉图像特征的机器之眼,是所有计算机视觉研究人员的共同目标。
对于目标检测任务而言,虽然通过基于图像分类的基础特征网络深度提取目标信息,再经过模型微调,网络性能取得了很大的提升,但仍然存在很多问题。一方面,图像分类和图像目标检测属于深度学习不同领域,两种模型对图片局部信息有着不同的敏感度。图像分类算法倾向于图像特征的平移不变性,因此需要频繁的下采样操作挖掘关键特征。然而,目标检测任务对图片的局部纹理信息敏感度更高,早期大尺度下采样操作极易导致图像关键特征消失,进而影响整个模型的性能。
在研究YOLOv3 中原始特征网络时,实验发现由于传统的基础特征网络多用于图像分类,但在目标检测任务中会折中空间分辨率,导致无法精确定位大物体和识别小物体。以基于Resnet50 的DarkNet-53 为例,在第一个卷积块中,第一层卷积操作使用了7×7 的卷积核以获取图像特征,而紧接着卷积操作后是一个3×3 的下采样,极易忽略油棕目标的关键特征,造成模型性能上不必要的损失。因此需要对原特征网络进行相应的改进,以实现对油棕目标的空间信息和深度信息的去耦,可以大大减少由于上采样过程中造成的关键信息丢失。
对此,在Voc2012 数据集中,充分考察在基础网络中下采样和第一层下采样对图像特征提取的影响。以YOLOv3 算法为模型平台,以原始基于Resnet50的DarkNet-53 为基础网络,分别测试了在基础网络中的第一个卷积块中,不同数目、不同尺寸的卷积核以及不同的下采样策略和对准确率的影响。
由表1 可知,在第一个卷积块中,在取消第一层的下采样的基础上,以3个3×3的卷积代替第一个7×7的卷积操作获得了最高的模型准确率。此外,如图2所示,用两个残差块替换了两个卷积块,直到网络末尾。每个残余块由两个分支形成。一个分支是步幅为2 的1×1 卷积层,另一分支是步幅为2 的3×3 卷积层和步幅为1 的3×3 卷积层。每个卷积层的输出通道数设置为128,有效地提取棕榈树目标的关键特征信息。
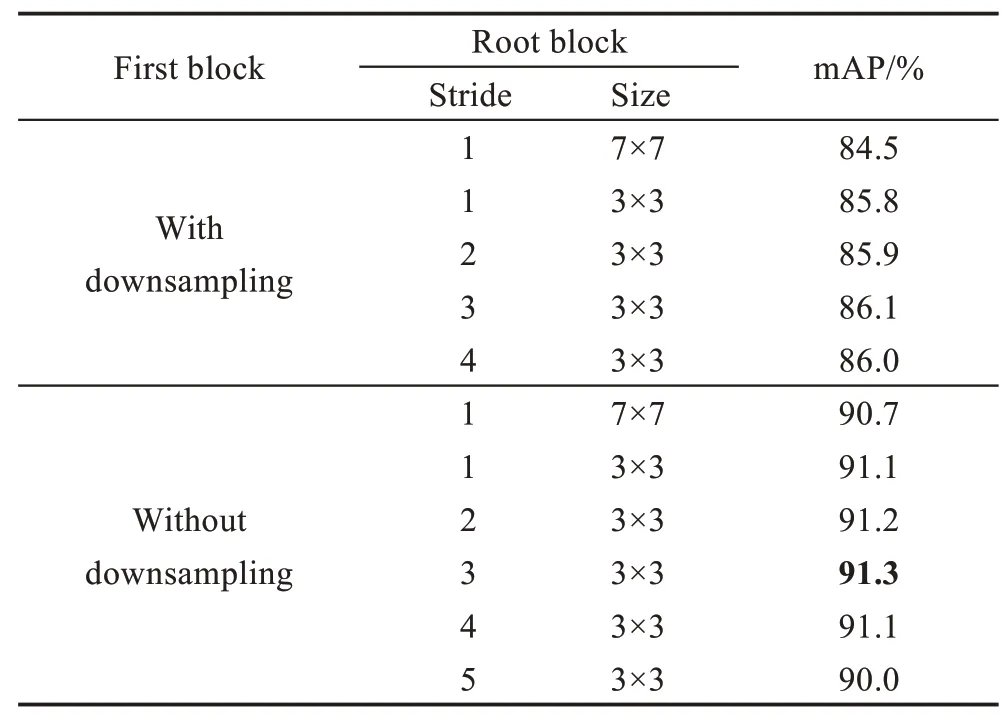
Table 1 Analysis of network performance with different backbones表1 不同基础特征网络性能分析
2.4 多尺度检测改进
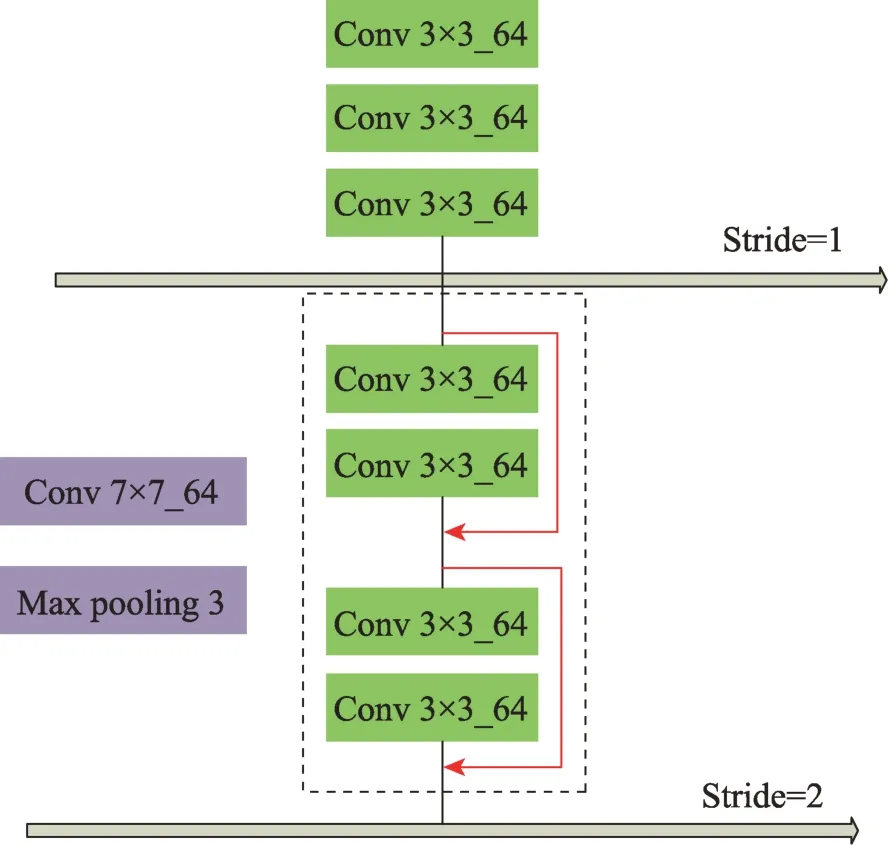
Fig.2 Improvement strategy of backbone图2 基础网络改进策略图
在YOLOv3 网络模型中,引入了FPN(feature pyramid networks)[19]网络算法思想,借鉴特征金字塔网络模型的特点,从而可以获得更高的目标检测准确率和更快的检测速度。首先针对网络低层特征具备高分辨率以及高层特征具备高语义的特性,通过进一步加大上采样的力度进而融合不同层的特征,可以在目标检测时候,在3 个不同尺度的特征层上检测。针对高分辨率遥感图像中的棕榈树目标为密集小目标的情况,对YOLOv3 中的原有的尺度检测模块进行进一步的改进,将原有的3 个尺度检测扩展为4 个尺度检测,因此可以在较大特征图给小目标分配更为准确的锚点框,从而提高准确率。
本文权衡平均交并比与锚点框的数量,取12 个不同的锚点框,分别为(11×15),(15×23),(20×33),(23×42),(22×52),(34×53),(26×64),(38×66),(36×76),(45×88),(55×107),(66×139)。此外,在每个尺度上的每一个单元格借助3 个锚点框预测3 个边界框。随后,对4 个不同尺度的特征提取层使用不同倍数的上采样操作。因此,对于检测层而言,进一步融合了不同层次的特征,也增强了各个尺度特征层的语义信息,对油棕目标的“注意力”更加集中。
如图3 中所示,显示了本文提出的多尺度检测模块。一共有3 种不同的多尺度融合路径,分别由颜色深浅表示。红色连线表示步长为2 的上采样操作,黄色的连线表示步长为4 的上采样操作,而紫色的连线表示步长为8 的上采样操作。
3 基于FPGA 的网络模型加速器设计与实现
3.1 顶层设计
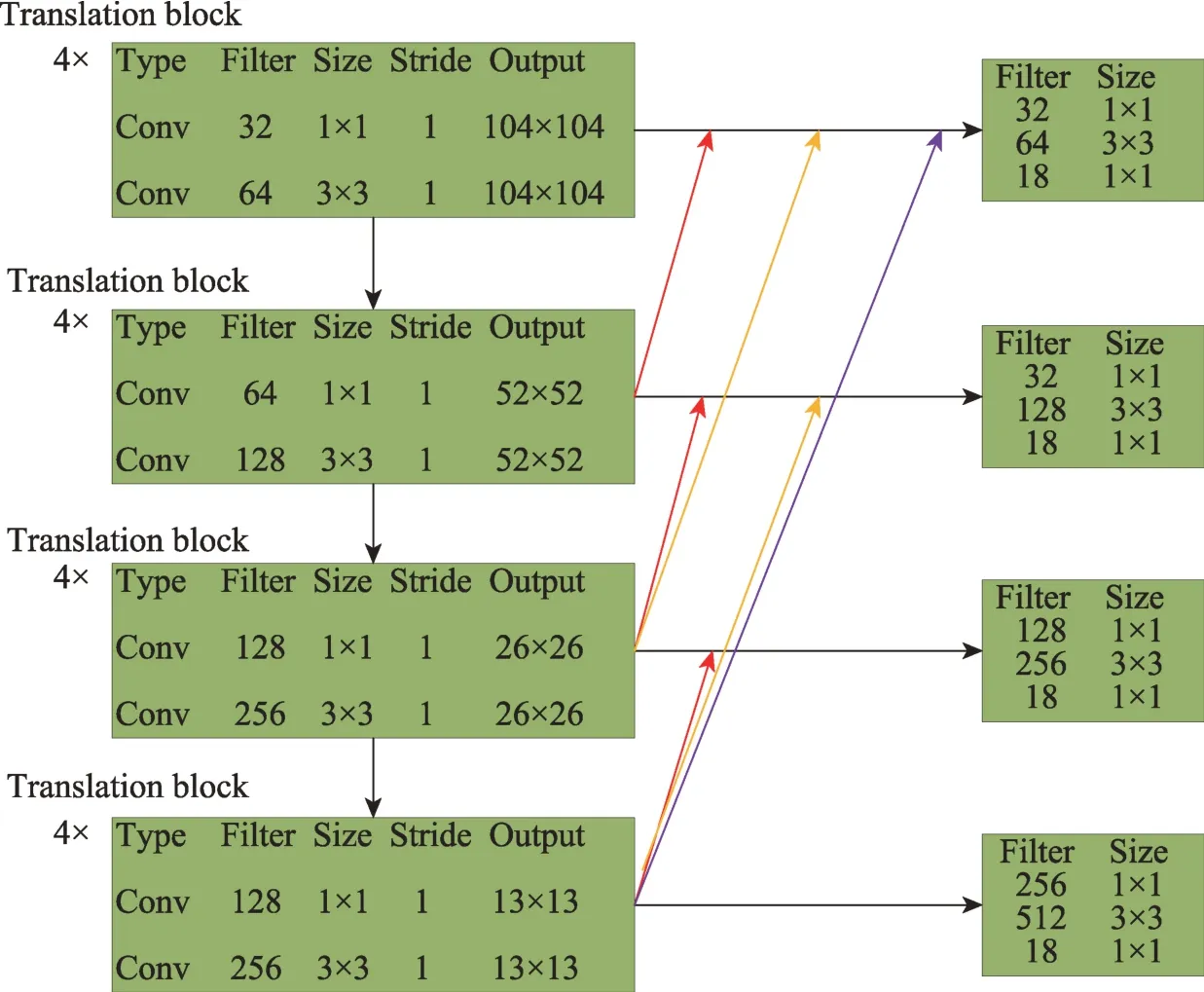
Fig.3 Multi-scale detection strategy图3 多尺度检测改进
在解决了模型准确率的问题后,本文提取出了更加细致的目标特征,而这直接导致计算量的飞速上升,因此本文将注意力放到了算法加速阶段。
图4 展示了基于FPGA 的整体应用流程图。顶层架构上图所示,由宿主机(Host)和FPGA 硬件设备构成了加速器平台,卫星采集到的数据经过处理通过PCIe 接口传输到FPGA 中进行高效处理,而处理后的结果再反传输到宿主机上。对于宿主机端而言,首先开辟所需的存储空间,并且读取外部图像数据文件image 数据,经过维度变化和向量化,以写队列的方式传送给输入模块。其次读取网络模型结构和已量化后模型权重参数,按向量存储,以写队列的方式传送给卷积模块。最后读取DDR 里由特征模块中输出的推理结果,并验证结果。而FPGA 端的功能为实现多个计算模块,以向量化并行运算的方式完成网络模型所有层的推理计算。接下来,将重点介绍权重整形8 位量化和高速计算模块并行化设计。

Fig.4 FPGA-based application flow图4 基于FPGA 的应用流程图
3.2 整数8 位量化模块设计
现有的CNN 模型网络主要的评价标准是基于分类和检测精度,在构建网络模型的时候并没有考虑到模型的复杂度对计算效率的影响,因此即使是目前最先进的卷积神经网络并不适合在移动设备上使用。因此,在有限的设备内存基础上,需要一个较小的网络模型。
而深度神经网络模型在数值精度上有很强的鲁棒性,因此在进行前向计算的过程中,即使使用低精度的数值来取代原本的全精度浮点数,网络模型最终准确率的下降仍然在可接受的范围内。其次,在进行硬件设计的时候,低精度的数值计算单元的资源开销要小于浮点数计算单元,这也就意味着,在相同的面积、功耗的要求下,使用低精度的数值计算单元来进行计算可以开发更高的并行度,进一步提升整个芯片的性能,降低了深度神经网络计算对于存储资源的需求,同时也降低了芯片能耗。综合考虑以上两方面原因,将CNN 模型的权重和偏置矩阵从浮点32 位转移到较低的位数是一个很好的方案。而这方面研究包括三元神经网络[20]、二元神经网络[21]等。
而本文量化的一个基本要求就是能够使用经过量化后的整数计算来代替浮点计算,以实现高效的算术操作,而量化方案将浮点数q映射为整数r。式(2)所示是本文的方案,常数S和Z是量子化参数,常数值S代表的是Scale,是一个任意的正实数。本文的量化方案是为每一个权重数组的所有值使用一组量化参数。

对于神经网络中的每一个激活数组和权重数组都存在一个缓冲区实例,因为有明确的类型传递,所以使用C++语法来描述类型。

而量化过程涉及到模型对于校验数据的推理操作,在推理的过程中,首先需要保证输入数据的有效性,不同的模型有不同的预处理措施,因此需要充分考虑数据集的预处理环节,需要确定提供的预处理方式与原始框架的测试场景一致。当输入图片经过预处理后,图像的值域范围发生了改变,因此需要在推理过程中,也需要对数据集进行量化操作,以用来保证模型的准确度。现在讨论的是如何使用整数算法进行推理,即如何将式(2)由浮点计算转化为整型8 位的量化计算。考虑到在神经网络推理段,图像需要经过预处理和后处理,且这两部分计算量相对不大。考虑到后处理涉及指数计算,而FPGA 实现指数拟合的资源耗费较大,因此对于图像的预处理和后处理两部分,可以放在CPU 端处理。
将规整的矩阵计算放到FPGA 上运行,例如:两个N×N的矩阵分别为r1、r2,即矩阵乘积r3=r1×r2,把每一个矩阵分量rα(α=1,2,3,4) 当作其中1≤i,j≤N。量化参数表示为(Sα,Zα),并且用q(i,j)α来表示浮点量化过程中的项数。因此,式(2)就变成了:

根据矩阵乘法的定义,则:
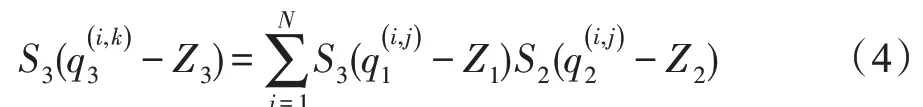
也可以被写成:
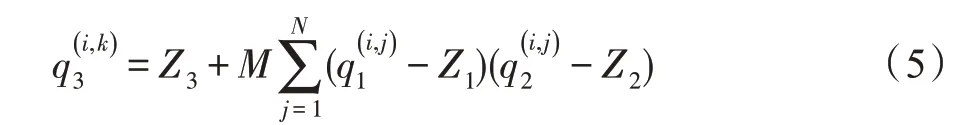
而对于式(5)中唯一的非整数量化因子M而言,其仅仅依赖于量化尺度,故而可以另行计算。而根据经验发现,乘数M大致分布在区间(0,1),因此可以使用标准化的形式来表示它:

其中,M0在区间[0.5,1.0]是非负整数,因此在归一化的过程中,乘法器可以很好地表示为定点乘法器。同时为了有效地对式(5)进行求解,而不需要进行2N次减法以及将乘法的操作数展开为16 位整数。
可以将乘法分配到式(5)中,将问题简化为核心整数矩阵乘法累加,可以将其重写为:
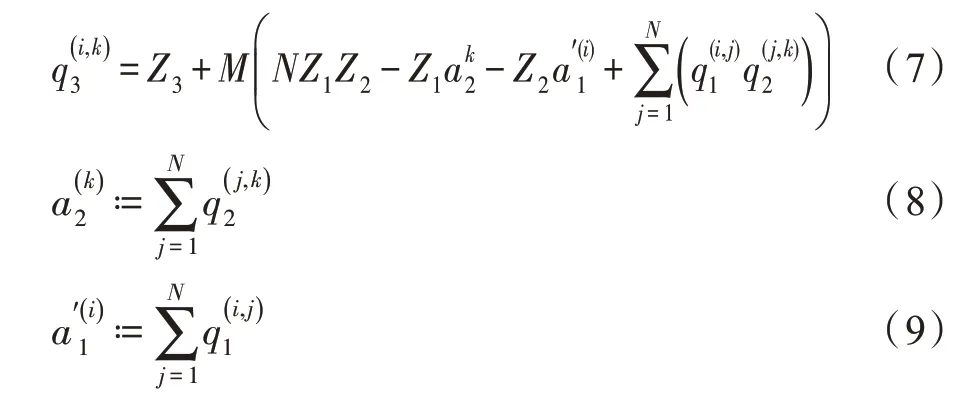
如图5 算法权值量化更新过程图所示,数据量化的本质其实可以理解为用更少的比特数来为原始数据进行粗粒度的编码,一般都是通过一个量化系数和一定的Rounding 规则来完成,根据0 值的位置可以分为对称量化和非对称量化。对于已训练好的模型参数,首先对权值进行分组,将绝对值较大和绝对值较小的权重进行区分,通过式(9),经过5 个过程;其次,依次转化权值到整形8 位,直至转化结束。
3.3 高速计算引擎模块设计
3.3.1 高速并发输入核心设计
由于硬件平台上PCIe 接口读操作和写操作通道之间相互独立,因此无论是读操作还是写操作都可以执行高并发执行。在输入模块设计过程中,首先通过读通道从DDR 读取输入的数据,然后由数据分发(data scatter)模块控制多个独立通道的DMA,从而完成对整个输入特征图像素块的有效读取,并将已经读取到的数据块分发到对应缓存单元[18]。
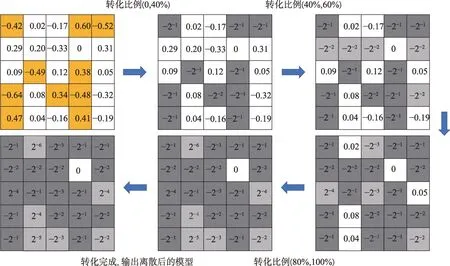
Fig.5 Algorithm weight quantization update process图5 算法权值量化更新过程
而通过数据收集(data gather)模块将输出到缓存单元中的像素块再写回DDR,并且控制多个写操作通道中的DMA,完成对输出特征图像素块的高效写入。当input_reader模块从DDR 中取出宿主机(Host)端存储的feature 数据,使用循环展开的方法,每个循环过程中分别从Width 和Channel 方向取出一个特征图向量,传送给大小为WVector×CVector的向量,在每个流水线的时钟周期会从缓存中,针对每一个输入特征图读入相同位置的像素。而特征图向量化方法及循环方向如图6 所示,在列方向和输入通道方向进行向量化。因此,大小C×H×W特征图包含的向量数量如式(10)所示:
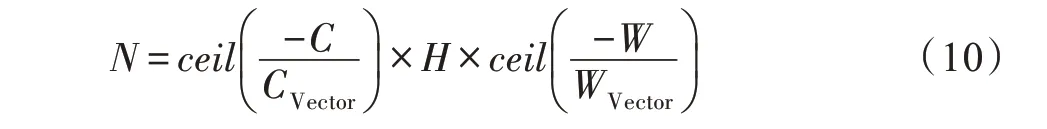

Fig.6 Input reader module vectorization图6 输入模块向量化
与input reader 模块类似,filter 模块向量大小则为卷积核权重向量和通道方向的乘积,即FWVector×CVector,而在每个循环过程中读取一个向量大小的权重并通过输入通道传送给计算单元。除此之外,还把filter 权重的写偏移地址以及通道号通过输入通道一起传送给计算单元。如图7 所示,由于卷积是特征图与数目为NVector个卷积核并行运算,因此卷积核向量可以理解为NVector×FWVector×CVector,总的向量M为:

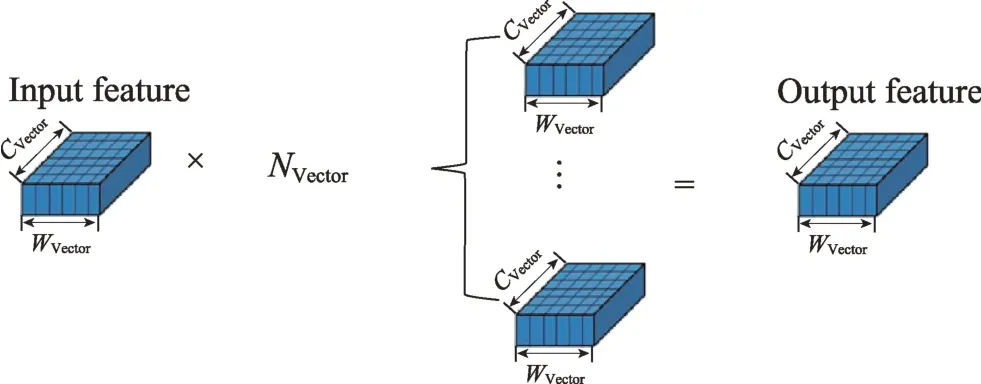
Fig.7 Parallel convolution kernel图7 卷积核并行简图
而为了保证计算核心单元Pipeline 的一致性,从而提高运算效率,因此当卷积核尺寸为1×1 时,每次读取3个输入通道权重,以保证卷积运算的一致性。
3.3.2 高速卷积核心设计
正如第2 章所讲,为了提高算法模型对复杂环境下小目标检测的准确性,需要对图像更加细致地提取特征,而这一策略在硬件上带来的直接后果便是计算量的直线上升,对此设计了具有高并行度的卷积计算引擎。如图8 所示,计算引擎中的计算核包含更多并行运行的卷积计算,它由多个乘法器和一个加法器树组成。计算引擎内核中的输出缓冲区存储部分卷积结果。在每个循环中,来自加法器树的结果将用于更新部分结果。该功能主要是执行不同形状的输入特征向量和系数矩阵的点积操作。
假设系数核的宽度为k,则乘法器的数量为k2,加法器树的深度为lbk2,乘法器从一个行缓冲区中获取输入,即从一个时钟周期内从输入特征映射中读取k个数据,而行缓冲区的另一端连接到一个较大的输入缓冲区,该输入缓冲区部分或全部包含所有的输入特征映射。而乘法器还连接到另一个缓存系数的输入缓冲区。计算引擎内核中的输出缓冲区存储部分卷积特征向量和系数矩阵。计算核包含多个并行乘法器,用于计算共矩阵的每一行与特征向量之间的点积。最后,将处理后的数据写回输出缓冲,待得到最终结果后写回片外。
计算核心模块完成目标检测网络模型中所有层的卷积计算,如图9 所示,根据卷积运算的原理,一个特征图向量与多个卷积核向量做卷积操作,并经过池化层,得到输出特征图向量。而多个并行的计算核心模块的数据输入采用了菊花链的方式,特征图向量与卷积核向量依次流经多个计算核心模块,因此计算核心模块为此开辟了双缓冲,当卷积核向量的序号与当前的计算核心模块的序号相符合时,计算核心模块将此向量进行相依的缓存,最终第n计算核心模块里存储了第n卷积核的全部权重,用于当前批次的计算,并且预读取了下一批次的第n卷积核的权重,从而实现不间断的计算,提高计算效率。
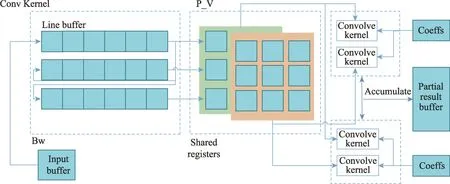
Fig.8 Design of convolution computing unit图8 卷积计算单元设计
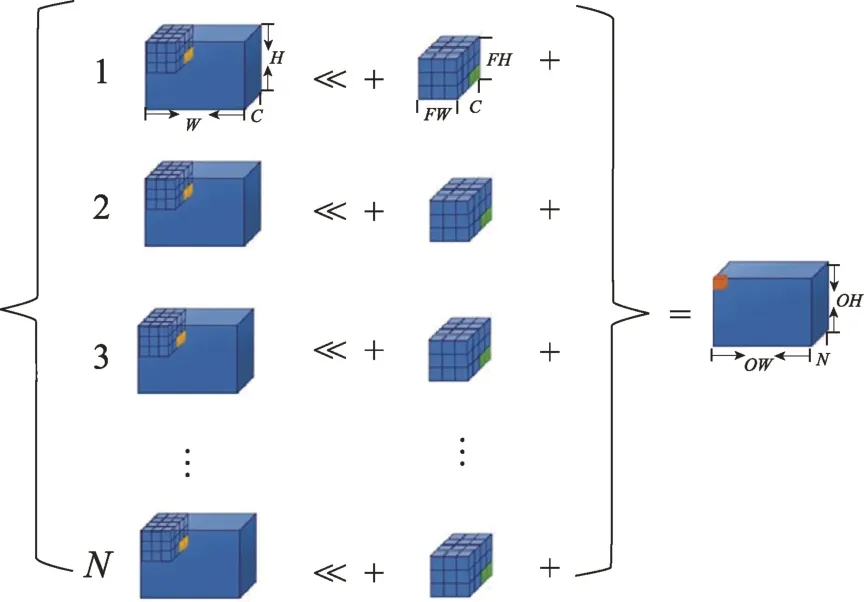
Fig.9 Convolution computing parallel design图9 卷积计算并行设计
计算核心模块完成目标检测网络模型中所有层的卷积计算,如图9 所示,根据卷积运算的原理,一个特征图向量与多个卷积核向量做卷积操作,并经过池化层,得到输出特征图向量。而多个并行的计算核心模块的数据输入采用了菊花链的方式,特征图向量与卷积核向量依次流经多个计算核心模块,因此,计算核心模块为此开辟了双缓冲,当卷积核向量的序号与当前的计算核心模块的序号相符合时,计算核心模块将此向量进行相依的缓存,最终第n计算核心模块里存储了第n卷积核的全部权重,用于当前批次的计算,并且预读取了下一批次的第n卷积核的权重,从而实现不间断的计算。
4 实验结果与分析
4.1 实验计算平台介绍
针对深度学习数据量大,算法复杂度高的特点,选用高性能计算平台来进行本文的研究。在训练端采用了Nvidia V100 平台进行算法高速训练,显卡内存为32 GB,在Tensorflow1.17 环境下,图片输入大小为500×500,批处理大小为64。
为了检测算法性能,在算法推理阶段,本文选取了不同的硬件平台(CPU、GPU)与FPGA 进行对比。CPU 平台选取的Core i9-9990XE 14 核处理器,基本频率为4.0 GHz,GPU 平台选取的Nvidia 最新Pascal架构P40 推理端专用加速器,整数(Int 8)运算力高达47 TOPS。此外,本文选取的星空加速器,采用的是Arria 10 FPGA 板卡芯片,整数(Int 8)运算力相比P40只有1.64 TOPS,主频只有200 MHz。
4.2 目标检测的衡量方式标准及结果分析
目标检测主要从类别、位置和形状大小进行分析和检测,常用的衡量指标主要有真正(TP)、真负(TN)、假正(FP)、假负(FN)、精确率(Precision)、召回率(Recall)。在本节,本文对不同优化策略所得到的油棕识别结果进行比较和分析。
为了严格评估本研究提出的油棕识别网络模型方法的整体表现,由专业的油棕数据标注团队,以人工解译的方式标注了面积为12 188×12 576 像素的整景卫星影像中的所有油棕榈树的准确坐标,经过人工标记得到的油棕坐标总数为281 827。使用端到端目标检测中常用的交并比作为本实验的评价方式,阈值设为0.5。当预测得到的油棕识别框和人工标记的油棕方框的交集面积与并集面积之比大于阈值(0.5)时,认为该油棕被正确识别。

Fig.10 Results of large scale images图10 大尺度检测结果
为了从细节上展示本研究提出的方法在不同区域中的油棕识别结果,从整个研究区域内选择了2 个有代表性的测试区域,将不同方法得到的油棕识别结果和人工标记的结果进行比较。在图10 中用红色正方形框表示,按位置从上到下的顺序编号。红色点表示正确识别出的油棕榈树,绿色框表示没有被正确识别出的油棕榈树,蓝色框表示被错误识别为棕榈树的其他类型的目标。
实验结果如表2 所示,原算法、只改变基础网络、只改变主干网络和本文方法得到的F1 分数依次为92.89%、93.08%、93.97%和94.53%,经过改进后的方法取得最高的F1 分数,原网络方法取得最低的F1 分数。对于四种油棕识别方法,识别精度均高于召回率。从四种方法得到的识别结果图中也可以看出,油棕和其他植被或建筑混淆的情况相对较少,油棕漏检情况需要得到进一步改善。

Table 2 Comparison results of 4 methods表2 4 种方法结果对比
可以总结出,对于本研究面向的基于高分辨率卫星影像的大尺度油棕识别问题而言,经过改进后的YOLO-v3 网络模型在准确率和效率两方面均取得最优的表现,不同改进方法在整个研究区域上取得F1 分数之间相差1%~6%。
于此同时,严格评估算法在各个硬件平台上的性能,其平台性能以及相应的加速对比结果如表3 所示。从运行时间、时间加速比和功耗比三方面分析不同平台的计算性能。在基于FPGA 异构平台上,无论是算法速度还是能效比都远远高于当前最新的i9 CPU 处理器。与14 核的i9-9980XE CPU 相比,加速比达到了7.51。而在数据精度Int 8 的情况下,与Nvidia 最新的推理端GPU P40 加速器相比,算力只有P40 的1/16,在精度只损失不到1%的情况下,运行速度可以达到30 帧/s,能耗比也要优于最新的GPU 板卡,能效比是Nvidia 推理段专用加速器P40 的1.2 倍,在业界处于领先地位。
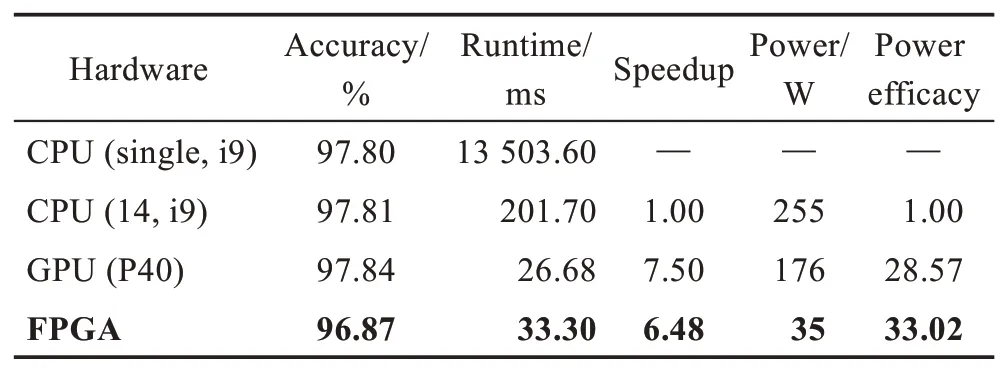
Table 3 Result of different hardware platforms表3 不同硬件平台上的结果
5 结束语
本文针对大尺度密集小目标的精准检测这一问题,从数据集的构造到算法改进再到硬件平台的移植,一站式全面探讨了如何准确高效地应用深度学习方法;实现了一套高效自动的棕榈树树木识别和检测的算法框架,能够对不同位置、不同类别和不同大小的棕榈树进行识别和检测;并且通过不同位置和不同数据上的测试,论证了检测算法的可靠性和鲁棒性。
未来会在不同区域的棕榈树检测上进行模型迁移方面的探索。在基于深度学习的棕榈树识别和检测方面,训练模型所需的数据量一般比较大,因此需要人工标注大量的数据,然而人工标注数据需要耗费大量的时间和精力,大大拖缓了整个训练检测的时间。针对此问题,将探索在不同地域之间的模型迁移性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
热带作物学报(2022年5期)2022-06-01
汽车工程师(2021年12期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
食品界(2019年6期)2019-06-27
读者(2015年9期)2015-05-04
世界热带农业信息(2014年8期)2014-09-23
