
支持隐私保护的社交网络信息传播方法
2021-02-05 18:10谢小杰王梓森李锦涛
计算机与生活 2021年2期
高 昂,梁 英,谢小杰,王梓森,李锦涛
1.中国科学院计算技术研究所,北京 100190
2.中国科学院大学计算机科学与技术学院,北京 100049
3.移动计算与新型终端北京市重点实验室,北京 100190
社交网络作为一种新兴的网络传媒,不仅大大加快了信息传播的速度,也使信息能够更高效和广泛地传播。人们将社交网络广泛应用于推荐系统、病毒式营销、广告投放、专家发现等领域,充分享受信息传播带来的种种益处。然而,信息的快速传播给用户带来许多便利的同时,也造成了隐私泄漏的隐患。
在现有的社交网络中,信息发布者为保护其隐私,可以通过设置仅对指定好友可见等方式来限制能看到信息的对象。但大部分社交平台都提供了转发功能,允许看到信息的对象继续转发该信息,从而造成隐私泄漏。
一些社交平台提供了设置不可见对象的功能,即使信息经过多次转发,对于指定的对象仍不可见。例如,假设A发送了一条信息,B再转发来自A的信息,C再转发来自B的信息,D是B或C的好友,但如果A设置了对象D不可见,那么D也没法通过B或C的转发来看见这条信息。然而,这样的功能并不能完全阻止隐私泄漏的发生。例如,如果B不是直接转发A,而是用自己的语言描述了A发送的信息中的信息后进行发送,假设D是B或者某个转发B信息的人的好友,那么D就能够看到这条信息,从而获取A的隐私,在本文中将这种行为称为转述。可见,在社交网络中用户的转发和转述行为都有可能造成隐私泄漏,而且通过转述行为造成的隐私泄漏很难被发现或阻止。
当前对社交网络的研究主要集中于影响力最大化和隐私保护,然而,现有影响力传播相关的研究没有考虑用户的隐私保护需求,隐私保护相关的研究没有关注用户的影响力;同时,现有的信息传播模型很难有效建模社交网络中隐私泄漏传播过程。这为社交网络的研究带来了三点挑战:(1)如何保障用户的个性化隐私保护需求;(2)如何最大化用户发布的信息的影响力;(3)如何平衡隐私保护和信息传播的矛盾。
例如,用户在社交网络上发布信息或推荐系统推送信息时,如何选择相关用户(种子节点)推送信息,使得所发布的信息通过社交网络传播能让更多的人看到(影响力最大化),同时不被黑名单用户捕捉;同样,通过病毒营销做品牌推荐时,如何选择社交网络中感兴趣的投放用户(种子节点)推送信息,使得传播的人数最多(影响力最大化),且避免传播到非目标用户群体(黑名单用户)。
为了解决上述问题,本文首先以独立级联模型为基础,设计了支持转发行为、转述行为的社交网络信息传播模型,实现对隐私泄漏来源的补充和修正;然后基于社交网络信息传播模型,提出了一种信息传播网络构建方法,实现对转发行为、转述行为融合建模,有效支撑包含转述关系的信息传播机制;最后,基于支持转述行为的信息传播网络,提出了一种支持隐私保护的影响力最大化方法,通过节点泄漏概率上限计算,结合隐私保护约束和启发式影响力最大化算法来选择种子集合,实现在满足隐私保护约束的同时,最大化信息传播的影响力。通过在爬取的新浪微博数据集上进行实验验证和实例分析,结果表明本文方法能够确保在保护用户隐私的情况下,最大化传播影响力。
本文主要贡献包括:
(1)提出了一种支持转述关系的社交网络信息传播模型,针对仅有转发方式激活新节点的社交网络传播模型,增加了模型对转述行为的支持,能够有效建模社交网络中的转发和转述行为,为通过转述行为传播造成的隐私泄漏追踪提供数学模型支持。
(2)提出了一种支持转述行为的信息传播网络构建方法,通过求解用户关注网络的转发边、转述边及无行为的三分类问题,判断网络中用户是否参与传播,预测消息传播到用户时的传播行为概率分布,补充了传统社交网络信息传播途径遗漏问题。
(3)提出了一种支持隐私保护的社交网络信息传播影响力最大化方法LocalGreedy,通过递增策略构造种子集合,计算节点局部影响子图,快速计算种子集合传播产生的影响力,提出节点泄漏态概率上限计算方法,确保种子集合满足隐私保护约束限制,减少了时间开销,平衡了影响力和隐私保护的矛盾。
1 相关工作
当前对社交网络的信息传播和隐私保护的相关研究主要分为四部分,包括:信息传播模型、信息传播预测、影响力传播和社交网络访问控制。
1.1 信息传播模型
典型的应用于社交网络的信息传播模型包括独立级联模型[1]、线性阈值模型[2]和传染病模型[3]。左遥等[4]以独立级联模型为基础,提出了一种用于描述社会化问答网站知识传播过程的传播网络模型,并进一步给出了一种社会化问答网站知识传播网络推断方法。蔡淑琴等[5]基于线性阈值模型和价值共创理论,提出了一种针对负面口碑特征的社会化网络传播及企业价值共创策略的模型,并通过仿真实验,分析了影响负面口碑在社交网络中爆发的主要影响因素。赵剑华等[6]以传统的SIR(susceptible infected recovered)传染病模型为基础,综合考虑用户的心理特征和行为因素,提出了一种新的社交网络舆情传播动力学模型,并选用粒子群算法,以2016 年微博上发生的热点事件为例,求解模型参数的最优解,并进行实验数据验证。线性阈值模型的随机性仅取决于节点被影响阈值的随机性,且在阈值选择上有较大的困难;传染病模型仅适用于对传播过程的宏观描述,但未考虑具体的传播路径;而独立级联模型通过使用边上的概率来描述信息传播的强度或发生的可能性,具有较好的扩展性。因此,独立级联模型将作为本文提出的信息传播模型的基础。
1.2 信息传播预测
信息传播预测是指通过一定的方法学习社交网络中用户的兴趣和行为规律,从而对用户是否会参与某条信息的传播进行预测。按照基本假设的不同,用户信息传播预测的研究可分为4 类:基于用户历史行为的预测、基于用户文本兴趣的预测、基于用户所受群体影响的预测以及基于联合特征学习的预测。Pan 等[7]通过捕捉用户历史行为中与传播相关的特征,结合协同过滤和传播过程的特点建立联合推荐模型,从而预测基于转发行为的信息传播过程。Zhang 等[8]提出了一种结合用户文本、网络结构和时间等信息的传播预测方法,利用非参数统计模型对转发行为进行推断,进而预测信息传播过程。Bian等[9]定义了兴趣导向的影响、社会导向的影响和流行病导向的影响,并基于这三种影响的综合分析来决定用户是否执行转发操作。Luo 等[10]基于联合特征学习,联合考虑转发历史、用户影响力、时间和用户兴趣等因素,在一个学习排名的框架内,研究各因素对转发行为的影响。信息传播预测方法较为丰富,是社交网络信息传播分析的重要组成部分。但是,现有研究往往将转发作为信息传播的唯一方式,而忽略了其他可能的传播行为。
1.3 影响力传播
影响力传播刻画影响力在社交网络中的传播模式,即节点的状态如何影响网络中相邻节点的状态,并将该状态在网络上进行扩散。优化影响力的传播是影响力传播建模的主要目的,而影响力最大化问题是该研究的核心内容,目前的研究方法主要分为三类:根据传播模型的具体特点设计启发式算法;对蒙特卡洛贪心算法进行效率优化;以社区发现作为中间步骤,将影响力问题从用户级别转化到社区级别。启发式算法基于直观或经验构造,旨在有限时间、空间损耗下对影响力最大化问题给出可行解。Jung 等[11]通过综合影响排序、影响估计方法,提高算法运行的鲁棒性及稳定性;Goyal 等[12]通过引入多个优化策略,以在较短运行时间和较低内存使用下保证最大化影响力种子集合质量。由于贪心策略无法在较短时间内迅速处理包含百万量级的大规模网络输入,因此对蒙特卡洛贪心算法的优化常通过降低运行时间[13],或使用基于草图[14]的方法解决影响力最大化问题。影响力问题向社区级别转化的方式从解决启发式算法无法提供性能保证的角度出发,最大化影响力。Shang 等[15]通过预先计算用户社区影响,自顶向下选取种子集合,进而实现影响力最大化;Li等[16]提出了一种基于社区发现的种子选择算法,实现了对最大化问题中种子集合的有效选择。影响力最大化问题未考虑用户的隐私保护需求,但相关研究中的启发式算法相对于其他方法通常有着更快的运行时间和更好的可扩展性,因此本文使用影响力最大化的启发式算法作为基础,提出支持隐私保护的社交网络信息传播方法。
1.4 社交网络访问控制
社交网络中用户的隐私包括个人信息和交流信息,为了保证用户的信息只被用户信任的人访问,需要实现用户节点间的信息访问控制进行隐私保护。Singh 等[17]设计了一种支持高可用性和实时内容传播的集中式社交网络模型,通过学习用户的社交行为来决定用户的隐私。Aiello 等[18]提出了一种基于分布式散列表的在线社交网络架构LotusNet,通过一个灵活细粒度的自主访问控制单元来控制私有资源,使得用户可以更简便地调整他们的隐私设置。然而在实际中,无论是集中式解决方案还是分布式解决方案都不能像预期的那样保护普适社交网络通信。为此,一类由二维信任度进行访问控制的方案被提出[19-20],通过利用信息节点属性计算节点间二维信任度,并根据二维信任度实现对用户隐私的访问控制。但是,现有针对隐私问题的访问控制研究主要通过对用户信息采取受限访问或信任管理措施,忽略了保护用户隐私的同时最大化信息的影响力传播。
综上所述,在已有的信息传播预测研究中,研究者未考虑将转述作为信息传播方式的可能性,这会造成对传播信息进行溯源时传播路径的遗漏,从而在信息传播建模中发生转述行为时,无法捕捉隐私信息的泄漏。在影响力最大化问题研究中,各式算法虽从不同角度探索最大化影响力的最佳方案,却忽略了传播过程中的隐私保护问题。而对于社交网络,用户隐私作为最常见的信息载体,缺少隐私保护措施的影响力传播方案显然难以直接应用于实际环境。虽然现有的社交网络访问控制研究可以应用于用户隐私保护,但是研究者仅关注用户隐私保护问题,忽略了用户影响力需求。因此,本文针对现有信息传播模型不能很好建模用户隐私泄漏产生的原因,以及相关研究难以平衡用户隐私保护和信息传播需求的问题,开展了支持隐私保护的社交网络信息传播方法研究,在支持最大化信息影响力传播的同时保护用户隐私。本文方法的主要应用:
(1)对于个人用户:发布信息时,只需指定黑名单用户,算法就能自动给出信息的推送对象,使得信息不会泄漏到黑名单用户。
(2)对于商家:通过将非目标用户设置为黑名单,可使用算法发现社交网络中哪些用户更有进行广告投放的价值,进行精准推送。
2 支持转述行为的信息传播模型
在用户发布信息后,关注用户的好友是信息的直接接收者,信息通过好友的转发和转述行为进行传播。在现有仅考虑转发行为的传播模型中,用户的黑名单对象仍能通过传播过程中的转述行为获取用户信息。因此,本文的研究问题是构建支持转述行为的传播模型,使得信息在满足隐私保护约束条件下,最大化信息传播的影响力。
研究思路是基于时间相近、位置相邻、内容相似规则推断转述关系,通过好友关系进行消息传播预测,利用转发、转述关系构成消息传播网络,并基于贪心策略计算种子集合获取信息传播范围,最终通过局部影响子图与泄漏概率上限计算使社交网络信息传播过程满足隐私保护约束的同时最大化传播影响力。首先给出本文的概念定义。
2.1 概念定义
2.1.1 基本元素
信息是社交网站中的基本单元,它由社交网络的用户所发布,可能完全公开(对所有人可见),也可能只对部分人可见,表示为M,信息的发布用户表示为User(M)。每条信息有唯一标识符,记作mid。在本文中,信息仅针对用户文本,M和mid间一一对应,对M和mid不作区分,根据上下文不同可以混用。
用户是社交网站的使用者,也是信息发布者。每个用户有唯一标识符,记为uid,并用集合U表示社交网络的用户集合。在本文中,uid和u间一一对应,对uid和u不作区分,根据上下文不同可以混用。
2.1.2 用户行为
当用户在社交网络中发布一条原创信息M时,将该行为记为Actpost。当社交网络中的用户接收到一条信息时,可能会产生不同的行为,这里将其区分为三种类型:
(1)转发(Forward):用户u收到信息后,通过社交网络提供的转发功能来进一步传播该信息,该行为记作Actforward。用Forward(M) 表示信息M的转发信息集合,则M'∈Forward(M)表示信息M'是信息M的转发信息。
(2)转述(Mention):用户u收到信息后,发布了一条新信息,但该新信息与用户u收到的原信息包含相似的信息,该行为记作Actmention。虽然这种行为从形式上是发布了一条全新的信息,但这里将其视为一种对所收到信息进行传播的行为,与Actpost进行区分。用Mention(M)表示信息M的转述信息集合,则M'∈Mention(M)表示信息M'是信息M的转述信息。
(3)无行为(No Action):用户u收到信息后,未以任何形式在社交网络中对该信息进行传播,该行为记作Actno。
定义1(用户行为)社交网络中的用户行为被定义为式(1)的四元组:
其中,uid是触发行为的用户的标识符;acttype是用户行为的类型,其取值范围如式(2);time是用户产生该行为的时间;mid是用户产生行为的信息的标识符,主要有四种情况:
(1)当acttype=Actpost时,mid是用户发布的原创信息的标识符;
(2)当acttype=Actforward时,mid是用户转发后的信息的标识符;
(3)当acttype=Actmention时,mid是用户转述后的信息的标识符;
(4)当acttype=Actno时,mid为空。
例1如图1 所示,以新浪微博为例,用户“_奶啤超好喝的”发布了一条信息(参见图1(a)),接收到信息的用户“p123TAT”可能存在三种行为:转发(参见图1(b))、转述(参见图1(c))和无行为。
2.1.3 用户类型
在社交网络的不同场景中,用户会扮演不同的角色类型,下面分社交关系场景和信息传播场景进行说明:
(1)社交关系场景:在社交关系场景中使用到的用户类型包括两种:关注者、被关注者。关注者(Follower)是关注了用户u的社交网络用户,用Follower(u)表示用户u的关注者集合,Follower(u)⊂U。被关注者(Followee)是被用户u关注的社交网络用户,用Followee(u) 表示被用户u关注的被关注者集合,Followee(u)⊂U。
(2)信息传播场景:用户在信息传播场景中有两种不同的用户类型:影响者和被影响者。假设用户v转发或转述了用户u发布的信息M,则称用户u为影响者,用户v为被影响者。
2.1.4 隐私设置
用户u在社交网络中发布的信息M只会被一部分社交网络用户直接接收到,并显示在其关注者动态中,收到信息M的用户集合记作Viewer(M),Viewer(M)⊂Follower(u),默认情况下Viewer(M)=Follower(u)。
定义2(信息的黑名单)对于信息M,用户对信息设置的黑名单记作Blacklist(M),Blacklist(M)⊂U,黑名单被用作用户的隐私保护。当信息M是原创信息时,Viewer(M)=Follower(u)–Blacklist(M)。对于一个信息转发序列
在不同的应用场景下,隐私有着不同的定义。本文将隐私泄漏对象定义为用户在发布信息时设置的黑名单节点。用户通过设置黑名单实现对隐私的传播控制,对于用户发布的信息M,如果在传播过程中,黑名单节点接收到信息的概率超过用户预先设定的泄漏概率上限,则称隐私发生了泄漏。
2.2 社交网络信息传播模型
2.2.1 信息传播方式
定义3(信息传播网络)信息M的传播网络是一个有向无环图GM:
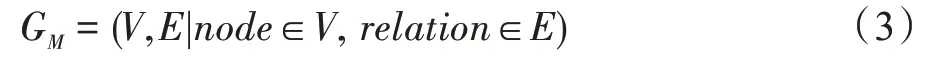
(1)V是网络中所有节点(node)的集合,其中每个node定义如式(4)。
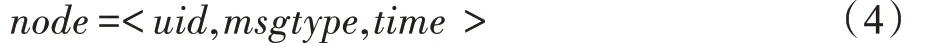
其中,uid是用户标识符;msgtype描述用户在信息传播过程中发布的信息的类型,取值集合为{Equaled,Derived},Equaled 表示用户发布的信息是信息M的等同信息;Derived 表示用户发布的信息是信息M的衍生信息;time表示用户发布信息的时间。
(2)E是网络中所有关系(relation)的集合:图GM中从nodein到nodeout的边代表信息在用户之间的传播方式,定义为:
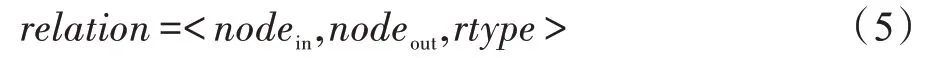
其中,nodein表示传播的上游节点,即影响者;nodeout表示传播的下游节点,即被影响者;rtype表示该关系的类型,rtype∈{Forwarded,Mentioned},Forwarded 代表的是nodeout节点对应信息是nodein节点对应信息的转发,Mentioned 代表的是nodeout节点对应信息是nodein节点对应信息的转述。
2.2.2 传播模型定义
在现实的社交网络中,信息的传播往往不局限于社交网络中的转发功能,还存在着转述关系。转发关系易于追踪和控制,而转述关系难以追踪与控制。而在传统的社交网络传播模型,如独立级联模型[1]中,每条边只对应一个属性,这种局限性使得难以在该模型下区分转发关系和转述关系。因此,为了支持转述行为,本文的社交网络传播模型在独立级联模型的基础上进行扩展,通过引入边的类型以及类型对应的概率分布来描述用户行为,以便更好地研究社交网络下的信息传播和隐私泄漏。
定义4(社交网络传播模型)定义社交网络传播模型为有向图G=(V,E,T,P),其中V表示社交网络中的节点且V=U,eu,v∈E表示社交网络中从节点u指向节点v的有向边,tu,v∈T表示节点u和v间连边的类型,每条边eu,v仅能属于一种类型。其中连边类型与社交网络中用户的动作类型一一对应,Tp对应Actforward,Tq对应Actmention,Tr对应Actno。

Pu,v表示节点u和节点v的连边类型的概率分布,其中u,v∈V。当节点u变为活跃态时,其有且仅有一次机会尝试以Pu,v的概率分布影响节点v。
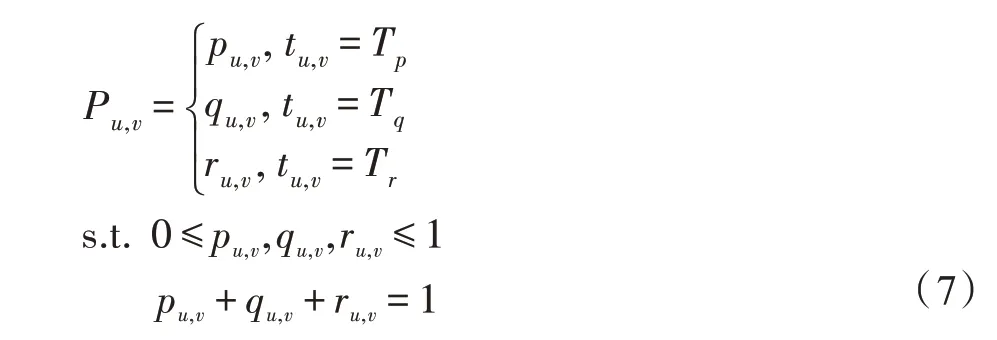
其中,pu,v表示eu,v是一条转发边的概率;qu,v表示eu,v是一条转述边的概率;ru,v表示eu,v是一条普通边(无行为)的概率。
对于一条即将发布的新信息M,基于社交网络信息传播模型,通过用户行为的概率分布对信息传播进行预测,可以确定信息M的传播过程,从而为最大化影响力和隐私保护提供支持。
定义5(泄漏路径)定义R(G,u,v)表示社交网络G上从节点u到节点v的路径集合。对一条路径P=
注意,正常情况下包含转述关系的传播路径无法追踪,定义泄漏路径是为了在传播过程中对包含转述关系的传播路径和只包含转发关系的传播路径进行区分,并不意味着信息发生了泄漏。
在社交网络G中选取一定数量节点构成种子集合S,其中S⊂V,假设存在路径集合使节点v的状态被影响,则影响的方式有两种:
(1)到达:H(G,S,v)中包含传播路径,但不包含泄漏路径,产生概率用P(G,S,v)表示,简写为P(S,v),v被称为到达态节点。
(2)泄漏:H(G,S,v)中包含至少一条泄漏路径,产生概率用Q(G,S,v)表示,简写为Q(S,v),v被称为泄漏态节点。
如定义2 所示,对于到达方式,因为传播路径上只存在转发关系,在信息M的传播过程中,接收用户对信息所设置的黑名单,会并入到信息M的黑名单中,因此信息M即使被多轮转发也不会对黑名单中的用户可见;对于泄漏方式,因为转述关系难以追踪,所以与到达方式相比,确定信息是否泄漏到黑名单节点更加困难。
定义6(影响力)定义IG(S)表示选取S作为社交网络G上信息传播的种子集合时产生的总影响力,其中:
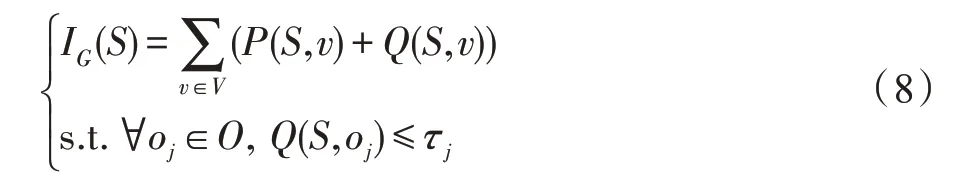
式(8)的约束条件中,O表示社交网络中的关键节点集合,表示黑名单对象,O⊂V。参数τj表示用户希望在选择种子节点集合S时,如果能够保证信息泄漏到节点oj的概率不超过τj,则种子集合S是合法的。O中每个节点都对应一项隐私保护约束,是一种更一般化的黑名单设置。集合F社交网络中的可选节点集合,F⊂V,在实际应用中通常对应信息发布者的关注者集合。需要注意的是,种子集合S必须是集合F的子集,即S⊂F。
影响力通过到达方式获得的影响力与泄漏方式获得的影响力之和计算而得出。在满足隐私保护约束前提下,通过求解种子集合S,使得用户发布的信息在社交网络信息传播模型中获得最大的影响力。隐私保护约束由发布信息的用户设定,包括限制获取信息的黑名单节点oj以及信息泄漏到oj的概率上限τj。黑名单节点的个数等于在影响力最大化计算时的隐私保护约束个数,在每个黑名单节点上,接收信息的概率都不能超过用户预先设定的泄漏概率上限。
例2图2 所示的是基于社交网络传播模型构建的信息传播过程,用户0 为发布信息M的节点,设可选节点集合F={1,2,3},种子集合S={1,2},关键节点集合O={7},信息由种子集合S获取,并传播到了其他节点上。对于路径P1=<2,5> 和P2=<2,5,6>,因为只存在转发边,所以P1和P2是传播路径,节点5 和节点6 是到达态节点;对于路径P3=<1,4>,P4=<1,4,7> 和P5=<2,5,7>,因为存在转发边,所以P3、P4和P5是泄漏路径,节点4 和节点7 是泄漏态节点。在保证信息M传播到黑名单节点7 的概率小于预先设定的上限的情况下,信息M传播的总影响力大小可由传播路径P1、P2和泄漏路径P3、P4和P5的概率和计算得出。
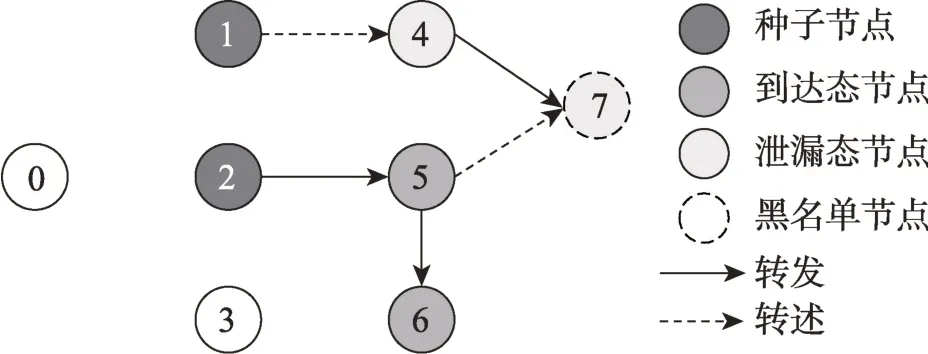
Fig.2 Process of information communication based on model of social network communication图2 基于社交网络传播模型构建的信息传播过程
3 支持转述行为的传播网络构建方法
对于用户即将发布的新信息,为了在满足预先设定的隐私保护约束的同时,最大化信息传播的影响力,需要基于社交网络传播模型,对信息的传播过程进行预测。而社交网络传播模型依赖于用户行为的概率分布,因此需要构建已发布信息的传播网络来训练用户行为分类器,从而获得用户行为的概率分布。构建支持转述行为的信息传播网络的具体步骤为:
(1)对于用户已经发布的信息,通过转述关系推断,构建信息的传播网络,获取三种用户行为:转发、转述和无行为的标注数据。
(2)利用构建好的训练数据,通过提取用户属性、发布内容和网络拓扑结构等特征,训练用户行为分类器。
(3)对于即将发布的新信息,基于用户关注关系网络,结合社交网络信息传播模型,通过用户行为分类器对用户的三种行为转发、转述和无行为的概率分布进行预测,构建信息的传播过程。
一旦确定了信息传播过程,就可以通过选取合适的种子集合,使得经由种子集合传播的信息到达黑名单节点的概率小于泄漏概率上限,在保证隐私保护约束的同时,最大化影响力。
3.1 方法概述
3.1.1 问题定义
构建传播网络的难点在于,从社交网络获取到的用户行为只有Actpost和Actforward两种,而实际上所获取到的全部Actpost(原创发布行为)中有一部分应当属于Actmention(转述行为),与传播网络相关,需要进行区分。
定义7(信息传播网络构建问题)已知一个用户us发布信息M的行为Actions=
定义8(添加节点操作)向传播网络中添加节点的操作定义为Gafter=AddNode(G,nodeold,nodenew,rtype) 。其中G表示操作前的传播网络;Gafter表示操作后的传播网络;rtype表示将要添加的关系,取值集合为{Forwarded,Mentioned};nodeold表示G中的一个节点,将作为新添加关系的影响者;nodenew表示添加的新节点,将作为新添加关系的被影响者。
传播网络构建过程主要通过添加节点操作完成,初始时建立代表用户us发布信息M的节点,之后按照时间顺序将信息所影响的节点加入到网络中。
3.1.2 方法步骤
传播网络构建的主要过程是将信息M发布后其他用户发布的等同信息与衍生信息与之进行关联。对于转发行为列表Lf,列表中的信息包含了其整个转发序列的关系,因此很容易添加到传播网络中。对于发布行为列表Lp,根据定义4,其中的一部分信息是信息M的衍生信息,对应行为类型Actmention,需要添加到传播网络GM中。而另一部分则是其他用户的原创信息,对应行为类型Actpost,与传播网络GM无关。
传播网络构建的基本思路是依据时间顺序,依次尝试将当前Action中的信息与传播网络中的已有节点建立关系。基本步骤如下:
(1)建立传播网络GM的初始节点,
(2)将列表Lf与列表Lp合并后排序得到列表L;
(3)遍历列表L,假设当前遍历到的行为是
(4)如果acttype=Actmention,则为信息M'新建节点nodenew,并更新信息传播网络GM=AddNode(GM,nodeold,nodenew,Forwarded);
(5)如果acttype=Actpost,则为信息M'新建节点nodenew,并更新信息传播网络GM=AddNode(GM,nodeold,nodenew,Mentioned)。
3.2 转述关系推断
社交网络中的用户行为数据中不包含转述行为,需要推断哪些原创信息是其他信息的转述。转述关系的推断基于以下原则:
(1)发布时间相近:两条信息的发布时间间隔较短。
(2)网络位置相邻:转述信息的发布者是原始信息发布者的关注者。
(3)信息内容相似:两条信息的主要内容相似。
对于Actiona=
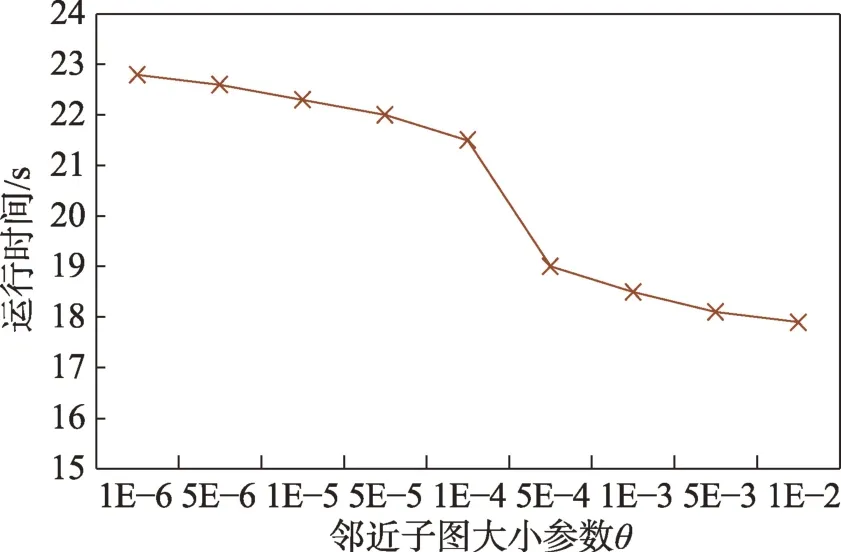
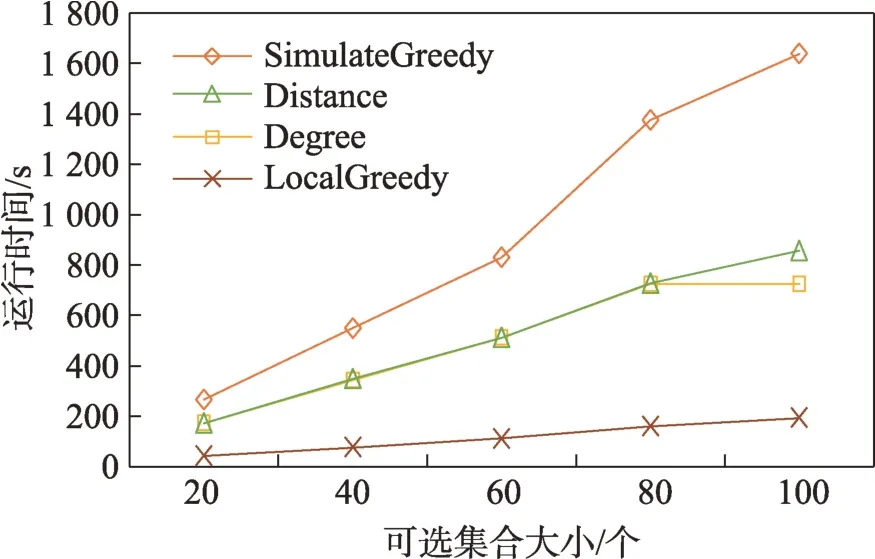
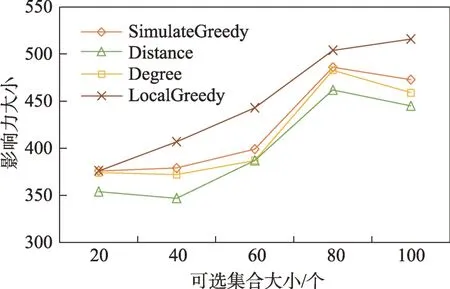
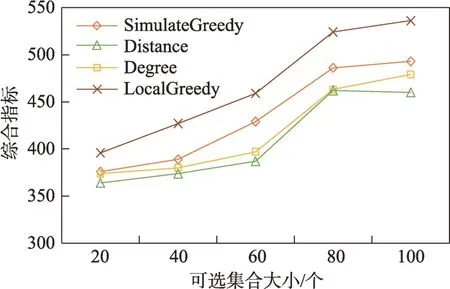
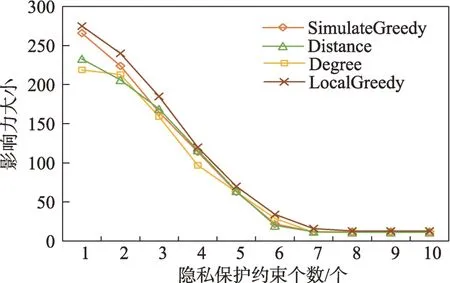
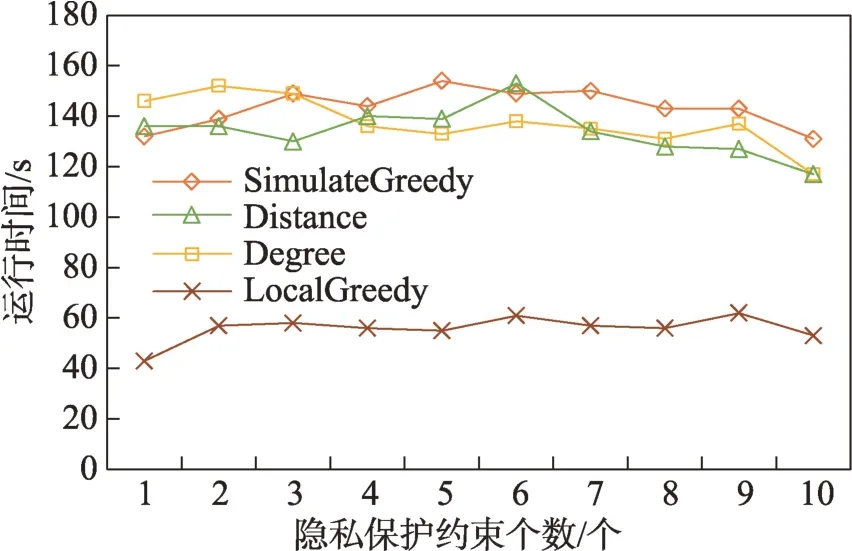
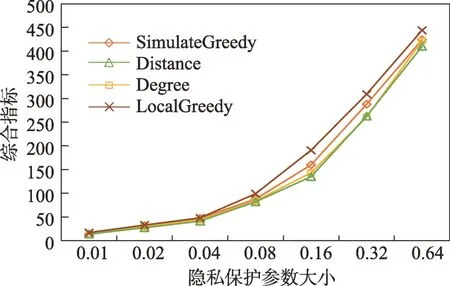
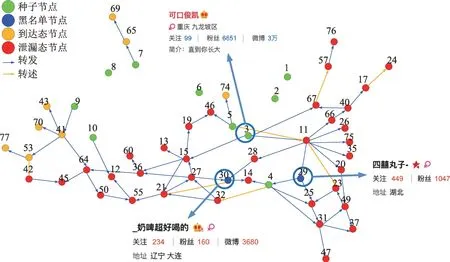
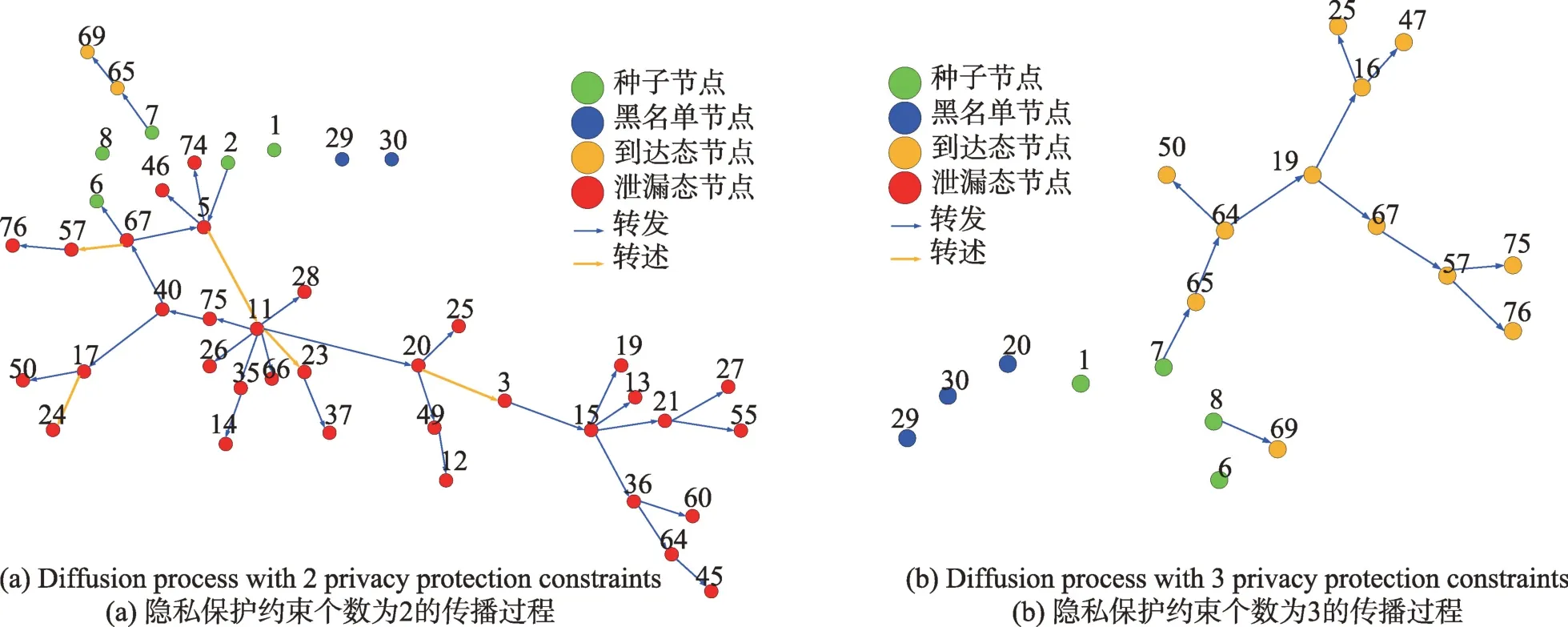
(1)时间相近规则:ta (2)位置相邻规则:ub∈Follower(ua)。 (3)内容相似规则:Similar(Ma,Mb)=true。 时间相近与位置相邻规则的判断易于实现,本文不予赘述,下面讨论内容相似规则计算方法。 Similar(M',M)函数通过设置信息的文本相似度函数DocSim(M',M) 的阈值Thdoc和单词相似度函数WordSim(M',M)的阈值Thword实现,式(9)给出转述关系推断规则中内容相似规则的计算方法。 其中,信息的文本相似度函数形式为DocSim:{ 式中,vM、vM'分别为信息M、M'的文本表示,vM、vM'∈Rd。信息的单词相似度函数形式为WordSim:{ 式中,wordlist(M)、wordlist(M')分别为信息M、M'的单词序列。 为了做到既能保护用户在社交网络中的隐私又最大化用户的影响力,当用户输入将要发布在社交网络中的信息时,需要能够对该信息在网络节点间的传播方式进行预测。 定义9(信息传播预测问题)已知一个用户将要产生的发布信息行为Actions= (1)信息M的等同信息或衍生信息到达用户u时,用户u转发该信息给用户v的概率pu,v,u∈U,v∈Follower(u); (2)信息M的等同信息或衍生信息到达用户u时,用户u转述该信息给用户v的概率qu,v,u∈U,v∈Follower(u)。 定义10(用户关注关系网络R)R=(VR,ER)记作社交网络的用户关注关系网络,VR是R的节点集合,ER是R的边集合,满足以下条件: (1)R是一个有向图; (2)VR=V; (3)v∈Follower(u)⇔(u,v)∈ER。 信息传播的预测问题,可以转换为社交网络中用户关注关系网络R的三分类问题,即将R中所有边的类型对应到传播网络中转发边、转述边或无行为三种类型中,这些边的类型由定义4(社交网络传播模型)中的3 种行为(转发行为Tp、转述行为Tq和无行为Tr)激活新节点后生成,再通过生成训练样本、提取样本特征、训练分类模型完成分类。其中生成训练样本可以通过使用历史数据构建的传播网络获得,这里不再赘述。本文使用的特征参考了文献[21]中提出的内容特征、拓扑结构特征、交互特征以及用户特征。 根据定义4 的信息传播模型以及隐私保护约束限制,算法的优化目标如式(12): 式(12)中,IG(S)表示种子集合S在社交网络G上产生的影响力大小;F表示种子节点的可选集合,即种子集合S必须是F的一个子集;O表示网络中的关键节点集合,默认情况下为设置的黑名单,用户希望信息以尽可能低的概率泄漏到集合O中的节点;Q(S,oj)≤τj表示隐私保护约束,即选取的种子集合S必须保证信息泄漏到节点oj的概率小于τj,集合O中的每个元素都对应一项隐私保护约束。 隐私保护约束限制下的影响力最大化问题的难点主要有三点: (1)如何选择种子节点集合,集合F的子集个数有2|F|个,枚举所有的子集会造成巨大的时间开销; (2)如何估计种子节点集合产生的影响力的大小,并在社交网络上产生尽可能高的影响力; (3)如何保证算法生成的种子集合能够满足隐私保护约束的要求。 为应对隐私保护约束限制下的影响力最大化问题的三个难点,本节提出了支持隐私保护的影响力最大化方法LocalGreedy。针对种子集合选取时枚举所有子集的问题,基于贪心策略递增构造种子集合,避免枚举造成的时间开销;给出计算节点的局部影响子图的方法,快速估计通过种子集合传播产生的影响力;为确保种子集合满足隐私保护约束限制,提出了推导节点泄漏态概率上限的计算方法,判断种子集合是否满足隐私保护约束,避免使用蒙特卡洛方法产生的时间开销。本节依次按照种子集合选择策略、影响大小估计方法以及节点泄漏概率上限计算,分三方面进行算法设计。 为应对4.1 节中的难点(1),本文采用递增的方法生成种子集合S,初始时令S为空集,并在每轮迭代过程中向集合S添加一个元素。每轮迭代时,在所有添加后满足隐私泄漏条件约束的节点中,选择让影响力增量最大的元素。定义Δ(S)表示算法每次选择的依据如式(13): 种子集合的选择基于贪心策略,其依据主要体现在以下两方面: (1)隐私保护约束与集合S存在单调性,当集合S不符合隐私保护约束的限制时,集合S的任意超集也不符合隐私保护约束的限制,因此从空集开始递增构造,可以及时中止算法,避免多余的计算; (2)IG(S)同时满足单调性和子模性,因此每次选择使得IG(S)递增量最大的元素添加具有一定的理论保证。 传统的蒙特卡洛方法在时间效率上十分低效,本节提出一个非蒙特卡洛模拟的方法,快速计算选定种子节点集合后每个节点状态的概率分布。对于一条长度为l-1 的路径P= 定义11(最大理想路径)对于社交网络G=(V,E,T,P)中从节点u到节点v的所有路径R(G,u,v),定义最大理想路径为节点u到节点v间影响权重最大的路径MIP(u,v),具体如式(14)。 考虑单个节点v被影响的概率,当wp(MIP(u,v))很小时,即使节点u被影响,信息经过其到达节点v的概率通常也会很小,也就是说节点v是否被影响与节点u是否被影响基本无关。那么在估计节点v被影响的概率时,可以只考虑其邻近区域的节点和边构成的子图。 定义12(局部影响子图) 对于信息传播模型G=(V,E,T,P)包含节点v的子图,定义节点v关于θ的局部影响子图如式(15)。 其中,θ是一个参数,MIA(θ,v) 由所有满足约束wp(MIP(u,v))>θ的路径MIP(u,v)取并集得到。 显然当θ越小时,MIA(θ,v)所表示的节点v的局部影响子图所包含的边越多。并且根据定义,局部影响子图MIA(θ,v)是树形结构,因此可以使用动态规划在线性时间复杂度下计算节点v被影响的概率。 本文所提影响力计算方法在仅考虑MIA(θ,v)中的节点和边的情况下计算节点v最后处于各状态的概率,处于到达状态的概率表示为ap(S,v,MIA(θ,v)),处于泄漏状态的概率表示为aq(S,v,MIA(θ,v))。在不引起混淆的情况下,将ap(S,v,MIA(θ,v))简写为ap(v),将aq(S,v,MIA(θ,v))简写为aq(v)。更进一步,通过计算所有节点的局部影响子图获取各个节点的ap(S,v,MIA(θ,v))和aq(S,v,MIA(θ,v)),可以在不使用蒙特卡洛模拟的情况下,得到种子集合S产生的总的影响力大小的估计值: 通过式(16)可以在不使用蒙特卡洛方法的情况下,高效估计种子节点集合产生的影响力,算法效率仅与节点数n和节点的平均邻接区域大小Bθ有关,时间复杂度为O(n×Bθ)。加上计算每个节点的局部影响子图的复杂度,总复杂度为O(n×Bθ×lbBθ)。 考虑节点集合O中的任一节点o,要想使得Q(S,o)<τ,那么对于节点o的入邻居集合Nin(o),其中的元素处于泄漏状态的概率不应过大。定义uq(v)表示Q(S,v)的上限,则可以通过以下规则来推断uq(v)的范围,使每个节点获得一个尽可能小的上限,下面给出计算条件。 (1)如果oj∈O,则uq(oj)≤τj; (2)如果uq(v)≤x,则∀u∈Nin(v),uq(u)≤x/(pu,v+qu,v)。 uq(v)的值越小则可以通过检验式(17)的条件是否满足,更大地提升算法的效果和效率。 具体地,本文所提节点泄漏概率上限计算方法使用uq(v)来判断当前的种子集合是否会违反隐私保护约束带来的限制,即检查∀u∈V,aq(v,θ,MIA(θ,u))≤uq(v)条件是否得到满足。 节点泄漏概率上限计算方法的本质是对最短路径算法的一种扩展,通过将原本仅对关键节点的限制推广至全图,从而在获取到uq(v)之后,就可以与本文所提影响力计算方法结合,估计种子集合产生的影响力的同时判断是否满足隐私保护约束。 为了构建传播网络,需要真实的社交网络数据,这里选择使用爬虫爬取新浪微博中用户的公开信息作为实验数据。爬取的数据可以分成3 类:微博数据、个人信息数据和社交关系数据。最终爬取到的微博数据中用户总数为2 903 403,微博总数为23 068 115条,其中转发微博有7 006 235 条。爬取的微博内容均为用户在2018 年国庆期间所发布的内容。 对于转述关系推断,根据时间相近、位置相邻规则获取微博数据子集。并利用内容相似规则,推断转述信息,作为转述关系的标注数据,由于多数包含相同语义的转述信息的单词相似度较低,为确保推断正确的同时获得更多标注数据,经过多次调整,将文本相似度阈值设置为Thdoc=0.7,单词相似度阈值设置为Thword=0.12,推断出258 179 条转述信息。然后,按照2∶1∶10 的比例生成转发、转述和无行为3 种类型的训练数据,并使用GDBT(gradient Boosting decision tree)[22]和交叉验证来训练用户行为分类器,得到accuracy、micro-F1 和macro-F1 分别为81.2%、84.4%和80.9%,能够满足后续预测用户在接收信息时产生的行为概率分布的需求。 因为在现有微博数据集上无法获得用户设置的黑名单节点,所以在进行实验评估时,通过随机的方式进行模拟。 隐私保护约束个数(黑名单节点个数)默认情况下为3 个,对应的隐私保护参数(泄漏概率上限)的默认取值范围为[0,0.1]。不同的算法在进行对比时,使用同一组隐私保护约束和参数。 5.2.1 评价指标与实验环境 本文使用以微博数据为基础构建的传播网络作为实验用的社交网络,并使用3 种指标进行评价: (1)影响力指标:对于算法生成的种子集合S,使用种子集合S满足隐私保护约束限制时的影响力IG(S)的均值作为评价指标,称作影响力指标。影响力指标越大时,算法产生的种子集合在传播过程中产生的影响力越大,效果越好。 (2)综合指标:考虑到算法的目标有两个,最大化传播产生的影响力和满足隐私保护约束下的限制,这里定义函数F(G,S)作为算法的评价指标,以下均简写为F(S),称作综合指标: 即当种子集合S不满足隐私保护约束限制时,F(S)为0,其他情况下F(S)等于种子集合S在网络上产生的影响力大小IG(S)。对于综合指标,当算法产生的种子集合S满足隐私保护约束限制的概率越大时,该指标越大,说明算法效果越好。除此之外,当算法产生的种子集合S产生的影响力越大时,该指标也越大。因此,F(S)是对算法的隐私保护效果和传播影响力大小的综合考量指标。 (3)运行时间指标:对于效果相近的算法,更短的运行时间意味着更好的效率,实验统计各算法的运行时间以评估其效率。 本文的实验均在单机平台下完成,包括Ubuntu 16.04.10 操作系统,1 块Intel Xeon Silver 4110 CPU,2块NVIDIA GeForce GTX 1080Ti (11 GB) GPU,32 GB内存。所有算法均使用Python3.6 实现。 5.2.2 对比实验设计 现有的影响力最大化方法主要分为3 种:启发式算法、蒙特卡洛方法的优化方法、基于社群的算法。由于基于社群的算法难以扩展到用户隐私保护需求的情形中,而基于蒙特卡洛的方法具有一定的理论保证,且基于节点度和节点在网络中的距离是常见启发式算法中的依据,因此本文的对比实验选取了具有代表性的3 种蒙特卡洛方法:SimulateGreedy 算法、Degree 算法[21]、Distance 算法[21]。其中Degree 算法、Distance 算法均为启发式算法,算法中的蒙特卡洛模拟部分仅用来判断种子集合是否满足隐私保护约束。 (1)SimulateGreedy 算法:依据贪心规则递增地构造种子集合,需要使用蒙特卡洛来估计影响力大小以及是否满足隐私保护约束限制。 (2)Degree 算法:以节点的度数为主要依据的度启发算法,一开始将所有节点按节点度数从大到小进行排序,然后顺次尝试加入种子集合中,需要进行蒙特卡洛模拟。 (3)Distance 算法:以节点到其他所有节点的平均距离为主要依据的启发式算法,一开始将所有节点按从小到大进行排序,然后顺次尝试加入种子集合中,需要进行蒙特卡洛模拟。 (4)LocalGreedy 算法(本文算法):初始时使用算法CalculateBound 计算每个节点的uq(v),估计种子集合影响力时使用算法LocalInfluence。该算法也递增地构造种子集合,但不再需要蒙特卡洛模拟。 SimulateGreedy 算法使用蒙特卡洛方法来计算种子集合的影响力,当模拟轮数较大时有较好的理论保证。节点的度数以及节点到其他节点的平均距离是影响力计算研究中经常使用的特征,在影响力最大化研究中也经常被作为算法设计的依据,因此本文将Degree算法与Distance算法作为对比算法。 除了使用F(S)和IG(S)作为判断算法的效果好坏的依据外,实验中还依据算法的运行时间来评价其效率。 (1)邻近子图大小参数θ对算法的影响 因为LocalGreedy 算法通过参数θ来计算每个节点的局部影响子图,所以不同的参数θ意味着不同大小的邻近子图,从而对算法的效果和效率产生影响。图3 和图4 分别绘制了以邻近子图大小参数θ作为横坐标时,算法的影响力指标和运行时间的折线图。 Fig.3 Influence of θ on effect of LocalGreedy图3 邻近子图大小θ对LocalGreedy 算法效果的影响 Fig.4 Influence of θ on running time of LocalGreedy图4 邻近子图大小θ对LocalGreedy 算法运行时间的影响 当LocalGreedy 算法的参数θ越大时,节点的局部影响子图越小,考虑的边数会减少,因而效果会变差,但运行时间会缩短。图3 与图4 展示的实验结果符合预期。综合图3 与图4 的结果,当θ=5E-5 时,算法在运行时间与影响力上取得较好的均衡。 (2)算法各指标对比 图5、图6、图7 分别绘制了以可选集合大小作为横坐标时,算法的运行时间、影响力指标、综合指标的折线图。 Fig.5 Comparison of algorithms running time图5 算法运行时间对比 Fig.6 Comparisons of algorithms influence index图6 算法影响力对比 Fig.7 Comparisons of algorithms composite index图7 算法综合指标对比 从图5 中可以看出,随着可选集合大小的增长,SimulateGreedy 算法的运行时间的增长趋势最大,Degree 算法和Distance 算法基本相当,本文算法也就是LocalGreedy 算法增长趋势最小。从运行的绝对时间来看,也是本文算法最好,Degree 算法与Distance算法相当接近,SimulateGreedy算法需要的时间最长。 当可选集合大小变大时,因为可以用作种子集合的节点变多,算法的效果应当越来越好,这从图6和图7 都得到了验证。另外,从图中还可以看出,运行时间最长的SimulateGreedy 算法在效果上稍好于两种启发式算法,而基于节点度数的启发式算法又更优于基于平均距离的启发式算法。结合上述的算法效果对比可以得出结论,本文算法不仅在运行时间上相对于主流算法有明显提升,并且在效果上有一定的优势。 (3)隐私保护约束对算法的影响 当关键节点集合O越大时,隐私保护的约束个数越多,算法求解过程中的限制越多。图8 和图9 分别绘制了以隐私保护约束个数作为横坐标时,算法的影响力指标和运行时间对比的折线图。当隐私保护的约束个数变多时,本文算法的运行时间有极小的增长趋势,运行时间优势明显。并且在各种不同隐私保护约束个数的情况下,本文算法的效果仍优于其他算法。 Fig.8 Influence of the number of privacy protection constraints on effect图8 隐私保护约束个数对效果的影响 Fig.9 Influence of the number of privacy protection constraints on running time图9 隐私保护约束个数对时间的影响 图10 展示了改变隐私保护参数τ的大小时,算法的综合指标的变化情况。τ值越大时,隐私保护的约束越弱,算法生成的种子集合越容易满足隐私保护约束限制,从而产生更高的影响力。本文算法在τ≤0.04 时效果与其他算法相当,对于更大的τ值,本文算法在效果上具有一定的优势。 Fig.10 Influence of privacy protection parameter on composite index图10 隐私保护参数大小对综合指标的影响 本节选取新浪微博用户关注网络中一个包含80个用户节点,985 条关注关系的子图进行实例展示。设置可选节点集合F={1,2,3,4,5,6,7,8,9,10},集合F同时也是要在社交网络中发布信息的用户的关注者集合。并设置关键节点集合(黑名单用户集合)O={29,30},其中标号为29 的用户微博名为四囍丸子,标号为30 的用户微博名为奶啤超好喝的,用户希望信息在传播过程中不会泄漏到这两名用户。 在图11、图12 中,绿色节点表示种子集合中的节点,蓝色节点表示黑名单用户,橙色节点表示节点处于到达态,红色节点表示节点处于泄漏态,其余未受影响的节点未在图中画出。图中的蓝色边表示转发关系,橙色边代表转述关系。 图11 展示了无隐私保护约束时的传播过程,此时S=F,可选集合中的所有节点均加入种子集合中,即用户将信息发布给所有关注者。从图中可以看出,信息泄漏到了节点编号为29 和30 的两个黑名单用户。下面分析信息如何泄漏到节点30 的黑名单用户,从信息传播路径可以看到,存在泄漏路径<3,15,21,30>,其中边(21,30)为转述边(泄漏路径中包含至少一条转述边),信息通过转述边泄漏到了节点30对应的用户。如果只考虑转发关系,虽然存在传播路径<3,11,28,30>,但是因为节点30 是黑名单中的用户,信息对该用户不可见,不会认为产生了隐私泄漏。 图12(a)展示了为黑名单中用户添加隐私保护约束后的传播过程,此时算法为了满足隐私保护约束,并最大化传播影响力,输出S={1,2,6,7,8},可选节点集合中容易形成泄漏路径的节点未被算法选择为信息到达节点。例如节点3,微博用户名可口俊凯,该节点有较高概率通过节点11 形成到节点29 的泄漏路径,以及通过节点15 形成到节点30 的泄漏路径。从图中还可以看出,算法输出的种子集合不仅满足了用户的隐私保护需求(不存在从种子节点到黑名单节点的泄漏路径),并且还产生了大的影响力,被影响的节点数并没有明显减少。 Fig.11 Diffusion process without privacy protection constraints图11 无隐私保护约束时的传播过程 Fig.12 Diffusion process with privacy protection constraints图12 隐私保护约束的传播过程 图12(b)展示了添加新的黑名单节点(编号20)后的传播过程,此时算法输出S={1,6,7,8},容易形成到节点20 的泄漏路径的节点2 被排除。实例展示了本文算法可以使社交网络用户在信息不泄漏到一部分特定用户的情况下,让信息在其他用户中取得较高的影响力。 针对社交网络信息传播过程中,最大化影响力传播与用户隐私保护的矛盾,提出了一种支持转述关系的社交网络信息传播模型和推断方法,以及种子集合选择算法IncrementGreedy、局部影响计算算法LocalInfluence和节点泄漏概率算法CalculateBound,并在此基础上提出了LocalGreedy 算法。在爬取的新浪微博数据集上进行了实验验证和实例分析,结果表明LocalGreedy 算法能够确保在保护用户隐私的情况下,最大化传播的影响力。 未来研究工作将基于本文提出的模型和方法,进一步挖掘社交网络信息传播的特点和隐私泄漏的原因,考虑信息在传播过程中信息量的变化,并在传播网络构建过程中引入更多的特征。
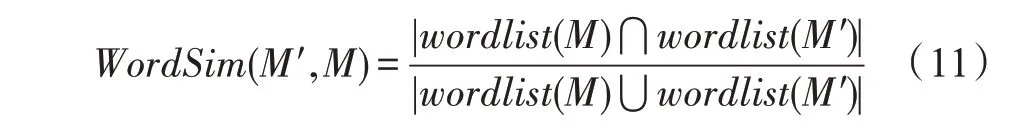
3.3 信息传播预测
4 支持隐私保护的影响力最大化方法(Local-Greedy)
4.1 方法概述
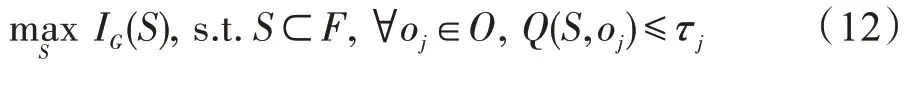
4.2 种子集合选择策略
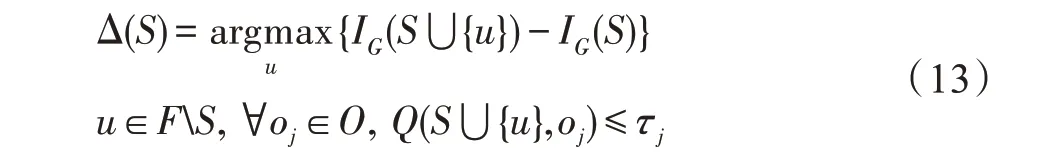
4.3 影响力计算方法
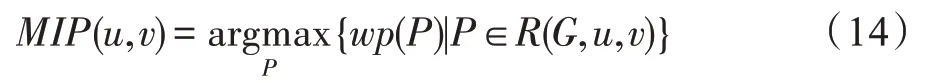
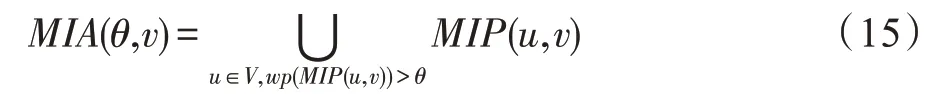
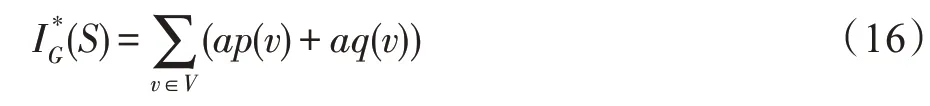
4.4 节点泄漏概率上限计算
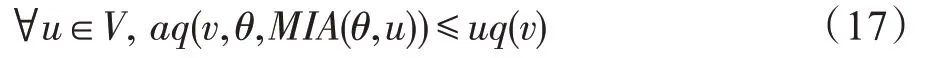
5 实验与效果评估
5.1 实验数据
5.2 实验设计
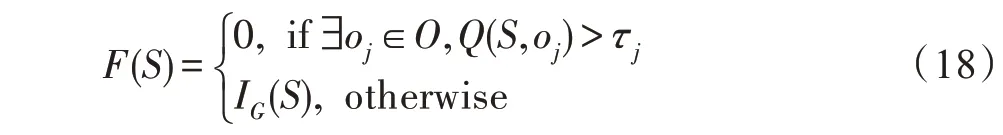
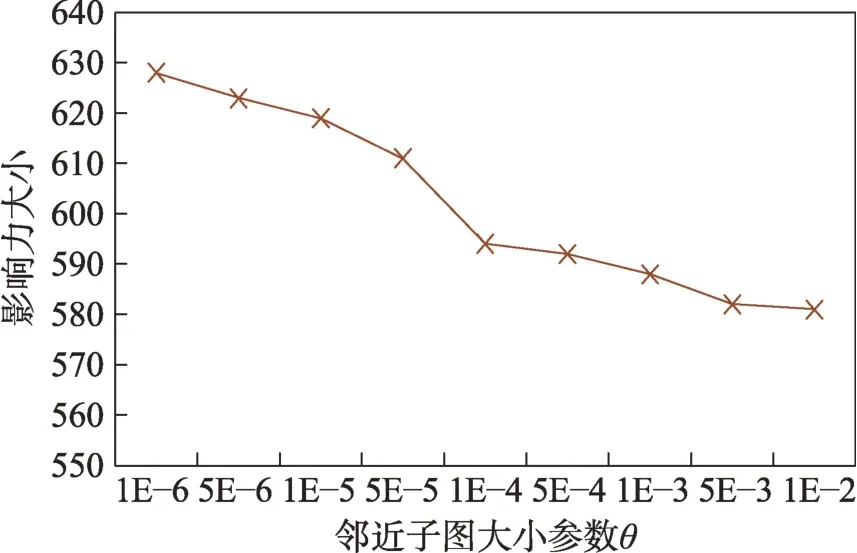
5.3 结果与分析
5.4 实例展示
6 结束语
猜你喜欢
导航定位学报(2022年4期)2022-08-15
意林彩版(2022年2期)2022-05-03
现代电子技术(2022年4期)2022-02-21
好日子(2021年8期)2021-11-04
计算机应用与软件(2021年10期)2021-10-15
金桥(2021年3期)2021-05-21
第一财经(2020年4期)2020-04-14
阅读(快乐英语高年级)(2019年8期)2019-09-10
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
文苑(2018年17期)2018-11-09
