
视觉惯性SLAM 研究进展*
2021-02-03 07:42:02郭金辉陈秀万
火力与指挥控制 2021年1期
郭金辉,陈秀万,王 媛
(1.北京大学遥感与地理信息系统研究所,北京 100871;2.中国电子科学研究院,北京 100041)
0 引言
同时定位与地图构建(Simultaneous Localization and Mapping,SLAM)是一种起源于上个世纪80 年代的机器人领域技术,其目标是在未知环境中进行建图并确定机器人自身位置[1]。SLAM 具有多种分类方式,常见的SLAM 系统根据传感器类别区分可划分为单目SLAM、双目SLAM、RGBD-SLAM、激光SLAM、微波SLAM、WiFi-SLAM、视觉惯性SLAM等。在SLAM 发展早期,激光SLAM 占据机器人领域相关研究的主要地位。但随着传感器不断发展,低成本、体积小、信息丰富的相机和惯性测量传感器(Inertial Measurement Unit,IMU)逐渐成为研究热点[2]。
在实际应用过程中,单传感器定位往往存在问题。例如相机获取的图像虽然信息丰富但易受环境干扰(遮挡、运动物体、无纹理场景、光照等),在运动较快时图像会出现模糊。而IMU 属于内部传感器,其不受成像质量影响且采样频率高,但长时间积分后位姿漂移较大。因此,相比单个传感器,相机和IMU 融合定位方式可取得更高的精度,提高整个系统的鲁棒性[3]。近年来,视觉惯性SLAM(Visual Inertial SLAM,VISLAM)发展迅速,在摄影测量、三维重建、深空探测、室内导航、增强现实、无人驾驶等领域已得到广泛应用。
当前已有许多视觉SLAM 的综述研究[4-6],但VISLAM 的研究综述相对较少。本文主要专注于对VISLAM 的方法进行分析和讨论,系统地介绍并分析几种经典算法框架及其优缺点。另外,本文从硬件和算法层面讨论了近年研究热点与发展趋势,并在最后作出总结。
1 VISLAM 关键技术
与视觉SLAM 一样,VISLAM 也可分为前端、后端、回环检测和建图4 个部分[7]。前端部分通过对传感器数据进行处理解算,获得相邻观测间的运动及局部地图。后端部分将前端和回环检测的信息作为输入,通过滤波或非线性优化的方式对整个系统进行状态估计,从而获得全局一致的轨迹和地图。回环检测用于判断机器人是否到达过先前的位置,可有效减小累积误差。而建图是指根据自身定位结果,构建与任务要求对应的地图的过程。
1.1 前端
1.1.1 视觉前端
视觉前端是指利用序列图像估计图像间运动,可分为特征点法和直接法。特征点法首先需要对图像提取特征点,然后通过特征匹配实现数据关联。良好的特征点具有可重复性与独特性,并具有一定程度上的平移、旋转和尺度不变性,常用的特征点包括SIFT[8]、SURF[9]、ORB[10]等。SIFT 和SURF 特征点计算较为复杂,因此,常用于运动恢复结构(Structure From Motion,SFM)问题的离线解算,而使用ORB 特征点可以保证SLAM 求解的实时性[11]。如果相邻图像基线较小,可使用光流跟踪的方法代替特征匹配[12]。光流跟踪一般只使用简单角点如Harris[13]和FAST[14]角点,因此,跟踪速度较快。但光流跟踪基于灰度不变假设,因此,光照条件变化较大时会导致跟踪丢失。在实现数据关联后,使用P3P[15]、EPnP[16]、UPnP[17]等方法求得位姿初值,再使用光束法平差(Bundle Adjustment,BA)最小化重投影误差,从而解得精确相机位姿。
特征点法将数据关联和位姿估计分为两个部分,而直接法通过最小化光度误差,以更整体的方式直接计算得到位姿[18]。由于不需要进行特征提取和跟踪,直接法可实时进行半稠密甚至稠密建图[19]。直接法在缺乏角点、重复纹理的环境下仍可正常使用,但直接法与光流跟踪同样基于灰度不变假设,因此,也存在对环境光照变化敏感的问题。
1.1.2 IMU 预积分
IMU 可以获得自身坐标系下的加速度和角速度观测值,直接对IMU 测量值按时间进行积分可以由一个时刻的状态量递推得另一个时刻的状态量。但每次状态量更新后,均需要重新进行积分,因此,计算量较大。而使用预积分可转换为相对积分量,表示对两个时刻状态量的约束,从而避免新状态量依赖先前状态的问题[20]。由于IMU 的采样频率一般比图像频率高,通常将两个关键帧时刻之间的所有IMU 观测积分起来。常用的积分形式包括欧拉积分、中值积分和龙格-库塔法积分,其中中值积分计算量小且精度较高,在实际应用中经常使用。
1.2 后端
早期视觉SLAM 中使用基于滤波的后端[21],自2007 年PTAM[22]提出后,基于非线性优化的方法成为视觉SLAM 所使用的主流方法。但在VISLAM 中,待估计状态量维数比视觉SLAM 更多而计算量更大。因此,基于滤波的后端和基于非线性优化的后端均十分常见,且效果相当。滤波与非线性优化在贝叶斯框架下相统一,简要推导如下。首先机器人定位模型中运动方程和观测方程可分别表示为:
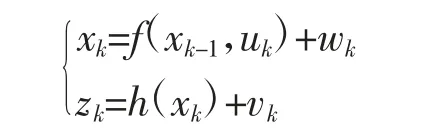
其中,xk表示k 时刻的待估计变量,即位姿和路标点等,uk为运动传感器输入项,即IMU 测量信息,zk表示k 时刻所有视觉观测,wk和vk为噪声项,通常假设满足零均值高斯分布。后端的任务即根据过去0到k 时刻的数据估计第k 时刻的状态分布:
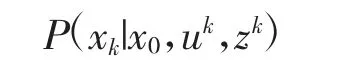
其中,设定上标k 表达1∶k 所有时刻,而下标k 表达当前时刻。为描述方便,忽略初始值x0得:
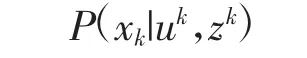
利用贝叶斯准则,可得:
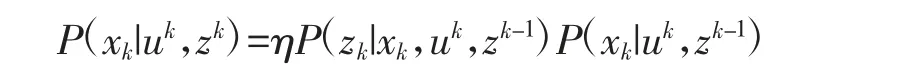
其中,η 等于P(zk|uk,zk-1),为与变量无关的归一化常量。假设各观测值相互独立,则化简为:

似然部分由观测方程给定,先验部分表明当前状态xk基于过去状态估计得,按照xk-1时刻为条件概率展开得:
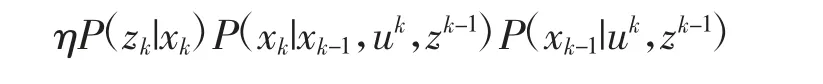
上式表示贝叶斯估计过程,其后续处理分为两种方法:
1)第一种方法基于马尔可夫性假设。一阶马氏性认为,k 时刻状态只与k-1 时刻状态有关,而与之前无关。故上式先验展开部分可简化为:
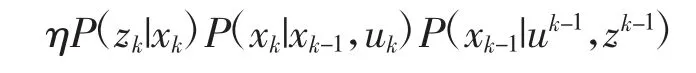
上式最后一项为k-1 时刻后验概率,因此,将k时刻后验概率写作递推的形式得:
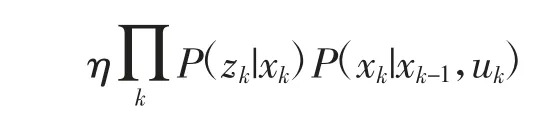
上式表示由之前时刻状态递推得当前时刻状态需要不断迭代(即预测)和更新。在VISLAM 中对应即使用IMU 进行状态预测,并使用视觉信息进行状态更新。假设状态量服从高斯分布且整个系统非线性,则可得到以扩展卡尔曼滤波(Extended Kalman Filter,EKF)为代表的滤波器方法。
2)另外一种方法依然考虑k 时刻状态与之前所有状态的关系。为求解状态的最优估计,需最大化后验概率(Maximize a Posterior,MAP)。当状态量先验信息未知时,则转换为求解状态量的最大似然估计(Maximize Likelihood Estimation,MLE)。假设状态量噪声项满足零均值高斯分布,则最大似然估计可转换为非线性最小二乘问题。在VISLAM中,则有:
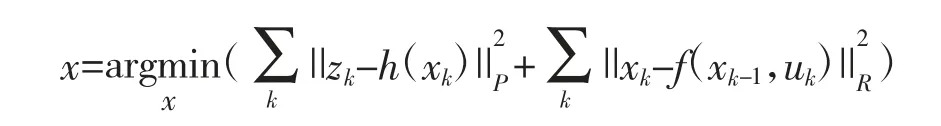
其中,第1 项表示视觉残差,可以为重投影误差,也可以为光度误差。第2 项表示IMU 残差约束,而P和R 分别为两个残差的协方差阵。为减小异常值的影响,通常还对残差项使用核函数进行鲁棒估计,常用的鲁棒核函数有Huber 核、Cauchy 核和Tukey核[23]。
VISLAM 中待估计参数量较多,因此,为减少计算量,通常在非线性优化时只维护优化一个滑动窗口(Sliding Window)内的各状态量。每当有新的帧被观测到时,需进行窗口滑动。为避免约束信息丢失,需对滑出窗口的帧进行边缘化操作,从而将约束信息保留为下一次求解的先验约束[24-25]。边缘化操作会造成填充(Fill-in)现象,使得原先相互独立的变量产生依赖,使滑动窗口内的信息矩阵变得稠密,因此,实际应用中还需尽可能维持信息矩阵的稀疏性。例如文献[25]提出保留临近的非关键帧和关键帧,根据对当前帧的影响选择直接丢弃或边缘化滑出窗口的帧。
滑动窗口算法优化时,信息矩阵由新的测量信息和之前的测量信息两部分构成。而这两部分计算雅克比矩阵时线性化点不同,这会导致信息矩阵的零空间发生变化,从而在求解时引入错误信息,破坏整个求解系统。还将导致不可观变量的可观性(Observability)发生变化(如航偏角),导致误差累积。因此,必须使用FEJ 算法(First Estimated Jacobian,FEJ),使不同残差对同一个状态求雅克比时,保持线性化点一致,避免求解零空间退化[26]。
1.3 回环检测
回环检测是一个SLAM 系统关键部分之一,正确检测回环事件是得到全局一致地图和轨迹的前提,目前常用词袋法(Bag of Words,BoW)和基于深度学习的方法。词袋法最先起源于文本检索,通过统计文档词频,构建直方图,用于表示该文档特有特征。其基本思想后来用于回环检测,即首先对图像提取合适特征,然后为减少字典冗余进行K-means 等算法聚类压缩,最终训练得词典,并据此进行匹配检索[27]。深度学习近年来取得巨大成功,冲击着各个学科和领域[28]。深度学习可自主学习复杂图像特征,从而避免传统词袋法需人工设计特征的缺点,研究表明基于深度学习的方法可取得同样精度且更具普适性[29-30]。相比召回率,回环检测对准确率要求更高。因此,实际应用中,除外观相似性约束外,还需时间和空间上一致性结合进行验证,以确保将假阳性情况降至最少[31-32]。
1.4 建图
建图即根据所估计位姿,建立与任务要求对应的地图。稀疏路标点地图常用于手机、机器人自身定位,计算量通常较小,但易受光照和场景影响;稠密点云地图或八叉树地图可用于导航和避障,但一般需要足够算力才能保证实时性[33];面片地图和TSDF 地图(Truncated Signed Distance Function,TSDF)能比点云更精细表示三维重建结果[34-35];而语义地图使得与地图间可以交互,提供更高层次语义信息[36-38]。
2 已有研究工作
视觉与IMU 信息的融合方式分松耦合和紧耦合两种,松耦合表示将IMU 定位与视觉定位位姿直接融合得到结果,而紧耦合将视觉约束信息与IMU约束联合解算,最终得到待求位姿。因此,根据融合方式和后端形式,VISLAM 可大致分为以下4 类。
2.1 基于滤波的松耦合方法
松耦合方法比较直接,如MSF 算法(Multi-Sensor Fusion,MSF)使用扩展卡尔曼滤波作为后端,在预测阶段使用IMU 数据进行系统状态传递,而将视觉前端当作黑箱进行更新[39]。由于松耦合法结构简单,因此,具有计算量小且运算速度较快的优势。此外这种模块化架构使得系统可方便与其他传感器结合,如与GPS、声呐等。模块化架构使得系统脱离具体模型限制,即使模型不够准确,仍可通过其他观测弥补。
2.2 基于滤波的紧耦合方法
Mourikis 等于2007 年提出MSCKF 算法(Multi-State Constraint Kalman Filter)[40],该算法同样使用扩展卡尔曼滤波作为后端,在预测阶段使用IMU数据进行系统状态传递,在更新阶段维护一个滑动窗口。MSCKF 通过对路标点边缘化来给共视帧添加约束,从而实现既不损失信息,又大大降低计算复杂度。
传统EKF 法只在固定点做线性化近似,无法保证全局最优,因此,更容易造成误差累积。在同等计算量下,非线性优化法效果一般优于滤波方法[41]。
2.3 基于优化的松耦合方法
文献[42]提出一种基于优化的松耦合VISLAM方法[42],融合结构如图1 所示。首先通过直接法计算得帧间相对位姿,然后将位姿变换到IMU 坐标系下,并直接以约束项的形式加入到IMU 优化框架中,从而联合估计得位姿。这类方法计算量大且精度不够理想,因此,研究者把目光投向基于优化的紧耦合方案。
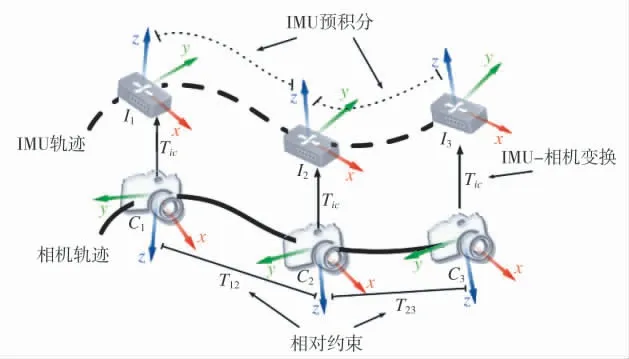
图1 基于优化的松耦合方法框架
2.4 基于优化的紧耦合方法
OKVIS[25]是基于关键帧优化的紧耦合开源VISLAM 系统,算法具体流程是通过IMU 测量值对当前状态做预测,根据预测进行特征提取和特征匹配,从而计算重投影残差,同时IMU 状态量预测值和优化参数之间构成IMU 测量误差,最后将视觉残差和IMU 残差放在滑动窗口中进行联合优化。另外,为保证系统一致性,OKVIS 采用FEJ 策略,理论上更加准确。
VIORB[43]同样是一个著名的紧耦合VISLAM系统,其基于开源框架ORBSLAM[11],且与ORBSLAM 同样包含图优化后端、回环检测及重定位功能。与一般VISLAM 方案不同,VIORB 没有采用经典的滑动窗口结合边缘化的方式,而每次使用局部光束法平差进行优化求解,如图2 所示。另外,VIORB 提出一种初始化方式,即首先只进行单目初始化,然后再对尺度、重力、速度向量、IMU 零偏进行估计[43]。
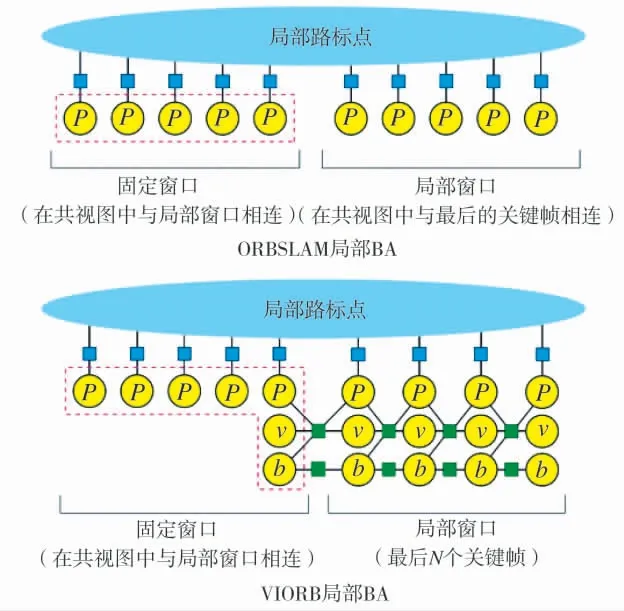
图2 ORBSLAM 局部BA 与VIORB 局部BA 对比
Vins-mono[44]是香港科技大学团队于2017 年开源的一个成熟的VISLAM 系统,其主要包括前端、初始化、后端优化、闭环检测和全局位姿图优化5个部分,如下页图3 所示。Vins-mono 前端使用Harris 角点光流跟踪,而IMU 部分使用预积分得到观测量。初始化部分与VIORB 类似,采用松耦合方式进行。即首先通过SFM 初始化,然后以此为运动参考估计其他参数,再将视觉坐标系与世界坐标系对齐。后端部分进行一个滑动窗口优化,并采用一种边缘化策略来尽可能防止信息丢失或冗余[44],如图4 所示:1)当滑动窗口中第二新的图像帧为关键帧,则边缘化最老的帧,以及上面的路标点;2)当滑动窗口中第二新的图像帧不是关键帧,则丢弃这一帧上的视觉测量信息,并将IMU 预积分传给下一帧。此外,为提供全局一致地图,Vins-mono 还加入闭环检测、重定位等功能,使整个系统更加完整、鲁棒。
3 研究热点与发展趋势
随着技术的发展和越来越多开源系统的出现,VISLAM 技术正逐渐趋于成熟。然而尽管在理想条件下已经可以达到很高的精度和计算效率,如需真正投入实际应用,算法的鲁棒性、实时性和准确性仍需进一步提高,硬件和算法的许多问题尚待进一步解决。
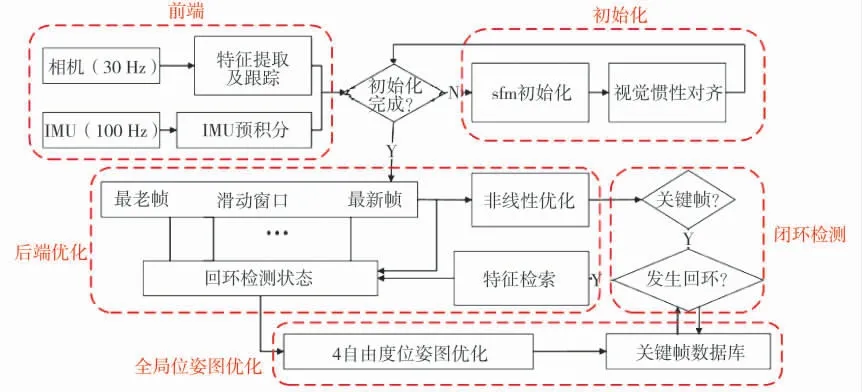
图3 Vins-mono 系统框架图
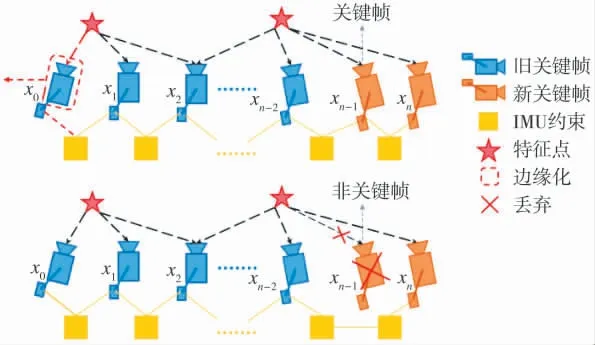
图4 Vins-mono 边缘化策略
3.1 硬件发展
VISLAM 不仅是一种算法,也是一种系统工程。其对硬件质量依赖较强,实际效果对相机IMU 外参、相机IMU 时间戳延迟、IMU 零偏等参数均十分敏感。尽管有研究已经可以通过算法减弱卷帘相机、相机IMU 时间戳未对齐等问题的影响,但VISLAM 系统精度提升仍需硬件质量的提升[45-46]。
此外,相机传感器本身具有天然缺陷。例如图像受光照变化影响很大,且存在运动模糊,基本无法满足无人机、无人驾驶等高速运动下的实际应用。近年来,事件相机(Event Camera)[47]引起许多研究人员关注。事件相机仅响应每个像素亮度变化,并以一组异步事件的形式表示,其中每个事件包括亮度变化的时空坐标及其正负号,如图5 所示。事件相机具有高动态响应范围(140 dB,而普通相机约60 dB)和低功耗的优势,且响应时间小于1 ms,因此,几乎不存在运动模糊。

图5 普通相机与事件相机对比
基于事件相机的上述优势,苏黎世大学研究团队提出基于事件相机的VISLAM 系统[48]。算法首先将一段时间内事件进行运动补偿,然后合成得到事件图像[49],如图6 所示。前端对每一帧事件图像进行光流跟踪,后端使用紧耦合的方式对视觉残差和IMU 残差进行非线性优化。后来该团队对此系统进行改进,提出终极SLAM(UltimateSLAM)[49]。UltimateSLAM 在之前基础上,引入普通相机作为第3 种传感器,将普通图像的视觉残差作为额外约束。从而共同发挥3 种传感器优势,在极具挑战的数据集上取得了很好的效果。

图6 合成事件图像示意图
3.2 后端加速
VISLAM 等多传感器融合方案可充分发挥不同传感器优势,实现精确鲁棒的定位与建图,但也同时造成待估计参数维数增加。尽管如今设备计算能力不断提高,仍需从算法上加速后端优化过程。
后段加速有许多不同的方案,其中增量优化是近年来的一个研究热点。增量平滑和建图(Incremental Smoothing and Mapping,iSAM)算法使用QR 分解,每次迭代只更新增量方程的一小部分[50]。在此基础上,iSAM2 还考虑消元顺序对计算量的影响,其在计算中动态维护一个贝叶斯树,以此确定消元顺序,从而减少不必要计算,加快后端求解速度[51]。
iSAM 主要针对信息矩阵稀疏情况,比如大尺度SFM 问题。而VISLAM 中经常会用到滑窗优化法,滑窗中信息矩阵结构稠密,此时iSAM 算法失效。ICE-BA 算 法(Incremental,Consistent and Efficient Bundle Adjustment,ICE-BA)[52]提出三点解决该问题:1)在全局BA 优化时,使用增量方式进行,即每次迭代时只对变化的相机或路标点进行更新[53];2)在局部滑窗BA 优化时,采用分段BA 方式来维持滑窗内稀疏性结构;3)在滑窗边缘化时,采用相对边缘化方式,以保证局部BA 优化和全局BA 优化对精度贡献一致。ICE-BA 通过采用这些技巧,保障了VISLAM 求解的实时性。
3.3 语义SLAM
随着深度学习的广泛应用,SLAM 与深度学习结合更加紧密。一些研究利用深度学习对图像进行识别、检测和分割,从而得到语义地图[54-57]。语义建图虽然在增强现实和三维重建中比较重要,但其对SLAM 本身促进有限。另一些研究将深度学习引入SLAM 本身的位姿估计中,但这些方法效果一般,目前还未成为主流[58-59]。还有一些研究利用深度学习检测或分割出物体,然后使用物体实例地图替代传统路标点地图,从而为SLAM 系统提供语义观测,如图7 所示[60-62]。这类物体级SLAM(Object SLAM)通过将图像的高层语义信息纳入定位流程中,从而能一定程度上克服大时间跨度下光照、天气、季节、场景结构变化等影响。随着训练数据集的增多和深度学习技术的发展,语义SLAM 定将大大提高SLAM 系统的准确性和鲁棒性。

图7 物体实例语义地图
4 结论
近年来,随着移动终端、无人机、机器人的快速发展,SLAM 技术也发展迅速。VISLAM 作为成熟的多传感器融合方案之一,取得了不错的精度和鲁棒性。尽管近年来VISLAM 在困难条件下定位与建图取得了很大的进步,但其鲁棒性、实时性和准确性仍有待提高,这势必会与硬件提升、后端加速、深度学习等内容进行结合,从而真正满足实际应用要求。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
数学物理学报(2022年2期)2022-04-26 14:08:28
环球人物(2022年4期)2022-02-22 22:05:06
小资CHIC!ELEGANCE(2021年32期)2021-09-18 06:17:14
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
大型铸锻件(2015年5期)2015-12-16 11:43:20
爆笑show(2015年4期)2015-06-24 01:55:12
河南科技(2015年8期)2015-03-11 16:23:52
小学阅读指南·高年级版(2014年2期)2014-05-27 05:29:32
