
基于Swarm模型的微博用户影响力评价方法
2021-01-22 06:00:32王利,于磊,吴渝
计算机工程与应用 2021年2期
王 利,于 磊,吴 渝
重庆邮电大学 计算机科学与技术学院,重庆400065
微博作为社会经济活动中常见的一种网络信息交互形式,因为其自身便利、快捷的传播机制而受到广泛的肯定和应用,微博中的大量活跃用户使得微博每天产生海量的数据。这些数据包括微博用户发表的微博帖子、点赞、分享转发、评论等。微博用户的这些错综复杂的关系形成了一个巨大的社交网络结构。由于微博的这些自身特点和优势,逐渐成为专家和学者研究的重点。
在社交网络群体与互动方面的相关研究中,个体影响力评估一直是一个重要方向。在社交网络中,用户基于社交目的或者自我价值实现的需要,发布和传播特定话题的信息并与他人互动,以获得和增强其在网上的话语影响力[1],用户的影响力是用户在微博中特定领域重要性的综合体现。目前关于微博用户影响力的研究,大体上从以下两个方面进行。
基于用户的静态属性来研究,Cha等[2]分别从入度、出度、提到以及转发指标入手,分别研究了各个指标对用户影响力的影响,并分析了这几个指标的效果。Wang 等[3]提出了一种在具有可调参数的复杂网络中节点重要性的新度量。与其他几个中心度量相比,他们提出的度量比网络节点的度数、中间度和紧密度中心性更具有区别性。Chen等[4]提出Personal Rank算法,该算法也可以用于计算微博用户的影响力,但在计算时还是需要依赖PageRank算法。
基于用户行为特征来研究,Kwak 等[5]提出的TunkRank算法,是基于PageRank的变形,是基于Twitter社交网络提出的,其思想是粉丝数越多的用户他们所发布的相关信息越有可能传播扩散整个网络。张俊豪等[6]结合用户自身行为与微博平台各个用户之间的关注关联关系,基于经典PageRank算法提出改进算法UIA(User Influence Assessment)。Kang[7]结合用户发表微博活跃度和PageRank算法,提出了Behavior-Relation-ship Rank算法来评价用户影响力。孙红等[8]在传统的PageRank算法模型上加入了微博用户自身在微博中的行为活动,同时考虑到了微博用户的自身行为,结合用户权值得到最终影响力。
微博话题直观地反射了当下大众对社会热点及事件的关注,话题中无数个体的态度聚集在一起形成一个动态整体行为,从这个角度看,对微博整体动态行为的研究亦属于突现计算的研究范畴。本文的主要研究内容是从突现的角度来对微博用户行为影响力进行评价。
本文从综合分析用户的转发、评论和点赞三种行为入手,结合突现计算Swarm 模型提出一种基于突现计算Swarm 模型的用户排序算法(Swarm Model user Rank,SMRank),基于PageRank和用户行为的影响力评价方法是研究者采用和改进比较多的方法,本文算法不同于以往的PageRank 的方法,给出了计算用户行为影响力的一种新的思维方法。
本文的创新点可以总结为以下两点:
(1)不再以用户为节点、用户之间的关注和粉丝为边来构建网络,而是根据微博话题中t 时刻的参与用户发布微博、转发微博、评论及点赞关系来构建t 时刻的用户交互关系网络。
(2)可以计算不同用户在不同时刻的影响力,如果需要在某个时间段对微博话题进行引导控制,可以根据用户不同时刻影响力的不同,对这个时间段用户影响力值高的用户进行管理,为微博话题的传播提供可管可控的思路。
1 相关技术基础
1.1 突现计算
突现计算(Emergent Computation,又称涌现计算)[9-10]是多agent系统在处理复杂问题时所展现出来的一种创新的思路逻辑。它是通过利用多个简单模块的相互沟通和协作来自我突现出更加复杂行为的系统。突现存在于自然和社会各个领域,如自然界的鱼群、鸟群和蚁群,社会领域中城市交通流、掌声同步和复杂网络行为等[11]。
1.2 Swarm模型
Swarm 模型[12]是基于自然界群集行为建立的一个用于研究系统突现行为的模型,它以Reynolds 的“Boids”理论为基础,其中每个个体根据对齐、聚集和分离三条基本规则确定下一步的行为,最终个体在整体上会形成各种不同的排列方式,即产生突现行为。借助Swarm 模型,可以简化复杂系统中突现规律的研究模式。Spector和Klein在文献[13]中提出了相关行为的具体计算方法,每个Agent根据周围的环境及行为参数决定下一刻的方向和速度。
2 基于Swarm模型的微博用户影响力计算
2.1 问题提出和模型框架
针对大多数微博用户影响力评价算法都是事前或事后进行计算的问题,本文结合Swarm突现计算模型提出了一种可以在不同时刻对用户影响力进行计算的方法(SMRank)。SMRank算法的模型框架如图1所示。

图1 模型框架图
2.2 微博特征及定义
由于微博用户的行为主要受自身认知水平和网络环境两大因素的影响,本文中用户的影响力由两方面构成:用户自身影响初值和用户不同时刻的行为影响力。用户自身影响初值主要通过用户粉丝数和用户在话题传播前发布微博数计算,用户t 时刻的行为影响力通过用户t 时刻交互关系网络计算,t 时刻用户交互关系网分为:t 时刻用户转发关系网和t 时刻用户评论点赞关系网。
现有的微博传播研究通常会直接以用户为节点、用户之间的关注和粉丝为边来构建用户关系网络,为了减少冗余节点信息(例如僵尸节点)对研究的影响,并非直接依赖关注和粉丝信息来构建网络,而是依靠微博话题不同时刻中用户的转发、评论及点赞关系来构建网络,为了方便问题的描述,这里先给出如下几个定义:
定义1(微博话题中t 时刻的用户转发关系网络)用户转发关系网络用一个二元组G1t=(U1t,E1t,W1t) 表示,其中,G1t表示微博话题t 时刻的用户转发关系网络,U1t表示t 时刻参与话题的全部用户,E1t表示网络中的边集合,边集合中的每条边表示两个用户之间存在转发关系,W1t为有向边的转发权重。
定义2(微博话题中t 时刻的用户评论点赞关系网络)用户评论点赞关系网络用一个二元组G2t=(U2t,E2t,W2t)表示,其中,G2t表示微博话题t 时刻用户评论点赞关系网络,U2t表示t 时刻参与话题的全部用户,E2t表示网络中的边集合,边集合中的每条边表示两个用户之间存在评论或点赞关系,W2t为有向边的评论点赞权重。
定义3(用户影响力)微博话题中用户影响力用一个四元组I=(G,U,It,f)进行表示,其中,G 包含G1t和G2t,U 表示参与话题的用户集合,It表示t 时刻的用户影响力,f 为五元组I 中各元素的映射关系。对于用户ui的影响力的定义如下:

2.3 Swarm模型定义
Swarm 模型中agent 在群体没有控制中心的环境下,完全依照自身判断与其他个体交互,从而对整体产生影响。与Swarm 模型中agent 相似,微博话题中的任一用户都可以参与发布微博、关注互动、评论点赞等功能,同时用户间的交互也会对个体的行为产生影响。根据微博话题中用户互动交流与Swarm模型中agent交流的相似性,将swarm模型融入到微博话题用户影响力评价算法中,关键在于agent 运动过程中要灵活结合用户发布微博、转发、评论及点赞等行为。
基于Spector 和Klein 在文献[13]提出的计算方法,根据本文的研究内容,在此重新定义Swarm模型的物理含义,在给出定义之前,首先了解以下两个概念:
微博话题中ui用户在t 时刻邻域用户节点。指对用户ui影响较大的用户集合,为转发用户ui微博的用户集合,在不同时刻用户ui的邻域用户是不同的,可以根据微博话题t 时刻的用户转发关系网统计得出。
微博话题中ui用户在t 时刻周围用户节点。指对用户ui有影响,但是影响不是很大的用户集合,为评论和点赞用户ui微博的用户集合,在不同时刻用户ui的周围用户是不同的,可以根据微博话题t 时刻的用户评论点赞关系网络统计得出。
定义4(面向微博话题的Swarm模型)
(1)V1在Swarm模型中代表某一agent指向远离其自身范围d 内的所有agent 的均向量,在微博中使用用户ui的邻域用户节点来进行计算,通过用户转发关系网计算。计算公式如下:

其中,U 是参与微博话题的用户集合,It-1( v )是用户v上一时刻的用户影响力,W1t( vui)是用户v 对用户ui在t 时刻的微博转发贡献度大小,Rt( vui)为用户v 对用户ui在t 时刻微博转发次数,S1t( vui)表示用户v 对话题中所有用户t 时刻转发微博总数。
(2)V2在Swarm 模型中是指向模拟世界中心的向量,在微博用户影响力评价中用上次迭代的前20%的用户影响力的均值表示。计算公式如下:

其中,Top 为上一时刻的前20%的用户集合,n 为Top用户个数。
(3)V3是某一agent 周围所有agent 的平均速度向量,在微博用户中,使用用户ui周围用户节点对用户的平均影响力来表示,计算公式如下:
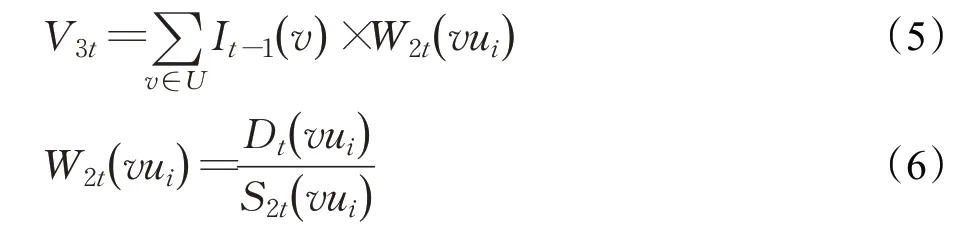
其中,W2t( vui)是用户v 对用户ui在t 时刻的微博评论及点赞贡献度大小,Dt( vui)表示用户v 对用户ui在t时刻的评论和点赞数,S2t( vui)表示用户v 在t 时刻所有评论和点赞总数。
(4)V4是某一agent 指向其周围所有agent 所构成的中心的向量,在本文中给出的计算公式如下:

其中,N 为话题中所有用户个数。
(5)V5是一个随机单位长度向量,在微博用户行为影响力计算过程中不考虑。
用户ui在t 时刻影响力公式表示为:

2.4 基于Swarm模型的微博用户影响力计算算法
一个微博话题发展要经历萌芽、酝酿、激活、高潮、平息等演变周期,这和复杂系统中鱼群、鸟群等群体的突现行为相似,本文结合突现计算模型,提出一种基于突现计算Swarm 模型的用户排序算法(Swarm Model user Rank,SMRank)。算法首先需要计算用户影响力初值;然后通过迭代计算不同时刻的用户影响力;最后对不同时刻用户影响力求和,得出用户总的影响力值。SMRank算法详细描述如下:
用户影响力初值计算,在本文中主要考虑两个方面,用户第一天发表与话题相关微博数、用户的粉丝数来衡量。使用最大最小值归一化方法进行计算,用户影响力初值计算公式如下:
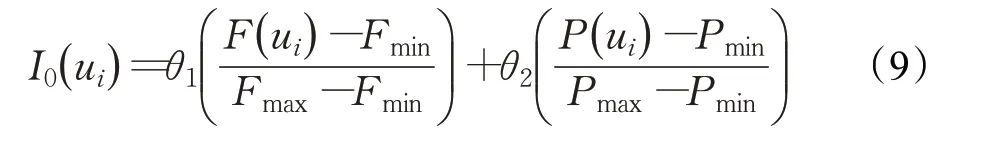
其中,F( ui)为用户ui在微博话题中的粉丝数,Fmin为用户集中用户拥有的最小粉丝数,Fmax为用户集中用户拥有的最大粉丝数,P( ui)为用户ui发布微博数(原创微博),Pmin为用户集中用户发布的最少微博数,Pmax为用户集中用户发布的最大微博数。
SMRank算法描述如下。
算法微博用户影响力计算
输入:微博话题用户参与关系网G,迭代次数T 。
输出:用户总影响力I( ui)。
执行以下步骤:
步骤1 对于用户ui,根据公式(9)计算用户影响力初值I0( ui)。
步骤2 对于用户ui,根据公式(8)计算t 时刻的用户行为影响力It( ui)。
步骤3 t=t+1;当t 小于T ,转到步骤2,否则转到步骤4。
步骤4 对于事件中所有的用户,用公式I( ui)=I1( ui)+I2( ui)+…+IT( ui)。
步骤5 计算得到最终的用户责任指数I( ui),进行排序后输出结果,算法结束。
从算法描述中可以看到,如果用户总数为 |U |,算法的迭代次数为T ,则SMRank 算法的时间复杂度为O(T |U|2)。在计算用户影响等级时,需要T |U |个额外空间存储每次迭代的用户影响力值,因此,该算法的空间复杂度为O(T |U |)。
3 用户影响力评价实验和分析
3.1 实验数据
在人们的微博社交活动中,很多时候都是以话题的形式产生和传播的。所以本文使用不同话题作为基本研究对象。使用实验室开发的爬虫软件,通过指定关键字搜索新浪微博进行爬取,爬取的数据包含用户的粉丝、关注关系,微博的评论信息和点赞关系等信息。
本文中数据集采用的是2018年11月26日至2018年11月28日的“基因编辑”和2019年2月15日至2月18日的“某品牌食品安全”的微博话题信息。经过预处理和标准化后,得到两个微博话题事件的统计信息如表1所示。

表1 数据统计
3.2 实验方案
3.2.1 实验对比对象
为了验证、评估本文方法,采用下列三种常用微博用户影响力评估算法进行对比。
(1)粉丝数量(FansRank)。按照微博用户的粉丝数量多少来对用户排名。
(2)被转发数量(RepostRank)。按照用户发布的微博被其他用户平均转发数的多少对用户排名。
(3)PageRank 算法[14]。PageRank 算法是一种用于分析网页的重要程度的算法,现已被广泛应用于社交网络分析、意见领袖识别的研究中。
3.2.2 算法参数设置
在进行实验时,需要对公式中的一些常量进行设置,设置方法如下:
公式(8)中的常量c1~c4 用层次法计算得出,层次分析法[15]是一种对复杂且模糊的问题进行量化决策的方法,在本文实验中它们的值分别为0.561 9、0.075 4、0.324 4、0.038 4。
公式(9)中θ1和θ2参数,它们的值根据粉丝数和微博数的权重不同,分别设置为:θ1=0.4,θ2=0.6。在微博话题传播中,发布微博的贡献往往高于其他行为,这里的权重按6∶4 划分,降低了粉丝数过高带来的偏差,同时也保留了粉丝数对微博用户影响力的表征能力。
3.2.3 具体实验设计
本文实验方案主要包括以下三种:
(1)用户影响力排名的合理性对比。在“某品牌食品安全”事件数据集上,针对不同方法计算得到的影响等级排名结果,分析排名靠前的用户的影响值、用户影响覆盖率[16]、发布和话题相关微博数等,以说明SMRank算法排名结果的合理性。
(2)影响覆盖率[16]对比分析。为了评价SMRank 算法的有效性,在“某品牌食品安全”事件数据集上,实验对比了FansRank 算法、RepostRank 算法和PageRank 算法,计算各方法排名结果靠前的用户的影响覆盖率。
(3)不同时间段的影响力对比。通过对排名靠前的用户不同时刻影响力进行分析,观察用户在不同时间的影响力的变化。
其中,(1)和(2)的实验方案是为了说明本文算法的有效性和合理性,实验方案(3)是本文与其他算法的主要区别。
3.3 实验结果分析
3.3.1 用户影响等级排名合理性分析
为了说明排名结果的合理性,对排名前10的用户进行分析。表2至表5分别展示了SMRank算法、FansRank算法、RepostRank算法和PageRank算法的实验结果。
表2至表5中用户编号是用户在SMRank算法中的排名序号,从用户发布微博数和用户影响覆盖率两项指标可以看出,SMRank算法的排名是比较合理有效的。
3.3.2 影响覆盖率对比
通过SMRank算法、FansRank、RepostRank和PageRank四种算法分别获得用户传播影响力排名,然后对排名前top k 的用户影响覆盖率进行对比,实验结果如图2 所示。结果表明SMRank 算法可以有效地发现微博话题中影响等级较大的用户。

表2 SMRank算法排名结果

表3 FansRank算法排名结果

表4 RepostRank算法排名结果

表5 PageRank算法排名结果
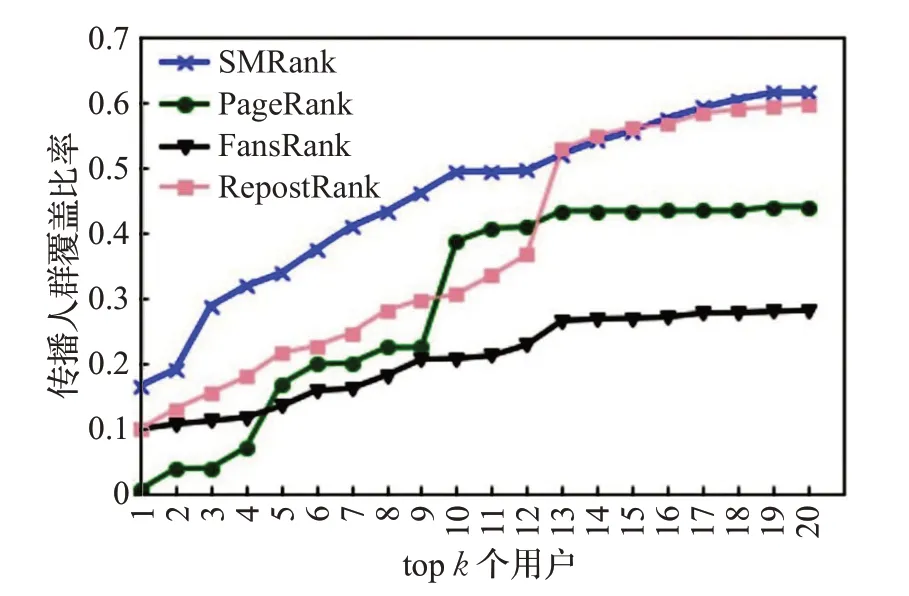
图2 “某品牌食品安全”中四种算法影响覆盖率
3.3.3 不同时间段影响力对比
本文提出SMRank 算法可以计算不同时间段不同用户的影响力,在这里时间段设置为天,在不同的数据集上时间段可以根据需要设置为更短或更长的时间(如2 h、6 h或一个月),图3和图4分别显示了不同数据集上的排名前5 的用户每天影响力变化曲线。可以看到每个用户在不同的时刻影响力是不同的;图3 中用户1 和用户4 在第一天影响力很大,而在后面两天影响力降低,说明该用户是该微博话题的发起者;用户2、用户3和用户5在第二天影响力比较大,它们是话题的主要传播者。图4中用户2、用户1、用户4和用户5在第一天有较大的影响力,说明他们对微博话题的发起起到很重要的作用,而用户1和用户3在中间时刻影响较大,说明他们是此微博话题的主要传播者;最后一天事件热度降低且即将消亡时,所有用户的影响力都减小。以上结论和真实网络中的情况是相似的。

图3 “基因编辑”中排名前5的用户每天影响力变化

图4 “食品安全”中排名前5的用户每天影响力变化
4 结论
本文在真实的微博话题中进行分析,考虑到微博话题的动态演化和突现计算的相似性,提出了基于Swarm突现计算模型的用户影响力排序算法。本文算法的评价基础不是建立在传统的关注关系网上,而是建立在从微博话题参与用户出发,结合发布微博、转发、评论和点赞等用户行为,构建不同时刻微博话题转发关系网和评论点赞关系网上;然后在这两个网络中进行算法迭代,不仅可以得出用户影响力排名,而且还可以计算出不同用户不同时间段的影响力。微博用户影响力是微博话题重要的研究方向之一,深入研究微博用户影响力对了解话题信息在微博网络中的传播以及其演化规律具有重要的意义。
本文也存在一些不足。由于实验数据的限制及不完善,对实验结果会造成一定的影响;其次,本文算法也仅仅通过实验结果表明它是有效的,缺乏充分的理论基础。
猜你喜欢
环球人物(2022年4期)2022-02-22 22:05:06
小资CHIC!ELEGANCE(2021年32期)2021-09-18 06:17:14
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
NBA特刊(2018年14期)2018-08-13 08:51:40
人大建设(2017年11期)2017-04-20 08:22:49
现代防御技术(2016年1期)2016-06-01 12:13:27
爆笑show(2015年4期)2015-06-24 01:55:12
瞭望东方周刊(2015年12期)2015-04-14 23:28:02
