
决策树与逻辑回归在商业应用中的对比研究
2021-01-22 13:40高瑞
数字技术与应用 2020年12期
高瑞
(西安财经大学统计学院,陕西西安 710100)
1 研究背景与目的
“数据挖掘”作为当前数据科学领域最为热门的关键词之一,在现实世界中得到了越来越广泛的应用与研究。数据挖掘技术作为一项知识发掘的工具,研究者可以通过与研究目的(研究者所感兴趣的目标变量)有关的数据(与目标变量存在相关性的输入变量),利用数据挖掘技术发现在这些数据中所蕴含的模式及规律,并根据不同的应用场景通过不同的方式将这些模式及规律提取出来来指导人们的行为或决策[1]。因此,数据挖掘技术为进行高效率的商业活动提供了强大而有力的支撑。人们将数据挖掘技术应用到商业活动中满足不同的业务需求,所以根据不同的业务需求选择适当的算法模型不仅能够达到预期的效果而且还能节省时间成本。
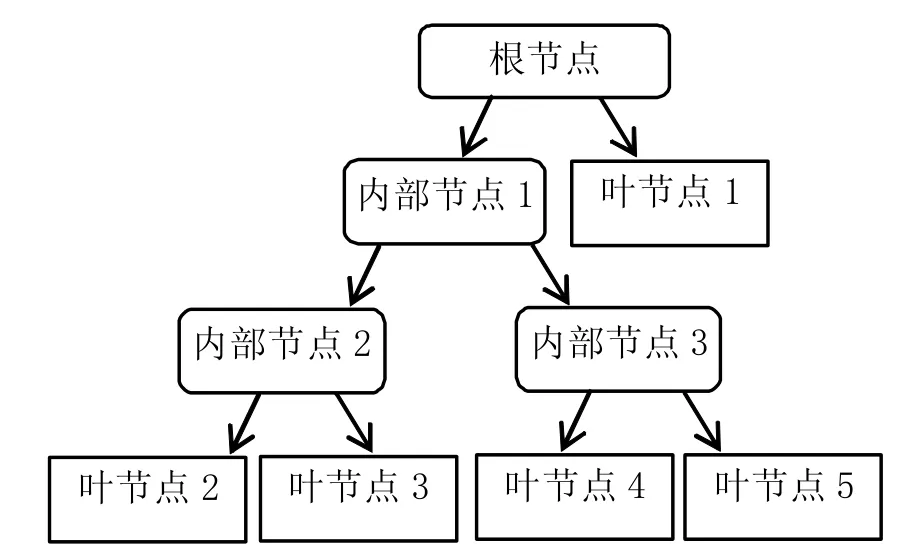
图1 决策树模型图
机器学习作为数据挖掘的常用方式解决了数据挖掘领域的四大问题:关联、聚类、分类和预测。机器学习算法中包含众多的分类算法模型,如K-Nearest Neighbor(K近邻)、Bayes Net(贝叶斯网络)、Decision Tree(决策树)、Logistic Regression(逻辑回归)、Neural Network(神经网络)、Support Vector Machine(支持向量机)等[2]。这些众多的分类算法模型都是对类别型的目标变量进行类别分类预测的方法,然而它们都有其独特的理论和算法逻辑,在复杂多样的商业活动中,其业务需求也是丰富多样的。本文以决策树和逻辑回归两种分类算法模型为例,基于它们不同的底层逻辑研究其在不同业务需求下的应用区别。
2 研究现状
2.1 决策树
决策树(如图1)是以目标类别在每个输入变量下的“纯度”为主要判断依据,综合选择对目标类别区分最为明显的输入变量作为优先节点“开枝散叶”,通过不同的对目标类别有区分能力的输入变量的不断“接力”形成二叉或多叉的树形结构,在满足模型泛化能力的前提下停止“接力”,在叶节点处做出分类判断[3]。常见的决策树算法包括C5.0和CART等,本文以C5.0为研究对象。
2.2 逻辑回归
3 研究步骤
本文通过选取来源于Kaggle的银行信贷数据Bank_Loan数据集来研究决策树和逻辑回归的应用区别(如图2),通过决策树和逻辑回归算法逻辑的不同研究除分类预测能力之外的在其它业务需求上的应用。
4 研究过程与结论
4.1 研究过程
为了更好地说明问题,本文选取了Bank_Loan数据集的部分字段Duration_in_Months(贷款期限,单位:月)、Age(客户年龄)、Status_Checking_Acc(支票账户的状态)和Default_On_Payment(违约标识)建立决策树模型和逻辑回归模型。其中Duration_in_Months、Age、Status_Checking_Acc为输入变量,Duration_in_Months和Age是数值型变量并对其用分位数法去除异常值;Status_ Checking_Acc是类别型变量(如表1)。Default_On_Payment为二分类的目标变量(如表2),0为未违约;1为违约。

表1 Status_Checking_Acc类别意义

表2 目标类别的分布情况
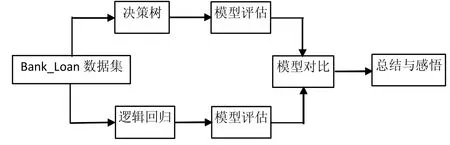
图2 研究流程图
A11表示客户的支票账户中的额度为负,银行为其进行代垫。
A12表示客户的支票账户中有小于10000美元的额度。
A13表示客户的支票账户中有大于10000美元的额度。
A14表示客户没有开通支票账户。
数据集包含有5000个观测,根据目标变量将数据集进行分层抽样,用80%的数据作为训练数据集,20%的数据作为测试数据集。用训练数据集建立决策树和逻辑回归模型,用测试数据集验证模型,模型结果如下:
(1)决策树模型。根据训练数据集生成的决策树模型(如图3)共有3个内部节点,6个叶节点。通过决策树模型的ROC曲线(如图4)可知,测试数据集在模型下的auc=0.704,说明模型有一定的预测能力。
(2)逻辑回归模型。根据训练数据集建立的逻辑回归模型,模型各项系数(如表3)有良好的显著性。通过逻辑回归模型的ROC曲线(如图5)可知,测试数据集在模型下的auc=0.717,说明模型有一定的预测能力。
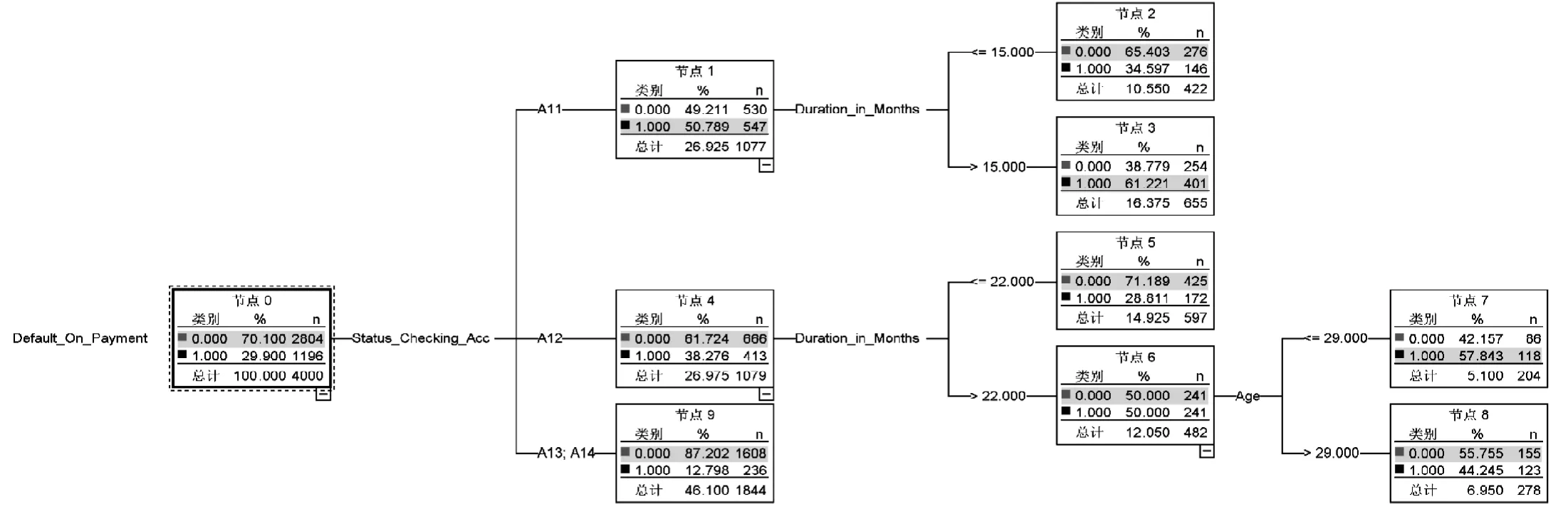
图3 决策树模型结果
根据以上可以得出:在现有的数据集下,决策树和逻辑回归均有较好的预测能力和泛化能力,并且预测的准确率不相上下。
4.2 研究结论
决策树模型和逻辑回归模型均可以对类别数据进行预测分类,并且有时其预测能力相差无几。但是由于两者分类算法的不同,使得其在对类别数据进行预测分类外还能对数据集内部的结构进行不同角度的描述。
(1)决策树模型。决策树是根据输入变量对目标类别的区分能力依次选择分支节点,用多样的条件进行逐步判断,最终得到一套规则体系。以本文的数据集为例,由于Status_Checking_Acc对客户是否违约有良好的区分能力,因此将Status_Checking_Acc作为优先的输入变量进行条件判断,再根据Duration_in_Months和Age进行条件判断,最终形成判断客户是否违约的六条规则:
规则1:若Status_Checking_Acc=A13或A14则判断客户不会违约,并且错误率为12.80%。
规则2:若Status_Checking_Acc=A11并且Duration_in_Months<=15则判断客户不会违约,并且错误率为34.60%。
规则3:若Status_Checking_Acc=A11并且Duration_in_Months>15则判断客户会违约,并且错误率为38.78%。
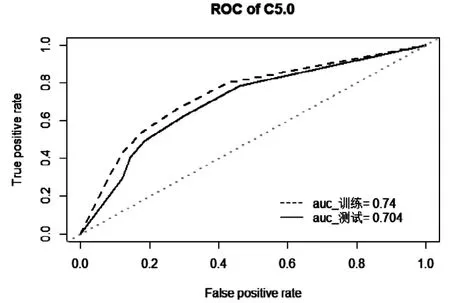
图4 ROC曲线
规则4:若Status_Checking_Acc=A12并且Duration_in_Months<=22则判断客户不会违约,并且错误率为28.81%。
规则5:若Status_Checking_Acc=A12并且Duration_in_Months>22;Age<=29则判断客户会违约,并且错误率为42.16%。
规则6:若Status_Checking_Acc=A12并且Duration_in_Months>22;Age>29则判断客户不会违约,并且错误率为44.25%。
因此,决策树模型除了能够对类别数据进行预测分类外还能生成基于业务的若干条规则,可以让业者清晰业务框架,业者所关注的目标是由哪些因素相互组合的结果。
(2)逻辑回归模型。逻辑回归模型与线性回归模型类似,是根据输入变量对目标变量的影响权重加权求和得到最终的结果。因此可以通过逻辑回归掌握输入变量与目标变量的数值关系。以本文的数据集为例,控制Status_Checking_Acc和Age观察Duration_in_Months,此时逻辑回归方程为:

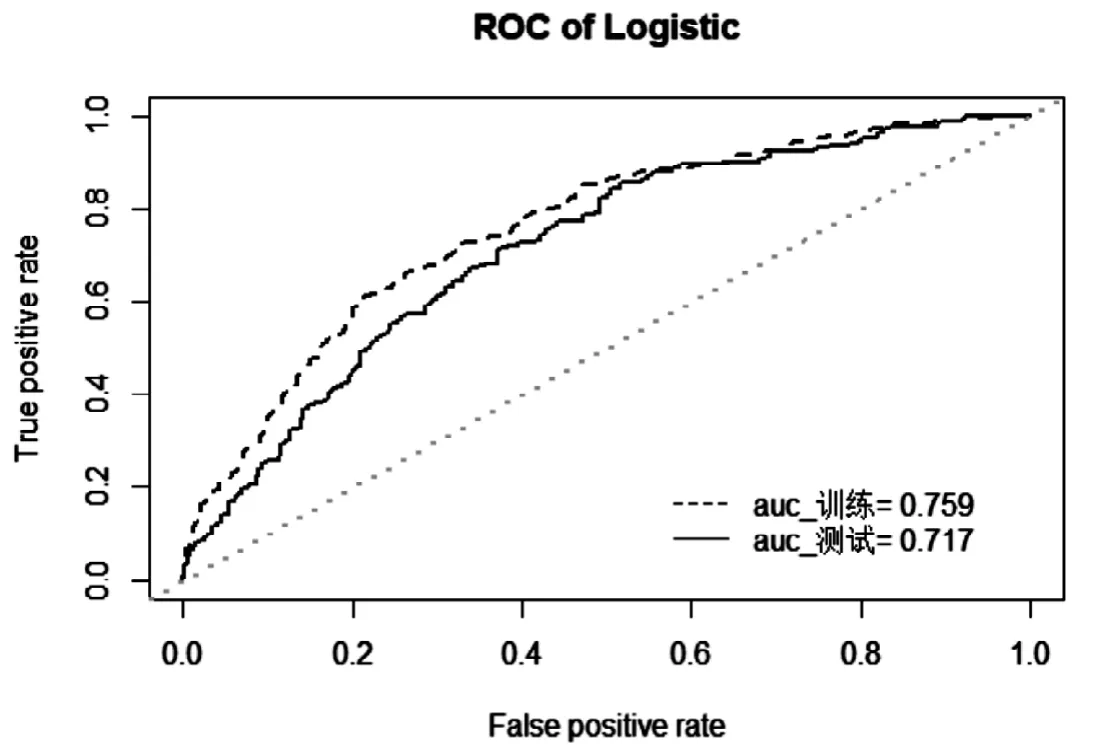
图5 ROC曲线
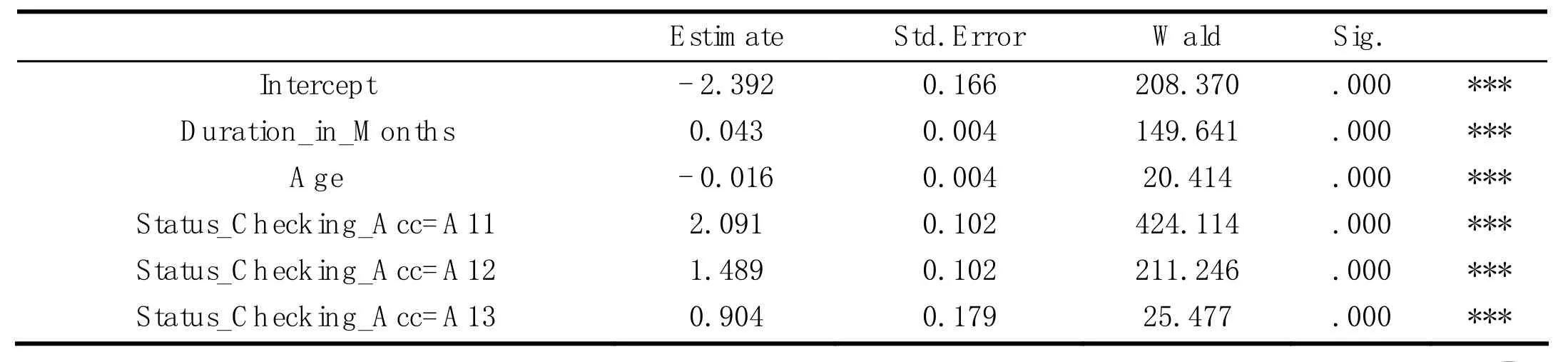
表3 逻辑回归模型结果

公式(2)除以(1)得:

说明Duration_in_Months每增加一个单位,客户违约的概率将会比原先增加
同理,控制Status_Checking_Acc和Duration_in_Months观察Age,说明Age每增加一个单位,客户违约的概率会比原先降低
以本文的数据集为例,控制Duration_in_Months和Age观察Status_Checking_Acc,将Status_Checking_Acc=A14作为参照,此时:
当客户的Status_Checking_Acc=A11时违约的几率是客户的Status_Checking_Acc=A14时的exp(2.091)=8.09倍。
当客户的Status_Checking_Acc=A12时违约的几率是客户的Status_Checking_Acc=A14时的exp(1.489)=4.43倍。
当客户的Status_Checking_Acc=A13时违约的几率是客户的Status_Checking_Acc=A14时的exp(0.904)=2.47倍。
因此,逻辑回归模型除了能够对类别数据进行预测分类外还能生成输入变量与目标变量之间的数值关系,让业者更加清晰输入变量对目标变量的影响程度。
基于以上,在机器学习中用于分类的算法模型有很多种,虽然都是用来分类的方法,但是它们由于各自算法逻辑的不同使得在商业环境下能够为特定的业务需求提供支持。以本文为例,若业者想要了解所关注的目标是由哪些规则生成的,可以考虑使用决策树算法;若业者想要了解影响所关注目标的因素对于目标的影响权值以及它们内在的数量关系,可以考虑使用逻辑回归算法。要根据所使用的业务场景选择适当的模型处理问题,简单问题用简单模型;复杂问题用复杂模型但更要使用适合的模型解决问题。
猜你喜欢
法律方法(2022年2期)2022-10-20
中学生百科·大语文(2021年11期)2021-12-05
纺织科学研究(2021年7期)2021-08-14
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
新校长(2016年8期)2016-01-10
郑州大学学报(医学版)(2015年1期)2015-02-27
商事法论集(2014年1期)2014-06-27
中国中医药现代远程教育(2014年16期)2014-03-01
