
基于Stacking模型融合的商户赌博监测算法研究
2021-01-22 13:40张野叶国林李欣刚
数字技术与应用 2020年12期
张野 叶国林 李欣刚
(银联商务股份有限公司,上海 201203)
0 引言
据统计,我国境外赌博网站目前达到2000多个,网站注册的赌博会员有数百万人[1]。赌博是社会的不安定因素,对赌博的个人来说容易造成因嗜赌而倾家荡产。对于国家来说,我国每年因为网络赌博而流失到境外的资金高达几百亿元。银联商务作为国内最大的收单机构,服务于近800万的商户,某些少数非法商户,利用银联商务的POS机或者条码支付进行线上或者线下的赌博活动,严重违反了收单和支付市场主体合规经营意识,损坏了个人利益、国家利益和公司形象。可见监控打击网络赌博迫在眉睫,付顺顺[2]提出使用机器学习算法对网站内容做分本分类,以识别赌博网站。由于在金融支付领域的赌博监测属于商业风控领域,且与企业业务密切相关,所以相关研究公开较少。本文提出基于组合Random Forest、GBDT、SVM和Logistic Regression的Stacking集成学习算法RGSL,以银联商务入网的商户静态信息和商户的交易流水记录等构造商户特征,建立组合模型。通过分类器融合,能够解决单个分类器易过拟合及其自身的局限性,效果更加准确。

图1 随机森林实现原理
1 算法介绍
1.1 Random Forest(随机森林)算法
随机森林[3]由Breiman等人提出,由多棵CART树组成,是典型的Bagging集成算法。算法模型最后的分类结果为每棵树投票所得,即得票最多的类为最终分类结果。随机森林的实现原理如图1。
随机森林的随机性体现在样本的随机性和特征的随机性:
(1)样本随机性:在构造每棵树的输入数据集时,从原始数据集中采取有放回的方式抽样,最终得出与原始数据集数量相同的一个子数据集,该子数据集中的样本可以存在重复。通过样本随机性实现了基分类器的多样性。
(2)特征随机性:在样本随机性基础上生成的数据集中,随机选取个特征的子集,d为全部特征的个数,接着选择一个最优的特征进行划分。通过特征随机性,不仅能够关注单棵树的性能,而且减少了树与树之间的相关性,提高了模型的性能,减少了模型的方差,增加了算法对噪声的鲁棒性。
1.2 GBDT(梯度提升树)算法
梯度提升树是集成算法Boosting中最具有代表性的一种[4],是将弱学习器提升为强学习器的算法。它的每一次计算都是为了减少上一次的残差(残差是指真实值与当前预测值之间的差值),而为了减少这些残差,在残差减少的梯度方向上建立一个新的回归树。最终的模型为整个迭代过程生成的回归树的累加。GBDT的迭代过程为:
对第t轮第i个样本计算残差为:

对回归树的每个叶子节点计算最小的损失函数,得到最佳的叶子节点输出值:

其中Rtj是第t棵树对应叶子节点区域,j为树的叶子节点个数,θ为初始常数,最终的GBDT模型为:

GBDT每一步都会在上一轮的基础上更加拟合原数据,所以可以降低偏差。
1.3 SVM(支持向量机)算法
SVM算法由Vapnik[5]提出,用于分类问题时,其核心思想是在分类准确率最高的同时,寻找一个能够将训练集正确划分且最大化两个类的间距的超平面,如图2所示。SVM不仅可以用于线性可分的数据,对于线性不可分的情况,可以通过核函数将数据映射到高维的特征空间,此时高维特征空间的数据是线性可分的。
SVM算法流程如下:
输出:分类超平面和决策函数
步骤1:构造带约束的最优化问题:

约束条件是:

图2 SVM原理图

其中iξ为松弛因子,C>0为惩罚系数。

其约束为:
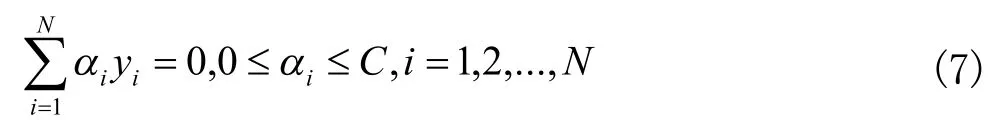

步骤3:求解超平面:

决策函数:

在支持向量机训练过程中,因为对偶问题,目标函数与决策函数的只涉及样本的内积计算,所以对于线性不可分的样本,只需要使用核函数K(x,z)替代内积计算,线性不可分的决策函数为:

1.4 RGSL Stacking算法
Stacking算法与Bagging、Boosting算法的区别是:Stacking算法采用一种特殊的结合策略,主要结合不同类型的基学习器,而后两者结合的都是相同类型的基学习器。周志华[6]提出,不同类型模型之间较低的相关性可以提高模型的误差校正能力,因此模型结果的差异性越高,最终Stacking集成模型的效果也会越好。李强[7]通过Stacking算法对员工离职预测分析,李珩[8]通过Stacking算法对中文组块分析,结果显示,在不同领域上,使用不同基分类器的Stacking模型融合算法的效果都要比单一基分类器效果好。Stacking算法主要分为2层,第一层的分类器为基分类器,第二层的分类器为元分类器,简要步骤为:将多个基分类器的输出结果作为新的特征,输入到元分类器中用于新的训练学习。
RGSL分别采用随机森林、梯度提升树和支持向量机作为基分类器,逻辑回归作为元分类器。第一阶段:样本的80%作为训练集Train,20%作为测试集Test。训练集采用5折交叉验证构建模型,分别为Train1、Train2、Train3、Train4和Train5,用随机森林、梯度提升树和支持向量机分别训练5次,并每次对Test做预测,每个模型会分别得出5个验证集的结果和5个测试集的结果。其中随机森林的验证结果为rfv1~rfv5,测试结果分别为rft1~rft5;梯度提升树的验证结果为gbtv1~gbtv5,测试结果分别为gbtt1~gbtt5;支持向量机的验证结果为svmv1~svmv5,测试结果分别为svmt1~svmt5。纵向叠加验证集结果,依次分别为RFD、GBTD和SVMD;平均取值测试集结果,分别为RFT、GBTT和SVMT。第二阶段:将第一阶段的RFD、GBTD和SVMD横向合并作为新的训练集,RFT、GBTT和SVMT横向合并作为新的验证集,并使用逻辑回归算法训练,得出最终的模型结果。RGSL Stacking的算法模型如图3。

图3 RGSL Stacking算法模型

图4 数据处理流程
2 实验及分析
2.1 实验数据
实验源数据采用的是银联商务2019年9月~2019年12月的商户收单流水以及静态商户信息,通过数据清洗、勾兑、特征选择等操作,汇总出以商户为维度的计125多万的样本,每个样本包含155个动态特征和17个静态特征。数据的部分特征如表1。

表1 数据部分特征
实验数据在特征选择时的最大时间切片跨度为30d,原始特征计算完毕后,进行特征工程,其中包括对连续型特征做95%分位数和5%分位数值截取以及最小最大值归一化,对类别型特征做浓度编码,得出可以直接输入到模型的数据特征。实验数据的处理流程如图4。
2.2 实验环境
由于银联商务的生产数据存储在大数据集群中,大数据框架是Cloudera,数据文件存储在HDFS上,结构化的表数据存储在Hive,所以本实验计算框架采用的是Spark,机器学习相关计算采用的是Spark的Spark MLilib。
2.3 评价指标
本次实验属于分类任务,所以采用混淆矩阵对实验结果进行评价分析。实验关注的是赌博商户,所以将赌博商户定义为正样本,其他商户为负样本,混淆矩阵如表2。
根据混淆矩阵,计算准确率P,召回率R和综合指标F1值。计算公式如下:

表2 混淆矩阵

表3 4种算法的分类结果

2.4 实验结果及分析
将2.1中处理好的特征数据,在2.2的实验平台上用1.4提出的算法做模型训练和评估,并采用1.4中的三个基分类器分别建模,比较四种模型的评价指标,如表3。
由表3可知,这四种算法模型的P和R都有较高的值,都在90%以上,说明数据特征较好,但是RGSL Stacking算法的结果都优于其他模型,这是因为RGSL Stacking算法使用了二阶训练的方式,在第二阶段训练时输入的训练集是RF、GBDT和SVM的结果,并没有使用原始的数据集,最大程度地避免了过拟合的风险,使得实验结果更加准确。
3 总结
本文针对银联商务的赌博商户监测任务提出了基于Stacking模型融合的算法,实验结果表明,该算法在一定程度上可以防止过拟合,与单一的模型对比,在准确率和召回率上都有了显著的提高。在金融风控领域,该效果的提高,可以及时监测出赌博商户,降低金融风险和减少损失,有实际的应用价值,银联商务已经落地应用。
猜你喜欢
金卡生活(2021年12期)2021-12-15
金卡生活(2021年9期)2021-09-13
金融周刊(2018年13期)2018-12-26
四川党的建设(2018年21期)2018-12-05
电子测试(2018年1期)2018-04-18
儿童故事画报·智力大王(2017年10期)2018-03-14
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
中国交通信息化(2016年8期)2016-06-06
电测与仪表(2014年15期)2014-04-04
