
深度学习在主动脉中膜变性病理图像分类中的应用
2021-01-21 03:23:42孙中杰赵艳丽秦曾昌
计算机应用 2021年1期
孙中杰,万 涛*,陈 东,汪 昊,赵艳丽,秦曾昌
(1.北京航空航天大学生物与医学工程学院,北京 100191;2.北京航空航天大学生物医学工程高精尖创新中心,北京 100191;3.首都医科大学附属北京安贞医院病理科,北京 100029;4.北京航空航天大学自动化科学与电气工程学院,北京 100191)
0 引言
胸主动脉瘤和夹层(Thoracic Aortic Aneurysm and Dissection,TAAD)是最具临床危险性的心血管疾病之一[1]。TAAD 的主要病理形态学改变是中膜变性(Medial Degeneration,MD),因此,中膜变性的识别和评估对TAAD 的诊断、病因学研究及早期疾病干预具有重要的临床意义。非炎性主动脉MD 病变类型主要包括平滑肌细胞核缺失(Smooth Muscle Cell Nuclei Loss,SMCNL)、弹力纤维断裂或缺失(Elastic Fiber Fragmentation and/or Loss,EFFL)、层内型粘液池聚集(Intralamellar Mucoid Extracellular Matrix Accumulation,MEMA-I)和穿层型粘液池聚集(Translamellar Mucoid Extracellular Matrix Accumulation,MEMA-T)[2](如图1所示)。在临床诊断中,MD 诊断需要病理医生在显微镜下对主动脉壁组织切片进行观察和人工判断,具有主观性强、一致性差、耗时费力等缺点,导致该类疾病诊断的准确率不高。例如,SMCNL 容易受到周围组织的影响,EFFL 与正常组织形态相似,识别较困难。此外,区分MEMA-I 和MEMA-T 是根据黏液样细胞外基质是否显著改变组织的层状结构,对医师的专业知识和经验要求比较高,因此,迫切需要智能化的辅助诊断方法来解决医师分析的局限性。
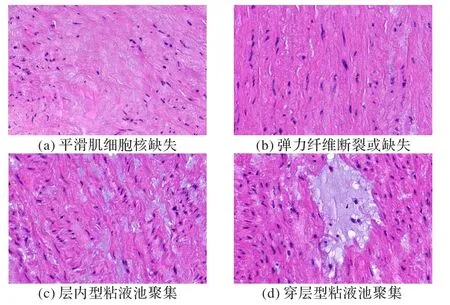
图1 四种非炎性主动脉中膜变性病理图像Fig.1 Histopathological images of four types of non-inflammatory aortic medial degeneration
随着计算机技术和图像处理算法的快速发展,计算机辅助诊断(Computer Aided Diagnosis,CAD)技术不仅可以帮助医生获得准确的诊断结论,而且能够提高诊断效率。例如,Wojnarski 等[3]采用机器学习方法来识别计算机断层扫描(Computed Tomography,CT)图像中主动脉病变亚类型,探究主动脉瓣膜形态和患者特征的关联性。Parikh 等[4]通过计算CT 图像中腹主动脉瘤壁厚和腹主动脉直径等几何指标对主动脉瘤进行分类。另外,Mohammadi 等[5]研究者基于卷积神经网络(Convolutional Neural Network,CNN)设计了一种深度学习分割方法将腹主动脉瘤从CT 图像上自动提取出来。以上研究表明虽然智能化的诊断系统已经较广泛地用于主动脉病变的识别研究中,但该技术在非炎性主动脉中膜变性程度的辅助诊断的相关研究仍然缺乏;并且,由于病理图像的高度复杂性,使得病理图像的自动分析仍然是一个极具挑战性的领域。
本文使用了一种改进的基于GoogLeNet[6]的卷积神经网络模型,用来设计区分MD 四种病变的分类方法。首先,采用迁移学习方法对该模型进行预训练,将先验知识应用于病理图像的表达,随后对模型进行微调训练;并使用Focal loss 和L2 正则化解决数据不平衡问题,进一步优化模型性能。该深度学习方法实现了对MD 四种病变的自动分类,为建立大规模病理图像的智能分析系统提供了新思路。
1 数据集和评价指标
1.1 数据集
1.1.1 数据标注
本文收集了106 例诊断为主动脉中膜病变患者的高分辨率组织病理图像。所有的病理切片在临床医学专家参与下取材、制片、苏木精—伊红染色法制作而成。图像的采集设备为3DHISTECH 公司的全切片扫描仪(Pannoramic,3DHISTECH Ltd.,Budapest,Hungary)。一位拥有10 年以上经验的病理专家,使用开放的数字切片处理软件CaseViewer,在病理图像上勾画出病灶区域,并且给出相应的MD 病变类型。其中,SMCNL 标签显示区域中存在细胞核缺失,EFFL 标签表明该区域出现明显并且严重的弹力纤维断裂,MEMA-I和MEMA-T分别表明病变区域包含不同程度和范围的粘液池。为了减少单个医生判断的主观性,一名高级别病理学家对标注结果进行了复查。
1.1.2 数据集制作
从所标注的病变区域提取了3 087 张图像块,包括663 张SMCNL、1 455 张EFFL、873 张MEMA-I 和96 张MEMA-T。训练集、验证集以及测试集按照比例6∶2∶2 进行随机划分,并且保证三个数据集具有相同的病变类型分布。为了避免分类偏差,训练和测试样本同时不包含来自同一患者的图像块。
1.1.3 数据增强
有限的标注图像和四种MD 病变类别之间的不平衡将会导致分类结果偏向于拥有更多数据的类型。因此,使用数据增强方法,将图像块分别旋转60°、90°、180°和270°,并结合随机裁剪,从而产生五倍的图像样本。数据增强不仅能够扩大训练数据集,同时能够使模型训练更加稳定。
1.2 评价指标
分类性能使用准确率(ACCuracy,ACC)、精确率(PREcision,PRE)、灵敏度(SENsitivity,SEN)和F 值(Fmeasure)四个指标进行量化,其计算公式表示为:

其中:TP、TN、FP、FN分别代表真阳性(True Positive)、真阴性(True Negative)、假阳性(False Positive)和假阴性(False Negative);F值是精准率和灵敏度的调和平均值。在四分类中,上述指标的计算方法与二分类相似,即计算某一类型病变时,其余三类病变被视为相同的类别。
2 深度学习方法
将深度学习方法应用于MD 四种病变类型的分类,能够自动识别MD 的四种病变类型,包括SCML、EFFL、MEMA-I 和MEMA-T。该方法流程如图2所示。
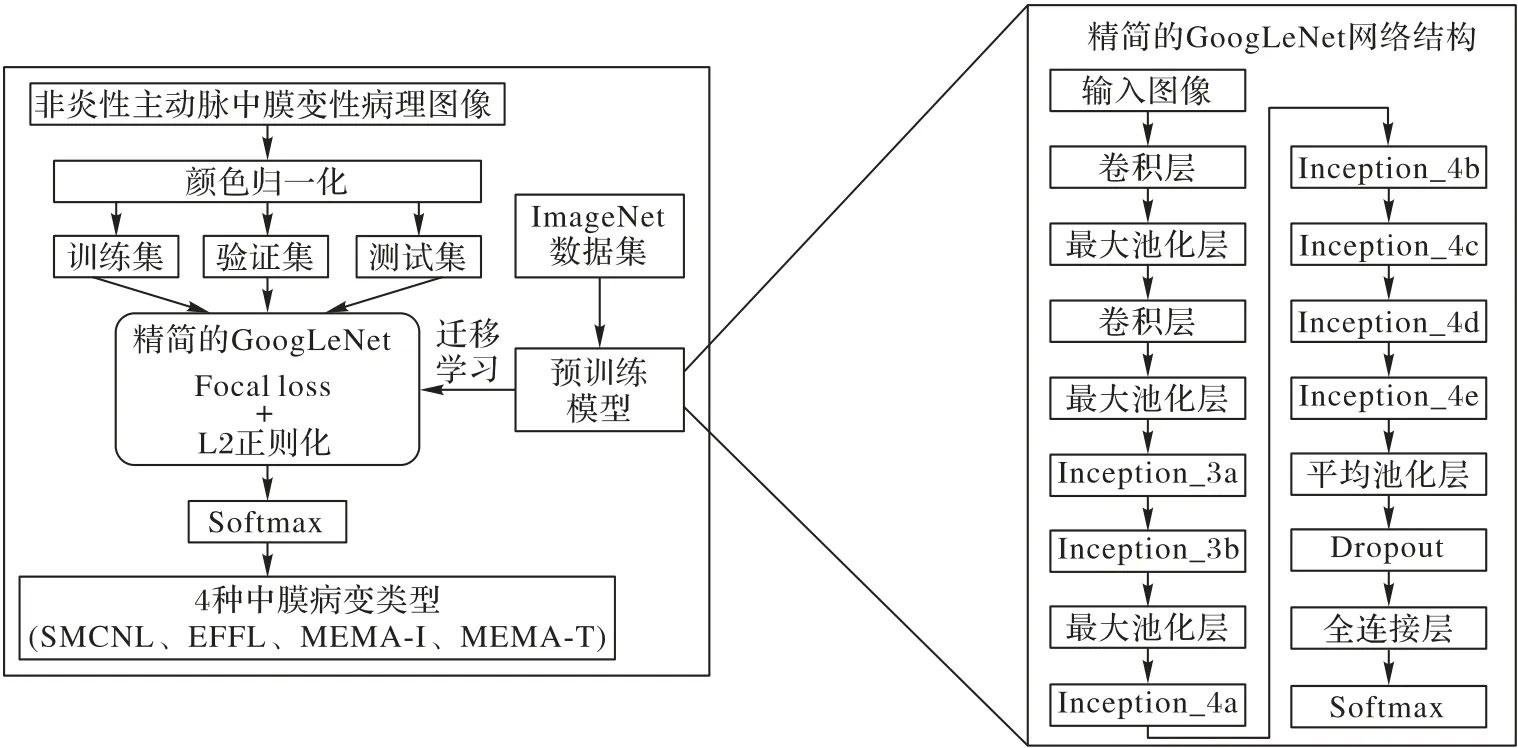
图2 中膜变性病理图像分类方法流程Fig.2 Flowchart of classification method of MD histopathological images
2.1 图像预处理
2.1.1 颜色归一化
由表8可知随着染色温度的增加,棉条表观深度K/S值提高,但温度超过70℃以后,K/S值减小。这是由于温度升高,染料加速扩散,上染速率提高,同时染料水解速率提高,但在一定的温度范围内,温度提高,染料上染速率大于水解速率,但是当超过合适温度时,染料的水解速率大于上染速率,所以上染率降低,棉条得色浅,因此选择染色温度70℃为宜。
在对主动脉壁组织样本进行染色制片以及扫描的过程中,由于染色的实验室条件、数字扫描仪的参数设置和光照的不同,往往会造成数字病理图像的颜色差异。颜色归一化操作不仅能够保证图像颜色的一致性,同时保留病理图像中存在的生物信息,进而提升模型的分类性能。采用一种基于染色分离的归一化方法[7],来减少组织病理学图像的颜色差异,同时通过生成染色密度图来尽可能保存细胞内的结构信息[8]。
2.1.2 训练样本的生成
医生手动标注的病灶区域面积大小相差较大。例如,SMCNL类型的病灶面积在300像素×300像素至600像素×600像素之间,然而MEMA-I 类型的病灶面积在80 像素×80 像素至150像素×150像素之间。经过比较不同输入图像尺寸对分类性能和计算复杂度的影响,选择病灶区域的裁剪大小为224 像素×224 像素。因此,有些较小的病灶区域通过扩大裁剪区域而获得大小一致的图像块。所提取的病理图像块作为模型训练和测试的数据集。
2.2 深度卷积神经网络模型的设计
以改进的GoogLeNet 网络结构为基础,对病理图像的四种MD 病变类型进行分类。在多分类任务中,输入的病理图像包含了主动脉中膜组织的多样病理性变化。例如,在MEMA-T 病理图像中,黏液状细胞外基质的增加显著改变了层状单位的排列(如图1(d)所示)。先验实验表明,GoogLeNet模型在处理这种具有微观结构的复杂组织病理图像具有优势,并且能够达到较高的分类精度。
GoogLeNet 是具有22 层网络结构的深度模型。提升网络性能的常用方法是增加网络的深度和宽度,但是这将会导致更巨量的参数,同时加大模型训练的计算量和难度。大量的模型参数容易产生过拟合,不利于获得最优的分类结果。受到Arora 等[9]理论工作的启发,Szegegy 等[6]提出了一种称为Inception 的模块化网络结构,将全连接甚至一般的卷积转化为稀疏连接,从而保持网络的稀疏性。该模型采用密集成分来近似最优的局部稀疏结构,极大地降低了参数量,提高了计算效率,其基本结构如图3所示。Inception 网络采用3种不同大小的卷积核学习图像特征,获得不同大小的感受野,通过拼接实现不同尺度特征的融合。另外,模型在卷积层前增加了1×1的卷积核对数据进行降维,从而提高了计算效率。

图3 Inception网络结构Fig.3 Inception network architecture
如图2所示,GoogLeNet模型中使用了9个Inception模块。随着网络层数加深,所提取的特征越抽象,相应的感受野也更大。因此,GoogLeNet在更深的网络层上增加了卷积核的个数来更有效地计算图像特征。最后,在卷积层后执行全连接操作,使用Softmax分类器实施多分类任务,得到MD病理图像的分类结果。
由于GoogLeNet 网络层数较深,在提取到更深层次特征的时候,感受野的扩大会产生特征消失的问题,从而对病理图像分类精度造成影响。针对实验所使用的病理图像中细胞微观结构特点,根据已有研究对GoogLeNet 模型的结构进行了精简和优化[10]。GoogLeNet深度学习网络具有模块化特点,并且每个Inception模块拥有相同的结构。通过选取不同数目的Inception 模块对网络进行训练,发现模型在Inception_4e 后分类结果提升缓慢,即网络达到最优性能。因此,本文去除了GoogLeNet 在Inception_4e 之后的结构,并且直接使用平均池化层和全连接层对特征图进行分类输出。精简后的网络不仅能够进行有效分类,而且节省约30%的计算资源,其与原始网络在图形处理器(Graphics Processing Unit,GPU)运行性能对比情况如表1所示。

表1 精简的GoogLeNet与原始网络的对比Tab.1 Comparison between simplified GoogLeNet and the original network
2.3 迁移学习
使用ImageNet大型数据集对模型进行了预训练。虽然病理图像与自然图像区别较大,但是自然图像中所包含的低级特征,例如点、线、颜色等,能够为病理图像分类任务提供先验知识;并且,通过从自然图像中提取这些特性,有助于加速模型的训练过程。此外,预训练后获得的模型权值参数可以用来初始化GoogLeNet模型。
2.4 Focal loss 和L2正则化
在训练模型的过程中,发现数据类型不平衡严重影响了模型的分类性能。训练集中所包括的四种MD 病变类型SMCNL、EFFL、MEME-I和MEME-T样本比例为7∶15∶9∶1。与标准的交叉熵(cross entropy)损失函数相比,Focal loss[11]可以更加关注分类困难和错误的样本,降低易分样本的损失值占比,进而更好地处理数据不平衡的问题。如图4 所示,相对于交叉熵损失,Focal loss产生的损失值曲线衰减更快,且曲线更加平滑。Focal loss函数可以定义为:

其中:Pt是模型在分类任务中对某一样本的预测概率;超参数α和γ分别起到调和正负样本不均匀和控制损失值曲线移动的作用。另外,引入了L2 正则化来控制模型的复杂度,避免由于样本不平衡而引起的过拟合问题。模型使用的损失函数定义为:
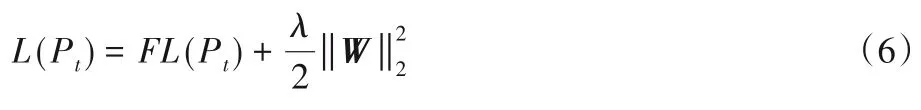
其中:W是模型权重系数向量;λ是控制正则化强度的正则化系数。
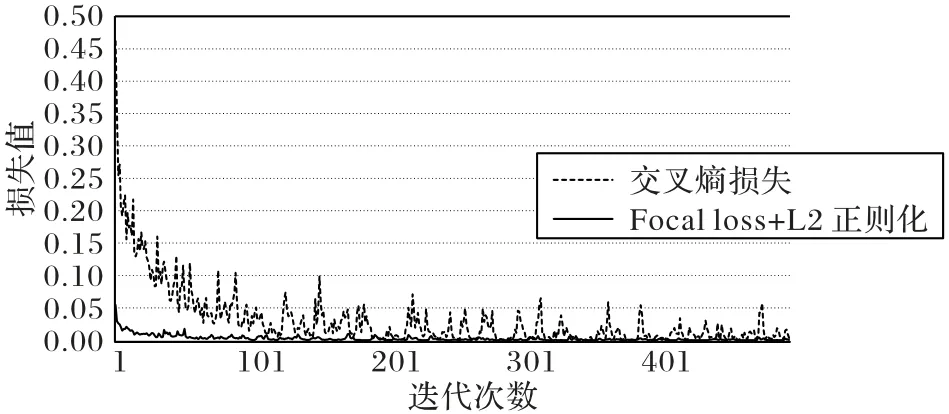
图4 交叉熵损失和使用L2正则化的Focal loss生成的损失值曲线Fig.4 Loss value curves generated by cross-entropy loss and Focal loss with L2 regularization
3 实验结果与分析
模型搭建采用基于Pytorch 的深度学习框架。模型训练使用高性能计算平台(华为G5500 系列服务器)和NVIDIA V100 GPU 卡。训练参数设置:批次大小(batch size)为32,学习率(learning rate)为0.001,轮次(epoch)为1 500。使用Adam 网络优化器来更新权值参数。模型训练需要大约23 400 s。图像预处理使用的是Matlab R2018b 平台和python3.7。通过手动调整L2 正则化的参数(λ=0.001)来获得最好的训练效果。Focal loss 涉及的两个关键参数为α=0.25 和γ=2。该参数组合的设定是根据前期工作结果,保证模型能够获得最好的分类性能[12]。
3.1 多分类结果
为了更好地可视化分类结果,将分类结果的混淆矩阵展示成如图5 所示的柱状图。图5 显示了在包含618 个数据样本的测试数据集对SMCNL、EFFL、MEMA-I 和MEMA-T 的分类结果。其中,SMCNL 和EFFL 分别有两个样本被错分为其他类型。该模型对SMCNL 和EFFL 的识别分辨能力较好。相较于SMCNL 和EFFL,MEMA-I 和MEMA-T 有较多的错分样本,尤其有约16%的MEMA-T 被识别为MEMA-I。原因是两种病变类型在图像上显示出相似的病理表征。另外,由于较严重的数据不平衡,MEMA-T 数据样本较少造成分类结果较差。

图5 中膜变性病理图像四分类结果Fig.5 Four-class classification results for MD pathological images
将改进的GoogLeNet 与四种常用的分类模型VGG16、AlexNet[12]、ResNet[13]和MnasNet[14]做对比,如表2所示。

表2 不同模型的多分类结果对比 单位:%Tab.2 Comparison of multi-classification results of different models unit:%
所有模型采用了相同的数据增强、迁移学习、L2 正则化和Focal loss。通过观察表2,发现改进的GoogLeNet 在MD 分类性能方面优于对比模型。EFFL 在所有分类指标中都获得了最好的结果。MEMA-I在准确率、精确率和F值取得了最好结果。SMCNL 的准确率和精准率是最高的。由于数据的不平衡,并且测试数据集中包含的MEMA-T 样本较少,MEMA-T的分类结果较差。ResNet 模型的表现也较好,其拥有18 层网络结构,和本文采用的GoogLeNet 精简模型的网络深度接近,另外其引入残差学习来提升模型的分类性能[15]。但是,由于MD 各病变类别间的病灶面积大小相差较大,而GoogLeNet 引入了不同大小的卷积核,可以更好地提取MD 的上下文信息,因此其性能优于ResNet。相较于其他网络,AlexNet 表现较差,其主要原因是AlexNet 是一种具有8 层网络结构的浅层网络,捕捉病理图像特征的能力有限,因此它在MD 分类任务中的准确率较低。对比结果表明,改进的GoogLeNet 模型能够从病理图像中识别出特定的组织病理变化,用来帮助提升MD四种病变类型的自动分类。
表2 的结果显示MEMA-T 的分类结果较差,主要是该数据样本数量较少,存在严重的数据不平衡。因此,本研究使用合成类过采样技术(Synthetic Minority Oversampling TEchnique,SMOTE)算法对MEMA-T 样本进行过采样,将样本数量增加至原来的5 倍,从而缓解数据不平衡问题。通过观察表3,发现MEMA-T 分类的三项评价指标(SEN、PRE 和F值)均得到了有效提升,表明数据增强有助于改善存在数据不平衡问题的病理图像的分类性能。

表3 使用SMOTE方法前后MEMA-T分类结果对比 单位:%Tab.3 Classification result comparison of MEMA-T before and after using SMOTE method unit:%
3.2 消融研究
为了提高模型的训练效率和稳定性,L2 正则化用来消除训练过程中存在的过拟合现象。本文使用Focal loss 代替交叉熵损失函数来解决数据不平衡问题。为了评估模型中不同方法的有效性,以训练集、验证集和测试集的四种病变平均分类准确率为评价指标,进行了消融研究。
表4 的结果显示精简的GoogLeNet 模型获得了与原始模型相当的分类性能,其中粗体文本、Goo、Ent、Aug、Tran、L2 和Foc 分别表示最佳性能、精简的GoogLeNet、交叉熵损失函数、数据增强、迁移学习、L2 正则化和Focal loss 损失函数。数据增强和迁移学习都可以增进模型的分类性能,并且这两种方法的组合使用比单独使用能够获得更高的分类准确率。L2正则化的使用在一定程度上抑制了过拟合,增强了模型拟合函数的稳定性。Focal loss能够通过减少易分类样本损失值的占比,并强制对难分类样本进行训练,从而进一步提升多分类性能。在本文的病理数据中,MEMA-I 和MEMA-T 是两种相似的病变类型,区分比较困难。相较于原始的GoogLeNet 模型,精简的GoogLeNet 对MEMA-I和MEMA-T 的分类准确率提高了约4个百分点。

表4 消融研究结果 单位:%Tab.4 Ablation study results unit:%
4 结语
本文采用了一种基于深度学习的计算机辅助方法对四种非炎性主动脉中膜病理图像(SMCNL、EFFL、MEMA-I、MEMAT)进行自动分类。利用精简的GoogLeNet 模型来提高训练效率,有效地使用数据增强、迁移学习和L2 正则化进一步提升网络性能。采用Focal loss 解决实际存在的中模变性病理图像数据不平衡问题。实验结果表明,精简的GoogLeNet 模型在MD分类性能指标上优于常用的深度学习模型。本文研究为深度学习技术用于基于病理图像的非炎性主动脉中膜病变分类提供了新思路。在未来工作中,将获取数量更多、种类更广的病理图像,进一步提升模型的泛化能力。
猜你喜欢
心肺血管病杂志(2019年6期)2019-07-12 09:04:34
数学年刊A辑(中文版)(2019年1期)2019-01-31 02:35:44
数学杂志(2018年5期)2018-09-19 08:13:48
中成药(2016年8期)2016-05-17 06:08:19
中国继续医学教育(2015年5期)2016-01-07 07:38:18
环境科技(2015年2期)2015-11-08 12:11:32
数学年刊A辑(中文版)(2014年5期)2014-11-01 05:43:38
心血管病学进展(2014年4期)2014-02-28 20:09:08
哈尔滨医药(2014年4期)2014-02-27 13:35:28
中国医学科学院学报(2013年2期)2013-03-11 20:25:48
