
基于增强BiLSTM的网络文章核心实体识别
2021-01-19 02:26曲卫东杨艺琛
计算机技术与发展 2021年1期
周 康,曲卫东,杨艺琛
(长安大学 信息工程学院,陕西 西安 710064)
0 引 言
随着互联网的迅速发展,网络文本数量呈现指数级增长,逐渐成为21世纪最有价值的资源之一。以文章为主体进行情感分析、舆情监测等任务也逐渐成为自然语言处理(natural language processing,NLP)领域的热门方向之一。识别文章的核心实体是进行情感分析、舆情监测等工作的基础步骤,要想从互联网上海量的文本信息中获取文章核心实体,依靠传统人工阅读的方式需要消耗大量时间和人力成本,如何迅速准确地获取文章的核心实体成为当下亟待解决的问题。随着机器学习技术在自然语言处理领域的兴起,针对文本信息中语义不明晰等问题,命名实体识别(named entity recognition,NER)的研究逐渐转向了机器学习方向,特别是随着近年来深度神经网络的应用命名实体识别系统的性能得到了大幅提高。Collobert等人[1]率先将深度神经网络应用到命名实体识别,极大地改进了识别的性能。尹继泽等人[2]运用注意力机制和长短期记忆网络(long short-term memory,LSTM),通过提取文本全局和局部特征,进一步提高了识别性能。目前双向长短期记忆网络(bidirectional long short-term memory,BiLSTM)结合条件随机场(conditional random field,CRF)已被广泛应用于文本情感分析[3]、关键词提取[4]、命名实体识别[5]等自然语言处理任务中,其中以生物学领域的命名实体识别研究最为成功[6-9]。
实体是人、物、地区、机构、团体、企业、行业、某一特定事件等固定存在,且可以作为文章主体的实体词。命名实体识别一般针对特定领域的实体词,由于局部特征明显,模型多使用句子级的特征,模型的识别能力比较强。与一般命名实体识别不同,文章核心实体是文章主要描述或担任文章主要角色的实体词。文章核心实体的识别则需要基于文章篇章级的理解,简单的实体词附近的局部特征信息并不适用于该任务。同时文章核心实体识别面向通用领域,文章复杂多类,核心实体又是篇章语义上的全文核心词,需要结合篇章级的特征信息进行识别。
此外,网络文章通常涉及的范围十分广泛,不同领域文章的表述方式也差别较大,其领域特征信息复杂多样,目前流行的识别方法并不能很好地适应文章核心实体识别任务的要求。为此该文提出一种基于增强BiLSTM的文章核心实体识别方法。该方法通过发挥BiLSTM对变长序列的处理和记忆能力来捕捉文章篇章级的特征信息[10],同时引入AdaBoost集成学习算法,通过调整训练数据分布对让系统对数据集不同侧面分别进行模型化,最后通过组合各细分子类的多分类器全面准确地模型化多领域混合的复杂数据,进而增强模型总体的识别能力。
1 增强BiLSTM模型
传统的命名实体识别由于实体词附近的局部特征明显,识别时大多只需要句子级的特征,且针对单一领域语料具有很好的效果。而网络文章核心实体的识别由于是基于内容理解进行识别,所以还需要篇章级的结构特征信息,其抽取所要结合的全文语义关系特征并不明显。同时网络文章面向通用领域,内容包含复杂多类的领域特征信息,很难通过单个模型进行全面描述。
针对以上问题,该文将长短不一的文章按照字符映射入BiLSTM模型变长的网络结构中,利用BiLSTM的记忆单元和双向特性解决篇章级的语义理解问题。但模型还是难以同时应对复杂的多领域特征信息,为此该文又引入AdaBoost集成学习算法以增强原有模型对数据复杂多类的特征进行捕捉刻画,通过调整训练集数据分布,针对数据特征不同侧面训练多个模型,每个模型只关注数据集复杂特征的一个侧面,最终通过组合多个关注数据特征不同侧面的子模型来刻画复杂数据的全局特性,增强模型总体的识别能力。
1.1 变长文本和篇章级特征
网络文章的篇幅长短不一致,文章核心实体的数量、位置也不确定,其抽取难度非常大,需要结合篇章级的语义理解,结合不同文本类别的文档特征来识别出文章的核心实体,同时忽略其他语义类别的实体。
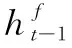
BERT(bidirectional encoder representation from transformers)[12]是Google提出的一种新型语言模型,该模型较完整地保存了文本语义信息,提升了模型的上下文双向特征抽取能力,在各类NLP任务上取得了目前最好的结果。
为充分利用文本的篇章级语义信息,该文采用BERT预训练模型编码字符级别的语境信息,提升字嵌入的上下文语义质量,增强模型的语义表达能力。同时还在BiLSTM后加入CRF层使用条件随机场模型对输出进行解码,通过标签间约束条件进一步提升标签序列预测准确性,更好地把握文章全局特性,得到最终的预测标签序列。采用的BiLSTM模型结构如图1所示。
1.2 AdaBoost
由于网络文章核心实体识别是面向通用领域的抽取任务,而且多领域导致文章具有复杂的篇章语义等特性,单个的BiLSTM模型难以同时对多个领域复杂类型的语料进行很好地模型化,使得核心实体识别效果较差,因此提升模型对复杂多类数据特征的模型化能力在实际应用中很有必要。
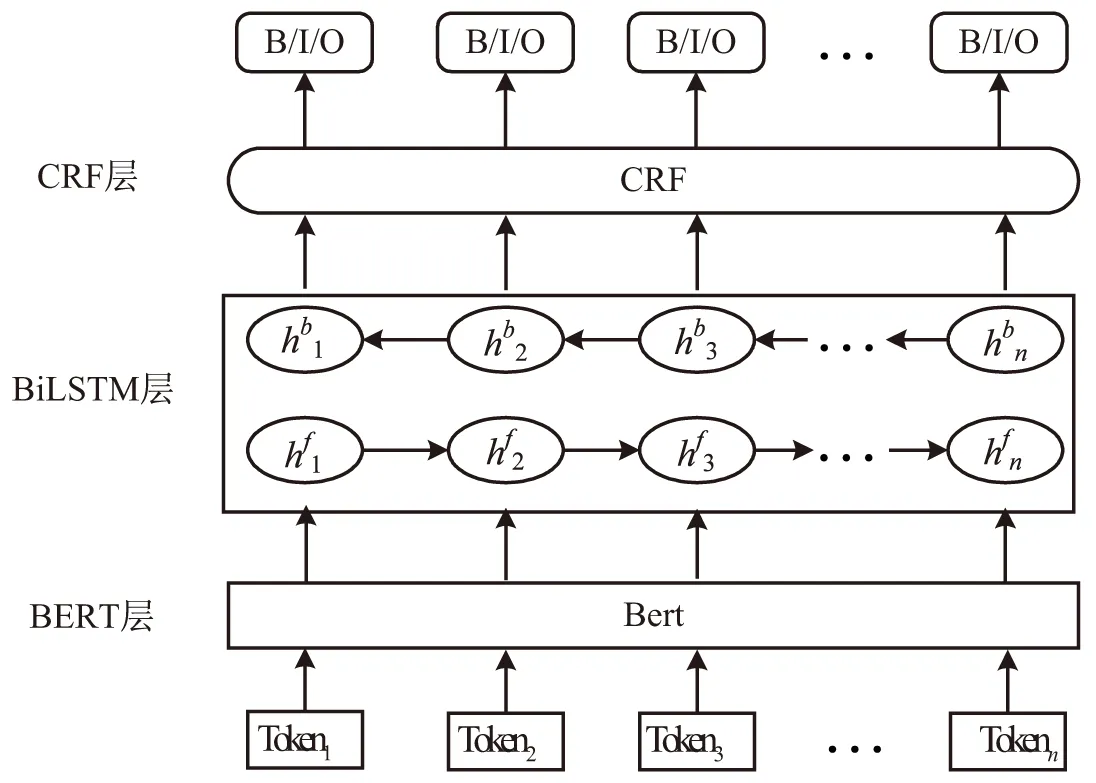
图1 BiLSTM模型结构
Boosting是一种重要的集成学习技术,能够有效提升弱分类器的准确率。目前有很多Boosting算法,常用的Boosting算法是Freund和Schapire于1995年提出的AdaBoost(adaptive boosting)算法[13]。AdaBoost是一种把多个简单弱分类器组合成强分类器的方法,最终的输出是由关注数据特征不同侧面的子分类器加权合成计算而得。
常见的AdaBoost与弱分类器组合有:使用AdaBoost提升决策树准确率[14]以及使用AdaBoost提升支持向量机(support vector machine,SVM)的准确率[15-16]等。新闻事件核心实体识别过程本质上是对预测标签序列进行分类的过程,受此启发,该文提出使用AdaBoost算法框架,改善BiLSTM模型对复杂数据全局特征的捕获能力,通过将多个关注不同细分子类的子模型组合为更强大的模型,来提高模型整体的分类预测能力。
由于BiLSTM模型与决策树、SVM等分类器不同,需要对原有AdaBoost算法与弱分类器结合的方法进行适当修改,以使得AdaBoost与序列预测模型结合。AdaBoost是通过调整训练集中样本权重值来改变每个子模型训练数据的分布,从而获得关注数据特征不同侧面的模型,然后通过各个子模型的正确率来判定各个子模型对最终识别结果的贡献。下面给出该算法的实现细节。

算法:AdaBoost算法。
输入:已标注样本集〈(x1,y1),…,(xn,yn)〉、样本权重向量D、BiLSTM模型参数、迭代次数K。
(1)fork=1,2,…,K
(2)从已标注样本集中依照权重Dk随机抽取训练集T。
(3)使用训练集T训练BiLSTM模型hk。
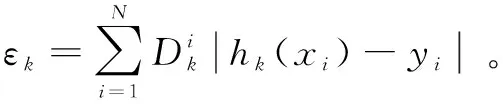

(7)end for
输出:模型最终输出为各子模型加权预测结果H(xi)=sign(∑hk(xi)*βk)。
“大概有四个月了,腿也有点麻木,但不是很明显,现在最远也就能走个三十丈吧。想我前年还能纵马驰骋疆场,一杆枪可挡千万兵马,如今却老迈如此,唉!”
1.3 增强BiLSTM模型结构
该文提出的经AdaBoost增强的BiLSTM模型总体结构如图2所示。
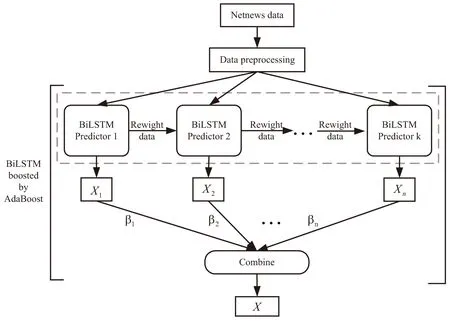
图2 增强BiLSTM模型结构
AdaBoost算法以迭代的方式训练BiLSTM网络,经过K轮迭代后得到关注数据特征不同侧面的K个BiLSTM模型。在每一轮迭代中,通过对已标注新闻语料进行概率随机抽样形成训练集并送入BiLSTM网络进行模型训练,训练结束后根据各模型的错误率生成模型权重β并调整训练数据集的样本概率权重,从而改变下一轮数据分布。数据分布的调整遵照加大错误样本权重减小正确样本权重的原则进行,这就使得下一轮的模型训练更关注于模型未准确捕捉的数据特征的那些样本集合。最后依照模型权重组合K个BiLSTM模型得到增强BiLSTM模型来进行网络文章核心实体的识别。
2 实验结果及分析
2.1 实验数据集
实验所涉及的语料来自搜狐新闻门户网站爬取的新闻数据,其时间范围为2019-03-01至2019-03-10,共计5万篇新闻报道,涉及民生、娱乐、科技、政治等多个领域,文章结构、表述方式复杂多样。采用人工统计法标注新闻数据集,每篇新闻文本依据所报道事件标明2到3个核心实体,图3为语料样例,核心实体为:“3d”,“工业”和“机器视觉”。图4为标记样本片段。

图3 语料样例

图4 标记样本片段
其中,标签策略借鉴命名实体识别的BIO系统,B表示核心实体的首字符,I表示核心实体首字符以外的其他实体字符,O表示非核心实体字符。实验中将带有核心实体标签的数据分为训练集和测试集。各数据集中的文本统计情况如表1所示。
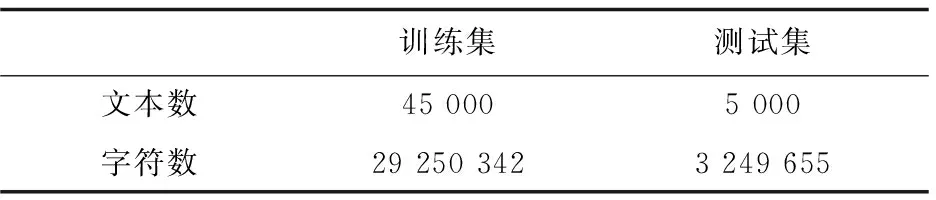
表1 数据集文本分布
2.2 参数设置
在增强BiLSTM模型的各子模型训练过程中,首先要得到句子级字向量序列。模型以句子为单位送入Bert模型生成字嵌入向量序列。输入句子最大长度为512,长度不足的句子以
接下来进入BiLSTM层学习文本中全局特征信息。在BiLSTM参数学习过程中,隐含层设置为400维,BiLSTM输出隐含层后经过一个全连接网络对其进行线性变换,降低维度,最终送入CRF层。输出层的神经元个数为3,即3种分类标签。在训练过程中,输入的批量文本大小batch_size为50,学习率初始值为0.001。模型使用优化的随机梯度下降算法训练网络参数并动态更新学习率的大小,其迭代次数设为100。
2.3 实验结果分析
CRF++和BiLSTM分别是统计和深度学习领域比较有代表性的序列标注模型,为此该文除了使用增强BiLSTM进行模型的构建与实验,还引入了普通BiLSTM和CRF++进行对比实验来验证所提出模型的有效性。
实验中核心实体词识别的综合得分F1-score计算方法如下:
F1-score(Entities)=
(1)
实验使用TensorFlow深度学习框架,借助GPU加速模型的训练过程,表2展示了文中方法、普通BiLSTM模型和CRF++在测试数据集上核心实体识别的精准度(Precision)、召回率(Recall)和F1-score综合得分情况。
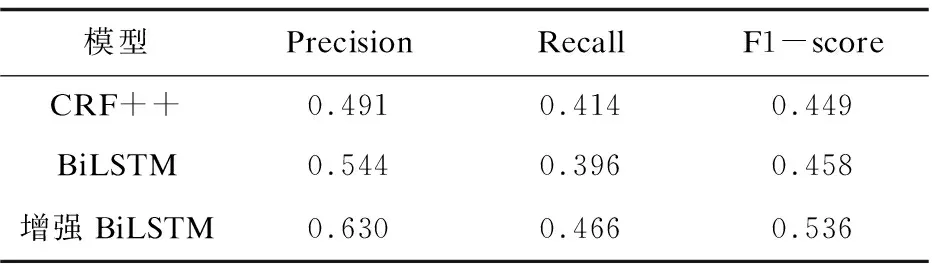
表2 模型性能对比
由表2中的数据可看出,在进行文章核心实体识别时,普通BiLSTM模型的识别效果略优于CRF++,该文提出的增强BiLSTM模型在精准度、召回率和F1-score上均优于普通BiLSTM模型和CRF++。说明在应对复杂类型语料时,CRF++和普通BiLSTM模型无法获得数据的全局特征,而增强BiLSTM模型在普通BiLSTM的基础上极大地提高了模型化复杂数据全局特征的能力。增强BiLSTM模型通过从不同侧面关注数据特征,组合多个关注数据集不同侧面的子模型形成最终的增强预测模型。实验结果证明了提出的模型的有效性,其识别性能比普通BiLSTM方法提升了17.03%,比CRF++提升了19.37%。
AdaBoost算法框架对BiLSTM模型的增强效果取决于各个子模型对数据集特征的捕获能力,为此实验对各个子模型的特征捕获能力进行了实验研究。实验使用同一测试集对各个子模型进行了测试,并对各个测试结果中的正确预测样例集合进行了对比分析。采用Jaccard相似系数(Jaccard similarity coefficient)来衡量各个正确预测样例集合的相似度与差异性,Jaccard相似系数计算方法如下:
(2)
其中,A表示子模型A的预测结果中的正确预测样例集合,B表示子模型B的预测结果中的正确预测样例集合。Jaccard相似系数的值域是0到1,相似系数越大,两个子模型对测试集的正确预测样例集合相似度越高,两个子模型的能力越相近,它们所捕获的特征也就越相似。实验计算了所有子模型对应的正确预测样例集合两两之间的Jaccard相似系数,平均相似系数为0.483。这说明各个子模型所捕获的数据集的特征不完全相同,它们对同一测试集展现出不同的预测能力。例如:子模型1对应的正确预测样例集合中大多是关于娱乐新闻的文章,其核心实体大多包含明星姓名;而子模型4对应的正确预测样例集合中多是关于金融的文章,其核心实体大多包含公司名称。从而推断子模型1和子模型4具有不同的能力特性,它们捕获了不同的数据特征。因此,AdaBoost可以通过自适应的调整数据分布使得各个子模型的训练数据具有不同偏向性,从而使各个子模型能够捕获数据集特征的不同侧面,即数据集的特征中的一部分。
实验还对增强BiLSTM模型中AdaBoost算法中的迭代次数K对模型的影响进行了实验研究,图5展示了当K从1到20时模型F1值的变化趋势。
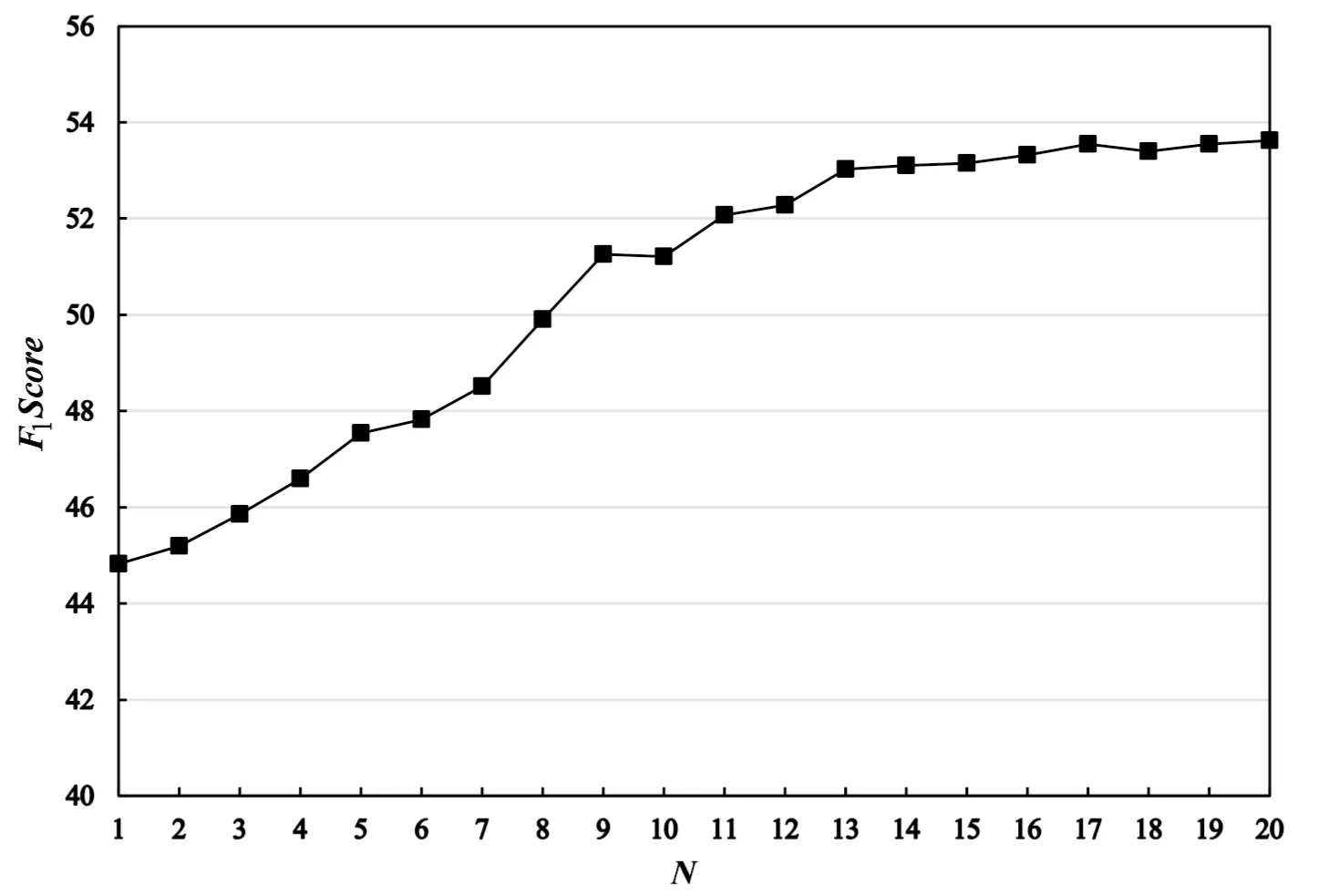
图5 F1值变化趋势
由图5可以看出,增强BiLSTM模型随着迭代次数的增加,模型性能逐渐提升,当迭代次数达到20时,模型性能提升趋势趋于平缓。增强BiLSTM通过调整数据分布来关注数据的不同侧面,每增加一次迭代,其实是对数据集为模型化特征的一次模型化,表现为增加错误率高的样本的权重使得下一次训练重点关注该样本。随着迭代次数的增加,在模型能力范围内未被模型刻画的特征逐渐变少,模型的增强效果趋势变缓。因此,较于普通BiLSTM模型,增强BiLSTM模型在面对复杂领域数据时性能较好,但并不能通过无限增加子模型数量来提升模型整体性能,合适的迭代次数K值应依据数据集特征的复杂程度和模型实际效果而定。
3 结束语
介绍了基于增强BiLSTM的文章核心实体识别方法:通过BiLSTM模型关注文本中字符之间的联系,挖掘文章篇章级的语义特征,使用AdaBoost增强模型加强对通用领域复杂数据特征的捕捉能力,从而更全面地刻画数据集全局特征。实验结果表明,该方法在核心实体识别任务上相比传统模型性能有了进一步的提升,从而为情感分析、舆情监测等任务提供更好的支持。增强BiLSTM的不足之处是其结构导致模型不能较好地支持并行训练,训练时间成本较高,如何提高模型的并行训练能力将是接下来的研究重点。
猜你喜欢
计算机系统应用(2021年11期)2022-01-06
阅读与作文(英语初中版)(2019年8期)2019-08-27
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
现代出版(2014年6期)2014-03-20
