
基于云计算技术的城市就业需求量预测研究
2021-01-17 13:19景毅,曹辉
现代电子技术 2021年1期
景 毅,曹 辉
(西南科技大学,四川 绵阳 621010)
0 引 言
随着就业形势越来越严峻,城市就业的竞争也日益激烈,对城市就业需求量进行分析和预测,可以科学把握城市就业需求量的变化规律,并根据该规律提前了解城市就业需求量的变化趋势,不仅可以帮助就业者更好地规划自己的人生计划,同时为就业管理者提供有价值的指导意见。因此,城市就业需求量预测研究成为大家关注的焦点[1-3]。
针对城市就业需求量预测问题,国内外学者进行了广泛的研究,涌现出了许多有效的城市就业需求量预测系统[4-5]。最初通过一些专家建立城市就业需求量预测系统,该系统的工作过程比较繁琐,使得城市就业需求量预测时间长,而且城市就业需求量预测误差大[6]。
随后出现了基于计算机的城市就业需求量预测系统,该系统主要采用一些数据分析技术,如聚类分析算法、人工神经网络建立城市就业需求量预测系统[7-8]。由于聚类分析算法是一种线性预测技术,而城市就业需求量与多种因素有关,如城市发展程度、经济水平、人文环境、人才吸引政策,使得城市就业需求量变化具有一定的随机性,因此聚类分析算法的城市就业需求量预测结果不理想[9];人工神经网络克服了聚类分析算法的局限性,可以描述城市就业需求量的随机性,因此城市就业需求量预测精度得到了提高[10-12]。
但是人工神经网络同样存在一些不足,如城市就业需求量预测建模速度慢、耗时长、城市就业需求量预测结果不稳定,同时当前主要采用单机平台搭建城市就业需求量预测系统,无法满足大规模城市就业需求量的预测效率要求,城市就业需求量预测系统的实时性差[13-14]。
为了解决当前城市就业需求量预测系统存在的一些缺陷,以提高城市就业需求量预测精度为目标,提出基于云计算技术的城市就业需求量预测系统。该系统采用云计算技术搭建城市就业需求量预测平台,使用多个节点同时对城市就业需求量进行建模和预测,相同平台下,与其他城市就业需求量预测系统仿真对比结果表明,本文系统的城市就业需求量预测精度得以提高,而且城市就业需求量预测时间明显缩短,预测综合性能更优。
1 基于云计算技术的城市就业需求量预测系统
1.1 云计算技术
随着信息技术的发展,各个行业都有自己的信息处理系统,每天会产生大量的数据,传统单机平台由于技术和硬件工艺等条件的限制,其性能已经达到瓶颈,上升的空间相当小,平台无法满足大数据分析的要求,在此背景下产生了云计算平台。
云计算平台包括许多模块,其中有两个核心模块:分布式文件系统和MapReduce 并行运行模型。其中,分布式文件系统主要负责对大数据进行存储和管理,将一个大数据分析问题划分成多个子问题,然后将子问题分析到相应的机器节点上;MapReduce 主要负责大规模数据集的运算,对大数据分析问题采用“分而治之”的思想。
云计算平台的结构如图1 所示。
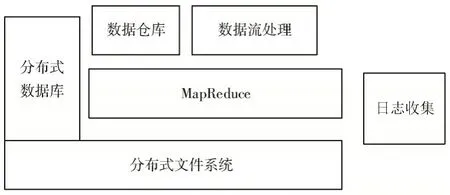
图1 云计算平台的基本结构
分布式文件系统采用主从架构设计,由许多节点组成,可以将节点划分为两大类:名称节点和数据节点,名称节点的数量通常为1 个,而数据节点的数量有多个。名称节点负责对数据节点进行管理,通常情况下,客户端会向名称节点发送文件操作的请求,而名称节点将客户端的相关信息反馈给数据节点,最后数据节点根据反馈结果对文件进行相应的操作。
数据节点为云计算的存储单元,每个数据块会在多个数据节点进行备份,即保持一定的冗余,当某一个数据节点出现故障不能正常工作时,其他数据节点可以使用,从而保证分布式文件系统长期处于正常工作状态。
分布式文件系统架构如图2 所示。
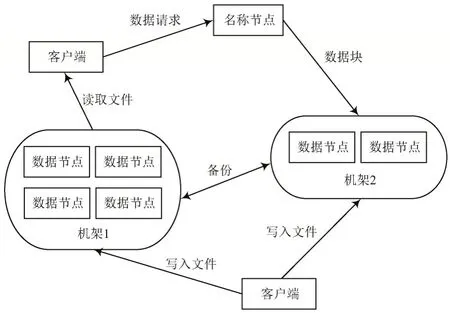
图2 分布式文件系统架构
MapReduce 负责数据的处理和分析任务,是云计算平台的灵魂,最开始由Google 公司开发,其将一个复杂的问题进行分块,得到若干个小问题,每一个小问题对应一个Map 函数,多个Map 函数并行运行,对小问题进行处理,并将处理结果发送给Reduce,Reduce 对Map 的处理进行融合和汇总,具体工作流程如图3 所示。
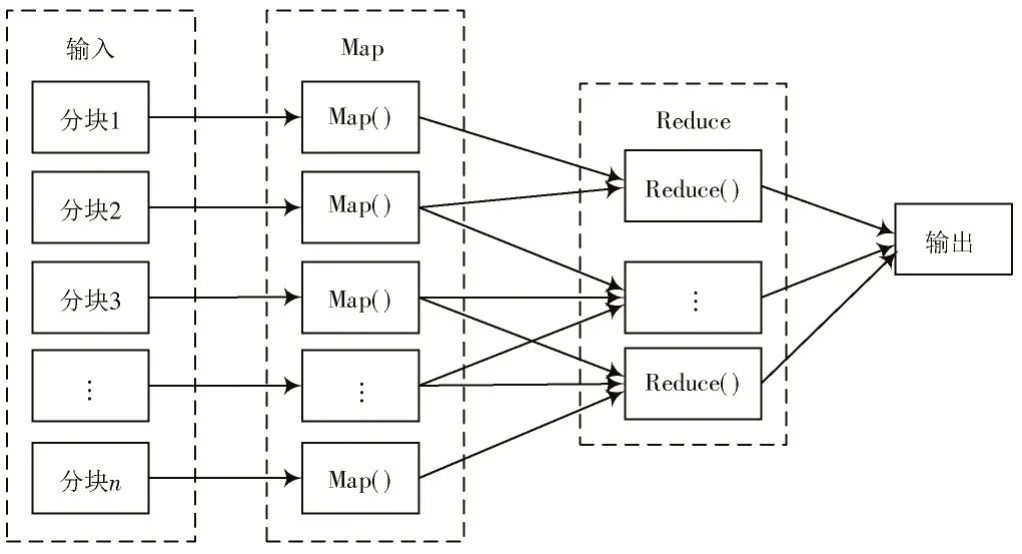
图3 MapReduce 的工作流程
1.2 城市就业需求量预测系统工作原理
由于城市就业需求量数据向大规模、海量方向发展,单机平台难以满足当前城市就业需求量预测建模的效率要求,为此本文引入云计算平台建立城市就业需求量预测系统。
城市就业需求量预测系统工作原理为:首先将城市就业需求量数据输入到分布式文件系统,并将城市就业需求量数据划分为多个子块,然后通过Map 函数将每一个子块分配到相应的数据节点上,所有数据节点并行运行,其中每一个节点上采用大数据分析算法——支持向量机对城市就业需求量进行建模与预测,最后通过Reduce 函数对城市就业需求量预测结果进行汇总、输出,具体原理如图4 所示。
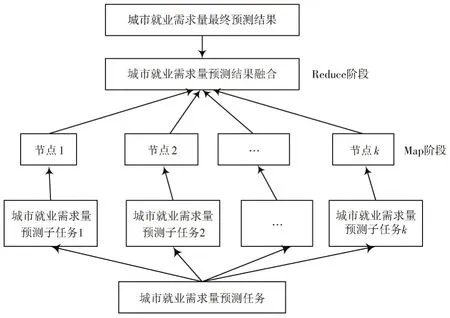
图4 云计算的城市就业需求量智能预测原理
1.3 大数据分析算法
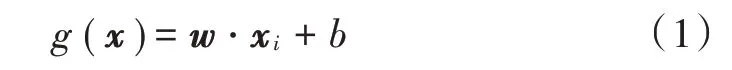
式中w和b分别表示权值和阈值。
为找到最优超平面,那么首先要确定最优的w和b,第i个样本到最优超平面之间的间隔为:
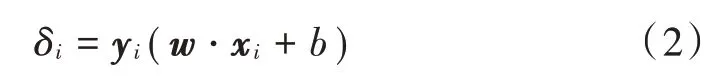
对w和b进行归一化操作,得到:
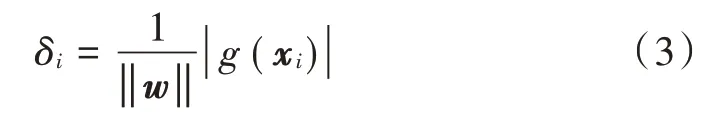
对于所有样本点(xi,yi),i=1,2,…,n,可以建立如下的条件约束:

最优超平面的求解可以变化成一个二次规划问题的求解,具体如下:
使用拉格朗日法对式(5)的问题进行求解,首先建立拉格朗日函数,即有:
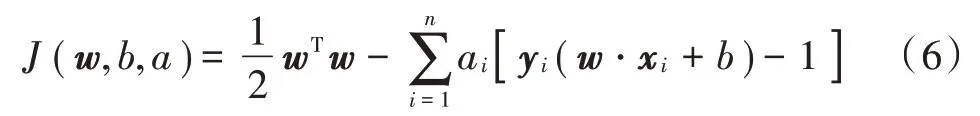
式中ai为拉格朗日乘子。
对式(6)的w和b进行求偏导操作,并且使偏导为零,即有:
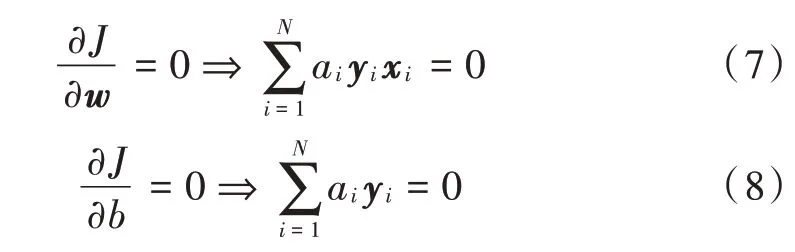
这样可以得到原问题的对偶形式,具体如下:
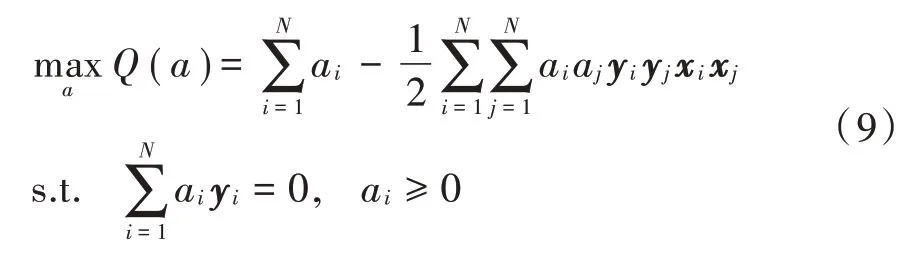
经过以上公式可以得到最优的w和b,最后得到支持向量机预测建模的决策函数为:

式中x表示测试样本。
1.4 大数据分析算法的城市就业需求量预测步骤
Step1:收集某一个城市就业需求量的历史数据,并去除一些错误的城市就业需求量样本点,将数据划分为训练样本和测试样本。
Step2:根据城市就业需求量的训练样本确定支持向量机的结构,并初始化支持向量机的相关参数。
Step3:采用支持向量机对城市就业需求量的训练样本进行学习,通过10 折交叉验证确定向量机最优参数值。
Step4:根据最优参数值建立城市就业需求量预测模型。
Step5:采用测试样本对城市就业需求量预测模型的预测精度进行分析。
大数据分析算法的城市就业需求量预测流程如图5所示。
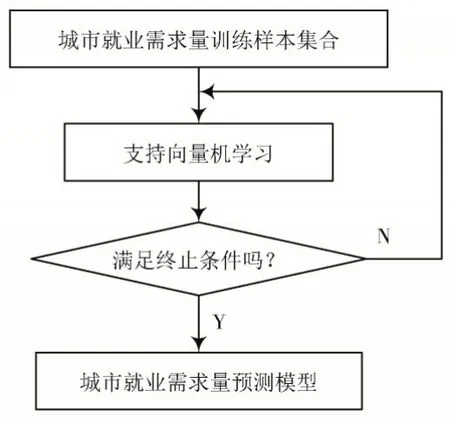
图5 大数据分析算法的城市就业需求量预测流程
2 城市就业需求量预测系统的性能测试
2.1 城市就业需求量预测的测试平台设计
为了测试基于云计算技术的城市就业需求量预测系统的性能,对其进行仿真实验,云计算平台包括1 个主节点,5 个从节点,城市就业需求量预测的云计算平台设计如表1 所示。
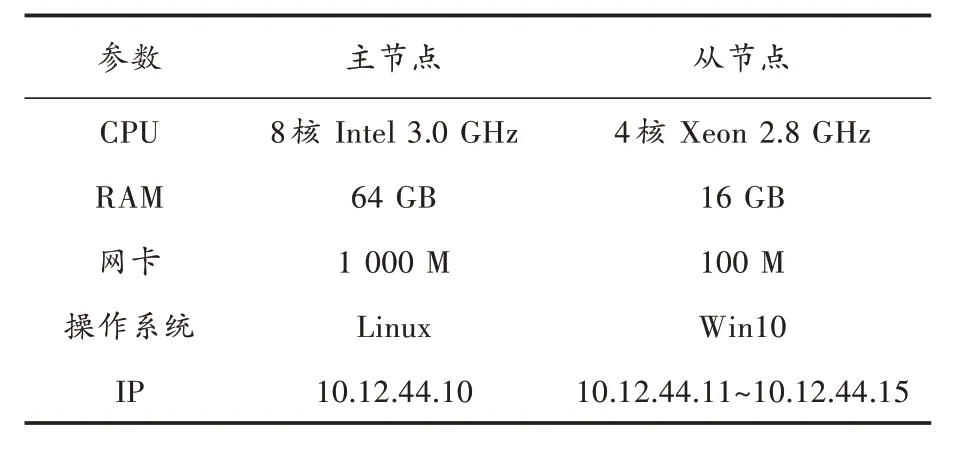
表1 城市就业需求量预测的测试平台设计
为了使基于云计算技术的城市就业需求量预测系统的结果有可比性,选择单机的城市就业需求量预测系统进行对比,其中单机系统采用BP 神经网络作为城市就业需求量建模与预测算法,验证支持向量机的优越性。
2.2 城市就业需求量预测的测试数据
选择某城市一段时间的就业需求量数据作为实验样本,该数据的样本数量为150 个,为了使实验结果具有比较强的说服力,进行5 次仿真实验,每一次仿真实验选择不同数量的训练样本和测试样本,具体如表2所示。

表2 城市就业需求量预测的测试数据
2.3 与其他城市就业需求量预测系统的性能对比
统计两种系统的城市就业需求量预测精度,结果如图6 所示。
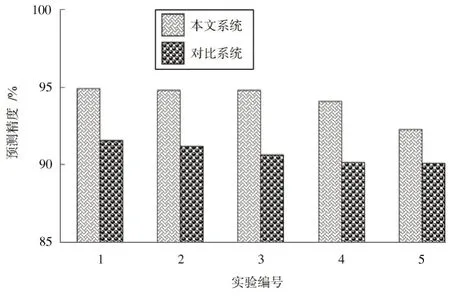
图6 两种系统的城市就业需求量预测精度
对图6 的城市就业需求量预测精度进行分析可以发现,相对于对比系统,本文系统的城市就业需求量精度得到了一定的提高,这主要是因为本文系统采用大数据分析算法——支持向量机对城市就业需求量的变化规律进行建模,可以高精度刻画城市就业需求量的变化趋势,降低了城市就业需求量预测误差,获得了更优的预测结果,验证了本文系统引入支持向量机对城市就业需求量预测进行建模的优越性。
为了体现云计算平台的优越性,将表2 的实验样本扩大100 倍,统计两种系统的城市就业需求量建模时间,结果如图7 所示。
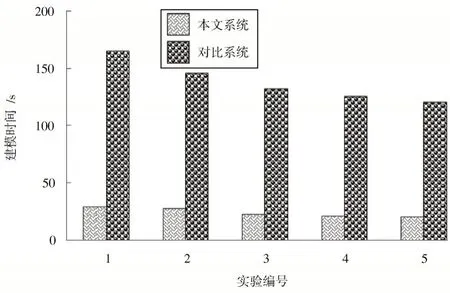
图7 两种系统的城市就业需求量预测建模时间
从图7 的城市就业需求量建模时间可以发现,本文系统的城市就业需求量建模速度大幅度提升,改善了城市就业需求量建模效率,这是因为本文系统利用了云计算的并行处理优势,使多个节点同时对城市就业需求量进行建模,克服了单机平台采用单节点对城市就业需求量预测建模时间长的不足,本文系统可以适应城市就业需求量数据向大规模方向发展的要求,具有更加广泛的应用范围。
2.4 本文城市就业需求量预测系统的鲁棒性测试
为了测试城市就业需求量预测系统的鲁棒性,选择10 个大城市就业需求量作为研究对象,统计它们的城市就业需求量预测精度,结果如表3 所示。
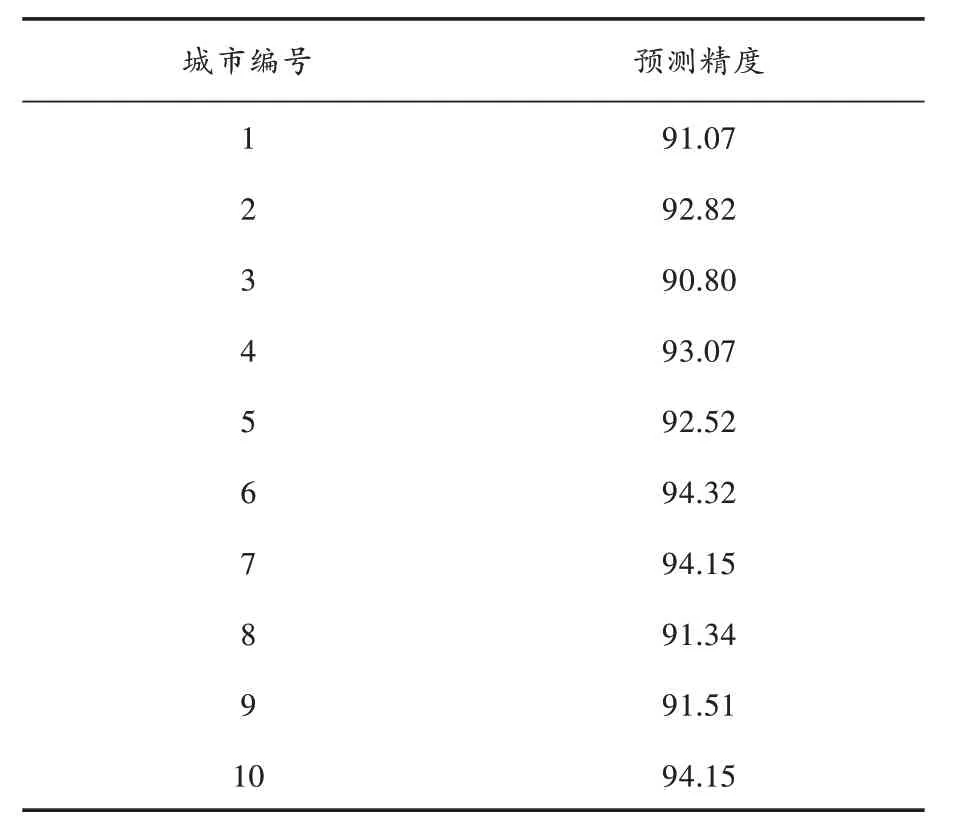
表3 本文系统的就业需求量预测精度 %
从表3 可以看出,对10 大城市就业需求量预测,本文系统的预测精度均超过了90%,这表明本文系统的城市就业需求量预测精度十分稳定,具有较强的鲁棒性,为城市就业需求量预测建模提供了一种新的工具。
3 结 语
为了降低城市就业需求量预测误差,在分析当前城市就业需求量预测系统的基础上,提出基于云计算技术的城市就业需求量预测系统。采用云计算平台强大的并行处理能力解决单机城市就业需求量预测效率低的难题,引入支持向量机对城市就业需求量进行建模和预测,解决了当前城市就业需求量预测精度低的不足,并进行仿真测试实验。实验结果表明,本文建立了一种速度快、精度高的城市就业需求量预测系统,为其他大规模、非线性预测问题提供一种新的建模思路。
猜你喜欢
数学大王·中高年级(2021年6期)2021-09-27
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
当代水产(2020年2期)2020-03-17
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
电子制作(2018年11期)2018-08-04
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
橡胶科技(2015年3期)2015-02-26
现代防御技术(2014年6期)2014-02-28
