
浅论大数据时代数据可视化技术对于数据分析的价值
2021-01-15 12:12
科海故事博览 2020年8期
(郑州宇通客车股份有限公司,河南 郑州 450000)
在很多城市,私家车的数量持续增长而交通并没有更加拥堵甚至还有所改善的时候,这是因为信号灯和摄像头除了地理位置以外有了数据处理等AI技术带来的其他维度的有效地互联互通。大数据时代的变革让人受益,在这个时代,人类接触的几乎所有事务都可能转化为数据资源。数据成为与自然资源、人力资源同样重要的战略资源,引起了科技界和企业界的高度重视。[1]2012年1月,在瑞士小镇达沃斯举办的世界经济论坛上大数据成为探讨的主题之一并发布报告“Big data,big impact:New possibilities for international development”。[2]
1 数据解读在大数据时代的面临的挑战
《史记•萧相国世家》中记载“何独先入收秦丞相御史律令图书藏之……汉王所以具知天下厄塞,户口多少,强弱之处,民所疾苦者,以何具得秦图书也。”这是历史上数据分析帮助人类决策取得成功的经典案例。数据的采集与分析不是一个新问题。但在大数据时代,传统科学也要面临新的挑战。
1.1 大数据特征所决定
大数据首先应该具备其代表性意义的3V特征[3],即大规模性(Volume)、多样性(Variety)和高速性(Velocity)。然而数据量的增长并不与数据价值呈线性比例增长,反而使我们在其中获取知识的难度增大。因此,有机构提出大数据还具有第四个V,价值密度低(Value)[4]。大数据这四个特征,对于数据科学的各个领域均增加了不同程度的复杂性。
1.2 数字化统计结果会有掩盖性
“谎言有三,普通谎言、严重谎言、统计数据。”这是源于19世纪英国政坛的一句名言,足以揭示数据化的统计结果对人类获取知识并进行决策的危险。[5]误导决策者的方式主要有:(1)选择有误导性的代表值,如经常提及的“精心挑选的平均数”;(2)对统计数字进行模糊字眼描述;(3)大量样本充分掩盖了个别重要数据,造成对一些重要的信息的忽略和错误估计。在大数据时代,样本量可以等同于数据总量。美国统计学家赫夫的著作《统计陷阱》(How to lie with statistics)中,描述了各种数据误导现象。自1954年出版以来,至今畅销。[6]
笔者针对第二点做一下举例分析。美国《星期日》周报提到“一个婴儿到第N 个月就能坐直”。许多父母看到这则消息,马上联想到自己的孩子,如果他们的孩子到这个月份还坐不直,就会怀疑孩子存在“软骨”、“发育不正常”等问题。这个标准是什么意思呢?据了解,这是孩子出生到能坐直时间的中位数。也就是说半数的孩子在N个月时一定是坐不直的,没有什么可担心的。“标准”一词,意味着达不到此数据就不合格,可是中位数是不能作为标准的。然而我们免去这些复杂的统计学分析,在大数据时代下将正常婴儿坐立时间用分布图表示,任何人不再有机会使用数据进行误导。这样能更充分、更科学的制定出相关数据,供大家参考。
数据分析人员的工种多样性。用户正从少数数据专家用户发展为广泛领域的工程技术人员。在大数据和新媒体时代有分析理解数据需求的人员从传统的数据分析人员和商业用户延伸到社会中几乎每位信息消费者。然而术业有专攻,不可能所有人都受过统计学训练并能够读懂传统分析结果(Summary),由此可见可视化的普惠性和低门槛借助 Web、移动端、互联网及物联网等新型环境便于普通用户使用。可扩展的可视化系统已经是大数据可视化的发展趋势之一。
2 数据可视化手段
数据可视化是是关于数据视觉表现形式的科学技术研究,是使数据分析结果简明之致的视觉化表现和传达过程。[7]这个过程并非简单地“直译”数据,而是要从大量数据中把隐藏在深处或各种数据之间的关联信息挖掘出来,是一种知识和价值的发现过程。最终丰富数据阅读者的认识体系并辅助其做出正确决策。其中,这种数据的视觉表现形式被定义为,一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量。它是一个处于不断演变之中的概念,其边界在不断地扩大。主要指的是技术上较为高级的技术方法,而这些技术方法允许利用图形、图像处理、计算机视觉以及用户界面,通过表达、建模以及对立体、表面、属性以及动画的显示,对数据加以可视化解释。与立体建模之类的特殊技术方法相比,数据可视化所涵盖的技术方法要广泛得多。
人类从外界获得的信息约有 80% 以上来自于视觉系统[8],可视化正是利用人类识别图像的天赋来促进更有效地理解数据。基于此原理,可视化技术将难以直接显示或不可见的数据映射为可以感知的图形、颜色、文理、符号等,以提高数据识别效率并高效传递有用的信息。[9]MIT 的学者用眼动仪观察用户观看可视化数据的过程,发现:首先,看一眼便能记住的可视化图形中要含有被记住的内容。[10]笔者借一句英文中谚语归纳一下数据可视化的价值:“一图胜千言”。(“A picture is worth a thousand words”)
从对数据的认知角度而言,数据的以下四个性质可以为人类提供相关知识。它们是关联性、特征性、次序性以及数量性。可视化的多个变量可以不同程度展示出数据的这四个相关性质。
数据的关联性可以使用的变量包括颜色、位置、形状和方向。数据的特征性最常使用的变量是颜色,其次是纹理、明度等级和尺寸。数据的次序性最佳表现变量是明度等级,其次分别是颜色和尺寸。对于数据规模的大小我们常用尺寸变量来表示。
笔者对可视化实现的功能进行梳理,可以归纳出数据可视化的几大分类。换言之,根据目标、意图以及数据的表现形式我们大致可以看到可视化会出现五种类型。
(1)时序可视化(RunTime Visualization),随着时间而变化的数据通过可视化的形式来表现。
(2)分布可视化(Distribution Visualization),将所关心的局部与整体之间的关系——例如最大、最小用可视化的方式进行表现。
(3)关联可视化(Relationship Visualization),寻找数据各个变量之间存在的关系。
(4)比较可视化(Comparative Visualization),寻找数据变量之间的价值比较。
(5)空间可视化(Spatial visualization),旨在表现在地图上承载的信息。
3 数据分析的案例分析[11]
假设三个组分别采集到如下数据:
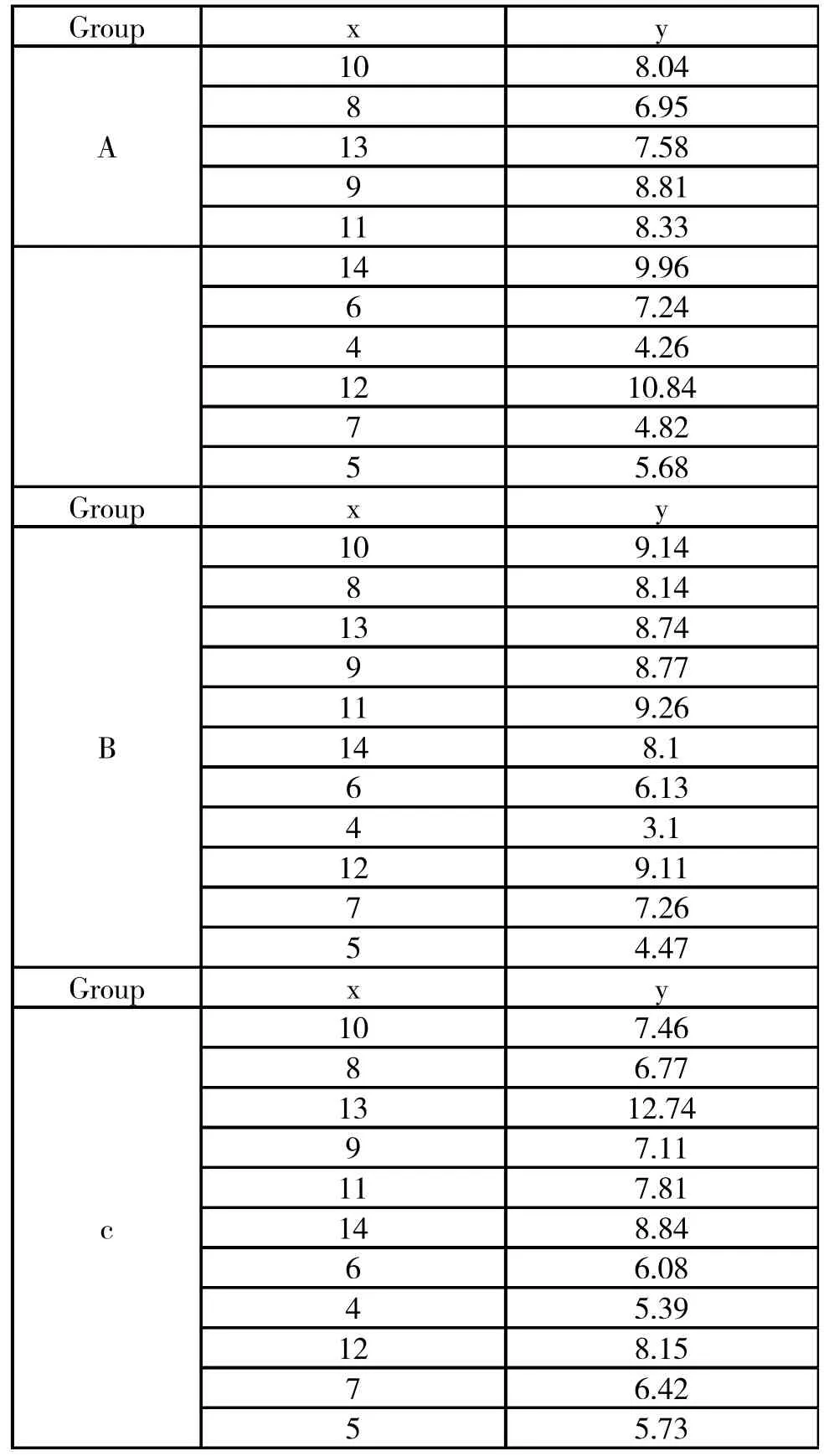
使用Python中的Statsmodels,对上述数据整理并做线性回归。笔者展示关键部分代码以及打印出的关键结果信息。
import statsmodels.api as sm
import pandas as pd
X=data.x
y=data.y
X=sm.add_constant(X)
model=sm.OLS(y,X).fit()
model.summary()
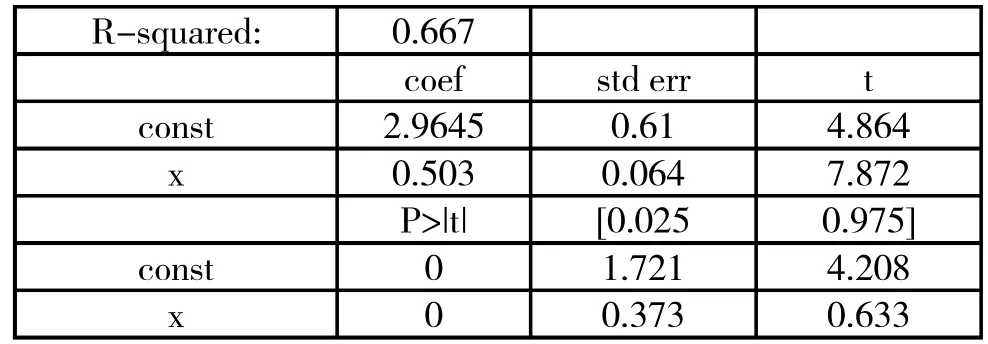
统计结果可以让数据分析人员接受这个模型,但需要将数据做一下可视化。
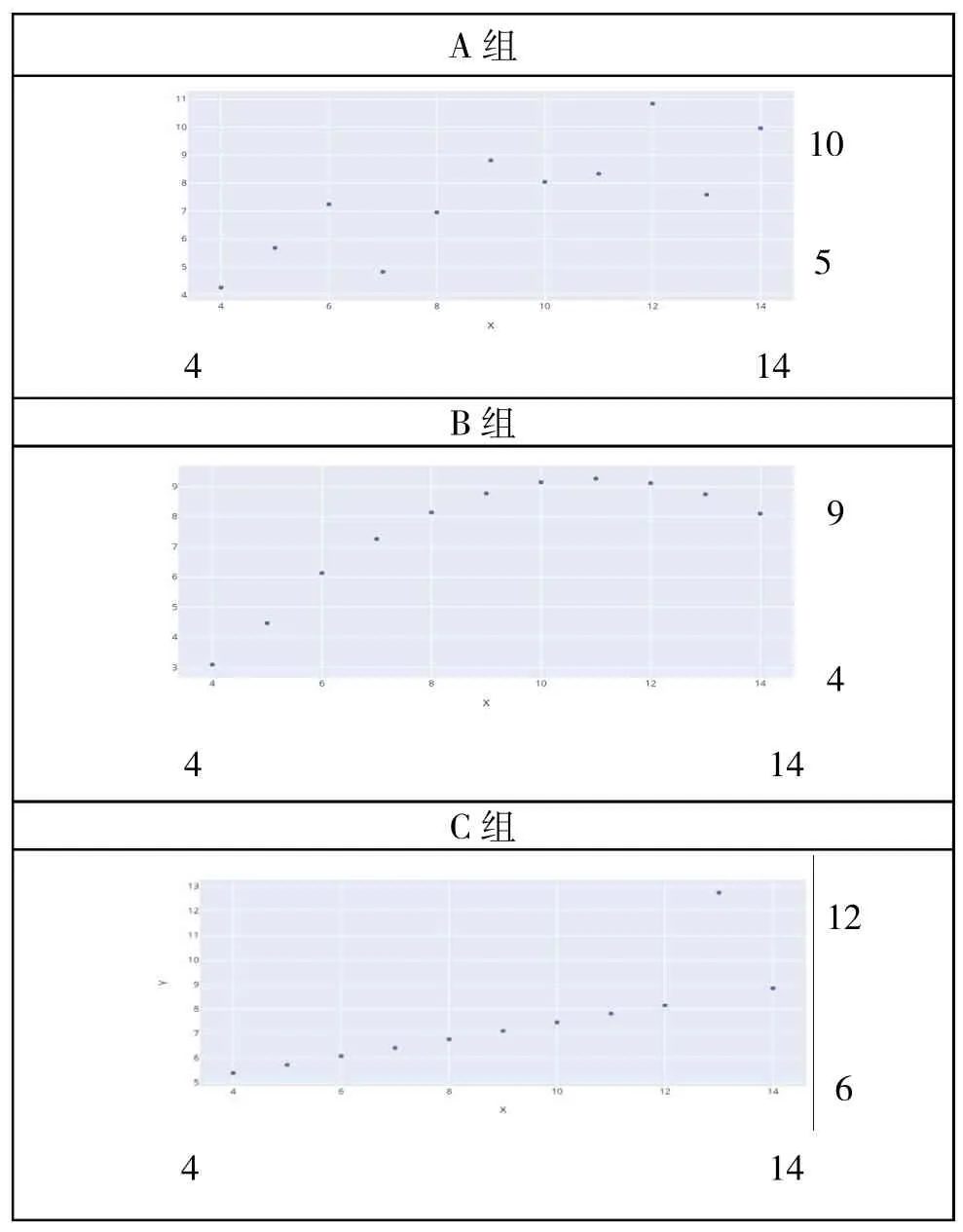
从数据可视化之后的图片信息可以看到,笔者只认为对A组做线性回归是相对科学的解决方案。所以不要轻易相信Summary statistics,聪明的人先对数据做可视化。
4 数据可视化发展方向
4.1 AR技术在数据可视化中的应用
人类是在三维世界中进行物体识别,然而在数据可视化中,3D效果的使用却始终不温不火甚至饱受质疑。其原因是3D图像可以扭曲感知从而扭曲数据。[12]其根本原因是数据可视化的展示载体是一个平面。AR技术使数据阅读者更身临其境,这大大有利于数据分析师构建更符合人类观察习惯的数据可视化作品。
4.2 数据可视化的视觉合理性研究
可视化研究的重要理论基础之一是认知心理学。这是一门研究有关人类如何感知和认识世界的理论,研究人类感知和思维信的过程。[13]不可思议的是最不可识别的可视化图像 54%来自于政府部门(美国),他们采用的可视化图像往往是相同的模板和类似的美学特征。因此,容易造成识别的混乱。若要促成数据可视化对信息更有效的传达以及让阅读者对数据有更深刻的洞察,技术与设计、科学与美学需要并驾齐驱。
4.3 钻取技术在数据可视化中的应用
计算机技术迅猛发展为大数据产业提供了强有力的支持。然而工程师们往往更专注后台的存储、算法、算力等方面的研究。其实在笔者看来计算机前端的发展同样为数据分析带历史性的变革。这些技术可以让数据分析人员纵向了解各个级别的数据,而非仅仅展示出来的横向部分。
在大多数情况下,可视化同时包含多个维度和度量。维度是指考察数据的角度。度量是某个维度的取值或某些维度的计算结果。好的可视化结果可以帮助数据分析师找到特征明显的维度和度量特征。如今非常火热的机器学习技术,主要依靠的就是数据的特征。[14]
钻取技术可以帮助数据分析师细化这些特征。其更大的意义在于,将可视化的成果变成更有力的数据分析工具。
从数据可视化之后的图片信息可以看到,笔者只认为对A组做线性回归是相对科学的解决方案。所以不要轻易相信Summary statistics,聪明的人先对数据做可视化。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
北京测绘(2022年6期)2022-08-01
当代陕西(2022年4期)2022-04-19
师道·教研(2022年1期)2022-03-12
当代陕西(2020年22期)2021-01-18
中华诗词(2019年7期)2019-11-25
传媒评论(2019年4期)2019-07-13
中华手工(2017年2期)2017-06-06
中外会展(2014年4期)2014-11-27
吐鲁番(2014年2期)2014-02-28
