
基于深度学习的暗网市场命名实体识别研究
2021-01-08 08:08范晓霞周安民郑荣锋李孟铭
信息安全研究 2021年1期
范晓霞 周安民 郑荣锋 李孟铭
1(四川大学网络空间安全学院 成都 610065) 2(四川大学电子信息学院 成都 610065)
(fanxxbili@gmail.com)
暗网(darknet)是指具有高度匿名性的网络,相对于普通人能轻易接触到的表网(clearnet),暗网需要使用洋葱路由器(the onion router, Tor)等专门的工具进行访问.Tor能阻止他人进行流量分析,是一个可以用来保护用户隐私、避免网络监控的软件.经由Tor的数据包经过多个延迟代理,且不会在服务器上留下日志记录.并且,Tor会对通信流量进行加密,并以固定的间隔时间改变路由[1].由于暗网的匿名特性,暗网变成了违法犯罪者进行违法活动的天堂.暗网上有许多的违法商品交易网站,也就是暗网市场(darknet markets, DNMs).例如,“丝绸之路”(Silk Road)就是第1个大规模违法商品交易暗网市场.暗网市场给买方和卖方提供了交易违法商品的平台,包括毒品、武器、假钞、性奴和网络攻击工具等大量非法商品[2],对网络安全从业者和网络安全相关部门来说是一个非常有价值的网络威胁情报来源.同时,从威胁发现的角度来讲,暗网数据也是非常有价值的情报.恶意软件,如病毒和木马通常早于表网出现在暗网市场上,如何从暗网市场获取有效信息是一个重要的研究课题,而从暗网市场文本获取安全相关信息的第1步就是识别出相关的命名实体.
命名实体识别(named entity recognition, NER)抽取有效信息是自然语言处理(natural language processing, NLP)的重要步骤.命名实体识别是许多任务的基础方法,广泛应用于信息抽取、关系抽取、语义分析、信息检索、问答系统、机器翻译等领域.通常,一般的命名实体识别系统只能识别出通用命名实体.例如,由斯坦福大学开发的自然语言处理工具Stanford NER(Stanford named entity recognitionizer)用于标记文本中的单词序列,如用“PERSON”标记人名,“ORGANIZATION”标记像WTO和WHO一类的组织实体,“LOCATION”标记地名,“O”标记其他非实体单词.由于信息安全领域和暗网领域的标注文本不足,应用于普通数据集的命名实体识别系统不能有效识别网络安全相关的命名实体,不同的研究领域关注不同的命名实体,如:生物医学领域关注疾病和药物;建筑领域关注材料和结构.此外,暗网市场主要是大量的短文本,还包含拼写错误、缩写等刻意和非刻意的难以识别的单词.基于以上考虑,相比普通领域,网络安全领域的命名实体识别更加困难,构建一个针对暗网市场的命名实体识别系统是十分必要且重要的.
1 相关研究工作
暗网市场又被称为加密市场和黑市,支持违法商品的交易,保护卖家和买家信息的匿名性.暗网市场屡禁不止,支持有关监管机构的工作,保护公众网络安全迫在眉睫.黄莉峥等人[3]提出了一种暗网文本主动获取的框架,收集暗网威胁情报,帮助网络安全从业人员提前应对可能的未知威胁.Nunes等人[4]提出一个系统,从暗网论坛和黑市收集信息,识别出现的网络威胁.该系统实现了平均每周识别305个高质量的网络威胁预警,包括一些还未大规模应用在表网攻击的恶意软件和漏洞.Han等人[5]提出一种基于Graphical Gaussian模型和Graphical Lasso算法的流量分析方法,可以实时监测通信流量中的恶意软件流量.Han等人[5]的工作使实时监测恶意流量成为可能,并能更快地响应攻击.由以上这些文章可知,暗网已成为一个关键的威胁情报来源,基于暗网研究的重要性不言而喻.
近年来,命名实体识别已经应用于许多领域.在命名实体识别早期阶段,主要是基于规则[6]的和基于字典[7]的方法,在某些特定领域的效果表现良好,但是这种方法十分耗时耗力.为了克服这种限制,命名实体识别开始使用机器学习算法,如支持向量机(support vector machine, SVM)、决策树、Adaboost等.但是,传统的机器学习方法严重依赖手工特征,需要专业领域的专家来设计特征.随着人工智能和感知计算的发展,命名实体识别也开始使用神经网络,不再需要特征工程.广泛使用的神经网络模型包括卷积神经网络(convolutional neural network, CNN)、递归神经网络(recurrent neural network, RNN)、长短时记忆网络(long short-term memory, LSTM)等等.谢腾等人[8]提出了一种基于BERT-BiLSTM-CRF模型的命名实体识别方法,BERT作语言预训练得到动态词向量,相较于传统的语言预训练模型训练出来的静态词向量在中文命名实体识别中更有优势.彭嘉毅等人[9]在命名实体识别中引入主动学习算法,使用较少的标注样本达到了较好的识别效果.命名实体识别技术在不断向前发展.
2 方 法
本文提出了一种基于深度学习的暗网市场命名实体识别系统DNER(darknet named entity recognition),检测5种命名实体,分别是:毒品类(DRUG)、黑客工具类(TOOL)、网络安全术语类(TERM)、信息贩卖类(INFORMATION)和武器类(WEAPON).该系统架构由4部分构成,分别是数据预处理、数据标注、数据向量化、深度学习训练,如图1所示:

图1 NDER系统框架
本模型的具体流程如下:1)数据预处理.通过删除帖子发布日期等其他无用信息,去除冗余干扰信息.对文本进行词形还原,排除包括名词单复数和动词时态的影响.2)数据标注.文本数据的每个单词都将被标注一个词性(part of speech, POS)和一个命名实体标签.单词词性的提取使用NLKT python工具包,命名实体的标注采用基于字典的方法.3)文本向量化.结合单词向量化和字符向量化,CNN算法提取单词字符的形态信息并转化为字符级表示.4)深度学习训练.BiLSTM神经网络根据文本的词级向量和字符向量序列收集特征,并预测命名实体标签.最后,CRF对BiLSTM序列标注结果的相关性进行约束,提高序列标注的准确性.
2.1 数据预处理
暗网市场的命名实体标注文本很少,大多是短文本内容,并不遵循严格的语法规则,且有大量拼写错误和缩写.为了解决以上这些问题,第1步就是删除冗余的词句,如发帖日期和重复回复,并且修正错误拼写.通过浏览数据集,建立一个可能被大量错误拼写的单词词典,匹配数据集的单词和词典并进行替换.修正这些错误和冗余信息使模型的表现效果更好.
2.2 数据标注
由于缺少已标注命名实体的数据集,需要预先对数据集添加标注信息.本文使用NLTK python工具包(NLTK是一个文本处理库,用于分类、词汇切分、词干提取、标记、解析和语义推理)作词性标注.POS标签代表了一个单词的性质和语义功能,一个单词的词性必须为名词,才有可能是一个命名实体,词性对于命名实体的识别有很大帮助.然后根据建立的网络安全相关命名实体字典,采用基于字典的办法对数据集进行命名实体标注.经过这一步骤,数据集中的句子被切分为一个个单词,每个单词都有一个词性标注和一个命名实体标签,作为后续词向量化和字符向量化的输入.
2.3 文本向量化
通常认为,词向量可以从文本中获取有用的语义和句法信息.Word2Vec采用浅层神经网络将文本词向量化[10],主要有2个模型,分别是CBOW模型和Skip-gram模型.CBOW模型根据上下文预测中心单词,而Skip-gram模型基于单词预测上下文.CBOW模型的时间复杂度更低,训练时间更少,所以本文采用CBOW模型进行文本词向量化.
词向量获取单词的形态信息,如前缀和后缀,而字符向量适合提取拼错词、新词(例如,Satoshi作为比特币的最小单位,2019年才被添加进牛津英语词典)的特征[11].CNN和RNN均能进行字符向量化,但是CNN的训练速度优于RNN,本文选择CNN作为文本向量化的模型.CNN对一个单词字符向量化的处理过程如图2所示:
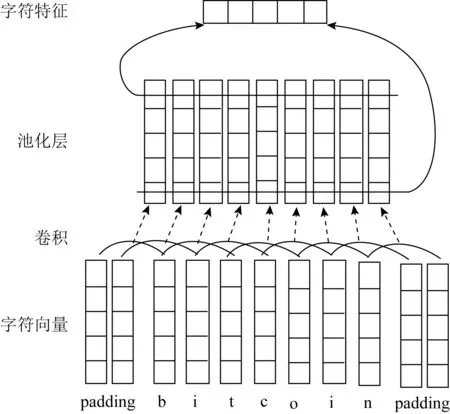
图2 CNN提取字符特征的过程
2.4 BiLSTM神经网络
长短时记忆网络(long short term memory, LSTM)是一种特殊的递归神经网络.BiLSTM层将上层向量化后的数据作为输入,由4个不同结构的重复的模块连接起来[12].RNN支持捕获长文的上下文信息用于当前训练,但是本文模型的应用场景是基于暗网市场.暗网市场文本是短文本,所以本文采用LSTM算法.并且,针对递归神经网络RNN的梯度消失和梯度爆炸问题,LSTM使用门(gate)机制有效解决了这个问题.LSTM单元结构如图3所示:
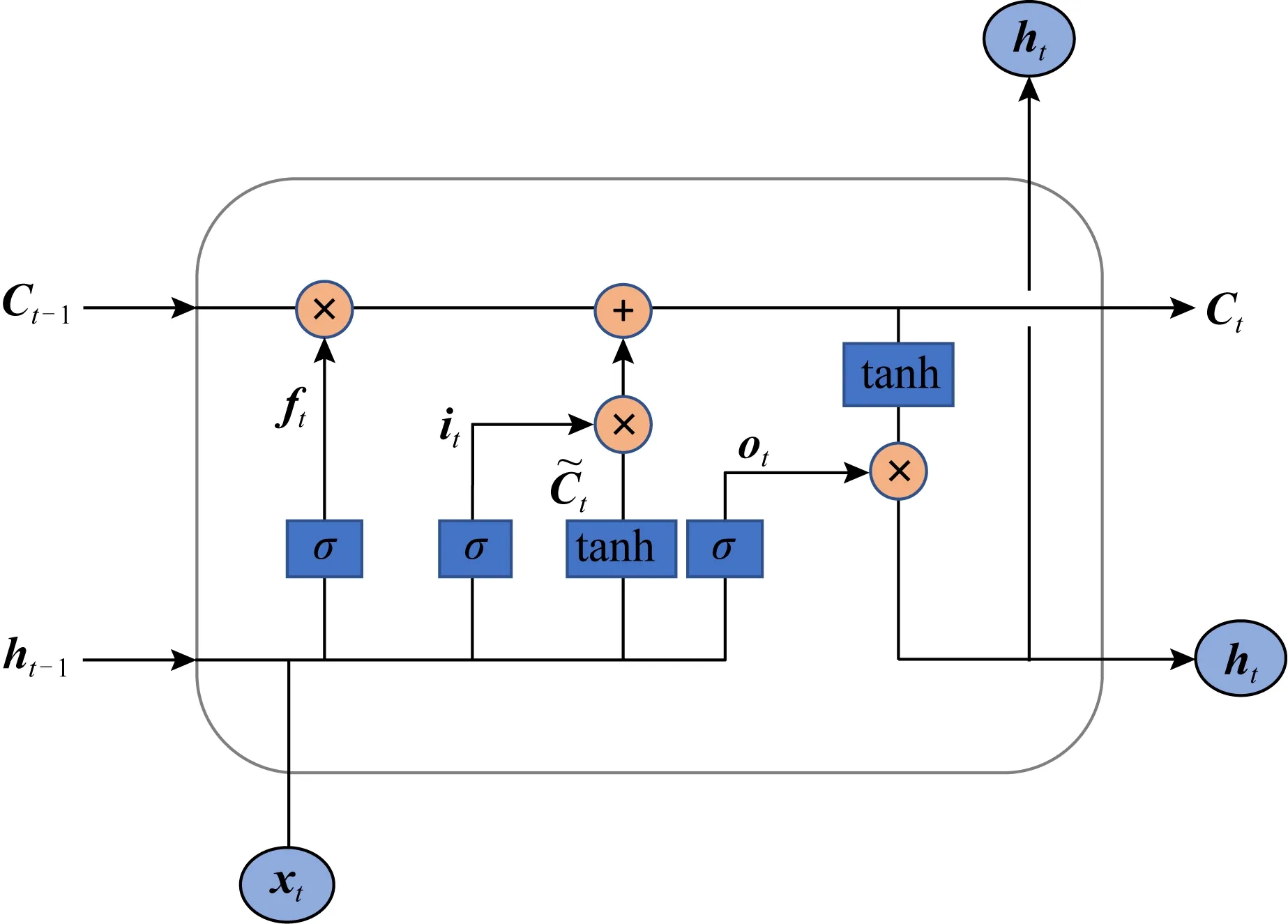
图3 LSTM单元结构
一个LSTM单元就等同于一个神经细胞.LSTM单元内的门(gate)选择性地让信息通过,它由一个Sigmoid神经网络层和一个点阵乘法运算组成.LSTM单元的运算过程如下:
ft=σ(Wf·[ht-1,xt]+bf),
(1)
it=σ(Wi·[ht-1,xt]+bi),
(2)

(3)

(4)
ot=σ(Wo[ht-1,xt]+bo),
(5)
ht=ot×tanh(Ct),
(6)
其中,i代表输入门,f代表忘记门,o代表输出门.σ代表Sigmoid神经网络层.W和b分别代表权重和Sigmoid层的常数.C代表神经细胞状态.
然而,LSTM是单向的基于上文或下文进行分析的模型[13],在很多NLP任务场景,基于上下文的双层双向语言模型相比单向模型更有优势,能够更好地捕获变长且双向的n-gram信息.因此,本文采用BiLSTM神经网络对输入序列进行训练,通过在输入和输出时间步长在向前和向后的2个方向上获得最大的输入序列,并输出每一个单词或词组属于某个实体类别的概率,最后送入CRF层.
2.5 CRF层
条件随机场CRF模型是常用于命名实体识别的图形模型.根据BiLSTM层的输出结果,计算输出一个条件概率分布,预测最终的命名实体标签,保证标注结果的有效性[14].本文采用线性链条件随机场(linear-CRF).假设有2组随机变量:X=(X1,X2,…,Xn),Y=(Y1,Y2,…,Yn),那么线性CRF的条件概率P(Y|X)计算过程如下:
(7)
Z(x)是归一化因子.
(8)
其中,fk是特征方程,ωk是对应的权重.CRF能学习到一些约束条件,对最后的预测结果进行约束.特别是当预测一些多词组合的命名实体时,CRF能自动预测到句子开头的单词标签应该是“B-”或者“O”,而不可能是“I-”.
3 实验分析
3.1 暗网市场语料库
为了构建暗网市场安全语料库,本文采用由Branwen开源的暗网市场数据文本[15],包括89个暗网市场数据、37个论坛数据,如Abraxas,Agora,Silk Road等知名网站.通过删除无用信息,如HTML、图片等内容以减少噪音干扰后,余下一共10 666条帖子.再删除文件大小小于1 000 KB的文件,剩余6 990个文件.最后这些数据以8∶1∶1的比例随机划分为训练集、测试集和验证集.
通过观察收集到的暗网市场文本数据,本文收集了暗网领域命名实体字典,一共分为5类,统计信息如表1所示.毒品类(DRUG)包括Weed,Cannabis,Shroom,Cocaine等;个人信息类(INFORMATION)包括Fake ID,Driving License,Credit Card等;安全术语类(TERM)包括Scam,Malware,DDOS,Botnet等;黑客工具类(TOOL)包括VPN,Napster,Ransomware,Hidemyass等;武器类(WEAPON)包括Rifle,Explosive,Gun,Pistol等.
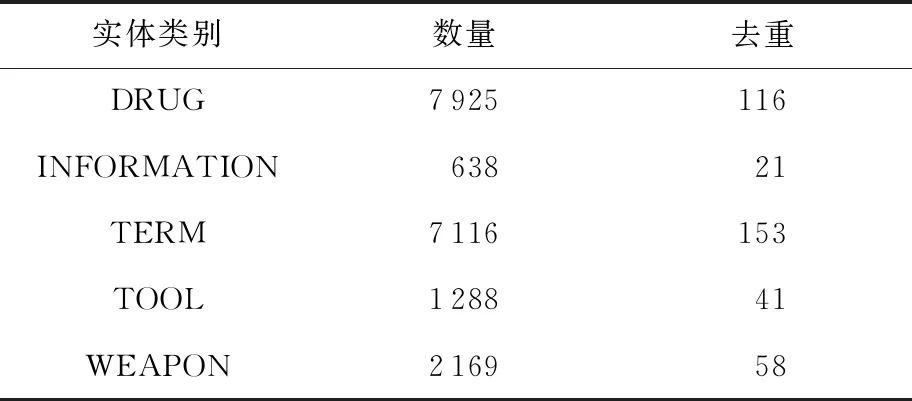
表1 网络安全命名实体统计
考虑到命名实体需要联合标注的情况,如“hack ebook”,本文采用IOB标注方式.B代表命名实体开始单词,I代表命名实体中间单词,O代表这个单词不是命名实体.因此,标注结果有11种类型,分别是B-DRUG,I-DRUG,B-INFORMATION,I-INFORMATION,B-TERM,I-TERM,B-TOOL,I-TOOL,B-WEAPON,I-WEAPON,O.
3.2 实验环境和评价指标
实验环境的软硬件配置信息如下.CPU:Intel®Xeon®CPU E3-1231 v3@3.40 GHz;内存:8 GB;GPU:NVIDIA Corporation GK208 B;操作系统:Linux version 4.15.0-107-generic.
本文评价指标采用精确率P、召回率R和调和平均数F1,其计算公式为:
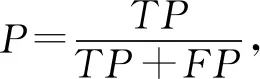
(9)

(10)
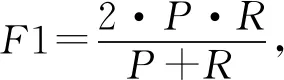
(11)
其中,TP表示标注为阳性的样本中正确的数量,FP表示标注为阴性的样本中错误的数量,FN表示标注为阳性的样本中错误的数量.
3.3 实验设计与结果分析
本实验基于字符向量和词向量,采用BiLSTM和CRF算法训练模型.设置初始学习率为0.005,L2正则化权重设置为0.000 2,可以在某种程度上避免过度拟合.同时,所有的数字也被置换为0,因为具体的数字会导致过拟合.
3.3.1 实验1:与其他模型的比较
本文比较了CNN-BiLSTM-CRF模型、BiLSTM-CRF模型和LSTM-CRF模型在本实验数据集的命名实体识别效果,讨论神经网络中每一层级的作用,如表2所示:
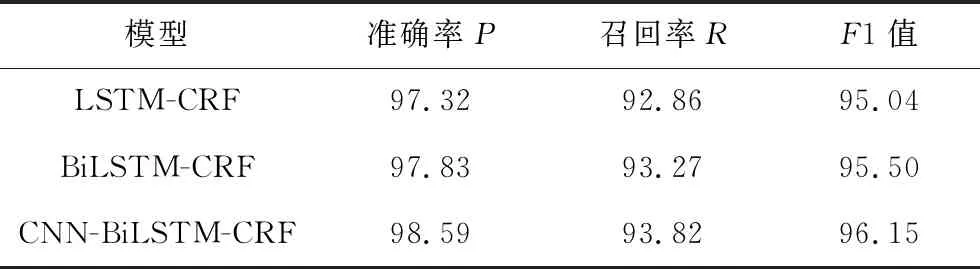
表2 3个模型的比较结果 %
从表2可知,CNN-BiLSTM-CRF模型的识别效果要好于BiLSTM-CRF模型,F1值得分高于0.65%,说明相比只有词向量的模型,字符向量能够增加识别准确率.Na等人[16]的研究表明,字符级向量能够表达词的形态特征,本文的研究结果也验证了这一结果的正确性.并且,BiLSTM-CRF模型比LSTM-CRF模型的F1值高0.46%,说明BiLSTM在序列标注任务方面相对于LSTM具有优越性.可以推测,因为BiLSTM的双向学习,即不仅从序列前端学习到末尾,而且从序列后端学习到前端,具有更好的学习效果.
3.3.2 实验2:不同类型实体的结果比较
本文分别比较了每一种命名实体的准确率P,召回率R和F1值,如表3所示.
从表3可知,每种命名实体的识别效果都不尽相同.命名实体数量最多的2个种类DRUG和TERM,拥有最高的F1值,而INFORMATION类的命名实体数量最少,相对的F1值也最小.通过对表3结果的初步观察,可以看出识别效果可能与命名实体的数量有关.为了验证这种猜想,本文将表3的数据直观展示在了折线图里,以便观察数量和准确率的关系.
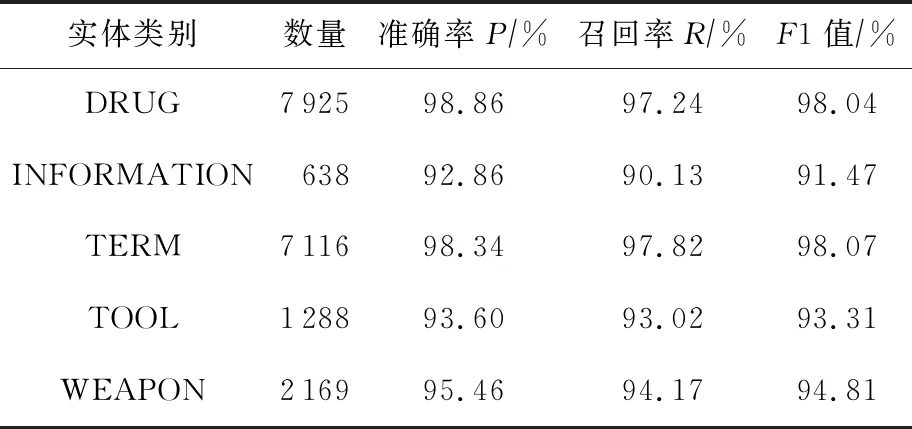
表3 不同种类的命名实体识别效果比较
如图4所示,当命名实体的数量增加时,其准确率、召回率和F1值也会升高,反之,则随之下降.实验结果与前文猜测一致,可以推测,命名实体的数量越多,模型可以从训练集学到的特征就越多,识别效果就越准确.
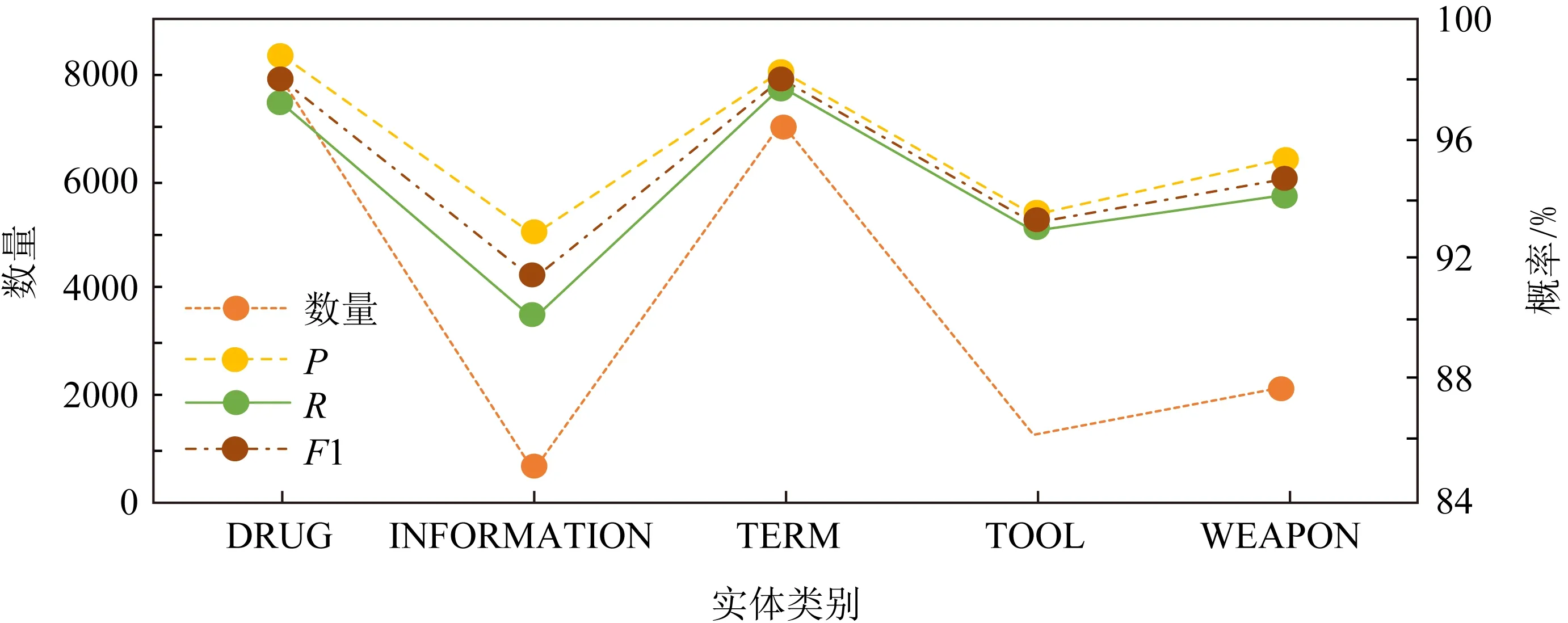
图4 不同种类命名实体的结果比较
4 结 论
本文提出了一种命名实体识别系统DNER,基于CNN-BiLSTM-CRF模型的暗网市场命名识别系统,结合了字符特征与词向量特征.由于缺少已标注的数据集,本文选择了基于字典的方式来标注数据集.词向量和字符向量结合的方式同时提取了词级和字符级的特征,帮助BiLSTM神经网络训练数据以取得更好的识别效果,然后CRF算法约束序列标签之间的相关性.基于上述过程,本文得到了很好的实验效果,阐述了DNER系统在暗网市场文本上的命名实体识别效果比其他模型的优越性.对于小众领域的实体类型,该系统可显著提高识别效果.
在将来的研究工作中,希望可以将该系统应用于知识图谱任务以建立一个暗网市场的知识图谱,并继续优化该系统以更低的代价实现更好的准确率.此外,继续探索此模型在自然语言处理领域任务上的表现效果,如机器翻译、问答系统,希望本文工作为未来的研究者作出一点微小的贡献.
猜你喜欢
法制博览(2021年1期)2021-11-25
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
检察风云(2020年20期)2020-12-03
方圆(2020年16期)2020-09-22
党员生活·中(2020年4期)2020-07-04
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
数字通信世界(2019年3期)2019-04-19
东方女性(2018年3期)2018-04-16
