
在线学习者社会临场感自动编码的最优路径探索
2021-01-04 08:24:20吴怡君冯晓英
开放学习研究 2020年6期
吴怡君 冯晓英
(北京师范大学 学习设计与学习分析重点实验室,北京 100875)
一、问题提出
互联网时代,在线学习和混合式学习逐渐兴起,人们在任何时间、地点都能方便地学习,在线教育巨大的发展潜力初显端倪(约翰·丹尼尔,2016)。但由于在线学习的规模较大,对于学习者而言是否能及时获得教师的支持、对于教师而言能否及时评估学习者的在线学习状态从而进行干预、能否识别并预测合格学习者的特征等都是在线学习领域理论研究者和实践者关注的重要问题(卢紫荆,刘紫荆,郑勤华,2019;曾嘉灵,等,2018)。由加拿大学者加里森等人提出的探究社区理论中的临场感是近年来衡量在线学习者学习水平的一个重要指标(Garrison, Anderson, & Archer, 1999; Ke, 2010; Morris, 2011; Szeto, 2015; 吴祥恩,陈晓慧,吴靖,2017)。
目前研究中常用的方法是问卷法和内容分析法,前者基于学习者自我判定,误差较大;后者数据量大且误差小。但内容分析法要求研究者对大量、冗杂的文本数据进行临场感水平的人工编码,需要花费大量的时间和人力成本。此外,由于人力的局限,人工编码数据的准确性和前后一致性也存在着较大的问题。
近年来,自然语言处理(Natural Language Processing, NLP)技术的迅速发展,为临场感的测量带来了新的可能。理论和技术的日渐成熟,开源的中文自然语言处理工具包越来越多,使用方法也都十分方便易懂。将中文自然语言处理技术运用到论坛帖的文本内容分析中,实现临场感的自动编码和水平测量,从而帮助教师及时了解学习者的在线学习水平,这或许是一种值得探索的解决方法。由于研究人员和时间的限制,本研究仅以探究社区理论中的社会临场感为例,进行了编码路径的探索。
本研究以在线学习者社会临场感的编码为例,希望能够借助自然语言处理的已有算法、技术和工具,探索在线学习者会话内容自动编码的不同算法路径。通过比较可行路径得出最优路径,从而实现文本的自动编码和学习者社会临场感水平的测量。
二、文献综述
(一)社会临场感水平的测量
探究社区理论模型(Community of Inquiry Framework),又称探究社区框架(见图1),是由加拿大学者加里森等人共同提出的一个对在线学习者学习状态进行分析的动态模型(Garrison et al., 1999)。该理论认为,在线学习和混合式学习中有三个关键要素:社会临场感(Social Presence)、教学临场感(Teaching Presence)及认知临场感(Cognitive Presence),只有当这三个要素均达到较高水平时,有效学习才会发生(Garrison, Anderson, & Archer, 2001)。
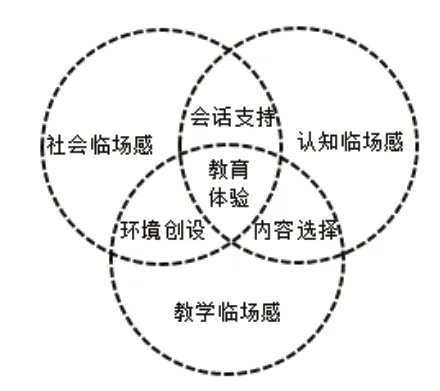
图1 探究社区模型示意图
目前学者们常用于临场感水平编码测量的方法是问卷调查法和内容分析法。问卷调查法需要研究者设计测量问卷或是应用已有的量表工具对在线学习者临场感水平进行测量。Conrad(2005)使用问卷调查、访谈等方法测量了一组研究生学习者的临场感水平,持续地追踪了他们的社区意识发展。内容分析法则往往需要研究者对在线课程中学习者的主题帖、评论回复等进行人工编码,从而确定学习者的临场感水平。Olesova、Slavin和Lim(2016)采用定量的内容分析法探究了脚本对学习者在异步在线讨论中的认知临场感水平的影响。Akyol和Garrison(2008)分析了社区的问卷调查结果,并对在线课程中论坛发帖进行了内容分析,从在线学习者临场感水平的变化探索了探究社区的发展。
问卷调查法的操作步骤较为简单,数据结构良好,但只能收集学习者行为及感受的小部分数据,与学习者真实的临场感水平有一定的偏差。内容分析法的对象是全学习过程的所有文本内容,数据量大且较为全面、丰富,但在目前的临场感研究中,内容分析法几乎完全依赖人工编码。这样的内容分析方式会耗费大量的人力、时间成本,分析的准确性和前后一致性也难以得到保证。
自然语言处理领域的迅速发展,为内容分析法在临场感的低成本自动测量带来了新的可能。因此,本研究希望创造性地借助现有的自然语言处理技术,探索机器自动编码分析及测量临场感水平的最优路径。
(二)社会临场感中文编码框架

表1 社会临场感中文编码框架
北京师范大学冯晓英教授的团队对Garrison等(1999)提出的探究社区理论模型框架中的三种临场感对应的不同策略、标准进行了翻译,得到了完整的临场感中文框架。基于Rourke、Anderson、Garrison和Archer(2001)对社会临场感内容分析框架的进一步阐释,对社会临场感的中文编码框架进行了完善(见表1)。在本研究中采用这一框架作为理论依据,对国家开放大学一期学习数据进行人工标注,形成监督学习的训练语料,对验证本研究探索出的自动编码路径是否正确有重要的参考作用。
(三)自然语言处理的思路与方法
近年来,能够自动对海量的本文信息进行处理、分析、理解的自然语言处理成为人工智能领域的一大研究热点。美国计算机科学家Manaris(1998)将自然语言处理看作是一门研究在人与人、人与计算机之间的交际语言问题的学科。有赖于该领域研究者和实践者的共同努力,中文自然语言处理技术发展到现在已经较为成熟,有广泛的应用问题域,常见的有机器翻译、情感分析、智能问答、文摘生成、文本分类、舆论分析和知识图谱等。
本研究预期实现的功能本质上是以上提到的文本分类问题。随着国内在线文本数量增长和机器学习的兴起,逐渐形成了一套解决大规模文本分类问题的经典方法。文本分类的常用方法是词法分析、机器学习、混合分析以及深度学习,本研究采用机器学习的方法进行文本分类。
在机器学习的文本分类问题中,首先需要对数据进行定义,即贴上类别标签。在对分类好的文本做好分词、去停用词等数据预处理的工作后,用相应的特征提取算法,提取文本最有意义的特征向量。接下来就是最重要的模型训练阶段,选择不同的分类算法,放入特征向量后训练出对应的文本分类器。用之前划分好的测试集对不同路径训练出的分类器进行测试,评价分类器的质量。通过比较,选择通过最优路径构建的分类器,对文本数据进行分类。
三、研究设计
(一)研究目标
本研究旨在运用Python中文自然语言处理文本分类问题中机器学习的相关算法技术,尝试对在线课程中的论坛贴文本内容进行不同路径的建模,比较不同分类器的模型质量后得出最优路径,构建在线学习者的社会临场感编码模型组,实现对文本进行自动编码和在线学习者社会临场感水平的测量,从而更好地帮助教师及时了解学习者的学习状态并进行相应的干预。
(二)研究问题
针对确定的研究目标,本研究需要重点解决以下三个研究问题:
Q1: 临场感自动编码的可行路径有哪些?
Q2: 最优路径是什么?
Q3: 最优路径的有效性如何?
(三)数据集
本研究将基于Moodle平台的国家开放大学在线教师培训课程“在线辅导”作为课程案例。该课程为持续一学期的线上课程,共有44名学习者有效参与,学习者均是国家开放大学的一线教师。选取的研究对象是此前已被人工编码的课程论坛帖,以一个讨论帖作为基本数据单元。初步筛选无效数据后,两位编码人员以社会临场感中文编码框架为理论指导背对背对论坛帖进行编码。综合两位编码人员的社会临场感编码结果,清除无法达成一致编码结果的数据,最终获取了社会临场感三个策略维度的有效编码数据,数据量如表2所示。

表2 社会临场感有效编码数据表
(四)重要技术
本研究运用的研究方法是自然语言处理,使用了jieba开源分词工具,对论坛中的文本内容进行分类,从机器学习的方法上来看是有监督的学习问题。研究过程中共涉及四项重要技术:特征提取、分类算法、模型评估和临场感水平测量。
1. 特征提取
在一条文本数据中仅有少量信息对分类任务有意义,即“特征”,为了提升获取信息和训练模型的效率,研究采用了词袋模型和TF-IDF算法两种方式进行特征提取。
2. 分类算法
自然语言处理中机器学习的核心是算法。本研究选取了机器学习常用的三种分类算法:多项朴素贝叶斯、支持向量机和逻辑回归。
3. 模型评估
为了评估训练出的分类器模型的性能,研究选取了准确率(Accuracy)、精准率(Precision)、召回率(Recall)和F1测度(F1-measure)四个维度。准确率反映了分类正确的样本占总样本量的比例。精准率和召回率是检索系统中的常用概念,前者表示正确预测为正的占全部预测为正的比例,后者表示正确预测为正的占全部实际为正的比例。一般而言,精准率和召回率无法同时达到理想数值,F1测度即为准确率和召回率的调和平均值。
4. 临场感水平测量
每一条文本数据都有对应的发帖人,训练出的分类器对文本数据进行预测编码,体现社会临场感某一策略维度的标记为“1”,计1分;否则标为“0”,不计分。调用Python中Collections集合模块中的Counter函数累计分数,从而获得每一位学习者的临场感水平。
(五)研究过程
研究过程共分为六个阶段,分别是:提出研究问题、标注语料、数据预处理、探索可行路径、比较最优路径和有效性验证。
1. 提出研究问题
对探究社区理论的相关文献进行整理和研究,归纳出研究者对临场感自动编码工具的需求,结合中文语言处理技术的发展现状,确定研究目标进而提出三个关键的研究问题。
2. 标注语料
第一步,确定编码框架。本研究采用了北京师范大学冯晓英教授的团队根据加里森等人提出的探究社区模型汉化的临场感编码中文框架。
第二步,数据清洗及预编码。对论坛帖进行初步筛选,剔除重复的、无意义的以及非学习者发帖的数据。两名研究人员按照编码框架对两百条数据进行预编码。在编码过程中及时沟通交流,对编码不一致的数据进行讨论,从而基本达成对编码框架的理解共识。
第三步,标注语料。两名研究人员以社会临场感编码中文框架为理论指导对论坛数据进行背对背编码。经过比对两名研究人员的编码结果,剔除编码不一致的数据,得到标注语料作为本研究的训练数据。
3. 数据预处理
第一步,规范格式。原始的论坛帖文本内容是以PDF格式保存,不符合建模的数据规范,因此需要先将初始数据规范化处理成建模需要的TXT格式。每一个论坛帖都有相对应的发帖人名以及社会临场感编码,将三类数据按顺序一一对应地存入TXT中,便于后续研究的进行。
第二步,分词。中文语言处理相较英语而言更难,原因之一就是中文不像英文一样有天然的词分隔符。因此所有中文语言处理任务的第一步都是分词。本研究选取了功能丰富但操作相对简单的分词软件jieba进行分词。
第三步,去除停用词。在文本内容中常常出现和表达句意无关的字词、标点符号等,对于文本处理的速度和效果都有影响,这些被称作“停用词”,需要去除。本研究自定义了停用词表,在常见停用词的基础上保留了对于社会临场感“情感的表达”(AF)这一策略有表征作用的“!”“哈哈”等,最终停用词表的内容包含大部分标点符号、数字编号、无意义的连词,如“。”“1.”“或者”等。
4. 探索可行路径
将预处理后的数据划分成训练集和测试集,测试集比例为30%。分别使用词袋模型和TF-IDF算法提取特征向量后采用三种不同的算法:多项朴素贝叶斯(MNB)、逻辑回归、支持向量机方法训练分类器,最终得到六个不同路径的模型:基于词袋模型特征的贝叶斯分类器、基于词袋模型特征的逻辑回归分类器、基于词袋模型的支持向量机分类器、基于TFIDF的贝叶斯分类器、基于TF-IDF的逻辑回归分类器和基于TF-IDF的支持向量机分类器。
5. 比较最优路径
引入评估函数分别检验六个不同路径构建的分类器在社会临场感三个策略维度上的准确率、精准率、召回率以及F1测度等四项评估数值,通过对比分析得到每一策略维度对应的最优路径。
6. 有效性验证
调用Collections模块,以累计的方式测量得到每一位学习者的社会临场感水平,并将其与学习者的真实水平对比,验证最优路径获得的分类器是否能够有效地测量出在线学习者的社会临场感水平。
四、研究结果
(一)临场感自动编码的可行路径
通过应用不同的特征提取方法和分类算法,共找到六条可行路径:基于词袋模型特征的贝叶斯分类器、基于词袋模型特征的逻辑回归分类器、基于词袋模型特征的支持向量机分类器、基于TF-IDF的贝叶斯分类器、基于TF-IDF的逻辑回归分类器和基于TF-IDF的支持向量机分类器。每条可行路径训练得到社会临场感三个策略维度的模型:情感的表达(AF)、开放的交流(OC)、团体凝聚力(CH)。进一步调用函数评估六个不同分类器训练得到的十八个模型的质量,评估数值包括准确率、精准率、召回率以及F1测度。
(二)最优路径的比较
通过比较不同路径训练的分类器的准确率、精准率、召回率以及F1测度四项数值(重点比较准确率和F1测度),解决 “最优路径是什么”的研究问题。
比较“情感的表达”(AF)策略维度的六个分类器的评估数值,如图2所示,模型质量相差不大。基于词袋模型特征的贝叶斯分类器准确率相对较低,为0.67;基于词袋模型特征支持向量机分类器F1测度相对较低,为0.65;基于TF-IDF逻辑回归分类器四个评估指标均为第一,模型质量最高。

图2 “情感的表达”(AF)不同路径分类器比较图
比较“开放的交流”(OC)策略维度的六个分类器的评估数值,如图3所示,模型质量相差极小且评估数值均在0.7以上。基于TF-IDF的贝叶斯分类器和基于TF-IDF的逻辑回归分类器模型质量相对较差;基于TF-IDF的支持向量机分类器四个评估数值均达到0.85左右,模型的综合质量相对更高。
比较“团体凝聚力”(CH)策略维度的六个分类器的评估数值,如图4所示,模型质量相差较大。基于词袋模型特征的支持向量机分类器准确率相对较低,为0.64;基于词袋模型特征的贝叶斯分类器准确率相对较高,为0.68;基于TF-IDF的支持向量机分类器F1测度相对较高,为0.62;综合来看,基于词袋模型特征的贝叶斯分类器模型质量最好。
对于本研究采用的数据,TF-IDF的特征提取略优于词袋模型,有利于提高分类器的模型质量。而贝叶斯、逻辑回归、支持向量机三种分类算法无明显的差别。综合以上比较结果,分别选取三个策略维度最优路径的分类器,形成用于编码在线学习者社会临场感的模型组,如表3所示。
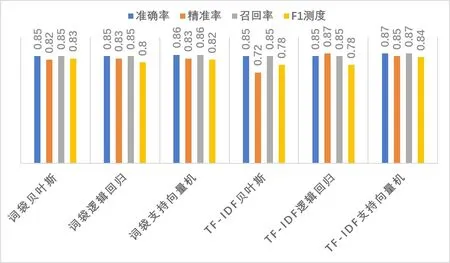
图3 “开放的交流”(OC)不同路径分类器比较图
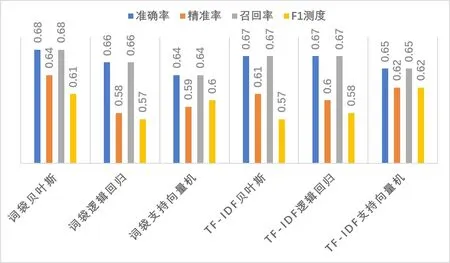
图4 “团体凝聚力”(CH)不同路径分类器比较图

表3 在线学习者社会临场感编码模型组
(三)有效性验证
调用函数获取44位学习者社会临场感水平的模型组预测值和真实值。首先用单因素方差分析方法对两组数据进行差异性分析,分析结果如表4所示。两组数据的单因素方差分析的显著性系数p值大于0.05,说明两组数据的差异无统计学意义的差异。此外,进一步分析两组数据的相关性,表5结果显示真实值和预测值显著相关(p<0.001)。综合以上两个分析结果来看,模型组预测得出的学习者社会临场感水平与真实的社会临场感水平较为接近,误差在可接受的范围之内,模型的有效性得到验证。
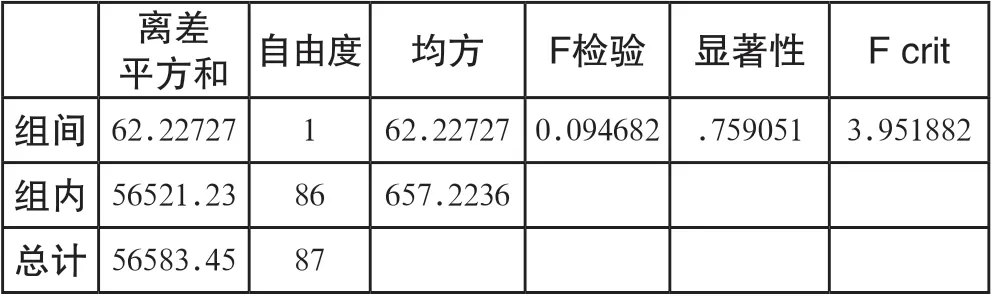
表4 学习者临场感水平预测值和真实值的方差分析

表5 学习者临场感水平预测值和真实值的相关系数分析
五、讨论
作为一项路径探索的研究,研究路径和研究设计是本研究最为核心的部分,其中有以下三点值得进行更加深入的思考和讨论。
(一)采用机器学习方法提高模型质量
目前文本分类问题在自然语言处理领域有很多经典的解决方法,这些方法的实现步骤、关键技术等都有所差异。在进行本研究的最优路径探索时,为了尽可能地提升建模的效果,对四种较为常见的文本分类方法进行比较和分析,如表6所示。

表6 文本分类常用方法
在这四种方法中,混合分析目前还没有较为成熟的算法可以借鉴。此外,本研究所采用的数据集数据量大约在2 000条,但未达到深度学习的水平,因此后两种方法都不适合采用。数据集此前已被编码(即已经人为确定规则),数据质量较好,符合应用机器学习方法的条件。词法分析需要预标记词汇组成的字典,而社会临场感的测量往往并不能仅仅以某个词作为判断标准,所以词法分析并不适用于本研究。
综上所述,本研究选取了文本分类问题中常用的机器学习方法,研究结果显示,通过机器学习方法训练出的模型质量较高,符合预期,可以为后续的相关研究提供参考。
(二)通过比较多条可行路径得出最优路径
正如前文的研究目标所述,本研究希望能够探索在线学习者社会临场感自动编码的最优路径。而最优路径的产生必定离不开多条可行路径的探索。在文本分类问题的机器学习中,特征提取和分类算法的选择是关键环节。本研究选取的特征提取算法有两种,分别是词袋模型和TF-IDF算法,选取的分类算法是朴素贝叶斯、逻辑回归和支持向量机三类算法。通过对这两个环节不同算法选择的组合,共得到六种可行的临场感编码路径。
为了比较六种不同的编码路径,本研究引入了准确率、精准率、召回率以及F1测度四个评估指标。通过对量化指标的对比,能够更加明确地看出哪条路径训练的模型质量更好,从而得出最优路径。
从研究结果来看,引入的四个指标很好地表征了路径之间的差异。但另一个问题随之而来,路径的评估数值有高有低,但差异很小,这在一定程度上表明路径的探索还不够开阔。在后续的研究中可以有意识地选取更多算法,探索差异更大的路径,不断迭代,寻找在线学习者临场感编码的最优路径。
(三)自然语言处理的过拟合
过拟合与欠拟合相对,是指机器学习模型或者是深度学习模型在训练样本中表现得过于优越,导致在测试数据集以及验证数据集合中表现不佳的现象。自然语言处理的核心环节是构建模型,而模型构建的关键在于算法和训练数据集的选择,过拟合的产生原因主要就来源于这二者。
本研究首要的研究问题是探索临场感自动编码的可行路径有哪些。为了尽可能地节省探索的时间和人力成本,在正式探索前,采用少量的数据样本作为训练集对不同算法组合进行初步尝试,但构建出的六个不同路径的模型都出现了过拟合现象。
由于采用的算法都是自然语言处理领域较为成熟的算法,并且六个模型都出现了过拟合现象,因此初步排除了算法选择失误的可能性。结合过拟合产生的两种原因,应该是作为尝试的训练数据样本选择出现了失误。深入分析抽取的少量数据样本,发现收取的这部分数据主要来源于小组破冰时的论坛交互,社会临场感表现十分显著,与课程实施时的平均水平有较大差异,从而导致过拟合产生。
重新选取数据样本后,经验证,在训练集选择恰当的情况下,采用不同算法组合构建的分类模型均没有出现过拟合现象。在自然语言处理的相关研究中,当处理数据出现问题时,回到数据的真正意义上去分析是明智的选择。
六、总结与展望
随着国内学者越来越多地将探究社区理论引入在线学习、混合式学习的相关研究,如何准确且高效地对中文在线课程中学习者的交互内容进行临场感编码也被更多人所关注。本研究探索了用自然语言处理的方法讨论文本临场感自动编码的建模技术。通过分别比较三个不同策略维度的六个分类器的模型质量,选取模型训练的最优路径,进而形成在线学习者的社会临场感编码模型组。将模型预测的学习者社会临场感水平与真实水平对比,误差在可接受范围内,能够较为准确地测量学习者的社会临场感水平,验证了模型的有效性。
本研究的研究成果能够较为准确地对在线学习者的社会临场感水平进行自动编码,为后续基于论坛讨论数据的临场感自动分析工具开发提供了扎实的技术和模型基础,从而能够快速地、低成本地实现对在线学习者临场感水平的编码测量。此外,本研究对于自动编码路径的探索过程能够为其他模型工具类研究提供一定的参考和借鉴,从而拓展丰富模型工具类研究的研究思路。
由于研究实践、人员等多方面的限制,本研究仅构建了社会临场感的编码模型组,数据来源较为单一,数据量相对较少,模型的完善度和稳定性还有很大的提升空间。在后续的研究中,期望能够基于更加丰富的数据,尝试应用深度学习算法等方式探索其他的建模路径,完善社会临场感编码模型组,并构建认知临场感和教学临场感的编码模型组,进而形成一套完整的临场感水平测量工具,实现对学习者在线交互文本的临场感自动编码和测量。
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09 06:12:12
学生天地(2020年15期)2020-08-25 09:22:02
汉字汉语研究(2020年2期)2020-08-13 07:52:48
意林·少年版(2020年2期)2020-02-18 11:14:52
电子制作(2019年22期)2020-01-14 03:16:24
疯狂英语·新读写(2018年3期)2018-11-29 22:37:11
电子测试(2018年1期)2018-04-18 11:52:35
海外华文教育(2016年4期)2017-01-20 08:22:24
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
