
业务网核心数据库及运行环境高可用改造实践
2021-01-04 12:45:36陈真玄范宇楠
水利信息化 2020年6期
陈真玄 ,范宇楠 ,张 怡 ,杨 柳
(1. 水利部信息中心,北京 100053;2. 北京金水信息技术发展有限公司,北京 100053)
0 引言
随着大数据时代的到来,水利信息化建设的不断深化,信息化范围逐步扩大,目前信息化建设已全面覆盖了防汛抗旱、水资源管理、水土保持、河长制、农村水利和电子政务等水利业务领域,大大提高了水行政管理和公共服务能力,提升了水利信息化水平。然而由于信息系统规模越来越大、应用范围越来越广,对数据可靠性的要求也越来越高,数据库作为管理数据的核心系统也变得越来越重要。在此情况下,对数据库系统进行高可用改造迫在眉睫。
1 数据库现状及面临的问题
水利部信息中心数据库在政务内网、业务网、DMZ 区 3 个区域分别采用大集中管理方式,特别是业务网核心数据库承载了水情、气象、财务、水资源、河长制等几十个重要业务应用,部分业务为全国大集中部署,一旦数据库瘫痪,将严重影响水利业务系统的正常运转和工作的正常开展。
业务网核心数据库目前已配置为 Oracle RAC 集群架构,运行在 2 台 IBM P750 小型机上,数据存放在 1 台 EMC VMAX 存储上,数据量约 25 TB。当1 台服务器硬件故障时,不影响数据库使用。此外,数据库配置了 RMAN 定期备份,可以为数据安全提供最后的保障。
但是目前仍然存在以下几个问题:
1)数据库集群只是实现了服务器冗余,数据库系统仍是单点,由于数据库 Bug、资源异常等原因引发的数据库故障,仍会影响业务系统运行。
2)数据库打补丁、升级等变更操作需要停止数据库,中断应用系统运行,并且由于变更操作时间窗口较长,一旦过程中发生问题会影响应用的恢复时间。
3)由于目前数据库数据量较大,在数据库损坏的情况下如果使用数据库备份进行恢复的话,恢复时间很长,业务会长时间中断,影响较大。
4)由于数据库是单存储,数据库的存储硬件故障会导致数据丢失或数据库不可用,严重影响业务系统运行。
因此迫切需要改造业务网核心数据库,提升数据库的可用性,避免硬件故障导致数据库不可用,缩短变更操作需要的停机时间,确保关键业务的连续性。
2 数据库高可用改造方案设计
2.1 数据库高可用概述
高可用性,指系统无中断地执行其功能的能力,代表系统的可用性程度。实现高可用有以下 3 个原则:
1)消除单点故障。通过增加系统冗余的方式,当系统部件故障时由其冗余部件接替,避免整个系统失效。
2)可靠的交汇点。交汇点通常指不容易冗余的节点,比如负载均衡器、Master 节点等,一般来说主从结构的系统中,交汇点本身往往会变成故障单点,可靠的系统中必须有可靠的交汇点。
3)故障监测。在遵循以上 2 个原则的基础上,监测故障,当发生故障时用冗余部件接替故障部件(Failover)实现高可用。
2.1.1 数据库可用性与一致性
相对于 Web 服务器等无状态系统,数据库作为有状态系统其高可用存在更多挑战,难点之一就是冗余部件的数据一致性问题。
数据一致性是指分布式系统中不同部件/节点/副本之间在相同时间点的数据相同,通常分为强、最终和弱一致性。
强一致性是指同一时间点不同副本的数据是一致的,最终一致性是指经过一定时间延迟后可以确保不同副本之间数据是相同的。如果数据库采用异步复制方式,在 Failover 时数据没有完全同步完、但能在 Failover 后将未同步完的数据复制过去则可以实现最终一致性;如果数据库采用同步复制方式,可以保证数据的强一致性,但可能会导致系统性能问题,因此数据库高可用的设计要根据业务需求在高可用和数据一致性进行权衡[1]。
2.1.2 数据库 RTO 与 RPO
恢复时间目标(RTO)和恢复点目标(RPO)用来衡量故障发生后数据库系统的恢复时间。RTO表示系统从故障发生到必须恢复的时间;RPO 是数据可用性指标,是指故障发生后系统和数据必须恢复到的时间点,与数据库一致性相关,数据强一致的冗余部件其 RPO 为 0,非强一致的冗余部件取决于其丢失的数据量[2]。
2.1.3 数据库可用性评价指标
数据库系统不可用通常分为 2 类场景:1)计划停机。指无法通过系统设计避免而必须进行的有计划停机,通常包括例行操作、周期维护、升级等操作,计划停机通常对业务有影响但不会丢失数据。2)意外停机。指由于系统故障、数据或介质错误、机房设施中断等导致系统非正常中断,通常会对业务和数据造成影响[3]。
系统可用性表示为正常运行时间与期望时间的百分比,通常作为服务水平协议(SLA)的 1 个指标,不同量级的可用性用数字 9 的个数表示,从1 个 9(90)到 5 个 9(99.999)。传统数据库的可用性一般是 95%~98% 之间,通过高可用技术和管理手段可以提高至 99.999%。数据库可用性及对应的停机时间如表 1 所示。

表 1 数据库可用性度量表 [3]
从数据库系统的组成来看,有以下几种冗余方式可以提高其可用性:
1)服务器冗余。通常采用双机集群、集群等方式在服务器层进行冗余,集群相比双机集群在切换时间及资源利用率方面更快更有效。
2)存储冗余。同一存储中采用 RAID 进行磁盘间冗余,存储之间采用存储级镜像、PV 复制、块复制等技术实现冗余。
3)网络冗余。采用交换机双活等网络设备冗余技术。
4)数据库或站点冗余。通过存储级和数据复制等进行站点间冗余,避免单个数据库或站点因为电力等设施发生故障导致的数据库不可用,新型的分布式数据库可以通过数据分片、一致性数据复制等技术实现跨地域多活的站点冗余。
2.2 数据库高可用改造目标
改造后的数据库不同场景的 RTO 和 RPO 如表2 所示。
数据库每月期望的服务时间为 60×24×30 =43 200 min,如果假设数据库每月各种事件都发生1 次,改造后意外和计划停机时间约为 20 min,数据库可用性可达到(43 200 - 20)/43 200 = 99.950%。
2.3 数据库高可用改造技术方案
Oracle 数据库主要的高可用技术如下[4]:
1)Oracle Real Application Clusters(Oracle RAC)。Oracle RAC 对服务器进行冗余,提高了数据库实例或服务器出现中断时应用程序可用性。OracleRAC 的服务器故障切换瞬间完成,另外还消除了计划维护任务造成的停机。
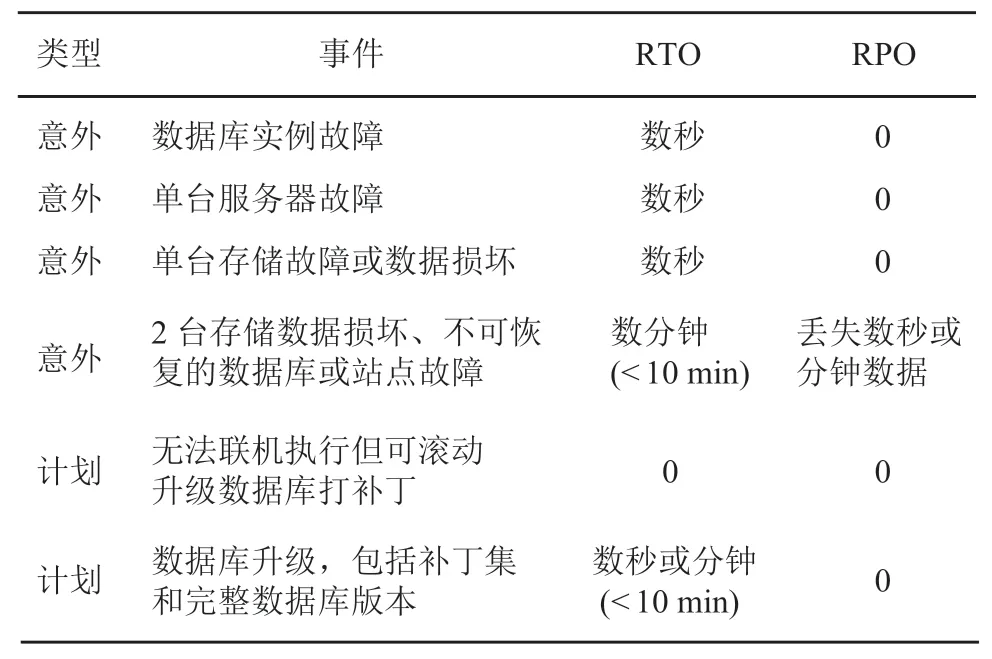
表 2 数据库 RTO 与 RPO 指标 [4]
2)Oracle Data Guard。Oracle Data Guard 对站点进行冗余,在远程位置维护一个同步物理副本(备用数据库),用于消除生产数据库(主数据库)或站点的故障,在数据库升级时可以转换为逻辑备库减少停机时间。
3)Oracle ASM。Oracle ASM 通过双存储对数据库存储进行冗余,ASM 将数据组织成 Extent 连续数据块,在每个存储上各保留 1 份,替代传统的存储镜像技术,消除单台存储故障或数据损坏对数据库的影响,简化了数据库存储管理,并且能够自动进行 I/O 平衡。各种数据库高可用技术特点对比如表 3 所示。

表 3 数据库高可用技术特点对照表
高可用设计考虑:
1)Oracle RAC 数据库作为对等架构的集群式数据库,没有物理上的 master 节点,可以理解为master 节点能运行在任意节点,所以其交汇点是可靠的,负责集群管理的 CRS 组件会监控包括数据库实例在内集群资源状态,发生故障时自动进行切换,可以实现高可用。
2)Oracle ASM 也是 CRS 组件的集群资源,其高可用机制类似 RAC,能够实现高可用。
3)考虑到现有的备用数据库计算能力较弱,切换时需要停止部分业务,避免备库过载,Oracle Data Guard 采用手工切换的方式,主库发生故障时监控系统报警,需要人工执行脚本进行切换。
数据一致性考虑:
1)Oracle RAC 的服务器虽然有数据,但其数据要写入存储持久化,所以可以理解为无状态系统,其通过私有网络进行的数据同步可以提高速度,没有一致性问题。
2)Oracle ASM 在 2 个存储间采用同步写入,正常情况下,1 个数据块写到 2 个存储才算成功,因此数据是强一致的。
3)Oracle Data Guard 采用异步复制,主备库是弱一致,主节点故障时如果日志没有完全传过去会丢失部分数据,后期会探讨在主库宕机时将未传过去日志通过其他手段发送到备库,实现最终一致性。
本次实践在水利部现有 Oracle RAC 核心数据库基础上,利用 Oracle Data Guard 数据库建立备份节点,利用 Oracle ASM 实现双存储冗余构造高可用架构。
2.3.1 Oracle Data Guard 高可用改造
利用 2 台水利部信息中心现有的 IBM P570 小型机搭建 Data Gurad 备用数据库,采用 IBM DS4800作为后端存储。Data Guard 使用数据库复制技术消除单点故障,并且为所有类型的意外中断提供可靠的数据保护和高可用性级别,包括数据损坏、数据库和站点故障。备用数据库还为在计划维护期间减少停机提供了实质性优势,将 RTO 降低到了数秒或数分钟,伴随的 RPO 为 0 或近乎为 0。
Oracle Data Guard 提供 3 种数据保护模式[5]平衡成本、可用性、性能和事务保护,Oracle Data Guard数据保护模式如表 4 所示。
本次改造由于现有环境的备用数据库性能较低,主备库配置差距较大,且需优先保证主数据库的性能,因此选择最大性能模式。
通过 Data Guard 改造实施,当主数据库由于存储、服务器等发生故障不可用时,可以切换到备用数据库,此时应用可以访问备用数据库继续执行业务,异步模式下备用数据库通常最多只会丢失数秒或分钟的数据。此外,通过 Data Guard 可以将打补丁、升级、迁移等变更操作的计划停机时间减少到分钟甚至秒级。

表 4 Oracle Data Guard 数据保护模式
2.3.2 Oracle ASM 高可用改造
在此阶段新增华为 6800 存储,通过 Oracle ASM创建 Normal 冗余的双存储磁盘组,当一套存储故障或数据丢失时,另一套存储可以继续提供服务不影响数据库运行。
Normal 冗余磁盘组在每套存储上创建 1 个Failgroup,数据组织成 Extent 连续数据块,在 2 个Failgroup 各保存 1 份,其中一个为 Primary Extent,另一个为 Second Extent,每个 Extent 在各自 Failgroup的位置并不相同。
数据库在将数据写入磁盘时会以并行异步的方式同时写入 2 个存储,异步写入请求发起后,数据库可以继续执行其他 I/O 或操作,当 2 个存储的异步 I/O 都返回后写入操作才算完成。
数据库需要读数据时,会先读取 Primary Extent,如果 Primary Extent 不可用,则从另一个存储中的Second Exten 中读取[6]。
当一套存储的某块磁盘连续几次不可读写时,数据库会 Offline 这块盘,此时数据库会将数据写入同存储其他可用磁盘,数据依然是双份冗余。如果整个存储不可用,数据库会访问另一个存储的数据,此时数据库仍然可以正常运行。
ASM 改造后整体架构如图 1 所示(红色为新增部分)。
3 水利部数据库高可用改造实施过程
3.1 Data Guard 改造实施
Data Guard 改造主要实施步骤如下:
1)主库激活 Foreced Logging。
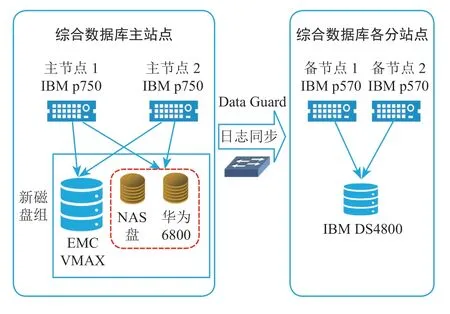
图 1 数据库双存储系统改造实施后架构图
2)设置主库 LOG_ARCHIVE_DEST_2 参数,控制数据同步方式:
LOG_ARCHIVE_DEST_2 ='SERVICE = stdby LGWR ASYNC VALID_FOR = (ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME = fxdbstb'。
3)主库创建 Standby Redo Log 日志,用于主库切换为备库后使用,其大小与主库日志相同。
4)拷贝主库密码文件到备库,确保主备库密码一致。
5)复制主库参数到备库并修改作为 standby 参数文件,主要参数设置如下:
*.LOG_ARCHIVE_DEST_2 = 'SERVICE = fxdb LGWR ASYNC VALID_FOR = (ONLINE_LOGFILES,PRIMARY_ROLE) DB_UNIQUE_NAME = fxdb'。
6)主备库 4 个节点增加静态监听,设置 fxdb,fxdbstb 等 tnsname,用于传送归档时的 tnsname解析。
7)备份主库用以创建备库,在主库上创建备库控制文件,并传送到备库服务器,命令如下:
backup current controlfile for standby format '/backup/dg/ctlbak_%U'。
8)采用 duplicate 方式通过主库备份创建备库:rman target sys/ @fxdb1 auxiliary/
duplicate target database for standby nofilenamecheck dorecover。
9)创建备库后,通过同步日志方式追平备份主库后产生的归档。主库启动日志同步:
ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2 = ENABLE SID = '*';
备库启动 MRP 进程:
ALTER DATABASE RECOVER MANAGED STANDBY DATABASE USING CURRENT LOGFILE DISCONNECT FROM SESSION PARALLEL 8。
10)检查确认备库同步完成。
11)注册备库到 Oracle Clusterware,由 Oracle Clusterware 管理备库。
3.2 ASM 双存储系统改造实施
ASM 双存储系统改造主要为创建新的磁盘组(CRS,DATA,RECO)并将原磁盘组的配置信息和数据复制到新磁盘组,实施步骤如下:
1) 在 EMC VMX 和华为 6800 上各划分相同数量及大小的新磁盘,用于创建各新磁盘组。
2)在第三方 NAS 存储上为 CRS 磁盘组创建用于仲裁的 NAS 盘,并 mount 到/fxdb_voting 目录:
dd if = /dev/zero of = /fxdbvote/quorum_vote bs =1024k count = 2048。
3)在 2 台存储新划磁盘及 NAS 盘上创建新的normal 冗余 CRS 磁盘组:
create diskgroup CRS normal redundancy;
failgroup fgemc disk'/dev/rhdiskpower180' size 20g;
failgroup fghw disk'/dev/rhdiskpower290' size 20g;
quorum failgroup fgnas disk'/fxdb_voting/quorum_vote' size 20g。
4)迁移 ocr 和 vote 盘到新建 CRS 磁盘组:$ORACLE_HOME/bin/ocrconfig - add + CRS;$ORACLE_HOME/bin/crsctl replace votedisk +CRS。
5)迁移 spfile 到 CRS 磁盘组,使用新的 spfile重启 CRS 集群,确认 CRS 集群运行正常。
6)在 2 台存储新划磁盘上创建新的 DATA 磁盘组:
create diskgroup DATA normal redundancy
failgroup fgemc disk … failgroup fghw disk …
7)拷贝参数及控制文件到新建 DATA 磁盘组,使用新的参数和控制文件启动数据库到 mount状态。
8)使用 rman 拷贝数据文件到 DATA,重建并打开数据库:
backup as copy database format '+ DATA';switch database to copy;
recover database;
alter database open resetlogs。9)修改 temp 和 redo log 文件到 DATA 磁盘组。10)在 2 台存储新划磁盘上创建新的 RECO 磁盘组,设置 recovery 区到新的 RECO 磁盘组。
4 结语
通过本次数据库高可用改造实施,消除了数据库、存储单点故障,可实现主备数据库、双存储灵活切换,减少了数据库恢复、打补丁、升级等操作对业务系统的影响,大大降低了业务中断时间,数据库从安全性、可用性方面都得到了大幅提升,能够更好地为水利信息系统的稳定运行做好支撑。
猜你喜欢
包装工程(2023年24期)2023-12-27 09:18:26
现代仪器与医疗(2021年4期)2021-11-05 08:25:06
海洋信息技术与应用(2021年1期)2021-06-11 01:20:34
电脑爱好者(2019年2期)2019-10-30 03:45:31
网络安全和信息化(2018年2期)2018-11-09 01:16:18
网络安全和信息化(2017年3期)2017-03-10 07:45:51
网络安全和信息化(2016年8期)2016-11-26 06:42:50
汽车维护与修理(2016年3期)2016-02-28 13:17:07
少先队活动(2014年6期)2015-03-18 11:19:18
河南科技(2015年7期)2015-03-11 16:23:13
