
浅谈人工智能技术在音乐创作中的应用
2020-12-28 06:49陈世哲
音乐探索 2020年1期
陈世哲

关键词:人工智能;电子音乐;算法作曲
引言
人工智能(Artificial Intelligence)并不是一个新名词。早在20 世纪50 年代,计算机领域就引起了第一次科技热潮, 中间也历经了多次低谷,但随着谷歌DeepMind 团队的AlphaGo 击败人类围棋冠军, 一个计算机学科中的人工智能技术迅速引发人类下一个科技浪潮, 并在各行业产生新的机遇。
在传统意义上, 机器的优势在于能够帮助人类完成机械而重复性的劳动, 对于创造性的工作则参与较少。但随着人工智能技术的发展,它正逐渐应用于音乐的创作、制作、分析和教育等领域。其中,利用AI 作曲或者辅助作曲变成关注度最高的应用方向之一, 很多疑问也就此产生。如AI 作曲技术能否在一定程度上代替人类作曲家? AI 作曲技术会如何影响传统作曲的思维? 这些将变成一个个有趣而又严肃的课题。
在人工智能于各行业应用的实际过程中,机器学习① 可以说是AI 最重要的子集之一,它深刻影响着AI 中的其他领域。用AI 技术自动作曲并不是一个新的课题, 相关的研究很多年前就已经开始,但是一直受技术所限。人工智能作曲的主要原理同下围棋的原理类似, 主要运用遗传算法② 、神经网络、马尔可夫链③ 和混合型算法等,利用音乐规律给计算机制定规则、建立海量数据库,继而进行深度学习① ,分析作曲规则、结构等各项信息,然后重新生成音乐。目前, 有多家国内外机构和公司开始了该领域的研究。传统的方案是完全建立在用规则构建智能系统的基础上, 而新的方案是更多地使用神经网络的方式,即使用“学习”的方式来实现。
本文主要讨论将AI 技术应用在音乐创作领域所主要使用的技术方案和策略算法, 并分析目前所碰到的问题以及与算法作曲的关系,讨论其应用方式, 以促进此技术能更好地为音乐服务。
二、相关技术手段分析
(一)神经网络(NN)
人工智能的传统方式是利用规则, 即以一种自上而下的思路来解决问题; 而神经网络(Neural Network,简称NN)则是以一种自下而上的思路来解决问题, 它的基本特点是模仿人类大脑的神经元② 之间的信息传递和模式。
神经网络有两个特性,一是每个神经元通过对应的输出函数,计算和处理来自相邻神经元的加权输入值;二是通过加权值来定义神经元之间信息传递的关系,算法在处理过程中不断地自我学习、不断地优化和调整这个加权值。此外,神经网络的处理过程需要依靠大量的数据来训练。所以,神经网络的处理过程具有非线性、分布式、并行计算、自适应和自组织的特点。
以人类学习创作音乐的过程为例, 一般要经历音乐感知(欣赏),音乐模仿写作,最后达到独立创作。在创作过程中,也包含对作曲技法、和声理论等的学习,学习者在不断地练习中,通过教师地批改引导, 不断完善自己的创作思路等。这些学习过程基本可以通过神经网络的架构模拟出来, 这也是这项技术得以应用的一个基础。
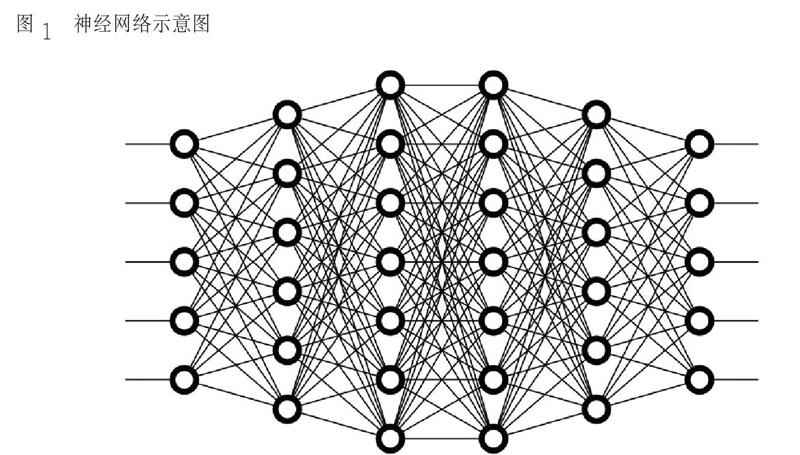
神经网络的运作过程需要有输入与输出,权重和阈值以及多层的感知器③ 的结构(图1)。神經网络可以看成是一个“黑盒子”,给定足够多的训练集,即可以在输入端给定X 后,得到预期的Y。具体来说,神经网络的运作过程需要确定输入和输出,然后找到一种或多种算法,可以从输入得到输出, 再找到一组已知答案的数据集,用来训练模型,此后,重复这个过程,输入模型,就可以得到结果,不断修正这个模型④。
音乐是时间的艺术, 许多信息是基于时间轴建立的。而神经网络实现的机制有很多种,其中能够较好地处理时间轴信息的一种技术就是递归神经网络(Recursive Neural Network,简称RNN)。RNN 是一种(前馈)神经网络,通过新增表示时间维度信息的参数以及相关机制, 使神经网络不仅可以基于当前数据而且可以基于先前数据来学习。和之前的模式不同,RNN 系统中,前一个输入和后一个输入是有关联的,RNN是一个在时间上传递的神经网络, 时间作为其深度的度量。循环网络通常具有相同的输入层和输出层, 因为循环网络预测下一个项目是以迭代的方式用作下一个输入,以便产生序列,因此RNN 是音乐创作中一项重要的实现方式。
(二)LSTM 长短期记忆单元
LSTM(全称Long Short-Term Memory)是一种特殊的RNN 结构,为RNN 的变种结构,属于反馈神经网络的范畴。LSTM 是为了克服RNN循环神经网络的梯度消失① 或爆炸而产生的神经网络,它除了继承RNN 模型的特性外还具备了自身的优点。RNN 虽然可以兼顾时间维度信息的处理,但是若时间间隔拉长后,长期保存信息并在其中开展学习得到的结果并不理想,这对于音乐信息处理是一个致命的问题, 而解决该问题的一个重要方向便是增大网络存储。因此,采用特殊隐式单元的LSTM 被首先提出,其自然行为是长期的保存输入。LSTM 主要的改变是增加了3 个门,分别是输入门、输出门和忘记门。在实践中,LSTM 被证明比传统的RNN 更加有效,它最先应用于机器翻译领域、对话生成以及编解码领域②。LSTM 能够表征更复杂的人类的逻辑发展和认知过程, 所以也是音乐生成目前最值得研究的方向。
(三)VAE
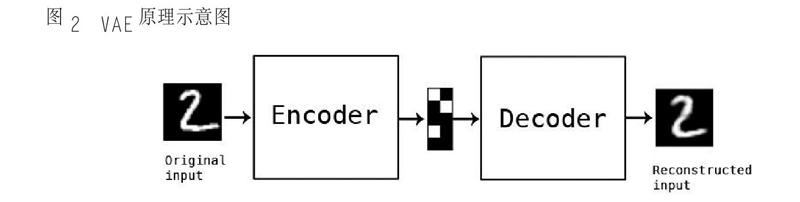
Autoencoder 是通过对特征数据进行压缩和解压来实现非监督学习的过程③ , 它本身既是一个多层神经网络, 也是一个对数据的非监督学习④ 的模型。⑤ 音乐数据没有明确的优与劣之分,所以更适合于非监督的模式。而其中的变分自动编码器(Variational Autoencoder, 简称VAE)是自动编码器的升级版本,结构与自动编码器相似,其原理是在编码过程中增加一些限制(图2)。这种处理原理同作曲的思维过程有相似之处,作曲在某种意义上是一个创作和规则并存的过程,而VAE 的机制可以很好地与之相符合。
在实践过程中,VAE 已经可以在对多声部音乐的音高动态和乐器等信息分析与生成中得到很好的应用,尤其在古典音乐和爵士乐方面。它甚至可以用爵士风格演绎莫扎特的作品,产生新的混搭方式。
变分自动编码器是目前生成内容最优的方法之一,它可以成功生成各种形式的数据,特别是在多声部音乐的生成工作过程方面。但是,当数据是多模式时,VAE 并不能提供明确的机制,它不能对离散值潜在变量进行推理, 所以这是制约其发展的一个重要因素。比如在C 大调与c 小调的处理过程中,对音阶中各种音的使用倾向是不同的, 特别是扩展到24 音及以上时,VAE 处理起来就比较困难。所以现在还有一些研究思路是设计一种VAE+LSTM 方式,这种方式可以避免部分问题。此外,在和弦问题上还可以用受限玻尔兹曼机(Restricted BoltzmannMachine,简称RBM) ① 建模等等。
三、深度学习与算法作曲的关系
算法作曲(Algorithmic Composition)是电脑作曲的一种重要方式, 也可称为自动作曲(Automatic Composition), 主要利用算法减少音乐创作时的人类干预。在传统意义上, 作曲可以从多个维度来理解,比如旋律、节奏、和声、编曲或者配器等等,虽然这些维度不能完全表征音乐,但可以作为数据化的起点,计算机可通过相应的语言和技术来表征这些,即计算机辅助作曲。但本文讨论的AI 作曲比之已有的方式更缩减了人类干预,并不属于传统意义上的计算机辅助作曲。
传统算法作曲领域的技术实现方案,除了前文提到的神经网络方式,还包括以下几种模式②。
1. 翻译模式(Translational Models)
这一类模式主要是将一些其他媒介的信息转换成音乐的相关信息,可以是因一定规则生成的,也可以是随机产生的。例如将图片的色彩和明暗对应到音色的色彩和明暗,但这种直接、简单的对应,其成果和表现形式往往过于牵强。
2. 数学模型方式(Mathematical Models)
这种方式主要通过数学模型来产生音乐,在此模型下, 很多音乐的元素是通过非确定性的方法构成的。这种随机的方式在很多传统音乐家的创作过程中都有所应用, 而这里的随机是完全基于数学方式的。在创作过程中,作曲家可以参与算法相关的参数配置。数学模型方式主要运用马尔可夫链、高斯分布③ 及分形理论④ 等实现。这种方式存在的问题是:其算法完全基于规则的设定, 对于创作音乐这项复杂的工作,公式化实现只能完成其中一个过程,完全由数学模型方式实现的创作结果很难完美。
3. 语法模式(Grammars)
这种研究方式认为音乐中存在着语法,如同语言中的语法。这种方式借鉴语言学的概念,将音乐当作一种特殊的语音对待, 其研究方向在于如何以这种思路从音乐中提炼出算法,目前有一定的研究成果, 也可以借鉴其他学科的相关成果。这种方式的问题是:第一,语法是存在层次结构的, 或者说语言的规则是相对固定的, 但音乐的表达是存在一定的即兴性或是模糊性的;第二,在语法分析和规则较多时,尤其存在模糊性的情况下,计算量要求比较高。
4. 演化模式(Evolutionary Methods)
这种方式可以通过一定的方法对信息做筛选,利用算法把好的方案筛选出来并不断优化,得到相应的结果。该方式主要利用遗传算法来模拟生物进化的过程, 因为遗传算法已被证明是解决大规模搜索空间的有效解决方式, 可以找到多个解法, 这些逻辑很符合音乐创作的某些逻辑①。这种方式的问题是:遗传算法并不能完全模拟作曲的思路, 特别是在实际操作过程中,为了节约资源通常会采用简化的方式,而一旦简化就会大大影响最终的结果。
5. 混合模式(Hybrid Systems)
混合模式就是混合以上方式甚至更多方式,一起来生成音乐。从理论上来说,这种方式有其合理性,研究十分复杂。但在实际应用中,传统基于规则和其他相关信息生成音乐的实现方法相对简单,对算法本身的要求太高,整个的运作模式并不存在“智能”和“学习”的成分②。神经网络的方式从运作模式上来说是最接近人类思维的,传统算法作曲的思路则各有各的特点,目前的各种主要技术方案还有一定的问题,所以结合规则和神经网络的方案在相当长一段时间里都是最优的一种解决方案。
四、应用实例与分析比较
人工智能应用于音乐创作时, 要确定处理的音乐信号种类的问题, 通常使用信号类信息或符号类信息。但在深度学习的过程中,使用符号信息的方式相对更加普遍。
信号类信息中的第一种是音频信号, 它可以是波形文件, 也可以是通过傅里叶变换处理后的音频频谱信息。符号类信息主要是用MIDI信息。MIDI 已经是一种成熟的并被广泛应用的格式, 主要使用音符信息中的Note On 信息和Note Off 信息,利用二者在0~127 之间的取值来表示主要的音乐信息。符号类信息另一个使用的信息就是MIDI 里面衡量时间点的Tick 值。
在深度学习过程中, 还有一种和计算机交换信息的方式,是直接用文本信息来表示音乐,当然它的规则也有很多。此外,还有以和弦、节奏或者总谱的方式用于深度学习。
就目前的研究水平来看,首先,绝大多数的研究不考虑自动作曲的音乐表情问题, 也就是说,生产出来的音乐基本是比较机械的,或者说是多种音频采样的组合。其次,由于音色采样和声音合成目前在商业应用领域发展的比较完整,并没有相关的AI 研究去关注这些方面。再次,游戏音乐因其结构完全取决于游戏场景,所以大部分研究也没有涉及到此类型。
实际上,以“AI为音乐服务”为宗旨的相关产品已经开始为音乐服务。
例如,人工智能作曲系統DeepBach 用于复调音乐特别是圣咏类作品的创作。为保证最终效果,该系统主要围绕四声部合唱来工作,并专注于巴赫的四声部合唱类作品的创作。系统采用灵活高效的采样抽样方法, 除了通过机器学习的方式生成, 使用者还可以在过程中添加音符生成,称为增加一元约束,通过节奏或相关信息对模型进行控制。这种让用户干预过程的方式, 是在音乐概率模型中经常被忽略的一种方式。与基于RNN 的模型相反,DeepBach 不从左到右进行采样。在考虑单个时间方向的情况下,DeepBach 架构会考虑时间上向前和向后的两个方向,使用两个循环网络:一个用于总结过去的信息,另一个用于汇总来自未来的信息,以及用于同时发生的音符的非递归神经网络。DeepBach 能够生成连贯的音乐短语,并提供各种旋律的重新调和,而不会出现重复。这个系统的工作困难来自于和声与旋律之间错综复杂的相互作用。此外,每个声音都有自己的“风格”和自己的连贯性。找到一种像巴赫式的和声进行,并与音乐上有趣的旋律运动相结合, 最终生成类似合唱的音乐是这个系统的目标。对此,我们通过网上调查问卷的方式,对1200 多人(包括音乐专业人士和业余人士)进行作品听辨测试,结果显示几乎所有人都难以区分这些作品是巴赫创作的还是DeepBach 创作的。谱例1 为AI生成的作品中的一个片段。
猜你喜欢
科学Fans(2019年6期)2019-07-26
时代人物(2019年4期)2019-06-14
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
演艺科技(2017年11期)2017-12-20
小康(2017年16期)2017-06-07
南风窗(2016年19期)2016-09-21
南风窗(2016年19期)2016-09-21
海外英语(2013年6期)2013-08-27
人民音乐(2009年7期)2009-09-01
