
基于LDA的舆情评论文本主题提取改进研究
2020-12-23 05:47曹锐孙美凤
软件 2020年10期
曹锐 孙美凤


摘 要: 基于LDA算法原理,提出了两种对语料库提供先验知识的改进策略。一种为对语料库中特定词性的词汇进行增删以进行相对定向的主题词的提取改进;另一种是针对舆情评论文本与新闻的相关性,引入新闻主题以期提高主题提取词汇的语义表达能力。实验证明,改进对提升舆情评论文本的主题提取准确率有明显效果。
关键词: 主题提取;LDA;舆情事件评论分析;无监督学习
中图分类号: TP391 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.10.017
本文著录格式:曹锐,孙美凤. 基于LDA的舆情评论文本主题提取改进研究[J]. 软件,2020,41(10):7075+85
【Abstract】: Based on the principle of LDA algorithm, two improved strategies for providing prior knowledge to the corpus are proposed. One is to add and delete specific part-of-speech vocabularies in the corpus to improve the extraction of relative targeted topic words; the other is to introduce the topic of news in order to improve the semantic expression ability of topic-extracted vocabularies based on the relevance of public opinion comment texts and news. Experiments show that the improved LDA algorithm has a significant effect on improving the accuracy of topic extraction of public opinion review text.
【Key words】: Topic extraction; Latent Dirichlet Allocation; Public opinion analysis; Unsupervised learning
0 引言
近年来,Web2.0的普及带动了互联网信息量的剧增和网络交互性的空前提升,网络舆情的分析顯得愈加重要,网络舆情是社会舆情在网络空间的映射[1]。针对网络舆情主题的稀有性特点——形成的热点主题只来自少量信息[2],为了快速、准确地从网络媒体带来的大量舆情新闻及对应评论信息中提取热点主题,需要将主题提取的工作由人工转化为半自动甚至自动。
LDA(Latent Dirichlet Allocation)[3]是基于BOW模型的一种自动主题提取算法。LDA因为有效训练不需要任何带标签的训练集的优点得到广泛应用[4-7]。
但作为一个无监督方法,LDA在实际应用中存在问题,主要有:
(1)每次主题划分会遗漏部分现实存在的主题[8]。这会极大影响测试集文本包括新文本划分到该主题的准确度。
(2)代表主题的关键词集合表义不明确[9]。这会使得人为难以判断主题提取效果是否达到理想的训练效果,也会影响测试集文本包括新文本划分为该主题的准确度。
针对上述问题,国内外研究者提出了多种改进方法,主要包含两个方向:一种是以改进LDA算法本身的不足为研究核心[10-12],一种是通过提供语料集更多先验知识以影响LDA算法结果。本文工作遵循第二种思路。
通过提供语料集更多先验知识的研究有:Zhai[13]等提出通过事先整理的must-link约束集和cannot-link约束集作为先验知识来在LDA主题划分过程中更好地聚集同类词汇和分离异类词汇。彭云[9]等在文中对must-link和cannot-link进行了详细的功能测试,发现对准确率有提升作用的主要是must-link约束集。Xu[14]等提出的SW-LDA通过人工构建敏感词汇集和加入Word2vec技术,利用以上增加的先验知识有效提高了敏感信息的主题识别量和质量。Li[15]等通过将WordNet的内容和规则引入LDA作为先验知识,提出了一种提取动态变化的主题的方法,并通过六次实验证明了算法可行性。专门针对舆情文本分析方面,刘玉文[4]等主要通过引入报道文档发布的时间信息作为先验知识使原始LDA模型识别新闻焦点的水平得到提升。
本文研究对象为舆情评论文本,为了提高LDA算法主题划分的全面性和主题表义的准确性,本文提出了以下改进:
(1)基于词性对主题表达的作用的先验知识,对语料库中特定词性的词汇进行针对性的增减,使LDA算法结果能够纳入出现频率较低的局部主题;
(2)基于舆情评论文本中的主题很大程度受引发评论的新闻中主题影响的特点,利用新闻数据中主题改进评论文本的主题提取。
1 LDA简介
1.1 LDA模型
LDA是一个基于doc-topic-word的三层贝叶斯模型,其数学推导核心是利用Dirichlet分布和Multinomial分布共轭的性质:
即当数据知识符合Multinomial分布时,参数的先验分布和后验分布都保持Dirichlet分布。
按照LDA模型,文档生成过程如图1所示。
第一步:从到再到最后对应到第m篇文档的第n个词的过程表示在有先验的文档-主题分布的情况下,首先计算出对应文档的实际文档-主题分布,再由的结果对每个词计算其可能的主题,因此第m篇文档的第n个词的主题即是;
第二步:从到再对应到第m篇文档的第n个词的过程表示在有先验的主题-词汇分布的情况下,首先计算出对应主题的实际主题-词汇分布,再由中选取主题的情况下即可对应到具体的第m篇文档的第n个词汇。
1.2 Gibbs采样法
吉布斯采样(Gibbs Sampling)是训练LDA模型的方式,它是一种马尔科夫链蒙特卡洛方法(MCMC),使其转移矩阵收敛,即可得其对应的样本。
吉布斯采样对于LDA的训练过程大致如下:
(1)首先随机赋予每篇文档每个词汇以主题编号;
(2)接着统计每个主题下词汇的数量和每个文档中相应主题的词汇数量;
(3)对每单个词汇,排除当前词汇的主题分布,依据其他所有词汇的主题分布计算当前词汇分配到每个主题的概率,按照概率分布重新为当前词汇赋予一个主题;
(4)重复上述过程,直到每个文档和每个主题、每个主题和每个词汇间的分布收敛。
1.3 LDA训练
LDA模型训练采样过程所需条件概率公式为[16]:
它正比于和两个Dirichlet后验分布的参数估计的乘积。
相应地,LDA模型的训练过程如下:
(1)对文档集合中的每篇文档,进行分词,并过滤掉无意义词,得到以词汇为单位的语料集合;
(2)随机赋予每篇文档每个词汇以主题编号;
(3)依据Gibbs采样法,对每单个词汇,排除当前词汇的主题,依据从剩余所有词汇及主题按公式(2)计算得到当前词汇分配到每个主题的概率分布 ,并据此重新为当前词汇赋予一个主题;
(4)重复上述过程,直到每个文档和每个主题、每个主题和每个词汇间的分布收敛。
最后,通常训练结果会取Gibbs采样多次迭代后的结果的平均值作为最终的参数估计,使模型质量更好。
1.4 LDA主题推断
LDA主题推断(LDA Inference)指利用训练生成的LDA模型,推断新文档的主题分布的过程。
对新文档的处理,就是按照类似上述LDA模型的训练过程,加入新文档后,重新计算该文档的主题分布。
以下是LDA主题推断的过程描述:
(1)通过随机初始化,对当前文档的每个词随机赋予一个主题编号;
(2)重新扫描当前文档,按照Gibbs采样的公式,对每个词重新采样主题;
(3)重复上述过程直至Gibbs采样收敛;
(4)统计文档中的主题分布,该分布就是。
2 主题提取改进策略
主题提取改进策略分为两部分:基于词性的改进策略和基于关联新闻挖掘先验主题的改进策略。
基于词性的改进策略利用LDA在主题提取时依赖词频的特点,通过增删的方式改进不同词性的词在词频分布上的不平衡,从而有效的解决LDA主题提取时会遗漏低频主题的问题。但基于词性的改进策略在有效地挖掘低频主题的同时也会影响其他主题的稳定性,会提高获取期望主题提取实验结果的难度,因此考虑利用LDA在主题提取时可以加入先验主题的特点,在实验中添加先验主题的方式稳定部分主题,再采用基于词性的方法挖掘剩余需要的主题,可以取得更高效的实验成果。
先验主题为了稳定提取评论中的部分主题而存在,因而提取的主要要求是:所有先验主题需从不同源语料中提取,但又需与评论语料库中主题内容和含义保持基本一致,不可出現评论语料库中不存在的主题。
通常,具体舆情事件中评论的主题来自两大类:一是随舆情新闻带来的主题,二是评论自身衍生出的主题。第一类主题显然更符合先验主题提取的要求。由此考虑适宜添加的先验主题可由关联新闻获得。对应先验主题的要求,选取新闻的要求是:与评论语料关联度高,内容简洁且不超过评论所涉及的言论范围。
2.1 基于词性的改进策略
从LDA的原理上分析,构成语料库的单词的出现频率会在很大程度影响它被选为主题词的概率,因此往往会出现与主题无关的高频词被提取为主题关键词和与主题有关的低频词被舍弃的情况,该情况会导致不能实现较好的主题划分。本文采用向语料库加入先验知识的方法进行改进,具体地说,就是提高有效主题词汇的频率。
情感词对舆情分析的重要性不言而喻。基于对如台湾大学NTUSD等情感词典的观察,以及刘德喜等[17]的研究,确定中文环境的候选情感词为形容词、动词和普通名词。为了确保有效情感词不被高频实体名词挤掉,同时要人工降低实体名词的频率。依据整体语料库的词性分布,提高的顺序由先到后是:形容词、动词和普通名词。改进由多次基于词性的统一增删完成,每次增删的次数为1。
改进策略对文档进行预期修改是通过改变当前文档中各词性的关键词、关键词词频及其权重从而改变主题提取的结果,但对几乎所有文档而言,在增删达到一定程度后,其改变程度会趋于稳定,主要原因有两种:(1)原文档被增删的词覆盖达到与原文档的差异最大化;(2)因为需要增加的词性词占原文档总数比例过高,最终等于回到原文档的分布。
本文选取TF-IDF+Simhash方法的结果作为改进策略与原文档差异大小的度量值。TF-IDF是最常用的计算文档关键词及其权重的方法,Simhash算法是常用的计算文本相似度的算法[18],它将两篇文档降维成64位编码,再计算它们的汉明距离值并作为结果返回。
本文记单篇原文档和改进后的文档经过TF-IDF+ Simhash方法返回的汉明距离值为,含义为原文档与改进后文档的关键词差异大小。以为度量值时,文档趋于稳定的两种情况分别对应为:(1)值增加到稳定在某个最大值;(2)值先增后减,最终回到最小值甚至为0。
从首次增删开始到趋于稳定的过程中,每篇文档会对应出现一组的值,策略选择优化的方法是:在某次优化中,可以对每篇文档取排名第x名的值来控制预期与原语料库的改变程度。对所有文档计算语料库的平均值,值越高则主题提取结果与原始语料库差异越大,依此多次实验,以值为度量找到最佳的改进方案。
改进策略的算法伪代码如下:
算法1:基于词性的词频修改策略算法
Algorithm 1: Word frequency modification strategy algorithm based on part of speech
输入:预处理后的语料库,预期的值排名,词性增删先后顺序
输出:经过改进策略增删的新语料库,
读取待处理词性集合中的增删先后顺序;
Begin For遍历每篇文档;
初始化记录文档词汇集中每个词汇的词性;并依据词性建立子词汇集;
While循环:
依序对删除列表集中每种词性词汇减1,对增加列表中每种词性词汇加1,记所有词性增删数量各改变一次为一轮循环,
While终止条件:本轮循环所有值相较于上轮循环所有值的两两差值在3以内;
按照读取的增删数量改进原文档,并加入新语料库;
End For
返回最终新语料库;
返回全文的距离平均值;
2.2 基于關联新闻挖掘先验主题的改进策略
由先验主题的提取要求,可得从原始新闻文库到取得先验主题的核心步骤是:(1)优选与评论关联度高的重点新闻,并形成摘要;(2)将所有新闻摘要作为语料库进行一次LDA主题提取,优选主题提取结果组成先验主题集参与后续评论语料库的主题提取实验。
步骤(1)主要考虑如下两个问题:一是优选新闻。优选新闻的标准是某条新闻评论数占评论集评论总数的比例,若高于某个预设比例,则认定关联度高。预设比例一般在1%-10%之间最好,可以兼顾对新闻语料库的代表性和完整性。二是形成摘要。目前已有许多方法,其类别主要分为从原文抽取型和概括原文重新生成型。前者有:如计算句相似度优选文中几句主题句作为摘要[19],或采用关键词聚类将关键词集作为摘要[20]等等。后者有近年一些基于深度学习的模型可以概括全文内容再生成一句话摘要[21]等等。本文不对摘要形成方法做重点研究,本文的摘要形成方法是抽取型,抽取内容来自新闻书写格式规范——第一段是新闻的导语,起概括全文的作用。因此本文形成摘要的方法是直接将新闻的第一段作为摘要。
步骤(2)将新闻摘要进行LDA主题提取的方式与评论完全相同——先进行预处理后进行实验,再优选每个主题的关键词,以期在对LDA做最大程度定向处理的同时最小化算法干预,发挥LDA作为无监督算法的本来优势。
单个先验主题的最终形式是:
其中表示先验主题编号,表示对应主题关键词,表示当前主题词的所占权重。
对先验主题集优选主题关键词的方法是:先对评论集提取关键词集,再对由关联新闻得到的每个主题的每个主题词判断是否命中评论集的关键词集,若命中则优选成功。最终每个主题所有合格的主题词及对应权重组成了先验主题集。
从新闻提取舆情先验主题的算法伪代码如下:
算法2:关联新闻形成先验主题
Algorithm 2: Related News forming a priori topic
输入:携带评论数的关联新闻,优选比例
输出:先验主题集
从输入中读取优选比例;
Begin For遍历被选出的关联新闻
若当前新闻评论占比超过;
保留当前新闻,并保留新闻前两段为新闻摘要;
End For
人工确定新闻主题数;
预处理所有合格关联新闻的摘要形成语料库,对语料库进行LDA主题提取;
对评论集进行TF-IDF提取关键词集,对每个主题保留命中关键词集的主题关键词;
返回所有主题及对应关键词组成的先验主题集;
3 实验与分析
3.1 数据集与文本预处理
数据集的事件来源是2017年6月16日,中方在洞朗地区施工时,遭到印军越线阻拦,印方公然派军队越过双方承认的边界线进入中国境内,严重损害中国领土主权。期间中印双方多次交涉无果,在国内和国际上都引发了广泛热议。
围绕“中印边境事件”,对2017年6月18日到2017年8月28日期间,出现在互联网上的评论(主要是今日头条)进行采集得到短文本约13255条。对其分词及进行停用词删除等预处理后生成数据集。
3.2 实验结果与分析
3.2.1 测试集主题划分
通过人工分析,将以上舆情评论文本分为以下大致主题:对于中方是否应当通过战争解决问题的评论(T1)、对于印方嚣张气焰的评论(T2)、对于中国国内其他问题的评论(T3)、对于尼泊尔和不丹等周边国家表态的评论(T4)、对于美国插手该事件的评论(T5)、对日本插手该事件的评论(T6)。
通过人工打标测试集记录共1002条,其中T1有290条,T2有136条,T3有107条,T4有48条,T5有135条,T6有286条。
测试集人工划分主题的大致方法是:寻找每个主题的评价主体和客体内容。通常评价主体由对事件本身的整理而来,对应客体内容由对测试集的观察而来,大致规则为:
若某评论文本中同时出现评价主体和客体内容(评价主体对应词汇较为确定,客体内容对应词汇相对更多),则属于该主题。如“印度站在分水岭,实际侵犯了两个国家的领土!……”中有明显的评价主体“印度”和客体内容“侵犯”、“领土”。以上划分方法是依照对舆情事件的实际解读划分的评价对象的全体。
人工划分的主题数量只影响对LDA训练时初始主题数的设置,但选择的最终模型主题数是否等于初始主题是不确定的,可以一对一,也可以一对多,只要形成独立划分即可。但如果选取的训练主题数过高,则文本划分过于分散,不利于后续LDA主题推断效果。
3.2.2 标准LDA实验结果
下图展示了直接进行语料库预处理后的LDA算法结果,可以看见,上述对于topic 3和topic 4的主题划分没有出现。
通过LDA主题推断可以依据模型计算出每篇文档的主题倾向进而算出每个主题划分的准确率,但对每次训练的模型计算测试集的准确率步骤较为繁琐,又因LDA在训练结束后提供由高到低的主题词序列预览,因此可以先由人工观察对当前训练模型的质量做一次基本判断。
观察判断的大致方法是在权重约前10位的词中寻找每个主题的评价主体和客体内容。观察判断规则为:
规则一:若评价主体不存在,则主题高概率不出现。
规则二:若某主题中同时出现评价主体和客体内容,则主题高概率出现。
对于任意主题,符合规则二即认定本次实验该主题划分成功,符合规则一即认定本次实验该主题划分失败,对规则一和规则二都不符合的主题本次实验不计数。
具体地,如上图实验观察主题4关于“尼泊尔”等周边国家,不存在主体词,因此划分失败。
最后,观察判断某主题划分的稳定性的方法是:若某主题在多次实验中(至少3次)仍基本符合规则二,则该主题为稳定的高频主题;若某主题在多次实验中仍基本符合规则一,则该主题为未被成功划分的低频主题。
按照6个主题划分经过多次实验后,依据上述规则从观察上认定使用标准LDA算法的主题划分结果只能尽量包含六个主题中的四个,而遗漏的两个主题也是原打标集合中最少的两个部分,因此,LDA算法确实侧重于总体的主题而容易遗漏局部主题。
依照上述规则,同样测试主题数为topic=12,20等参数值时主题划分质量,结果如图2所示,图中x轴是训练选择的主题数,y轴是稳定提取的主题数,没有出现高于划分出4个稳定高频主题的结果,为简化工作量,方便后续主题改进时的主题划分,依照满足要求的最小主题数即topic=6保存主题模型并对测试集进行LDA主题推断。
下表展示了对于测试集数据进行主题分类的准确率P、覆盖率R和标准值F1,表中“—”表示在实验结果中该主题划分不成功。
3.2.3 基于词性的改进实验
本文得到语料库的范围:取最小值等于全文不变时得出,为0;最大值为取全部最大值时得出,约为21。实际实验中,每篇文档的稳定通过几层循环即可达成。另外,选取的排名越高,过拟合的情况也越明显,因此不适宜取最高值,会明显降低在测试集的准确率。经过LDA主题提取结果检验,最终选取的值排名为由高到低的第四名,得到的值为14.48。
在所有词性的词汇集中,\nr的词性的词几乎是可以确定的,主要是“中国”、“印度”、“日本”等国名和一些地区词,该词性词出现概率过高,需要降低频次,但本文考虑了保留至少该词汇至少存在一次的做法,该做法又等同于部分提高了“尼泊尔”等次高频词的频度,使其可更恰当地出现在主题提取结果中。其他词性的词进行统一增加,再通过调参数和多次训练寻找最佳结果。对于单篇文档,在结束所有词性处理后,将修改后的文档返回,并在每个文档末尾添加被增加的词。
采用通用改进策略后,该舆情评论可以被大致完整划分为六个主题,但表义仍不够明确,实验结果也不够稳定,因此需要先验主题确定部分主题来使实验结果更好、更稳定。
3.2.4 基于关联新闻报道主题的改进实验
本文舆情事件对应的实际主题不多,因此本文选取的新闻评论占比为1%。
由于关联度高的新闻较少,可以人工阅读这些新闻摘要,确定主题数,由于新闻报道的主题类别较为明显,一般取一对一的主题数即可成功划分。
加入的新闻先验主题示例如下。
新闻先验知识可以对实验中固定高频LDA主题的提取有较为明显的效果,但其仍然依照概率形式参与采样,不会因为相似的形式和高初始权重而完全覆盖评论语料库的主题关键词。
3.2.5 主题准确率计算实验结果
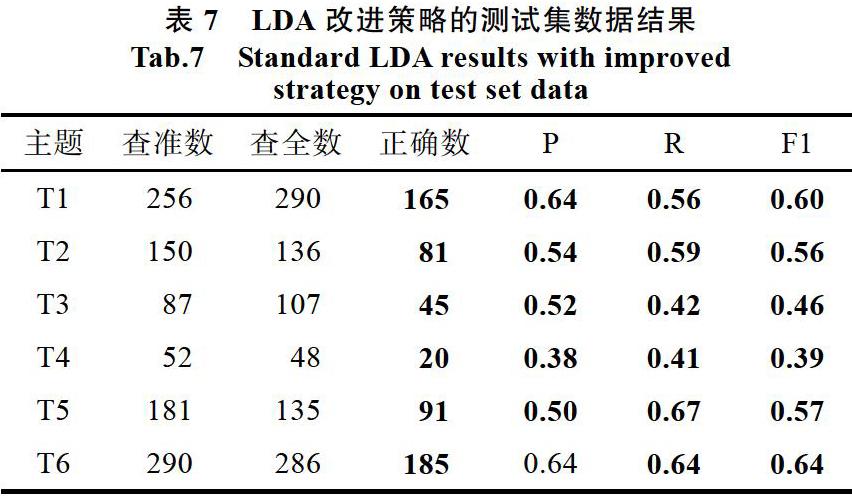
同时采用两种改进策略后,该舆情评论可以被大致完整划分为六个主题。结果如下表所示:
同时使用两种改进策略对于数据的准确率P、覆盖率R和标准值F1如下表。
从上表和前表可以看出,同时使用两种改进策略后的LDA算法,几乎在所有主题的分类中都高于标准LDA算法的效果。证明了提出的改进策略的良好效果。
整体查准率与查全率偏低与语义理解有关:当前分词算法和LDA都不是利用语义理解完成划分的,而舆情文本语义结构十分复杂,二者间出现了明显偏差,如分词后的许多语句人工已无法理解语义。
3.2.6 对比实验结果
本文的对比实验选用标准LDA算法和sentence- LDA算法(简称senLDA)[11],实际实验设计为对标准LDA、使用改进策略的LDA、标准sentence-LDA、和使用改进策略的sentence-LDA四种算法在每个有效主题上得到的F1值作为参照。
由图表明,标准sentence-LDA成功劃分了6个主题,且每个主题的F1值与使用改进策略的LDA大致相当,而sentence-LDA算法在使用改进策略后在成功划分出6个主题的同时取得了最佳的F1值。
4 结束语
在将舆情评论类数据直接输入LDA算法进行分析时,往往会出现与主题无关的高频词被提取为主题关键词和与主题有关的低频词被舍弃的情况,该情况会一方面会导致不能实现较好的主题划分,另一方面会导致被划分的主题关键词不能较好表达语义。针对以上问题,提出了通过加入先验知识,修改语料库分布的方法,改善了处理效果。
本文采用基于词频统一处理,并辅以相关新闻作为舆情事件评论的先验知识集的方法进行了实验,实验结果表明,采用该方法后的LDA主题关键词提取结果,在主题划分和主题词表义方面都有了明显提升。
后续工作中,希望利用更多的词性在语料库中分布或在日常语言表达中的规律进行更多针对性的修改,利用有效的规则筛选修改的词,以期通过更精确的先验知识使主题提取结果产生更有效、更穩定的改变。
参考文献
[1]王书梦, 吴晓松. 大数据环境下基于MapReduce的网络舆情热点发现[J]. 软件, 2015, 36(7): 108-113.
[2]信怀义. 基于异质图随机游走的网络话题优化策略与仿真模型[J]. 软件, 2016, 37(1): 105-109.
[3]Blei, David M, et al. “Latent Dirichlet Allocation.” Journal of Machine Learning Research 3(2003): 993-1022.
[4]刘玉文, 吴宣够, 郭强. 网络热点新闻焦点识别与演化跟踪[J]. 小型微型计算机系统, 2017, 38(4): 738-743.
[5]W Zheng, B Ge and C Wang, “Building a TIN-LDA Model for Mining Microblog Users Interest,” in IEEE Access, vol. 7, pp. 21795-21806, 2019.doi: 10.1109/ACCESS.2019.2897910.
[6]F. Gurcan and N. E. Cagiltay, “Big Data Software Engineering: Analysis of Knowledge Domains and Skill Sets Using LDA-Based Topic Modeling,” in IEEE Access, vol. 7, pp. 82541-82552, 2019.
[7]D. Puschmann, P. Barnaghi and R. Tafazolli, “Using LDA to Uncover the Underlying Structures and Relations in Smart City Data Streams,” in IEEE Systems Journal, vol. 12, no. 2, pp. 1755-1766, June 2018.
[8]Daniel Maier, A. Waldherr, P. Miltner, G. Wiedemann, A. Niekler, A. Keinert, B. Pfetsch, G. Heyer, U. Reber, T. Hussler, H. Schmid-Petri & S. Adam (2018) Applying LDA Topic Modeling in Communication Research: Toward a Valid and Reliable Methodology, Communication Methods and Measures, 12:2-3, 93-118, DOI: 10.1080/19312458.2018.1430754.
[9]彭云, 万常选, 江腾蛟, 等. 基于语义约束LDA的商品特征和情感词提取[J]. 软件学报, 2017, 28(3): 676-693.
[10]Mei Q, Ling X, Wondra M, et al. Topic sentiment mixture: modeling facets and opinions in weblogs[C]. International Conference on World Wide Web, 2007: 171-180.
[11]Balikas G, Amini M R, Clausel M. On a Topic Model for Sentences[C]//Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. ACM, 2016: 921-924.
[12]R Das, M Zaheer, C Dyer. “Gaussian lda for topic models with word embeddings,” in Proc. 53rd Annu. Meeting Assoc. Comput. Linguistics, vol. 1, 2015, pp. 795-804.
[13]Zhai Z, Liu B, Xu H, et al. Constrained LDA for Grouping Product Features in Opinion Mining[C]//Advances in Knowledge Discovery & Data Mining-pacific-asia Conference. DBLP, 2011.
[14]G Xu, X Wu, H Yao, et al. “Research on Topic Recognition of Network Sensitive Information Based on SW-LDA Model,” in IEEE Access, vol. 7, pp. 21527-21538, 2019.
[15]C Li, S Feng, Q Zeng, et al. “Mining Dynamics of Research Topics Based on the Combined LDA and WordNet,” in IEEE Access, vol. 7, pp. 6386-6399, 2019.
[16]Heinrich, Gregor. (2005). Parameter Estimation for Text Analysis.
[17]刘德喜, 聂建云, 万常选, 等. 基于分类的微博新情感词抽取方法和特征分析[J]. 计算机学报, 2018, 41(7): 1574-1597.
[18]陈磊磊. 不同距离测度的K-Means文本聚类研究[J]. 软件,2015, 36(1): 56-61.
[19]赵旭剑, 张立, 李波, 等. 网络新闻话题演化模式挖掘[J]. 软件, 2015, 36(6): 1-6.
[20]赵旭剑, 邓思远, 李波, 等. 互联网新闻话题特征选择与构建[J]. 软件, 2015, 36(7): 17-20.
[21]Radford A, Wu J, Child R, et al. & Sutskever, I. (2019). Language Models are Unsupervised Multitask Learners.
