
基于生成对抗网络的人脸超分辨率重建算法
2020-12-18 03:21:22王先傲林乐平欧阳宁
桂林电子科技大学学报 2020年1期
王先傲,林乐平,欧阳宁
(桂林电子科技大学 信息与通信学院,广西 桂林 541004)
人脸超分辨率重建是从低分辨率(low resolution,简称LR)图像中恢复高分辨率(high resolution,简称HR)图像,因为一张低分辨率图像对应的高分辨率图像拥有较多的可能性,所以人脸重建的过程是一个不适定问题。目前大多数解决方法是通过卷积神经网络(convolutional neural network,简称CNN)建立从LR图像到HR图像的映射关系,以峰值信噪比(peak signal to noise ratio,简称PSNR)作为图像重建质量的评价标准,其数值越高就表明重建效果越好。
LR图像由于缺乏高频信息,丢失了图像的纹理细节信息,因此重建图像的高频信息至关重要。Dong等[1]首次将稀疏表示与CNN相结合,设计了一个3层的卷积神经网络,重建图像的PSNR数值超过了传统算法。以MSE为目标函数优化模型参数,可得到PSNR更高的超分辨率图像,但细节并不一定更加突出。针对此问题,Ledig等[2]提出了一种基于生成对抗网络(generative adversarial networks,简称GAN)[3]与感知损失[4]的图像超分辨率重建方法,其能够得到细节更突出的人脸图像。Huang等[5]针对极低分辨率的人脸图像,提出一种结合哈尔小波的低分辨率人脸重建算法,通过CNN预测对应的小波系数,以小波逆变换重构出超分辨率图像,重建质量得到较大提高。上述大多数算法以均方误差(mean squared error,简称MSE)作为损失函数进行优化,虽然能够得到PSNR值较高的重建图像,但生成图像过于平滑。
为了得到细节丰富的高分辨率人脸图像,提出一种基于生成对抗网络的人脸超分辨率重建算法。其中生成模型与对抗模型均采用了利于图像重建的网络结构,算法优点如下:
1)生成模型由2条支路构成,并主要对图像的高频信息进行重建,由深度残差网络构成的判别模型对真假图像进行判别,最终可得到更加自然真实的超分辨率图像。
2)通过融合对抗损失WGAN-GP[6]与MSE损失对网络参数进行联合优化,并以对抗损失为主导,能够赋予重建图像更多细节,MSE用以保证图像重建前后身份的一致性,最终网络可迅速收敛。
1 基于生成对抗网络的人脸重建算法设计
1.1 生成器
大多数基于CNN的人脸重建算法可分为3步:1)HR图像通过插值下采样,得到LR图像作为模型输入;2)通过网络得到放大后的超分辨率(super resolution,简称SR)图像;3)以HR图像为标签,通过损失函数的反向传播优化网络参数。
受文献[7-9]提出方法的启发,设计了一种基于生成对抗网络的重建算法来解决人脸超分辨率问题。模型结构如图1所示。

图1 生成对抗网络结构图
图1(a)为生成器结构,图1(b)为判别器结构,Real表示真实图像,Fake表示生成器生成的图像。其中生成器由2条支路组成,分别对应图像的高频分量与低频分量。由插值上采样层组成的低频支路对应图像的轮廓信息,由深度残差网络组成的高频支路则对应人脸图像的细节信息。判别器的作用是对真假图像进行区分,网络训练的过程就是判别器与生成器不断博弈的过程,当最终生成器生成的图像能够骗过判别器时,模型即达到了收敛,生成器的设计思路如图1所示。
一幅高分辨率人脸图像由高频信息与低频信息组成,
IHR=Ilf+Ihf。
(1)
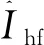
(2)
(3)
(4)

1.2 判别器
为了能够得到更加真实的超分辨率图像,提供了一个由深度残差网络组成的判别器对生成图像与真实图像进行区分,如图1(b)所示。判别网络由14个卷积层组成,卷积通道由64递增至512。生成器与判别器的卷积核大小均为3×3,小尺寸的卷积核能够减少参数,并且可以通过堆叠多个3×3卷积核达到相同的感受野,同时提高非线性映射能力。采用的残差模块结构如图2所示。

图2 残差模块结构
图2(a)为生成器所用残差单元,图2(b)为判别器所采用的残差单元。通过借鉴文献[8-9]中的网络设计思想,生成器与判别器中采用了更适用于超分辨率重建的残差模块,卷积核尺寸均为3×3,padding为1,卷积前后特征图大小不变。生成器中采用双线性插值进行上采样操作,而判别器中采用池化层对特征图进行下采样。残差单元以及批归一化层(batch normalization,简称BN)[10]的加入可以一定程度上缓解深度网络带来的梯度消失与梯度爆炸问题,加速网络收敛。
1.3 损失函数
RPSN作为图像质量评价指标,其定义为
(5)
由式(5)可看出,当2幅图像之间的EMS越小时,对应的RPSN值越高。因此,以EMS作为损失函数可以带来较高的RPSN值。与此同时,EMS越小,说明2幅图像之间的像素平均值越接近,容易导致生成图像过于平滑。
针对上述原因,将WGAN-GP[6]损失与MSE加权融合作为网络的目标函数,并以对抗损失为主导,MSE的加入是为了保证重建前后身份的一致性,优化方法为
l=αlWGAN-GP+lMSE。
(6)
其中:lMSE为均方误差损失;α为权重系数,用来平衡对抗损失与重建损失,lWGAN-GP是一种改进的GAN损失。
(7)
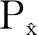
(8)
其中:W、H为图像的宽度和高度;ISR、IHR分别为生成图像和目标图像;i,j为像素所在位置的索引。通过优化lMSE可使得生成图像的像素点均值逐渐向目标图像逼近。
2 实验结果与分析
本实验基于Ubuntu14.04 操作系统,使用GTX1080Ti 显卡加速,pytorch深度学习框架实现模型搭建。
2.1 实验数据与预处理
采用公开的人脸数据库CelebA[11]、LS3D[12]中的图像作为高分辨率人脸数据,CelebA数据集中大部分为正面人脸,LS3D则含有多种姿态的人脸图像,共选取30 000人脸作为高分辨率人脸数据库。
在保证训练与测试数据不重复的前提下,从CelebA中选取3 000张高分辨率人脸进行重建测试。对所有训练和测试样本都做相同的预处理,高分辨率人脸大小为64×64,通过下采样得到16×16的低分辨率人脸图像。
2.2 实验参数设置
在本实验中,平衡系数α=0.05,λ=10。生成器学习速率为0.000 1,判别器学习率为0.000 4,进行交替迭代训练。权重衰减设为0.000 5,批次大小为64,采用Adam[13](β1=0.9,β2=0.999)算法进行随机梯度优化,共迭代200个周期。
2.3 实验结果分析
实验测试结果分为2个方面:1)针对CelebA数据集中的3 000张高分辨率人脸图像,以不同算法进行重建结果对比,以人的视觉主观判断为标准;2)重建图像的FID(fréchet inception distance)[14]分数和RPSN数值对比。
2.3.1 重建结果对比
分别与双三次插值算法(Bicubic)、Wavelet-SRNet[5]、SRGAN[2]进行对比,放大4倍的重建结果如图3所示。其中图3(a)为16×16的低分辨率图像,图3(e)为本算法得到的重建结果,图3(f)为64×64的目标图像。从图3可看出,Wavelet-SRNet与SRGAN算法所得到的图像相较于原图更为平滑,而本方法能够生成纹理细节丰富的图像,在视觉上与原图更加接近。SRGAN与本方法都是基于GAN进行超分辨率人脸重建,不同的是本方法充分利用了GAN的生成能力,而SRGAN仍是以MSE为主导,因而本方法可得到五官更加清晰的人脸图像,但是某些纹理与原图存在一些差别,这是本方法仍然需要改进的地方。

图3 重建结果对比
2.3.2 重建图像的RPSN与FID对比
分别对重建图像的RPSN值与FID分数进行对比,如表1所示。FID[14]是图像数据之间的相似性度量,用于评估重建图像的质量,计算重建图像与目标图像之间的FID分数,其数值越小,表明跟实际图像越接近。

表1 重建图像的RPSN与FID分数对比
Wavelet-SRNet与SRGAN的RPSN值相对更高,而本算法可以达到更低的FID分数,表明重建结果与实际图像更加接近。由于网络参数优化过程中,并未主要针对MSE进行训练,而是更加注重利用生成器的生成能力赋予图像更多纹理,导致RPSN值并不突出。
3 结束语
为了得到纹理丰富的高分辨率图像,提出了一种基于生成对抗网络的人脸重建算法。算法采用了更适用于图像重建的残差单元模块,优化过程中以对抗损失为主导,可生成与目标图像更相似的超分辨率人脸图像。基于CelebA数据集对重建结果进行对比,实验结果表明,本算法能够得到细节丰富的人脸图像,且FID分数高于其他人脸重建算法。
猜你喜欢
红外技术(2022年11期)2022-11-25 08:12:22
电子产品世界(2022年9期)2022-05-30 20:41:07
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
雷达学报(2020年3期)2020-07-13 02:27:16
动漫星空(2018年9期)2018-10-26 01:17:14
艺术科技(2018年2期)2018-07-23 06:35:17
太空探索(2015年8期)2015-07-18 11:04:44
浙江大学学报(工学版)(2015年1期)2015-03-01 01:17:19
发明与创新(2015年33期)2015-02-27 10:40:09
航天返回与遥感(2014年4期)2014-07-31 17:47:42
