
基于代码碎片化的软件保护技术
2020-12-18 00:27:58郭京城舒辉熊小兵康绯
网络与信息安全学报 2020年6期
郭京城,舒辉,熊小兵,康绯
基于代码碎片化的软件保护技术
郭京城,舒辉,熊小兵,康绯
(信息工程大学,河南 郑州 450001)
针对当前软件保护技术存在的不足,提出一种代码碎片化技术,该技术是一种以函数为单元,对函数进行代码shell化、内存布局随机化、执行动态链接化的新型软件保护技术,代码shell化实现代码碎片的位置无关变形,内存布局随机化实现代码碎片的随机内存加载,动态链接化实现对代码碎片的动态执行,通过上述3个环节实现对程序的碎片化处理。实验表明,代码碎片化技术不仅能实现程序执行过程中函数碎片内存位置的随机化,还能实现函数碎片的动态链接执行,增加程序静态逆向分析和动态逆向调试的难度,提高程序的抗逆向分析能力。
代码碎片化;软件保护;分离;动态链接
1 引言
软件保护问题一直是计算机安全领域的重要研究课题,虽然当前的软件保护手段能够在一定程度上增加软件被恶意修改和逆向分析的难度,但攻击方可以实现对程序的结构特征进行静态分析[1-2],也可以反复地对代码进行逐步运行、调试、反汇编、反编译,能够获取软件在内存中的数据、执行期间的中间值,通过连续获取系统的内存镜像,进行前后镜像之间的对比分析,可以获取程序的具体行为[3]的动态分析,因此,如何有效地实现对应用程序的防破解、防盗版是一个亟待解决的问题。当前有很多软件保护技术,代码加壳[4]是通过对原程序的压缩加密实现对可执行文件的保护手段,代码虚拟化[5]是将本地指令转换成自定义的虚拟指令,并通过虚拟解释器解释执行虚拟指令,实现原始程序的功能,代码混淆[6-9]分为外形混淆、控制混淆、数据混淆和预防混淆[10-12]。在源代码基础上实现若干种控制混淆转换与数据混淆转换,通过适当插入垃圾代码和不透明谓词实现的改进型控制流混淆算法[13],通过增加冗余基本块的数量和随机下标生成实现改进型的二进制程序控制流扁平化[14],是常见的代码混淆手段。内存布局随机化通过不断改变进程内存布局,实现进程攻击面的随机性变换,从而消除了攻击者的不对称优势,增加了攻击者的攻击难度[15-16]。这些软件保护技术能够实现对代码的保护,很大程度上增加逆向攻击者对程序静态分析的难度,但不能实现抗动态调试,当逆向攻击者通过动态调试工具对保护后的代码进行动态调试时,代码的执行逻辑依然会被暴露,进而可以通过内存dump方法获取完整的程序代码。针对当前软件保护技术在动态分析中存在的不足,提出一种基于代码碎片化的新型软件保护技术,该技术通过在中间语言(中间语言是一种采用静态单赋值形式的中间表达)层面对功能函数代码碎片进行分离,实现对代码碎片的动态链接执行。该技术将功能函数的直接调用转换成间接调用,能够避免被完整地控制流分析,进而增加静态分析的难度;各个函数模块能够加载到内存中的任意位置,有效防止程序被dump分析,增加程序动态分析的难度。
2 基本思路
代码碎片化技术基于LLVM编译平台,LLVM是一系列分模块、可重用的编译工具链,它提供了一种代码编写良好的中间表示(IR),可以作为多种语言的后端,还可以提供与编程语言无关的优化和针对多种CPU的代码生成功能。LLVM中间表示是一种采用静态单赋值形式(SSA,static single assignment)的中间表达(intermediate representation),包含一套汇编语言类似的指令集和一个类型系统,该指令集是类似于RISC(reduced instruction set computer)的三地址指令集。以可移植的执行体(PE,portable executable)程序碎片化处理过程为例,说明代码碎片化技术的原理,如图1所示。首先,对源代码进行shell化变形,在中间语言层面对源代码进行相应的修改,将代码中的所有全局变量和应用程序编程接口(API,application programming interface)函数等全局数据提取出来保存在全局数据区。然后,在中间语言层面将所有功能函数以数组的形式保存起来,并将功能函数的调用由直接调用改为间接调用的形式,添加Loader函数,负责对功能函数进行调用,同时构建功能函数的动态地址表,依据构建的函数数组将所有函数代码碎片分离到独立的中间语言文件中。最后,将主函数、Loader函数、全局数据区数据和分离的功能函数碎片作为一个整体进行编译,生成类PE文件。
3 碎片化技术模型建立
代码碎片化技术有3个阶段:函数代码shell化、函数内存布局随机化、函数执行动态链接化。本文通过符号化形式建立碎片化的技术模型。
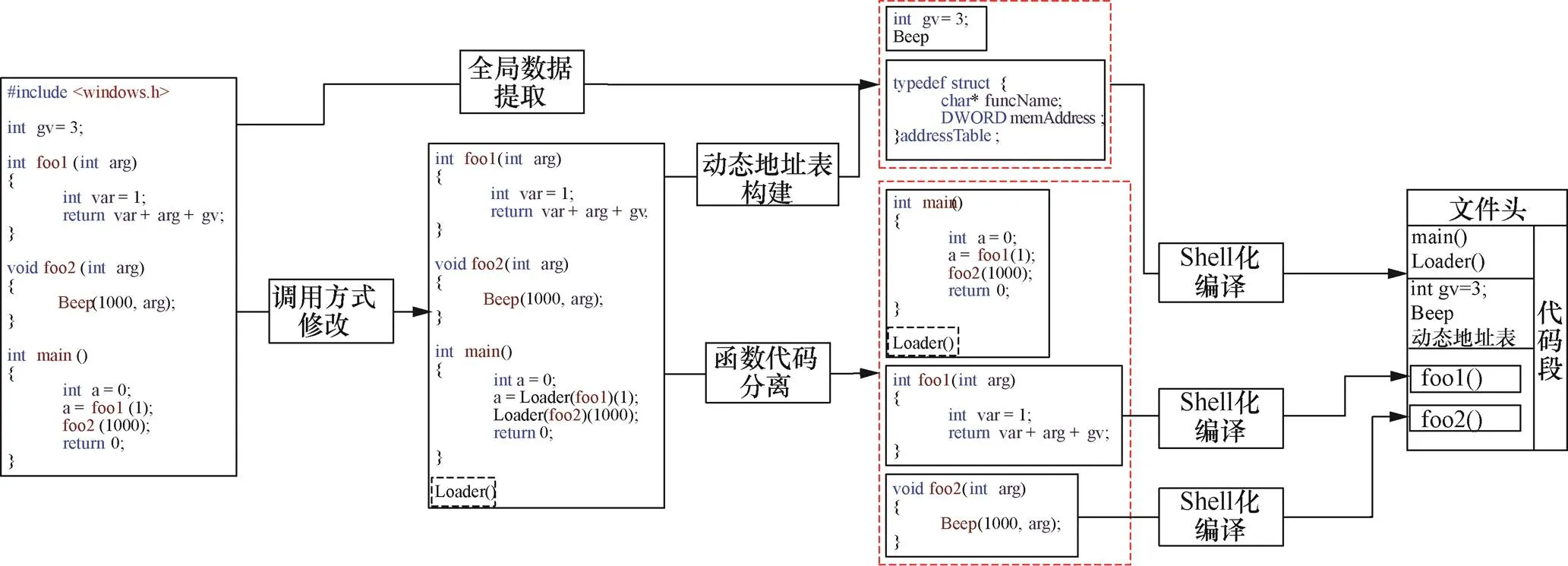
图1 碎片化处理过程
Figure 1 The process of fragmentation

表1 函数fi中各元素定义
定义4 函数代码shell化各映射关系定义如表2所示。

表2 代码shell化各映射关系定义
定义7 函数执行动态链接化各映射关系定义如表3所示。

表3 动态链接化各映射关系定义
代码碎片化模型可以形式化地表示为
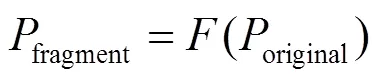
代码碎片化由3个阶段组成:函数代码shell化,函数内存布局随机化以及函数执行动态链接化。每个阶段都对程序进行相应的修改,具体算法如算法1所示。首先,对中间语言IRoriginal提取API函数和全局变量;然后,对API函数调用方式和全局变量访问方式进行修改,接着,修改函数调用方式,并将函数碎片进行分离,同时生成动态地址表;最后,通过Loader函数实现对分离的函数碎片进行调用。
算法1 代码碎片化算法
输入 原始中间语言文件IRoriginal
输出 碎片化处理后的中间语言文件IRfragment
begin
2) Array
3) procedure Shell(module)
4) GetGVData(module)/*全局数据聚合*/
5) RetriveGVDataCall()/*修改全局数据调用方式*/
6) end procedure
7) procedure GetGVData(module)
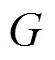
9) GV_INFO*oGV = new GV_INFO(GV);
11) API_INFO*oImportFn = new API_INFO(ImportFn);
13) end foreach
16) end procedure
17) procedure RetriveGVDataCall()
19) foreach GV_User in gv_info's Users
20) /*得到该变量在全局数据区中的位置*/;
21) var GV_Addr = CreateGetElementPtr(GlobalStruct, index)
22) /*替换原全局变量的使用 */
23) GV_User.ReplaceUseWith(GV, GV_Addr);
24) end foreach
25) end foreach
27) foreach API_User in api_info's Users
28) /*得到该变量在全局数据区中的位置*/;
29) var API_Addr = CreateGetElementPtr(GlobalStruct, index);
30) /*读取该地址存储的数据*/
31) var API_Addr_Value = CreateLoadMemory(API_Addr);
32) /*替换原API的使用 */
33) API_User.ReplaceUseWith (API, API_ Addr_Value);
34) end foreach
35) end foreach
36) end procedure
37) procedure Seperate(module)
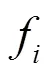
39) GenerateDynAddrTable()/*初步生成动态地址表*/
40) foreach CustomerFn in FuncInfoList
41) SeperateFragment(CustomerFn)/*分离功能函数碎片*/
42) end foreach
43) end procedure
44) procedure ModifyCallFunc(module)
45) CollectFunc(module, FuncInfoList) /*收集每个功能函数保存在结构体中*/
46) foreach CustomerFn in FuncInfoList
47) foreach UserInst in CustomerFn's Users
48) CreateCallOrInvoke(NewUserInst, Params)/*创建新的指令*/
49) UserInst.RemovefromFunction()/*删除原指令*/
50) end foreach
51) end foreach
52) end procedure
53) procedure GenerateDynAddrTable()
54) foreach CustomerFn in FuncInfoList
55) GenerateTable(TableList) /*初步生成动态地址表*/
56) end foreach
57) end procedure
58) procedure DynamicLink()
59) addLoader()/*添加Loader函数*/
60) foreach CustomerFn in FuncInfoList
61) Loader(CustomerFn) /*动态调用功能函数*/
62) end foreach
63) end procedure
end
4 碎片化技术流程设计

图2 碎片化技术基本流程
Figure 2 The basic process of fragmentation technology
4.1 代码shell化变形
代码shell化变形需要解决两个关键问题。
1) 生成的碎片代码必须具有位置无关性,即碎片代码可以在任意内存空间中运行,碎片代码对内存地址的引用及跳转操作只依赖碎片代码的基址。
2) 碎片代码需要自行解决对外部函数的引用,即碎片代码需要自行索引系统函数的地址。
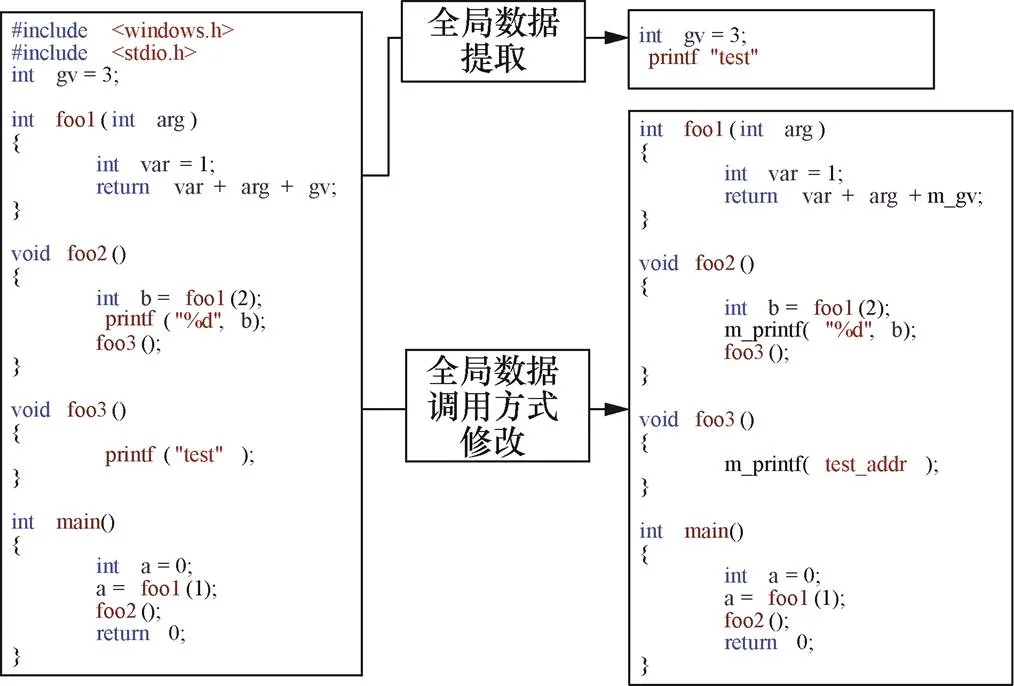
图3 shell化变形过程
Figure 3 The process of Shell deformation
通过对IR文件的分析和变形,分别完成了全局数据区和结构体的构建、函数重定位的处理和位置无关变形。在这个过程中,生成的全局数据以内联汇编宏代码的方式保存在生成的头文件中,同时引导文件内包括负责全局数据初始化和函数地址重定位的功能函数。因此,头文件和引导文件需要同变形后的IR文件合并编译链接。经过函数签名修改后的IR文件,默认的入口函数符号已经发生变化,不再被链接器识别。因此,在合并编译之前,需要新建IR文件的入口函数,该函数负责调用全局数据初始化函数和原入口函数。
4.2 函数碎片分离


图4 代码碎片分离过程
Figure 4 The process of code fragmentation
算法2 功能函数分离算法
begin
1) foreach Fn in FuncList
2) SeparaeProcess(Fn)
3) end foreach
4) procedure SeparateProcess(Func)
5) if FuncCallNum>1 /*处理调用函数数量大于1的情况*/
6) separate(Func)/*分离函数*/
7) end if
8) if FuncCallNum == 1 /*处理调用函数数量等于1的情况*/
9) ParentNode = search(Func)/*回溯父节点*/
10) if ParentNode is main
11) separate(Func)
12) end if
13) if ParentNodeCallNum> 1/*处理父节点调用函数数量大于1的情况*/
14) separate(ParentNode& &Func)/*分离父节点与其子节点*/
15) end if
16) if ParentNodeCallNum == 1
17) SeparateProcess(ParentNode) /*递归处理*/
18) end if
19) end if
20) end procedure
end
4.3 碎片代码执行时动态链接

图5 功能函数调用流程
Figure 5 The process of function call
5 原型系统
根据代码碎片化技术设计流程,设计实现了代码碎片化原型系统,如图6所示,该系统主要由3个模块组成:代码shell化变形模块、代码碎片分离模块和代码碎片动态链接模块。
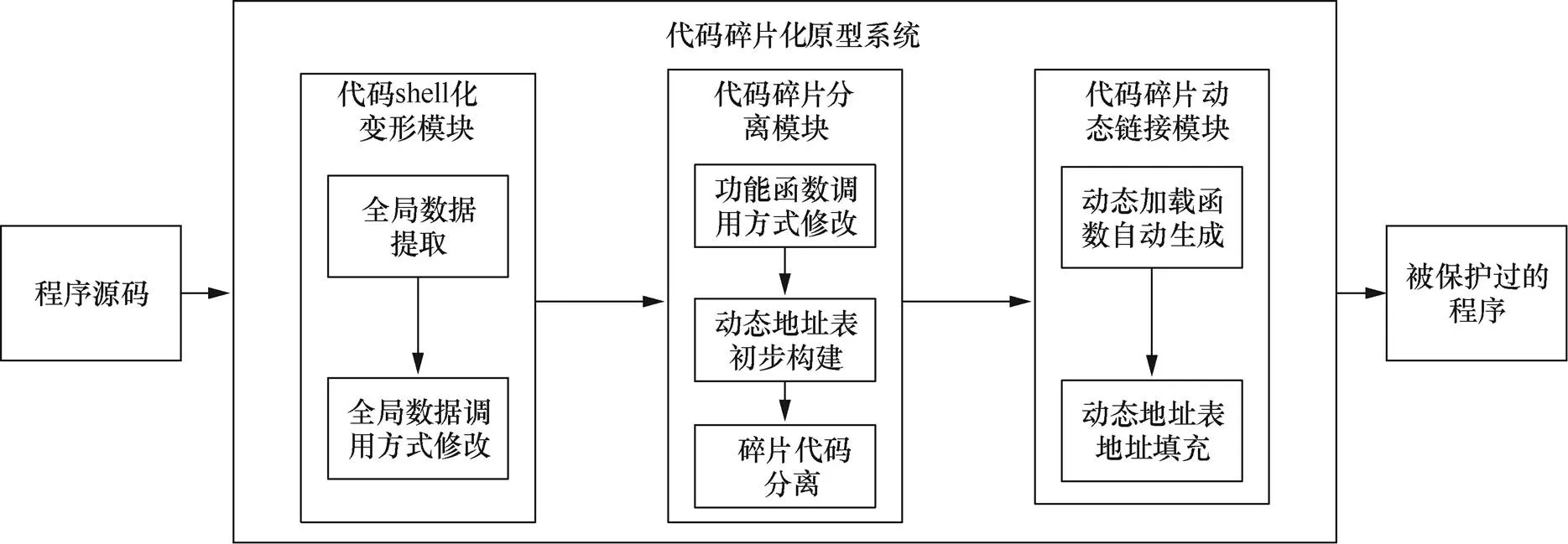
图6 代码碎片化原型系统
Figure 6 Code fragmentation prototype system
代码shell化模块实现对程序源码中的全局数据进行提取,保存到统一的全局数据区中,并实现对全局数据引用方式修改,在全局数据区中通过“地址+索引”的方式实现对全局数据的引用。
代码碎片分离模块实现对功能函数代码碎片的分离,是原型系统的关键。首先,在中间语言层面通过LLVM接口获取所有功能函数,并修改对功能函数的调用方式,由直接调用修改为间接调用;然后,根据功能函数列表构建动态地址表;最后,通过LLVM编译平台将功能函数实体分离为代码碎片,写入独立的中间语言文件中。
代码碎片动态链接模块完成代码碎片的动态链接,这需要在主函数之外自动添加一个Loader加载函数,负责对分离后的代码碎片进行动态调用,同时实现对动态地址表的动态填充。
6 实验
代码碎片化技术实现了对PE文件的结构布局的改变,通过该技术产生的类PE文件在代码段中存在主函数和加载函数两部分,其他功能函数以碎片的形式保存,通过间接调用的形式调用。因此,代码碎片化技术能够有效增加逆向攻击者逆向分析的难度。目前学术界和工业界尚未提出一套合理有效的方法来评测代码碎片化技术的强度,因此这里从程序执行的角度来说明该技术对软件的保护效果。
本文选取实验环境为Windows7操作系统,Intel I7 2.6 GHz CPU,4 GB内存;Windows8操作系统,Intel I7 2.6 GHz CPU,4 GB内存;Windows10操作系统,Intel I7 2.6 GHz CPU,4 GB内存。选用的测试集由rsa、rc4、MD5、aes、des、sm4、sha256、gzip、huffman、Huffcomprs这10个程序组成,测试集的基本信息如表4所示,分别记录代码行数、函数数量和程序功能。
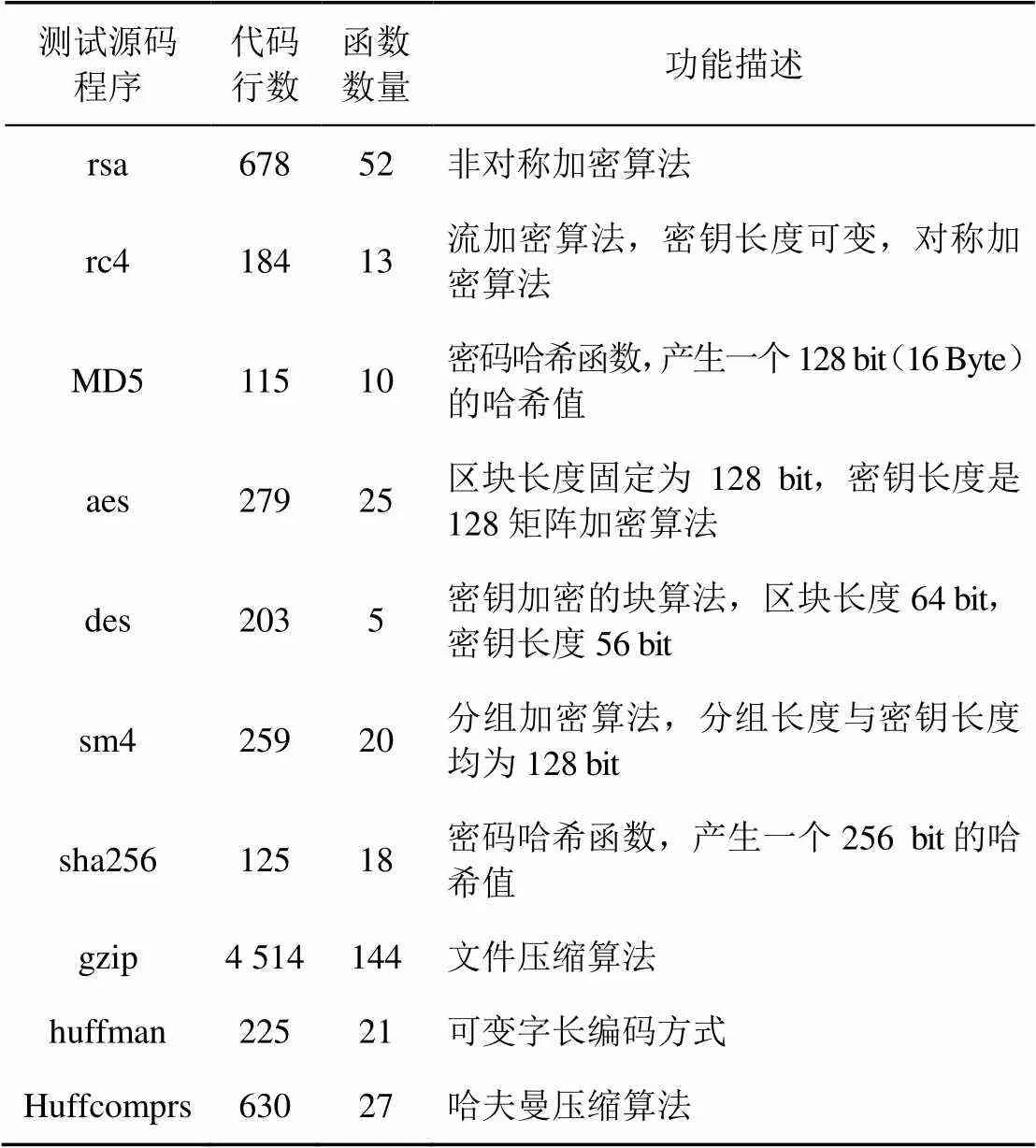
表4 测试集基本信息
对程序进行碎片化保护后需要对每个程序的可用性进行测试,分别在Windows7、Windows8、Windows10操作系统下进行测试,代码碎片化保护之后所有程序功能均正常。
针对原型系统,采用3个指标对原型系统进行衡量,分别是导入函数变化、函数在内存中的布局与间接调用在程序中函数调用的比例。
函数导入表是记录程序所用到的其他模块的导出符号的地址、名称和序号。在程序执行时导入函数是与位置有关的,代码碎片化技术需要实现程序的位置无关化,消除导入函数的位置有关性。通过比较碎片化前后导入函数数量的变化能够体现代码碎片化的位置无关化,如表5所示。

表5 导入函数数量变化
对于函数在内存中的布局,以gzip程序为例,记录程序执行30次zip函数在内存中的加载位置,如图7所示,zip函数在程序每次执行时在内存中的加载位置都不同,体现函数内存布局的随机化。
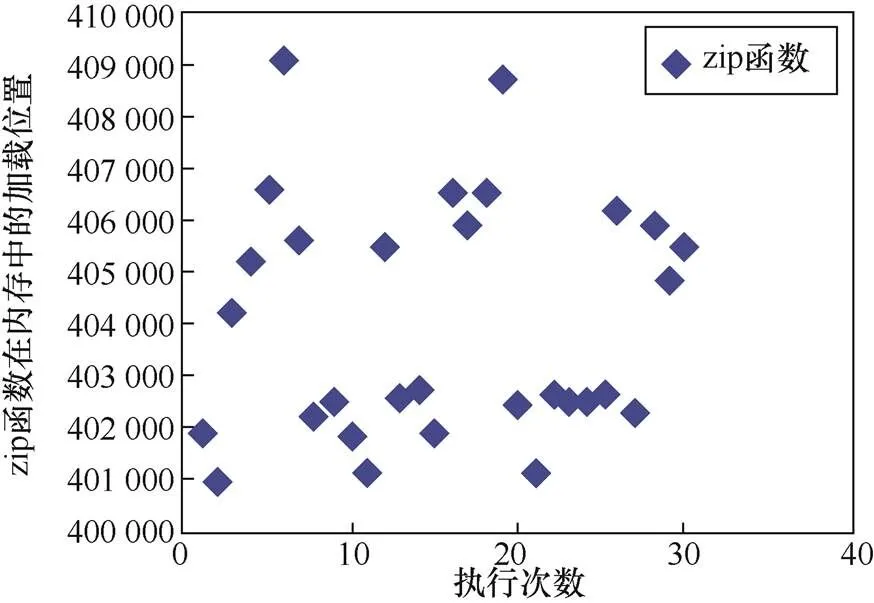
图7 gzip程序中zip函数的内存布局
Figure 7 The memory layout of the zip function in the gzip program
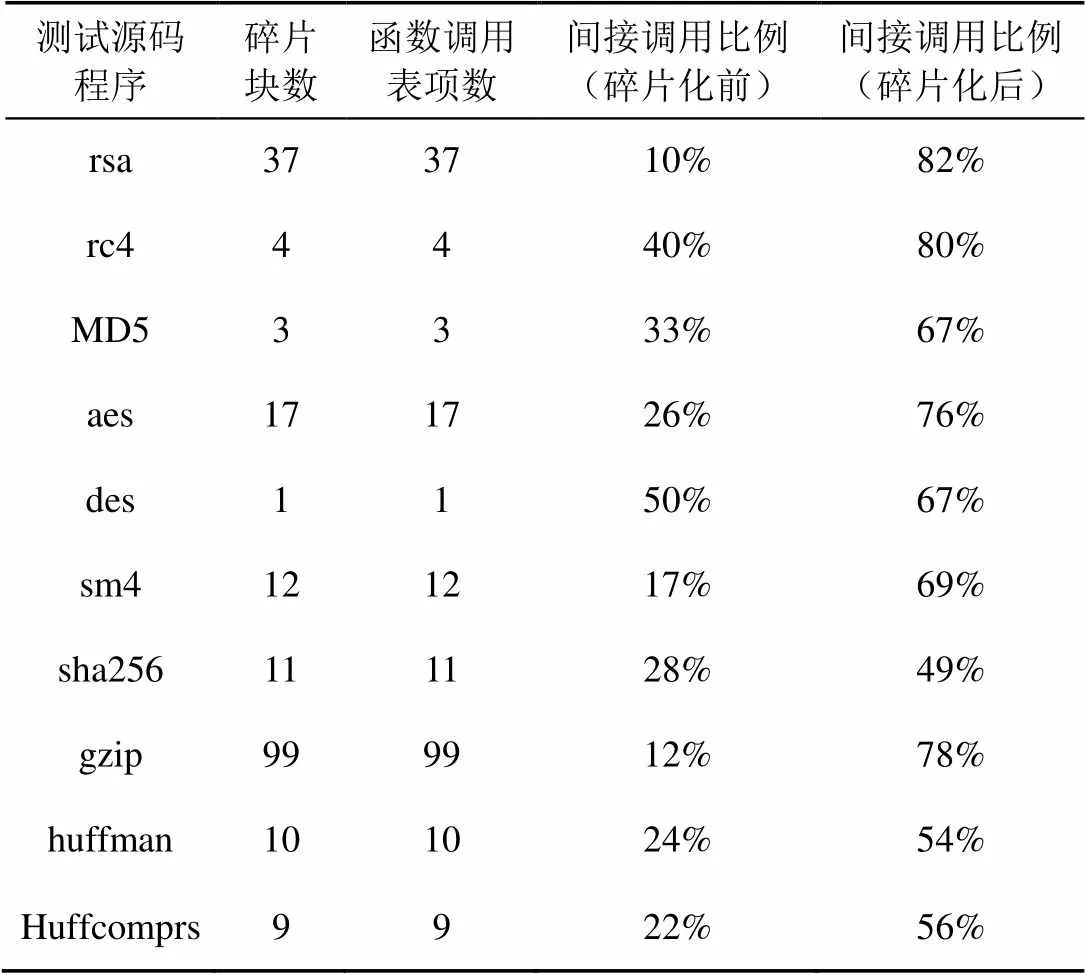
表6 程序中间接调用比例
函数碎片是在执行时通过动态链接的形式进行调用的,调用方式由直接调用修改为间接调用,因此,对程序进行代码碎片化后,程序中间接调用的比例会有所增加,如图8所示。
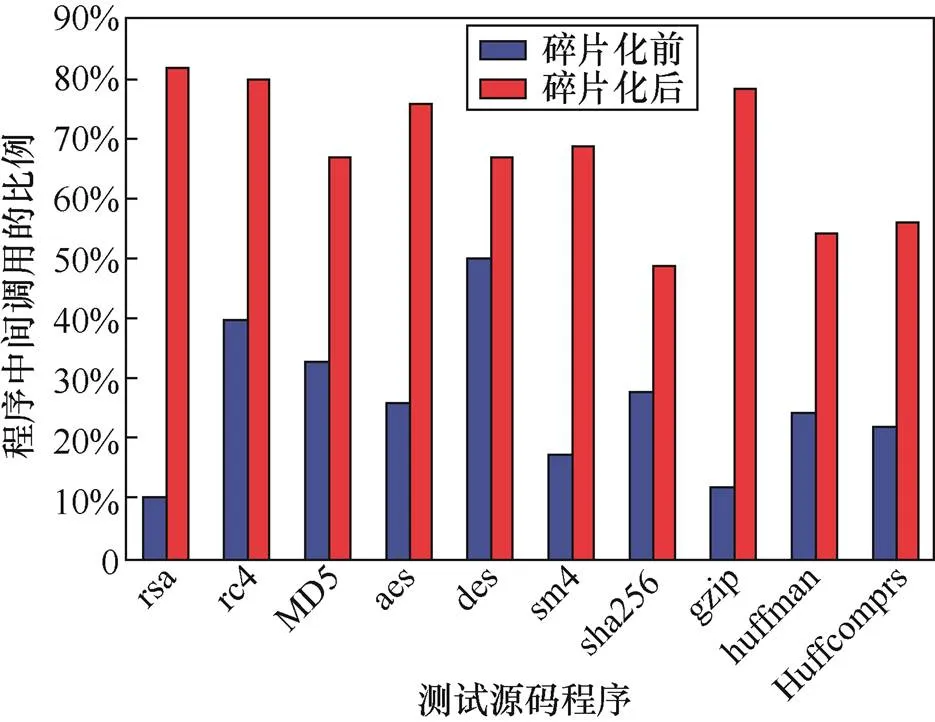
图8 程序中间接调用比例变化
Figure 8 Changes in the proportion of indirect calls

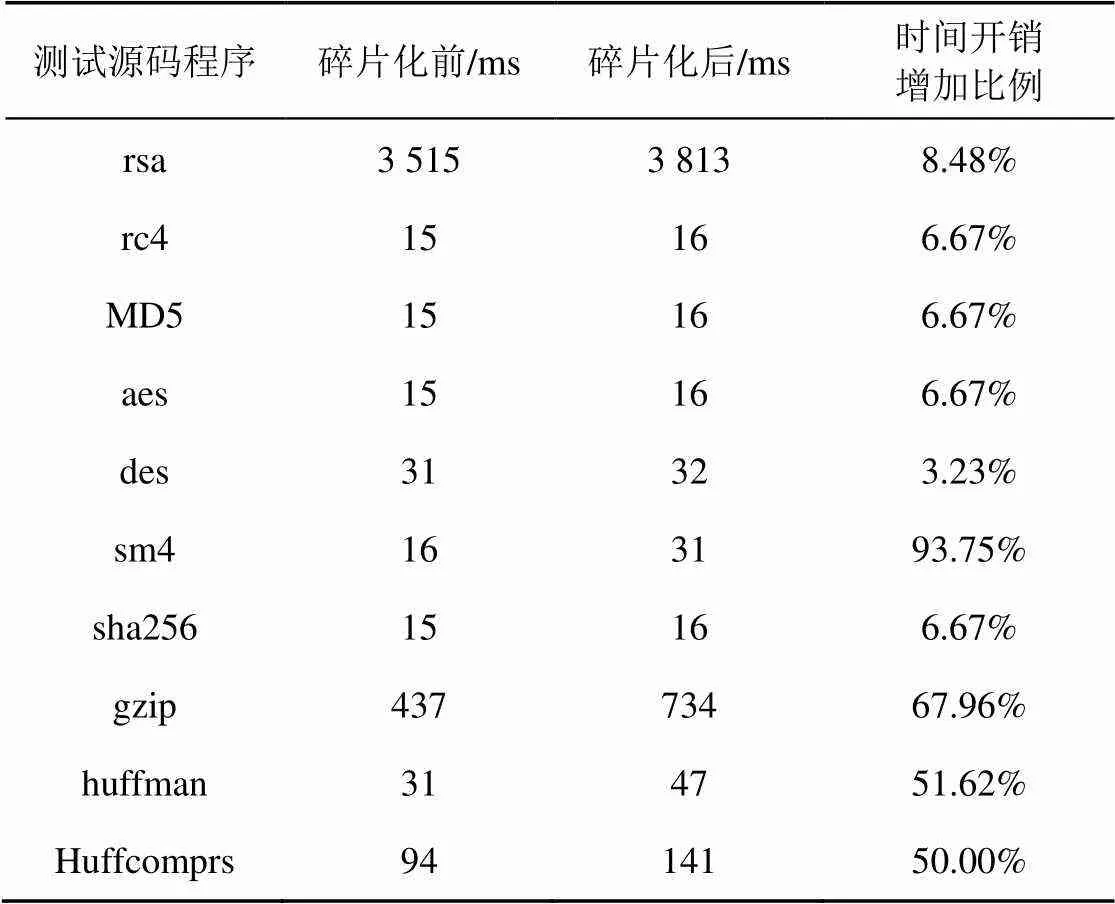
表7 碎片化前后时间开销变化
7 结束语
代码碎片化技术对代码的保护是通过将功能函数分离并独立编译成能够在内存中任意位置执行的碎片,通过动态加载函数碎片实现对功能函数的动态执行。攻击者通过静态分析碎片化保护后的程序时,只能实现对主函数和加载函数的分析,无法分析以碎片存在的功能函数。当攻击者通过动态调试工具对程序进行动态调试时,只能跟踪调试主函数和加载函数的控制流,无法对碎片中的控制流进行跟踪,大大增加了程序逆向分析的难度。通过实验分析,碎片化技术能够实现函数碎片的内存布局随机化,碎片化保护后的程序间接调用比例有所增加,通过将函数的直接调用修改为间接调用,能够实现对函数碎片执行的动态链接。同时,代码碎片化技术有很多不完善的地方。控制流完整性分析在程序逆向分析中具有重要作用,未来将针对模糊函数与函数之间的控制流,增加程序的控制流完整性分析的难度作进一步研究。
函数单个调用链的函数组采取以非内联的形式进行处理,将每个函数单独碎片化,将函数组中的函数内联化为一个函数是减少程序时间开销的有效手段,是将这些函数单独处理的进阶措施。程序因间接调用的增加而造成的攻击面增加问题,将从两个方面进行研究:一方面,采取随机转换策略,随机选取部分函数进行碎片化,避免间接调用增加过多;另一方面,引入垃圾函数调用,平衡因碎片化而造成的间接调用比例失衡。软件升级也是需要考虑的问题,对于以下载二进制补丁和汇编补丁的方式进行更新的软件,需要作进一步研究。
[1] 许团, 屈蕾蕾, 石文昌. 基于结构特征的二进制代码安全缺陷分析模型[J]. 网络与信息安全学报, 2017, 3(9): 31-39.
XU T, QU L L, SHI W C. Analysis model of binary code security flaws based on structure characteristics[J]. Chinese Journal of Network and Information Security, 2017, 3(9): 31-39.
[2] 孙博文, 黄炎裔, 温俏琨, 等. 基于静态多特征融合的恶意软件分类方法[J]. 网络与信息安全学报, 2017, 3(11): 68-76.
SUN B W, HUANG Y Y, WEN Q K, et al. Malware classification method based on static multiple-feature fusion[J]. Chinese Journal of Network and Information Security, 2017, 3(11): 68-76.
[3] 李伟明, 邹德清, 孙国忠. 针对恶意代码的连续内存镜像分析方法[J]. 网络与信息安全学报, 2017, 3(2): 20-30.
LI W M, ZOU D Q, SUN G Z. Successive memory image analysis method for malicious codes[J]. Chinese Journal of Network and Information Security, 2017, 3(2): 20-30.
[4] 王健. 基于完整性验证和壳的软件保护技术研究[D]. 太原: 中北大学, 2018.
WANG J. Research on software protection technology based on in-tegrity verification and shell[D]. Taiyuan: North China University, 2018.
[5] 杜春来, 孔丹丹, 王景中, 等.一种基于指令虚拟化的代码保护模型[J]. 信息网络安全, 2017(2): 22-28.
DU C L, KONG D D, WANG J Z, et al. A code protection model based on instruction virtualization[J]. Netinfo Security, 2017(2): 22-28.
[6] BALACHANDRAN V, EMMANUEL S, KEONG N. Obfuscation by code fragmentation to evade reverse engineering[C]//2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC. 2014.
[7] BALACHANDRAN V, KEONG N W, EMMANUEL S. Function level control flow obfuscation for software security[C]//Eighth International Conference on Complex, Intelligence and Software Intensive Systems. 2014: 133-140.
[8] LASZLO T, KISS A. Obfuscating C++ programs via control flow flattening[R]. 2009.
[9] JUNOD P, RINALDINI J, WEHRLI J, et al. Obfusca-tor- LLVM−software protection for the masses[C]//2015 IEEE/ACM 1st International Workshop on Software Protection. 2015: 3-9.
[10] DAVIDSON J, HILL J, KNIGHT J. Protection of software-based survivability mechanisms[C]//2013 43rd Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN). 2001: 193-193.
[11] WANG C, HILL J, KNIGHT J. Software tamper resistance: obstructing static analysis of programs[J]. 2000.
[12] WANG C.A security architecture for survivability mechanisms[D]. Virginia: University of Virginia,School of Engineering and Applied Science, 2000.
[13] 蒋华, 刘勇, 王鑫. 基于控制流的代码混淆技术研究[J]. 计算机应用研究, 2013, 30(3): 897-899.
JIANG H, LIU Y, WANG X. Code confusion technology research based on control flow[J]. Application Research of Computers, 2013, 30(3): 897-899.
[14] 王旭. 基于目标代码的控制流混淆技术研究[D]. 北京: 北京邮电大学, 2013.
WANG X. Research on control flow obfuscation technology based on object code[D]. Beijing: Beijing University of Posts and Telecommunications, 2013.
[15] 王丰峰, 张涛, 徐伟光, 等. 进程控制流劫持攻击与防御技术综述[J]. 网络与信息安全学报, 2019, 5(6): 10-20.
WANG F F, ZHANG T, XU W G, et al. Overview of control-flow hijacking attack and defense techniques for process[J]. Chinese Journal of network and information security, 2019, 5(6): 10-20.
[16] 乔向东, 郭戎潇, 赵勇. 代码复用对抗技术研究进展[J]. 网络与信息安全学报, 2018, 4(3): 1-12.
QIAO X D, GUO R X, ZHAO Y. Research progress in code reuse attacking and defending[J]. Chinese Journal of Network and Information Security, 2018, 4(3): 1-12.
Software protection technology based on code fragmentation
GUO Jingcheng, SHU Hui, XIONG Xiaobing, KANG Fei
Information Engineering University, Zhengzhou 450001, China
Aiming at the shortcomings of the current software protection technology, a code fragmentation technology was proposed. This technology is a new software protection technology that takes functions as units, shells functions, randomizes memory layout, and performs dynamic linking. The code shellization realizes the position-independent morphing of code fragments, the memory layout randomizes the random memory loading of the code fragments, the dynamic linking realizes the dynamic execution of the code fragments, and the program fragmentation processing is achieved through the above three links. The experiments show that the code fragmentation technology can not only realize the randomization of the memory location of function fragments during program execution, but also the dynamic link execution of function fragments, increasing the difficulty of static reverse analysis and dynamic reverse debugging of the program, and improving the anti-reverse analysis ability of the program.
code fragmentation, software protection, separation, dynamic linking
The National Key R&D Program of China (2016YFB08011601)
TP309.5
A
10.11959/j.issn.2096−109x.2020063

郭京城(1994− ),男,山东济南人,信息工程大学硕士生,主要研究方向为网络安全与软件保护。
舒辉(1974− ),男,江苏盐城人,博士,信息工程大学教授、博士生导师,主要研究方向为网络安全、嵌入式系统分析与信息安全。

熊小兵(1985− ),男,江西丰城人,博士,信息工程大学副教授,主要研究方向为网络安全。
康绯(1972− ),女,河南周口人,硕士,信息工程大学教授,主要研究方向为网络信息安全。
论文引用格式:郭京城, 舒辉, 熊小兵, 等. 基于代码碎片化的软件保护技术[J]. 网络与信息安全学报, 2020, 6(6): 57-68.
GUO J C, SHU H, XIONG X B, et al. Software protection technology based on code fragmentation[J]. Chinese Journal of Network and Information Security, 2020, 6(6): 57-68.
2019−12−05;
2020−02−21
舒辉,shuhui@126.com
国家重点研发计划(2016YFB08011601)
猜你喜欢
商品与质量(2019年34期)2019-11-29 03:25:51
当代陕西(2019年13期)2019-08-20 03:54:22
测控技术(2018年5期)2018-12-09 09:04:46
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
信息安全研究(2016年4期)2016-12-01 06:07:05
测绘科学与工程(2014年5期)2014-02-27 07:06:14
中国信息化·学术版(2013年1期)2013-05-28 05:53:24
