
基于加权随机森林的FDD-LTE上行干扰分类研究
2020-12-18 10:12许鸿奎李鑫邵星姜彤彤宫淑兰
山东建筑大学学报 2020年6期
许鸿奎李鑫邵星姜彤彤宫淑兰
(1.山东建筑大学 信息与电气工程学院,山东 济南250101;2.山东省智能建筑技术重点实验室,山东 济南250101)
0 引言
随着移动通信网络的发展,第2、3、4代移动通信技术网络并存,第5代移动通信技术也在逐渐扩大商用的规模,网络形态变得更加复杂。这种情况下,多网并存导致的无线网络频段分配紧张以及系统互干扰增强等问题日益严重,上行干扰成为了亟待解决的焦点问题。长期演进LTE(Long Term Evolution)网络中的上行干扰会造成切换成功率低、业务速率下降,严重影响了用户的体验。现有的干扰排查方法是依靠网络优化工作人员根据路测结果或者网管中的指标等发现干扰,结合话务报告干扰分析的严重级别和干扰存在的时间,到现场利用扫频设备观察底噪曲线的变化情况,从而确定干扰类型。虽然这种方法能够对小区的受干扰情况进行精准定位,但是其主要依赖优秀工作人员的经验判断,效率较低,不适合大面积推广。
科研工作者们在移动通信网络的上行干扰自动化识别方面进行了深入的研究。翁文迪[1]根据分时长期演进TD-LTE(Time Division-Long Term Evolution)F频段上行干扰的产生机理分析了相应的波形特征,并结合共站址信息,提出了使用异系统干扰识别算法对小区进行干扰检测,为后续的排查工作提供了理论基础。孙黎明[2]利用同类波形特征提出了基于逆向传播BP(Back Propagation)神经网络的自动干扰排查算法。但是,研究人员忽略了实际上行干扰数据中存在不平衡的问题,其会导致机器学习算法的错分率上升[3]。针对此问题,詹皓粤[4]通过主成分分析PCA(Principal Component Analysis)与偏度特性相结合,降维提取了物理资源模块PRB(Physical Resource Block)数据,实现了对分类模型的性能优化。通过改变特征提取方法,虽然能够在一定程度上改善模型性能,但是特征失去了可解释性,并且丢失部分的信息。
目前,上行干扰自动化识别的研究主要针对TD-LTE 1800 MHz频段,而对频分双工—长期演进FDD-LTE(Frequency Division Duplexing-Long Term Evolution)系统的上行干扰分析较少。经过分析发现,FDD-LTE 900 MHz频段的上行干扰问题较为严重,极大地影响了用户的业务体验,因此,对其研究已经刻不容缓[5]。文章提出了基于加权随机森林的上行干扰分类方法,可以有效地解决FDD-LTE网络中上行干扰数据存在不平衡的问题,是提高上行干扰分类准确率的有效方法,在实现智能化网络优化中具有重要的研究意义。
1 FDD-LTE上行干扰类型分析
在移动通信网络中,系统间的上行干扰可以分为杂散干扰、阻塞干扰、互调干扰和外部干扰[6]。文章主要针对中国移动900 MHz FDD-LTE(889~909 MHz/934~954 MHz频段)进行上行干扰分析。
1.1 杂散干扰
杂散干扰是指其他通信系统存在非线性工作器件,其在工作频段外产生无用的信号辐射导致FDDLTE系统接收到无用信号,形成对有用信号的同频干扰。受干扰小区在受到杂散干扰时,干扰波形呈现滚降特性,频点前端的干扰功率值随着PRB频点的增加而降低。根据我国网络频谱划分情况可知,电信850 MHz FDD-LTE在系统间隔离度非常小的情况下,会存在杂散干扰。
1.2 互调干扰
互调干扰是由于天馈系统相关器件存在非线性问题导致设备在发射信号时形成了互调产物,其频率在FDD-LTE系统信号接收器的接收范围内会使信号接收器的信噪比下降,造成服务质量的下降。受干扰小区在受到互调干扰时,主要体现在干扰波形有多个突起,且突起处连续的PRB频点数不超过4个,如图1(a)所示。根据频谱划分可知,联通GSM 900 MHz的上行频段为909~915MHz,2f1-f2的互调产物恰好落于移动900 MHz FDD-LTE的频段范围内,产生互调干扰。
1.3 阻塞干扰
阻塞干扰是由于FDD-LTE系统的接收设备接收到带外强的干扰信号,使接收设备链路的有源器件达到饱和状态并产生失真,受干扰系统接收设备灵敏度下降,无法接收到有用信号。阻塞干扰的波形图主要表现在每个频点的干扰功率均有一定程度的提升,一般>5 dBm即为阻塞干扰,如图1(b)所示。电信850 MHz FDD-LTE基站设备系统隔离度不足是造成移动900 MHz FDD-LTE阻塞干扰的最大原因,而私装直放站也是导致阻塞干扰的重要因素。
1.4 外部干扰
所有移动通信系统之外的干扰源引起的干扰统称为外部干扰。主要的外部干扰源有信号屏蔽器和信号干扰装置等。建网初期,对GSM 900 MHz频段干扰排查不彻底也会造成严重的外部干扰。此类干扰在波形图上主要表现为受干扰处会呈现一个尖峰 突起,如图1(c)所示。
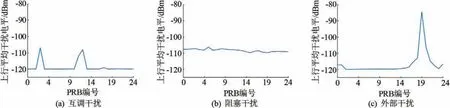
图1 上行干扰波形图
2 基于加权随机森林的上行干扰分类模型建立
2.1 决策树模型
决策树是一种树形结构的机器学习算法[7],由根节点、非叶子节点和叶子节点组成,其结构如图2所示。
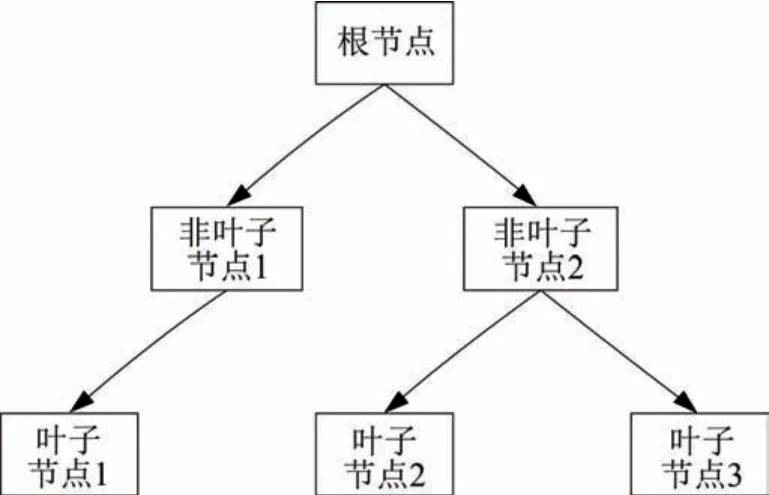
图2 决策树结构图
决策树为递归结构,由根节点自上而下进行数据训练和预测,根据不同的相似度计算标准,将数据中具有一定相似度的子集划分出来,产生多个分支,到达决策树的叶子节点则停止划分。叶子节点根据最大树深度或者最小叶子数进行设置,1个叶子节点代表数据的1个分类结果。决策树根据特征划分依据的不同,可以分为基于信息熵、信息增益、信息增益率和基尼不纯度的决策树。假设数据量为N的训练样本集合D可以分为K个类别,则其建立不同决策树的信息熵H(D)、信息增益g(D,a)、信息增益率gR(D,a)和基尼不纯度Gini(D)由式(1)~(4)表示为
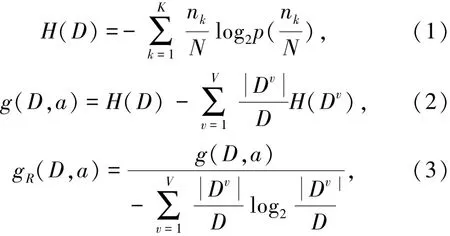

式中nk为第k个类别的数量;v为样本集根据特征a划分的子集数量,取值范围为[1,V]。
2.2 随机森林模型
随机森林是以决策树为基础的一种集成学习算法[8]。其随机生成多个不相关的决策树,每个决策树各自独立地进行学习和预测,通过投票的方式将这些预测合成单预测,得票最多的类别即模型预测结果,其结果优于决策树。
假设输入为训练样本集合D,决策树的迭代次数为M次,随机森林的生成步骤为
(1)对样本训练集进行第m次采样,其中m为整数,取值范围为[1,M]。随机采集n次,得到含有n个样本的训练集Dm;
(2)在决策树进行节点划分时,全部n个输入变量不完全参与节点分裂,而是随机抽取k(k≤n)个随机特征变量,k的取值一般为2 log2n+1,将k个特征中最佳的特征作为节点进行分裂,训练得到第m个使用分类与回归树CART(Classification and Regression Trees)算法生成的决策树Gm;
(3)CART决策树基于基尼不纯度进行特征划分,当基尼不纯度越小时,代表不纯度越小,其特征越好,最终生成M棵CART决策树形成随机森林;
(4)通过计算投票数决定数据属于哪一类,随机森林算法流程如图3所示。
决策树算法计算速度快便于理解,但是容易过拟合,并且在处理不平衡数据时,特征划分会倾向选择数值更多的特征。随机森林与决策树算法相比,准确率高且不容易过拟合,但是在不平衡数据集中,少数类的分类准确率依然不高。针对不平衡数据集的分类问题,文章提出了采用加权随机森林[9]提升较少类分类准确率的方法。
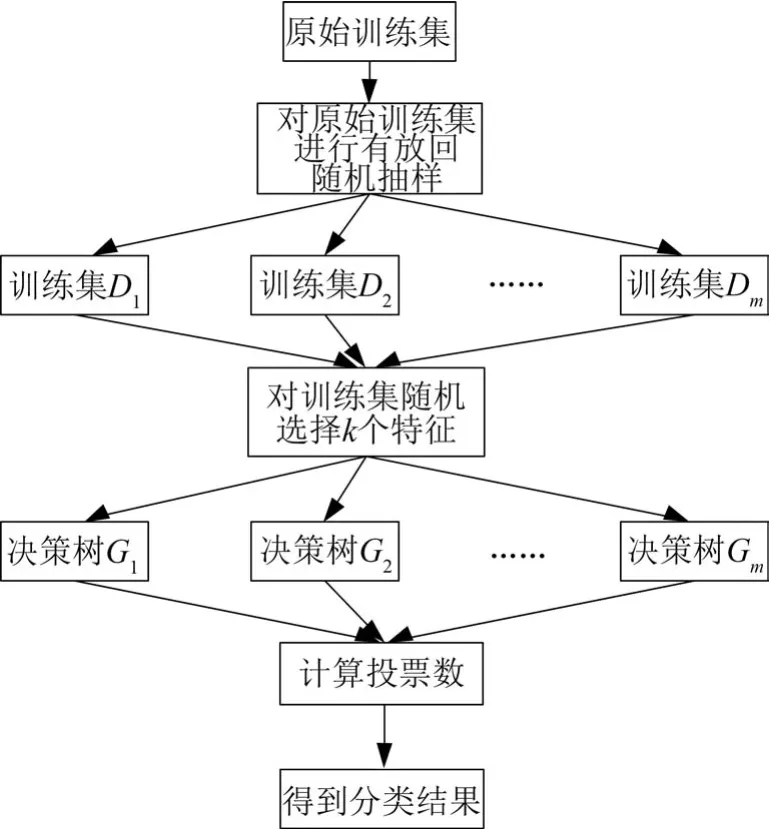
图3 随机森林算法流程图
2.3 加权随机森林模型
机器学习算法为了最小化整体错误率会忽略数量较少类的分类情况,在训练时容易形成有利于多数类分类的模型。为了改善此情况,加权随机森林遵循了代价敏感学习的思想,通过赋予较少类更大的权重来增大较少类的影响,平衡样本之间的关系可以使生成的模型更加适合不平衡数据,提高少数类分类结果的正确率[10]。
类权重主要体现在:(1)在决策树的生长过程中,采用加权基尼不纯度GI的减少量Δgi寻找最优的划分特征,其值越大,代表不纯度越小,分离效果越好,计算式由式(5)和(6)表示为


式中K为总类别数;J为未分离的节点处的样本集,其中JL为分离的左侧节点样本集,JR为分离的右侧节点样本集;ni为节点内的各类样本数;Wi为分配给每类的类权重值。
(2)在叶子节点处确定类别时,通过结合每棵决策树的加权投票来确定最终分类结果c,由式(7)[11]表示为
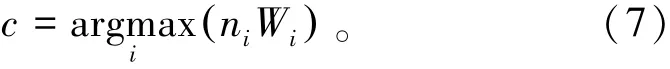
进行二分类权重设置时,可以设定多数类的类权重值为1,对较少类的类权重值从小到大设置并依次进行实验,直到错分率急剧增加,确定错分率最小时的值为较少类的类权重。分类时,若遍历所有的类权重,工作量将过于庞大,一般选择具有代表性的权值进行实验。研究表明:以样本值的比例或者错分值的比例为依据设置类权重比较合适,但是较少类过大的类权重会使整体或者其他类的错分率升高,导致性能下降,所以通常选择2或3作为错分数多或样本数少的类的权重,不需设置过大的权重[11]。
3 上行干扰分类实验及结果分析
3.1 数据准备
传统的网络优化只能通过路测[12]、定点测试来获得用户的感知信息,而路测和定点测试只能对交通主干道和重点场所进行测试,所获得的采样点数据相对较少。测量报告MR(Measurement Report)是手机上报的数据,其地点、时间的限制很少,可以获得丰富的数据点信息,而MR数据应用在网络优化方面则可以更加全面、准确地得到分析结果。
MR数据分为统计数据MRS(Measurement Report Statistics)和样本数据MRO(Measurement Report Original)。MRO数据是海量原始数据经过数据的分发、整合、处理、汇总为报表,用于开发上层应用[13]。FDD-LTE系统将MRO数据中25个PRB上的信号干扰电平作为网络管理的上行干扰指标。文章采用某地区MRO数据中PRB0~PRB24的15 min上行平均干扰电平作为样本,共1 268条数据,部分原始数据见表1。
表1 部分原始数据表 单位:dBm
3.2 特征提取
根据定点测试中干扰门限不应>-110 dBm,设定干扰阈值为-110 dBm;由于平均每PRB抬高>5 dBm为阻塞干扰,设定阻塞阈值为-105 dBm。根据上述规则,并结合上行干扰波形图,对数据进行特征提取,见表2。

表2 干扰特征说明表
3.3 实验方案
为了探究加权随机森林在FDD-LTE上行干扰分类的表现情况,文章设计了对比实验,整体实验流程如图4所示。

图4 整体流程图
实验步骤如下:
(1)根据上行干扰波形图,对FDD-LTE上行干扰数据进行标注,并提取统计干扰特征,得到标注后的干扰特征数据集;
(2)采用分层抽样将干扰特征数据集分为训练集和测试集,根据训练集建立决策树分类器、随机森林分类器和加权随机森林分类器;
(3)利用测试集测试分类器的稳定性和准确性,并根据测试结果得到每类分类器最合适的参数,对比分析分类结果。
3.4 实验参数设计
样本集根据上行干扰电平波形图进行判断和标记,得到互调干扰、阻塞干扰、外部干扰和无干扰依次为62、106、216、884个。对样本集进行随机分层抽样,分别在多数类和少数类中抽取大约2/3的样本组合作为训练集用于构建分类器模型,剩余样本作为测试集测试分类器性能。样本集数据情况见表3。

表3 样本集数据表 单位:个
当随机森林中决策树的棵数较少时,其性能较差、分类误差大。当决策树的棵数尽量大时,能够确保决策树的多样性,从而提高分类的准确率,但是棵数过多会降低随机森林运行速度、加长运行时间[14]。为了确定随机森林中决策树的棵数与干扰分类正确率之间的关系,根据不同的决策树棵数分别建立随机森林模型,决策树棵数与分类正确率之间的关系曲线如图5所示。

图5 决策树棵数与分类正确率关系图
由图5可知,随着决策树棵数的增加,正确率整体呈上升趋势,当决策树的棵数为900时,分类的正确率最高。因此,随机森林中决策树的棵数设定为900。
加权随机森林虽然能够在一定程度上提高不平衡数据中较少类的分类准确率,但是设置合适的类权重非常重要,权值设置不当会降低整体分类正确率。为了设置最合适的权值,设定最小叶子数为3,决策树棵数为900,选择不同的权值进行实验,选择袋外错误率最小的一组权值作为加权随机森林的参数最为合理。每次实验的袋外错误率见表4。

表4 不同权值下加权随机森林的袋外错误率表 单位:%
由表4可知,第1组设置为原始权值,第2组设置为每类样本数量的反比,其余权值根据错分率的大小排序,对其设置2~4的权值进行实验,当权值设置为2∶1∶1∶1时,较少类的分类错误率最小,因此设定其为加权随机森林的权值。
3.5 实验结果分析
实验使用相同的训练集构建不同的分类器,并在相同测试集中进行样本预测,分别对决策树、随机森林和加权随机森林3种分类器进行测试,得到的分类结果见表5。

表5 不同分类器的正确率表
由表5可知,随机森林较决策树分类正确率提高了1.66%,运行时间是决策树运行时间的1/2,但是由于较少类总数量少,错分代价大,随机森林分类情况并不理想,互调干扰分类正确率仅有65.22%。加权随机森林与随机森林相比,互调干扰分类正确率提高了8.69%,外部干扰分类正确率提高了1.74%,证明了加权随机森林可以提高较少类的分类正确率。
为了全面直观地反映每一类分类器的分类效果,每个分类器分类结果的混淆矩阵[15]如图6所示,其中互调干扰、阻塞干扰、外部干扰和无干扰分别标记为1、2、3和4。

图6 不同分类器的混淆矩阵图
混淆矩阵的每1行之和表示该类别的真实样本数量,每1列之和表示被预测为该类别的样本数量,其清晰地显示出每一类的错分情况。由图6(a)可知,第1行数据中,正确预测为互调干扰的样本有14个,错误预测为阻塞干扰和外部干扰的样本分别有2、7个。通过对每个分类器的分类结果比较发现,加权随机森林与决策树相比,互调干扰、阻塞干扰和外部干扰正确分类的个数均增多了3个,无干扰正确分类的个数增多了1个;加权随机森林与随机森林相比,互调干扰正确分类的个数增多了2个,外部干扰正确分类的个数增多了1个。
综上所述,在不平衡的FDD-LTE上行干扰数据的分类中,加权随机森林较少类的分类正确个数有所增加,分类性能优于决策树和随机森林,说明加权随机森林能够有效地解决FDD-LTE上行干扰数据不平衡的问题,改善较少类分类准确度较低的现象,而且运行速度快,分类准确率高,能够较好地实现FDD-LTE上行干扰的智能化分类。
4 结论
文章针对FDD-LTE上行干扰分类问题建立了一种基于加权随机森林的上行干扰分类模型,对比分析了决策树、随机森林和加权随机森林3种分类器的分类结果,得到以下结论:
(1)加权随机森林根据数据较少类的数量或者错分率,设置合适的权值能够提高较少类分类的准确率。当权值设置为2∶1∶1∶1时,较少类的分类错误率最小,其互调干扰和阻塞干扰的分类正确率分别达到73.91%和96.67%。
(2)与决策树和随机森林相比,加权随机森林在不平衡的FDD-LTE上行干扰数据处理中具有最好的分类效果。决策树和随机森林的分类正确率分别为93.85%和95.51%,加权随机森林的分类正确率达到了96.22%,而运行时间仅有0.98 s。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
电子产品世界(2022年4期)2022-04-21
邮电设计技术(2021年2期)2021-03-13
计算机系统应用(2021年2期)2021-02-23
计算机应用与软件(2020年1期)2020-01-14
计算机与数字工程(2019年11期)2019-11-29
科学与信息化(2019年28期)2019-10-21
计算机测量与控制(2019年4期)2019-05-08
科学与财富(2016年32期)2017-03-04
科技视界(2016年1期)2016-03-30
