
基于短语结构文法的评价关系识别研究
2020-12-17 03:17王玉玲
江汉学术 2020年1期
何 伟,王玉玲
(1 中国传媒大学 人文学院,北京 100024;2 清华大学 人文学院,北京 100084)
评价分析是中文智能信息处理领域的一个研究热点,有着广泛的应用前景。例如对购物平台上海量的用户评论进行自动分析,获取用户对产品的真实评价,这显然有着巨大的商业价值。[1]评价分析通常采用三元组[2]〈评价对象、评价词语、褒贬极性〉或五元组[3]〈评价对象、评价主体、评价词语、褒贬极性、程度〉作为评价单元,分析的过程就是正确抽取出评价句中的评价单元。
例1:拍照挺给力的,就是指纹解锁不灵敏。
评价分析的结果:〈拍照,给力,1〉〈指纹解锁,不灵敏,-1〉
例1 是一条用户针对某款手机的评论,评价分析的结果就是正确抽取出句子中所包含的两个三元组〈拍照,给力,1〉〈指纹解锁,不灵敏,-1〉,其中 1 代表褒义,-1 代表贬义。
评价句中往往包含着多个评价对象和评价词语,评价对象和评价词语之间存在着对应关系,也就是评价关系。准确地识别出评价句中的评价关系,将评价词语和其所指向的评价对象对应起来,就是本文所说的评价关系识别,这也是评价分析的难点所在。
目前,关于评价关系识别的方法大致有基于最短距离、基于机器学习、基于句法语义规则三类方法。基于最短距离的方法通常选取距离评价对象最近的评价词语作为其对应的情感词[4],此类方法过于简单,没有考虑句法语义关联和长距离搭配问题。基于机器学习的方法通常是引入机器学习算法来习得评价对象和评价词语的关系。例如Zhang S 等人使用条件随机场模型来识别评价对象,然后根据评价对象的最近邻和句法树来发现情感词[5]。王荣洋等将语义标注特征引入条件随机场(conditional random field,CRF),认为评价对象通常会担任某个谓词的施事者或者受事者,考察了语义标注、词法、依存关系、相对位置,对抽取英文语料评价对象性能做了比较研究[6]。Duyu Tang 等人利用深层记忆网络(deep memory networks,DMN)方法获取上下文词语对评价对象的重要性信息,随后利用重要性信息计算对象在当前句子环境中的表示,并判定情感极性。实验结果显示该方法比长短时记忆网络(long short-term memory,LSTM)效果更好[7]。机器学习方法的主要制约因素是难以获取大量的人工标注训练语料。
基于句法语义规则的方法往往采用依存句法分析和语义角色标注,然后通过规则或算法来识别评价关系。例如,Kamal A 等人基于语义分析设计了相关规则以实现“评价对象—情感词对”的抽取[8]。Poria S 等人基于依存结构树设计了相关规则抽取评价对象—情感词对[9]。顾正甲等人利用主谓结构(subject-verb,SBV)极性传递法,即利用句法分析中的依存关系抽取评价对象和情感词,然后采用定中关系链算法和互信息算法相结合的方法修正评价对象边界[10]。江腾蛟等人提出基于浅层语义与语法分析相结合的评价对象—情感词对抽取方法。具体操作为,针对金融评论语料进行依存语法及语义标注,而后根据情感词在句中充当的句法分成确定其语义指向,继而抽取情感词修饰的评价对象[11]。此类方法对依存句法分析或者语义标注的准确率要求较高,但是目前依存句法分析的性能还有待完善。
与依存句法分析相比,短语结构文法更加成熟,从词到短语到分句到句子的结构清晰,对名词短语(noun phrase,NP)和动词短语(verb phrase,VP)的识别率高,非常适合提取短语形式的评价对象和评价词语,因此本文提出基于短语结构文法的评价关系识别方法。
一、评价词语及候选评价对象提取
评价关系的识别首先需要提取评价词语和候选评价对象,评价词语的提取主要依靠情感词典和组词规则,候选评价对象的提取主要是识别出句子中的NP 短语,以下分别简要介绍。
(一)评价词语提取
评价词语可以看作由(程度副词)+(否定词)+情感词组成[12],括号内的成分表示可能出现,也可能不出现。如下面这句用户评论。
例2:手机性能很好,发货速度快,外观好看,就是指纹解锁不灵敏。
上例中的评价词语“很好”是程度副词“很”+情感词“好”组成的,“快”“好看”是情感词直接做评价词,“不灵敏”是否定词“不”+情感词“灵敏”组成的。情感词是指能够反映说话人褒贬态度的词语,一般预先存储在情感词典中,并标注上褒贬极性,如“好,形容词,正面评价”。识别评价词语时首先匹配句子中的情感词,然后再判断该情感词是否和程度副词、否定词进行搭配;程度副词不会改变原有情感词情感倾向,否定词则会改变其修饰的情感词的情感倾向,使原情感词极性反转。例2 句子中评价词语的提取结果如表1 所示。

表1 评价词语提取示例
例2 句共有4 个评价词语,表1 中的每个评价词语记录,“id”为句中位置,“word”为词形,“pos”为句法标记,“tag”为词性标记,“pol”表示褒贬极性。如“[id:16,word:不灵敏,pos:VA,tag:a,pol:-1]”,记录评价词语“不灵敏”信息:在句中位置为16,句法标记“VA”表示形容词作谓语,词性标记为“a”形容词,褒贬极性“pol:-1”表示该评价词语为负面倾向。
(二)候选评价对象提取
候选评价对象主要由名词性成分构成,包括单个名词和名词性短语。例如主谓评价句“发货速度很快”“手机性能很好”“电池很耐用”“屏幕清晰”等,此时名词性主语成分“发货速度”“手机性能”“电池”“屏幕”即为评价对象。宾语中的名词性成分也可能成为评价对象,如“我就是讨厌华为的海军”中“华为的海军”就是评价对象。名词性的中心语成分也可能成为评价对象,如“很不错的手机”中“手机”就是评价对象。
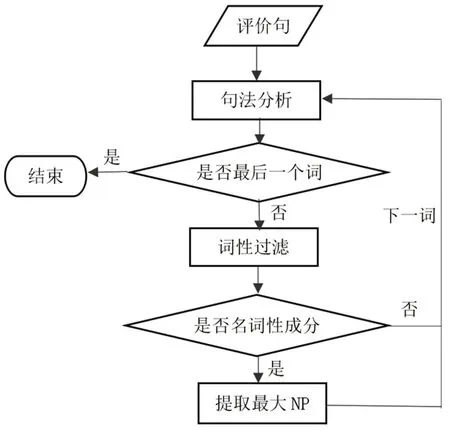
图1 候选评价对象提取流程图
候选评价对象抽取流程图如图1 所示,首先将含有评价词语的评价句输入句法分析器进行短语结构文法分析,句法分析器采用斯坦福句法分析器。然后进入候选评价对象抽取阶段。候选评价对象抽取,需要利用分词结果、评价词语抽取结果、句法分析结果等信息。这些所需信息均保留在每个切分单词中,每个单词均保留其句中位置、词性标记、句法标记、词形、是否评价词及褒贬极性等信息。候选评价对象的抽取主要分两步进行。第一步为词性过滤,可初步过滤肯定不为评价对象的词性,如标点符号(w)、连词(c)、副词(d)等。第二步为抽取句子中最长名词性成分,即最大名词性短语NP,如果无名词短语NP 则抽取单个名词。最大名词性短语NP 的识别过程就是判断围绕某一名词能否构成最大NP。判断两个词是否能构成名词短语NP,需要找到两个结点的最低公共父节点是否是NP。如图2 所示句子“手机性能很好,发货速度快,外观好看,就是指纹解锁不灵敏”的句法结构树,其中“手机”句法标记为“NN”即为普通名词,该词与后一个词“性能”最低公共父节点为“NP”,即两者可构成名词性NP 短语“手机性能”,而“外观”不与周围词构成更大NP,自身构成名词短语NP。
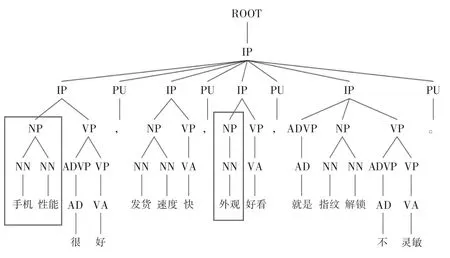
图2 最大名词性短语NP 提取示例
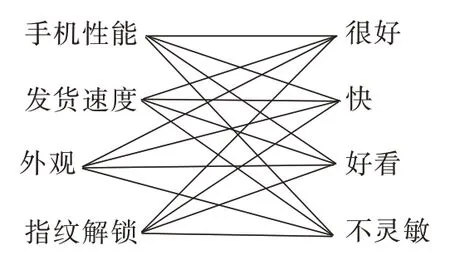
图3 可能的评价关系
二、利用句法路径识别评价关系
要想确定某一评价对象与某一评价词语是否具有语义关联或者指向关系,需要判定两者句法路径是否合法,即是否在一个从句IP 之内。图2 所示句子“手机性能很好,发货速度快,外观好看,就是指纹解锁不灵敏”中含有候选评价对象“手机性能”“发货速度”“外观”“指纹解锁”与评价词语“很好”“快”“好看”“不灵敏”,它们可能存在如图3 所示的评价关系。其中多数为不合法的句法路径,如评价词语“很好”和候选评价对象“发货速度”两者的句法路径为“很好↑VA↑VP↑VP↑IP↑IP↓IP↓NP↓NN↓发货速度”,不在一个IP 之内是不合法的,应予以排除。对于评价词语和候选评价对象之间存在合法句法路径的,可以进一步判断两者是否具有评价关系,分为三种情况:1.评价对象为主语,评价词语为谓语;2.评价对象为宾语,评价词语为后指动词;3.评价词语为修饰语,评价对象为中心语。
(一)评价对象为主语,评价词语为谓语
例3:手机说实话很一般,什么超声波解锁也很垃圾。
path:手机↑NN↑NP↑IP↓VP↓VP↓VA↓一般
fromWord:手机 toWord:一般
path:超声波↑NN 解锁↑NN↑NP↑NP↑IP↓VP↓VP↓NP↓NN↓垃圾
fromWord:超声波解锁 toWord:垃圾
例句3 的短语结构树如图4 所示,图中加粗的黑线表示评价词语和评价对象之间合法的句法路径。第一个小句中主语即评价对象“手机”,核心评价词语为“一般”。两者之间还有程度副词“很”,插入语“说实话”(句法分析器无插入语标记,故标注为副词),评价对象和核心评价词语之间的句法路径为“手机↑NN↑NP↑IP↓VP↓VP↓VA↓一般”。所以副词或者插入语不会影响主语谓语之间的句法路径,仍包含“NP↑IP↓VP”。同样第二个小句中,主语为评价对象“超声波解锁”,核心评价词为“垃圾”,句法路径为“超声波↑NN 解锁↑NN↑NP↑NP↑IP↓VP↓VP↓NP↓NN↓垃圾”,所以谓语“垃圾”与主语“超声波解锁”构成评价关系。

图4 例句3 的短语结构树
(二)评价对象为宾语,评价词语为后指动词
例4:小米不错,便宜好用,我就是讨厌华为的海军才买小米的。
path:讨厌↑VV↑VP↓NP↓NP↓NN↓华为的海军
fromWord:讨厌 toWord:华为的海军
例句4 的短语结构树如图5 所示。第一个小句“小米不错,便宜好用”为主谓句句式,主语即评价对象“小米”,评价词语“不错”“便宜”“好用”同时指向“小米”。第二个小句“我就是讨厌华为的海军才买小米的”,评价词语为谓词“讨厌”,指向的对象为宾语“华为的海军”,所以评价对象为宾语“华为的海军”,第二个小句的句法路径为“讨厌↑VV↑VP↓NP↓NP↓NN↓华为的海军”,路径起始节点的评价词“讨厌”为后指动词作谓语,路径终止节点“华为的海军”为后指动词的宾语,路径包含“VV↑VP↓NP”,为合法路径,所以谓语“讨厌”与宾语“华为的海军”构成评价关系。
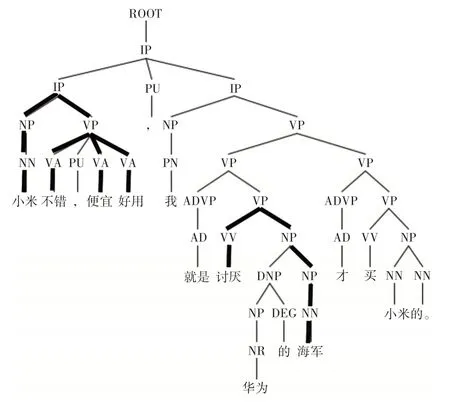
图5 例句4 的短语结构树
(三)评价对象为中心语,评价词语为修饰语
例5:很不错的手机,性价比高。
path:很不错↑JJ↑ADJP↑ADJP↑DNP↑NP↓NP↓NN 手机
fromWord:很不错 toWord:手机

图6 例句5 的短语结构树
例句5 的短语结构树如图6 所示。第一个小句“很不错的手机”为NP 短语,定语“很不错”和其指向的中心语“手机”两者之间句法路径为“很不错↑JJ↑ADJP↑ADJP↑DNP↑NP↓NP↓NN 手机”,路径起始节点的评价词“很不错”为修饰成分作定语,路径终止节点“手机”中心语,路径包含“DNP↑NP↓NP”为合法路径,所以修饰语“很不错”与中心语“手机”构成评价关系。
三、实验及结果
(一)评价单元抽取
实际应用中,需要将具有评价关系的评价对象和评价词语组合成评价单元,评价单元为三元组形式〈评价对象,评价词语,情感极性〉。因此获取合法路径后,抽取路径起始节点和终止结点,并判断两结点哪个为评价对象,哪个为评价词语,将评价词语的情感极性也写入,最后组成三元组形式,如下所示。
例6:手机很好,轻巧,京东送货速度很快。
评价单元:〈手机,很好,1〉
〈手机,轻巧,1〉
〈京东送货速度,很快,1〉
(二)京东手机商品评论分析实验
实验语料为京东商城某品牌手机商品评论,针对1000 条商品评论人工标注了〈评价对象;评价词语;情感极性〉三元组答案。依据本文方法所建立的系统为CUCeval,对比系统为中国传媒大学有声媒体中心CUCsas 系统,对比系统CUCsas 曾在2013 年中国计算机学会(CCF)主办的第二届自然语言处理与中文计算会议(NLPCC2013)微博观点句评价对象抽取及褒贬极性判定评测任务中取得了第一名。实验结果如表2 所示。
与对比系统相比,本文系统CUCeval 的准确率、召回率、F1 值均大为提高。回查实验数据,发现本文方法主要存在以下四方面优势:

表2 京东手机商品评论分析实验结果
第一,容错率更高。商品评论语言较不规范,很多句子或者缺少标点或者之间无标点等。本文方法以句法结构为依据,标点符号只是形式上的分隔,不能割裂句法结构,句法路径仍然不会变化。如“手机挺好,就是充电口不一样,有点不方便”中评价词语“不方便”与评价对象“充电口”之间虽然间隔“,”,但“有点不方便”是“充电口”的谓语VP,两者之间的句法路径不会变化。
第二,评价对象边界识别准确率更高。评价对象边界的识别主要为名词短语组块的识别,这实际上是句法分析的任务,利用较为成熟的短语结构句法分析,就会取得较好性能。
第三,避免了规则冲突问题。基于句法语义规则的系统容易出现规则众多、规则之间相互冲突的情况。本文系统抽取评价单元依赖句法路径筛选,规则较少,避免了此类情况,性能较稳定。
第四,远距离搭配识别准确率更高。评价对象和评价词语之间距离较远时,两者间的评价关系较难抽取。如“机子还不错,只是没有配耳机、钢化膜和保护套不太满意”中评价词语“不太满意”指向三个评价对象“耳机”“钢化膜”“保护套”,其中“耳机”和“不太满意”间隔较远,借助短语结构句法分析,能够有效的识别出“耳机”“钢化膜”“保护套”具有共同的谓词“不太满意”,成功抽取评价关系。
四、结 语
本文提出利用相对成熟的短语结构句法分析进行评价关系识别,并在商品评论分析实验中取得了较好的结果。但是商品评论语言结构比较简单,无论是评价对象还是评价词语颗粒度均较小,句式上也多为简单句,而人类的语言丰富多彩,在涉及人物、事件的评价时,往往采用更加隐晦、间接的评价方式,例如新闻、娱乐等领域的评论语言,此时评价分析的结果往往不尽如人意。因此,评价关系的识别仍然有许多值得进一步探索与研究之处,以下列出可能的几个方面:
1.比较句的评价对象抽取。本文没有对比较句进行研究,在此认为比较句应该单独研究。比较句的评价对象抽取工作重点在于,第一,抽取两个比较对象或者多个比较对象;第二,抽取比较结果,即判断两个或者多个比较对象哪个更优。
2.领域情感词典的自动构建。本文评价词语的抽取及褒贬极性判定均依赖于通用情感词典,实验语料也只有1000 条,当需要分析涉及众多领域的海量规模的商品评论时,通用情感词典显然不能满足需求,将导致某些领域情感词无法识别,因此领域情感词典的自动构建尤为重要。
3.混和语法分析。本文候选评价对象的抽取主要依赖短语结构句法分析器,短语结构语法的优势是名词组块边界识别较准确,组块内部的识别错误不影响评价对象的抽取,这点优于依存句法分析,但依存语法通过依存关系分析能够更加准确地判断评价对象与评价词语的指向关系。因此,如果对评价句进行混和语法分析,使用短语结构语法抽取评价对象,使用依存语法确定评价对象与评价词语的指向关系,可能获得更高的准确率。
猜你喜欢
大连民族大学学报(2021年2期)2021-07-16
时代英语·高一(2019年5期)2019-09-03
天然产物研究与开发(2018年9期)2018-10-08
中华诗词(2018年3期)2018-08-01
中华诗词(2018年11期)2018-03-26
天然产物研究与开发(2016年1期)2016-06-05
海峡姐妹(2016年2期)2016-02-27
当代修辞学(2014年3期)2014-01-21
数理化学习·高一二版(2009年2期)2009-03-30
