
大庆油田类比油藏库建立及其在可采储量评价中的应用
2020-12-11 08:17王禄春杨吉祥
石油地质与工程 2020年6期
王禄春,杨吉祥,姚 建,关 恒
(中国石油大庆油田有限责任公司勘探开发研究院,黑龙江大庆 163712)
在国内油田新动用储量区块可采储量评价中, 使用较广泛的方法是静态法,即首先根据经验公式计算采收率,再通过地质储量和采收率计算可采储量[1-6]。目前石油可采储量计算行业标准(2010)针对不同的油藏类型建立了相应的经验公式[7-10],大庆油田也在“十一五”期间针对外围葡萄花、扶杨油层建立了经验公式,满足了当时新区可采储量评价工作的需要。但是,随着油田开发的深入,开发对象的变化,经验公式法已经不能完全满足目前储量评价的需要。一是经验公式法是通过多个样本建立的回归公式,应用到某一具体油藏的时候存在着适应性较差的问题;二是部分参数范围已经不再适用,通过对2010 年以来投产的21 个区块参数的统计发现,其中20%左右的区块参数范围已超出原经验公式参数范围。由于经验公式法在计算采收率过程中存在的问题,近年来,在国内可采储量标定时,也逐步借鉴SEC 储量的评估规则,提倡加大类比法在新动用储量区块评价中的应用[11-12]。为此,针对大庆油田实际,建立了类比油藏数据库,类比法在评价工作中得到了较好的应用。
1 类比油藏库建立
1.1 类比油藏优选
根据石油可采储量计算行业标准(2010)关于类比油藏序列建立的要求,结合大庆油田实际,综合考虑地质、开发等方面因素,类比油藏的选择主要考虑三个方面:①地质储量计算结果合理,开发后储量通过复算、核算及动态法计算等检验合理;②开发单元有一定规模、井网基本完善、注水方式合理;③开发时间较长(投产时间一般大于 3 a)、规律性较好(具有连续12 个月以上的稳定递减趋势)。
为了实现“全覆盖”,优选102 个类比油藏,建立大庆油田低渗透类比油藏全序列数据库。
1.2 可采储量评价
由于各开发单元生产时间较长,递减规律较好,所以应用递减曲线法对筛选出来的102 个类比油藏区块的可采储量进行重新计算,进而重新计算采收率。根据 Arps 指数递减曲线进行可采储量评价,首先把所有的实际产量和累计产量数据绘制在直角坐标系中,然后判别、选定产量递减曲线的直线段及对应数据点对选定的直线段进行线性回归,当年产量为零时的累计产量即为技术可采储量。
1.3 类比油藏库聚类及判别分析
1.3.1 采收率的影响因素
影响采收率的因素很多,包括地质特征、流体性质、开发方式、管理水平等,根据油藏工程原理,并结合专家经验,初选了102 个类比油藏的有效厚度、孔隙度、流度等8 项指标作为研究对象,应用多元线性回归方法确定主控因素(表1)。
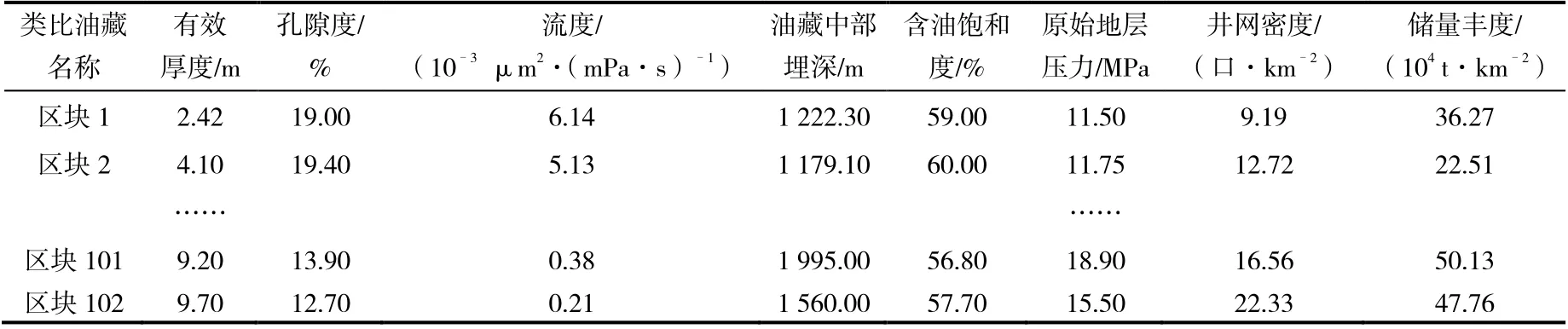
表1 影响类比油藏采收率的主要参数



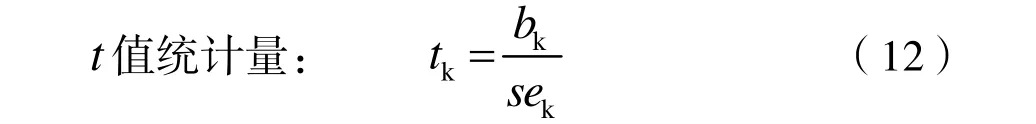
式中:sek为每个回归系数的标准误差。
经过6 轮回归,依次排除了有效厚度、储量丰度、原始地层压力、含油饱和度、油藏中部埋深等5项因素。最终,确定影响采收率的主要因素为井网密度、流度和有效孔隙度。按照偶然性判断标准,F=22.07,F临界=1.73,F>F临界说明整个回归方程是线性显著;t临界=1.984 5,各项因素t 观察值均大于临界值,说明各个因素也都是显著影响因素(表 2)。
1.3.2 聚类分析
聚类分析又称群分析,是研究(样品或指标)分类问题的一种多元统计方法,主要包括参数录入、标准化处理、求取样本距离、进行系统聚类、生成聚类图等几个主要步骤。由于聚类分析方法比较复杂,编写了聚类分析程序以便进行分类研究。完成了66个单采X 油层区块及36 个单采Y 油层区块的聚类分析。
(1)X 油层:66 个区块,共分成3 类(表3)。
(2)Y 油层:36 个区块,共分成3 类(表4)。
整体看,X 油层采收率好于Y 油层。两类油层采收率主要分布在15%~20%(表3、表4)。

表2 多元线性回归采收率主要影响因素确定

表3 单采X 油层区块分类参数

表4 单采Y 油层区块分类参数表
1.3.3 判别分析
判别分析是判别样品所属类型的一种统计方法。是在已知研究对象分成若干类型(或组别)并已取得各种类型的一批已知样品的观测数据,在此基础上根据某些准则建立判别式,然后对未知类型的样品利用Fisher 判别法进行判别分类。
(1)X 油层判别函数(表5)。
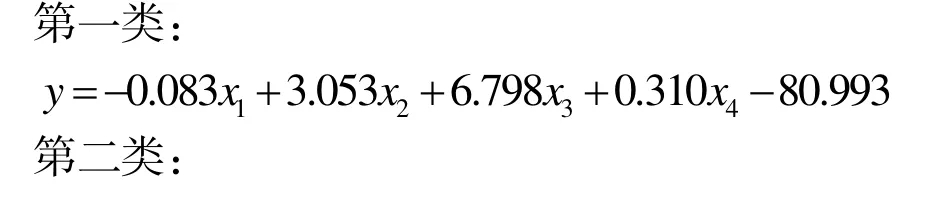
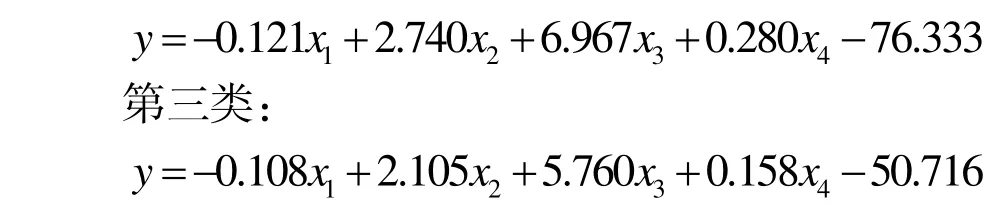
式中: x1为空气渗透率,%; x2为地层原油黏度,mPa·s; x3为孔隙度,%; x4为井网密度,口/km2。
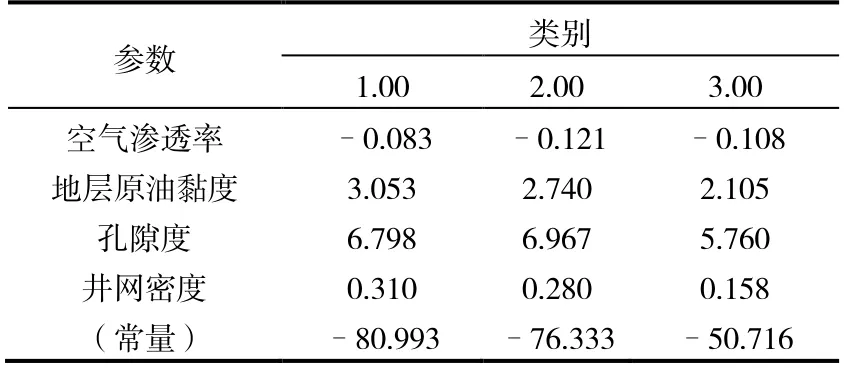
表5 Fisher 的线性判别式函数参数
从典则判别函数上看,类间界限明显(图1)。
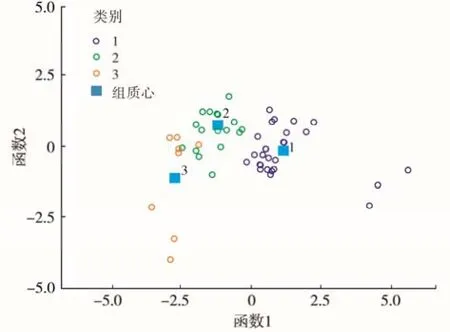
图1 典则判别函数
(2)Y 油层判别函数(表6)。

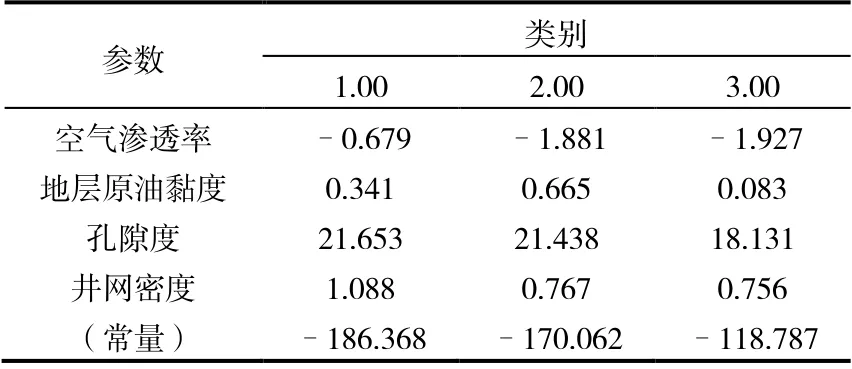
表6 Fisher 的线性判别式函数参数
从典则判别函数上看,类间界限明显(图 2)。
1.3.4 相关度分析
明确目标油藏属于哪一类之后,还需从类比油藏序列数据库中选择与目标油藏最为相似的区块作为类比油藏区块,应用数组相关性函数进行判别。
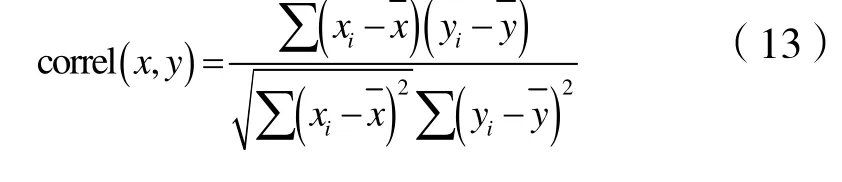
式中:xi为数组X 第i 个样本,x为数组X 样本平均值;yi为数组Y 第i 个样本,y为数组Y 样本平均值。
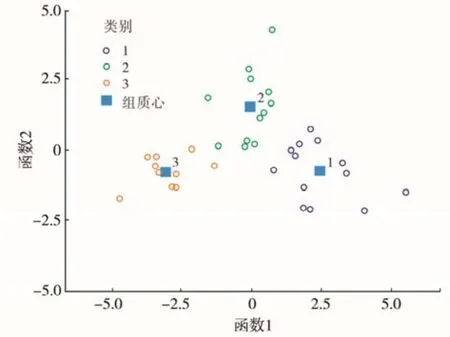
图2 典则判别函数
2 实例
以某区块A 油藏为例,该区块隶属于X 油层,按照X 油层Fisher 判别式的结果:属于第一类的概率为90.79%,属于第二类的概率为88.60%,属于第三类的概率为81.57%。因此,判断A 油藏属于X 油层第一类。
应用数组相关性函数计算A 油藏和X 油层第一类的各区块相关度,按照相关度最高原则选择区块1 油藏作为类比油藏(表7)。
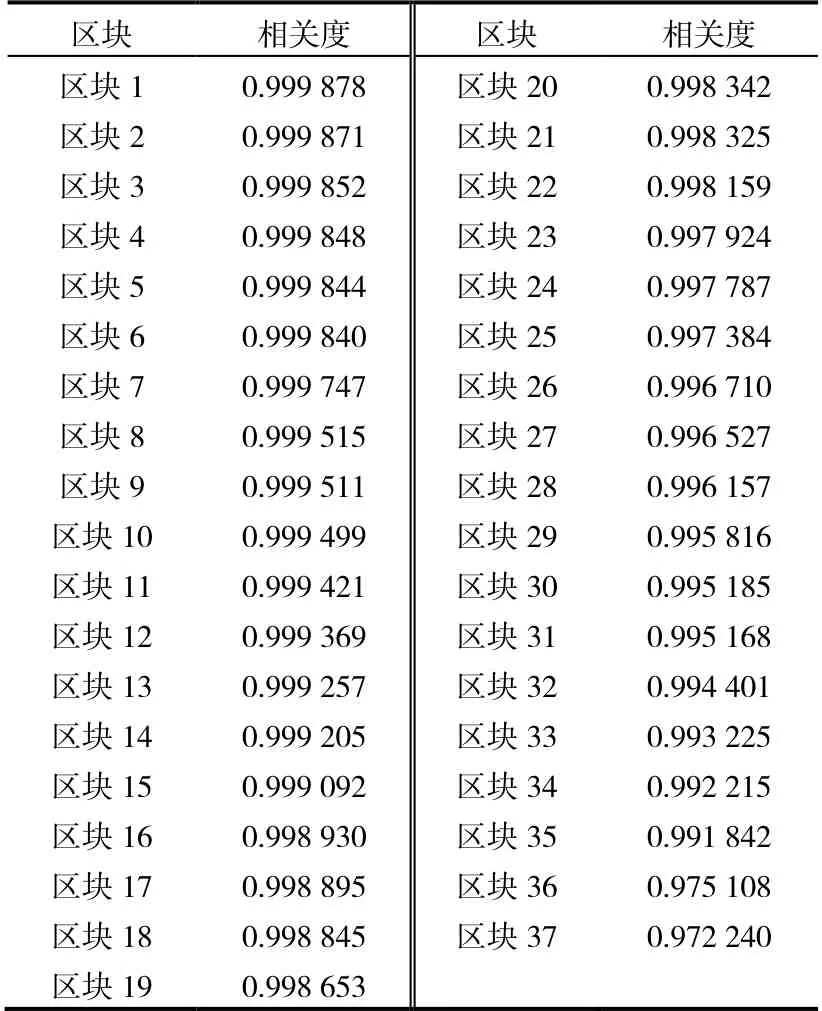
表7 区块A 目标油藏与类比油藏相关度对比
区块1 油藏地质储量为 430.55×104t,应用递减法评价可采储量为69.75×104t(图3a),计算采收率为16.2%,所以应用类比法确定区块A 油藏采收率为16.2%。区块A 油藏地质储量为169.12×104t,应用递减法评价可采储量为25.88×104t(图3b),计算采收率为 15.3%,与类比法确定采收率比较接近,证明类比法计算结果较可靠。
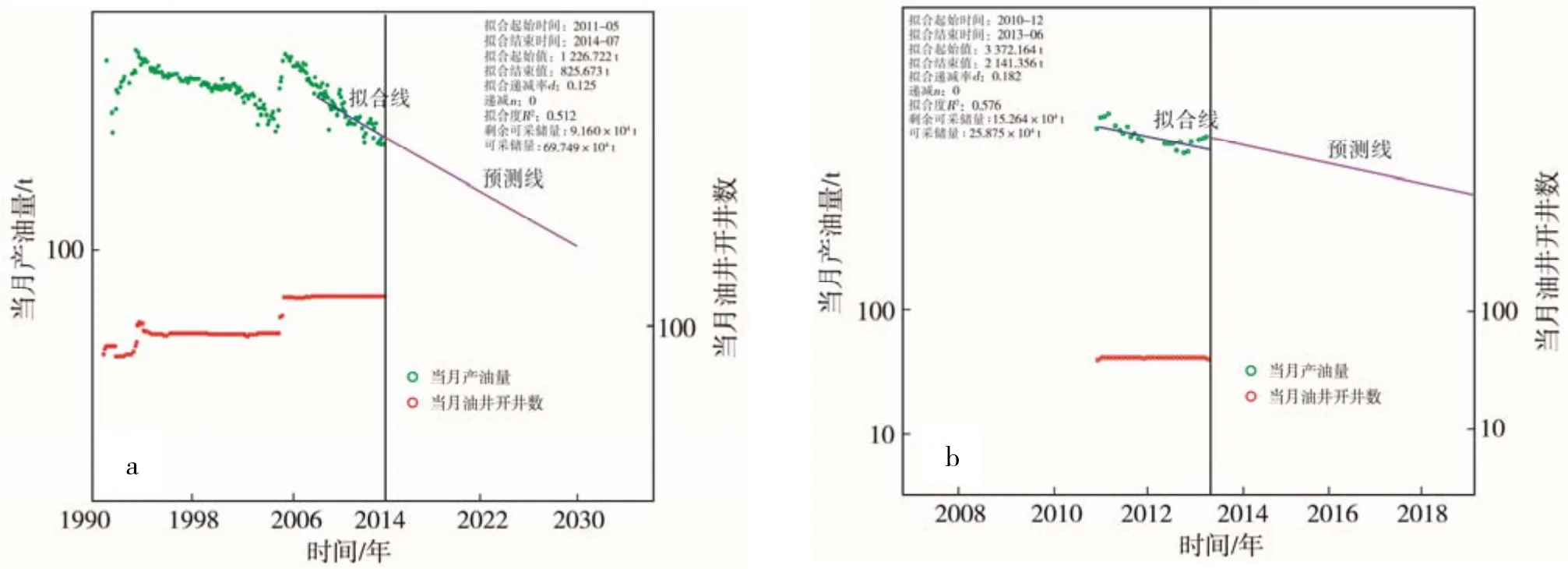
图3 递减法评估可采储量曲线
3 结论
(1)类比法是通过类比成熟油藏确定采收率的一种方法,由于类比油藏与目标油藏具有相同或相近的地质特征及开发方式,且具有开发时间长、动态法计算可采储量准确度高等特点,所以在可靠性和适应性方面要优于经验公式法。
(2)通过单元优选及可采储量重新评价,应用油藏工程及数理统计等方法优选大庆油田102 个开发油藏建立类比油藏序列数据库,应用多元线性回归确定了影响采收率的主要因素为流度、有效孔隙度和井网密度3 项。
(3)类比法是通过对类比油藏进行聚类分析,并利用Fisher 判别法建立分类判别函数,应用数组相关性分析优选与目标油藏最为接近的类比油藏。经实例验证,应用类比法确定采收率结果与动态法接近,误差较低,精度控制较好,能满足生产的实际需求。
猜你喜欢
油气地质与采收率(2022年5期)2022-09-15
油气地质与采收率(2022年3期)2022-05-20
油气地质与采收率(2021年4期)2021-08-04
油气地质与采收率(2021年4期)2021-08-04
景德镇陶瓷(2021年3期)2021-07-03
油气地质与采收率(2021年3期)2021-06-02
文史春秋(2019年10期)2019-12-21
当代化工(2019年2期)2019-12-10
中国高新技术企业(2015年26期)2015-08-14
中国高新技术企业(2015年29期)2015-08-11
