
电池材料数据库的发展与应用*
2020-12-05 07:33吴思远王宇琦肖睿娟陈立泉
物理学报 2020年22期
吴思远 王宇琦 肖睿娟† 陈立泉
1) (中国科学院物理研究所, 清洁能源实验室, 北京 100190)
2) (中国科学院大学, 北京 100049)
基于自动化技术和计算机技术的高通量方法可快速提供数以万计的科研数据, 对如何科学、高效的管理科研数据提出了新的挑战. 可充放的二次电池作为一种清洁高效的能源存储器件, 是电动汽车发展的关键,也是风/光电储能的首选. 电池器件性能的提升与电池新材料的研发密切相关, 电池材料数据库的发展可在电池材料研发中引入基于大数据的新兴方法, 加速电池材料的开发. 本文从电池材料数据的获取、通用型及特定性质的电池材料数据库构建、大数据方法对电池材料研发的促进和发展电池材料数据库所面临的挑战等方面对电池材料数据库的发展和应用进行了介绍.
1 引 言
在材料研发的诸多领域中, 锂二次电池材料的开发对于能源的清洁高效利用及环境的可持续发展十分重要[1]. 当前锂电池产业面临的关键问题是开发出全新的锂电池材料以提升下一代锂二次电池的能量密度、功率密度和安全性能[2]. 近年来“材料基因组”作为一种新的研究方法, 有效地加速了材料从研究到应用的进程, 降低了材料研发的成本[3,4]. 基于材料基因组思想的高通量技术为科学研究提供了大量的数据, 也对如何高效、完备的管理和使用科研数据提出了挑战, 建立高通量材料研究的相关数据库将有效加速新材料的探索和研发,并将为材料研究领域中引入机器学习、数据挖掘等人工智能技术奠定基础. 目前材料数据库的研究主要涉及材料数据的产生、归类和应用三个方面, 如图1 所示. 数据的来源包括实验数据和计算数据,除了文献和已有资料中可收集的大量数据外, 高通量实验和高通量计算也提供了越来越可观的数据;对于收集的数据通常需要根据其获得方式、精确程度和所关联的物性等进行归类, 为数据匹配相应的标签, 以实现数据库的建立; 从构建数据库的数据中, 可以根据应用需求直接筛选符合条件的材料,也可以通过大量的材料学数据借助机器学习算法来挖掘材料宏观性质与微观结构之间的关联. 随着大量材料数据的出现和人工智能算法的优化, 材料数据库在未来协助研究人员优化和设计电池新材料方面将发挥越来越显著的作用[5-7].
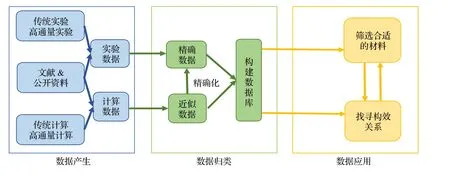
图1 材料数据的产生、归类和应用流程Fig. 1. Flowchart of creation, classification and application of materials data.

图2 各类材料数据库的出现时间Fig. 2. Appearance time of various materials databases.
图2 显示了几种具有代表性的材料数据库的出现时间. 这其中以按照材料类型建立的数据库为主, 例如为具有某种共同用途或具有某种共同结构特征的材料建立的数据库, 包含每种材料的多种物理、化学等性质[8-10]; 也有以某种特定材料性质建立的数据库, 例如针对离子在固体中传输性质的数据库[11,12]. 早期的材料数据库常常是针对一类材料的一个具体性质, 例如钙钛矿结构铁电材料的声子性质数据[13], 非线性光学材料的阴离子基团性质等[14]; 在2000 后, 逐步出现了热电材料、半Heusler半导体、沸石材料和拓扑材料等各类材料数据库[15-18]; 近十年来, 随着自动化高通量计算的发展, 目前已实现了对无机晶体数据库中大量已知结构化合物的计算, 因此出现了Materials Project,AFLOW, OQMD, Atomly 等多个包含各种可计算物性的通用型材料计算数据库[19-22].
可充放的二次电池作为下一代储能器件的首选, 受到了人们的广泛关注. 建立数据信息丰富的电池材料数据库将有助于研究人员从数据获取、数据挖掘和数据预测各个阶段实现电池新材料的探索. 正确认识材料结构与性能之间的关系, 可以合理的筛选、优化和设计新材料, 进而加速材料从研发到应用的过程, 降低材料的开发成本. 本文将在第二部分介绍电池材料数据的来源及通用型和特定性质型的电池材料数据库; 第三部分介绍目前使用电池数据进行材料筛选和机器学习的进展; 第四部分介绍发展电池材料数据库所面临的挑战.
2 电池材料数据库的构建
2.1 电池材料数据的获取
与图1 所展示的各种材料数据的获取方式相似, 电池材料的数据也主要来源于实验和计算两个方面. 实验数据的收集和整理主要来源于已发表的各类文献, Ghadbeigi 等[23]从科技文献中手工收集了大量电池材料数据并构建了数据库. 计算机技术的发展, 特别是基于自然语言的文本挖掘功能的实现, 显著加快了从已发表文献中获取实验数据的自动化进程. Huang 和Cole[24]采用自行编写的Chem-DataExtractor 建立了从文献中自动收集电池数据的方案, 构建了总条目29 万余条, 包含容量、电导率、库伦效率、能量密度和电压共五种性质的数据库.
理论模拟也为电池材料提供了丰富的数据集.电池的模拟包括在原子分子尺度、微观尺度和器件在宏观尺度上电池各类性质进行模拟. 如分别采用原子尺度的DFT 和DFTB 计算从电荷转移角度以及采用有限元的微观尺度从Li 浓度梯度引发的应力应变等来阐述界面问题[25,26]. 近年来快速发展的高通量计算主要是基于密度泛函理论的高通量计算, 通过设计一系列运算流程, 实现对材料原子尺度本征性质的大批量自动化计算. 材料中各种不同的物性会涉及到不同的计算方法, 表1 列出了目前已实现高通量化计算的各种材料性质. 针对电池材料的反应机制, 还可通过热力学数据获得各种材料的理论能量密度, 为实际分析和筛选电极材料提供参考. Peng 等[27]与Zu 和Li[28]分析了过去60 年电池能量密度的增长趋势并计算了不同体系Li,Na, Mg, Al 和Zn 电池的理论能量密度; Wu 等[29]使用电池材料的基本数据计算了不同18650 电芯的实际能量密度; Wang 等[30]计算了不含锂的正极材料的嵌锂性能, 得到其理论能量密度; Cao 等[31]收集了理论能量密度高的材料的热力学数据, 用于寻找高能量密度电极.
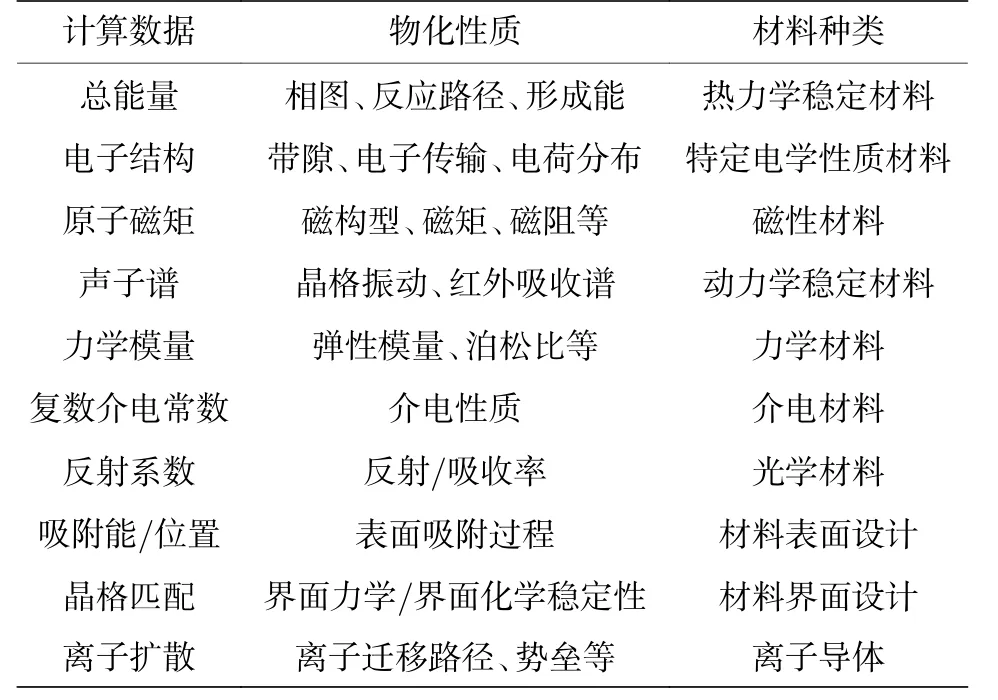
表1 高通量计算所能获得的材料性质Table 1. Properties achieved by high-throughput calculations.
在数据的获取过程中, 需要关注数据产生的条件和数据的误差[32,33]. 对于实验数据, 测量环境(如温度、压力等)和测量方法常常会影响数值的大小, 那么后续的数据挖掘则需要对数据进行归类,在相同条件下测量的数据间可以进行更为科学的比较. 对于理论模拟的数据, 设定相同模拟参数则较为容易, 例如在基于密度泛函的高通量计算中,通过设定相同的关联函数、积分密度和收敛条件等参数, 可以将数据的准确度控制在相同的范围. 实验数据与计算数据相结合的数据库构建思想目前获得了广泛的认同[34,35]. 数据类型的全面和准确是进一步对电池材料数据进行大规模分析和挖掘的基础.
2.2 典型的材料计算数据库
电池材料的诸多性质中, 脱/嵌锂电位、热力学稳定性和化学稳定性等均可从密度泛函计算得到的能量、电子结构等信息中获得[36], 因此包含高通量密度泛函计算结果的通用型材料数据库都可用于电池材料本征性质的研究. 国际上已有多个研究团队推出了包含体系能量、能带结构、力学模量和热力学相图等信息的材料数据库, 其材料结构的来源既包括无机晶体数据库中已有物质, 也包括大量由已有物质衍生出的虚拟结构, 为发现新材料提供了条件. 表2 列出了几种公开的通用型材料数据库及用于构建该数据库的高通量计算软件. 其中Materials Project 数据库除了收录密度泛函的计算数据外, 还开发了将基本计算数据转化为电池性质数据的模块, 可获得电压曲线、理论容量、不同锂化学势下的稳定性等用于电池材料研发的数据,可通过Battery Explorer 模块进行查找. Atomly数据库是中国原创的材料数据库, 包含14 万余种材料的电子结构信息和4 万余组热力学相图信息,且含有通过机器学习获得的势函数, 可有效加速分子动力学的模拟进程, 有望为电池材料提供大量动力学方面的研究数据[22].
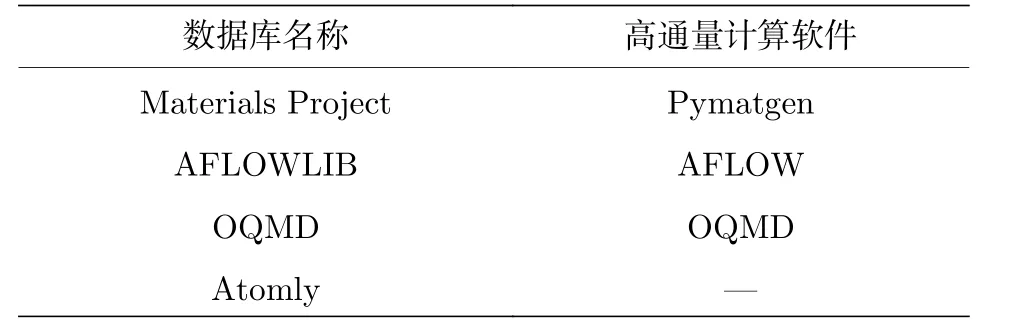
表2 国内外典型的通用型计算材料数据库及公开发布的高通量计算软件[19-22]Table 2. Typical database forcomputational materials[19-22].
除了从通用型的材料数据库中获取电池材料信息外, 还有为电池材料某一特定性质构建的数据库, 其中以几何和半经验方法计算得到的锂离子输运动力学数据库为主, 包括我们在2018 年推出的电池材料离子输运数据库[11]和上海大学2020 年上线的离子传输特征数据库[12,37]. 电池材料的离子输运性质与电池器件的充放电速率密切相关, 也是开发新型固体电解质的主要指标之一. 实验中常通过电化学阻抗谱或核磁共振光谱来获取材料的离子传输信息, 理论方法对离子输运现象的模拟则经历了由晶体中几何空间进行预估[37-39]、通过半经验势函数进行估算[40]和采用基于密度泛函的过渡态方法精确计算[41]的几个阶段. 精确计算所需的计算量较大, 为了在初始阶段实现大规模的材料筛选, 基于半经验势函数的键价方法由于能给出离子输运势垒的变化趋势, 因此被用来作为快离子导体初筛的方法之一. 我们用高通量键价计算的结果构建了电池材料离子输运性质数据库[11]. 如图3(a)所示, 该数据库包含了采用键价方法计算得到的21204 种无机晶体化合物中的离子输运势垒, 其中包括含Li 的化合物4535 种, 含Na 的化合物4344 种, 含K 的化合物2808 种, 含Mg 的化合物2145 种, 含Zn 的化合物2180 种、含Al 的化合物5192 种. 目前该数据库具备三种便捷的查询方式,包括根据化合物的元素组成进行查询、根据化学式进行查询、根据离子输运类型及离子迁移势垒的数值范围进行查询. 利用该数据库可快速排除已知结构化合物中离子迁移势垒较高的物质, 为进一步探寻快离子导体有效地缩小了范围. 同时, 如图3(b)所示, 数据库所包含的大量化合物中, 不仅有迁移势垒小的结构, 也有迁移势垒大的结构, 这为后续的数据挖掘和机器学习提供了完备的样本集. 上海大学施思齐研究组[37]则采用几何分析的方法, 利用Voroni多边形镶嵌模型寻找扩散路径并编写了CAVD 程序, 为进一步使用第一性原理NEB 计算势垒构建了初始输入文件[39].

图3 (a) 电池材料离子输运数据库网站页面; (b) 数据种类Fig. 3. (a) The database of ion transport properties for battery materials; (b) data distributions for various types of materials.
3 电池材料数据库对材料研究的促进
3.1 利用材料数据库进行新材料的筛选设计
材料数据库的建立可以帮助我们加深对已有材料的理解, 发现具有目标物性的新材料. 当人们对某一性质所对应的原子结构或电子结构特征已有清晰认识时, 可以从数据库中直接寻找具有这一特征的化合物. 例如: 在确认非线性光学材料的性质与阴离子基团结构的关联后, Avdeev 等[14]通过寻找具有特定阴离子点群特征的结构来寻找新的非线性光学材料; 在发现了电子结构特征与材料拓扑性质的关联后, Zhang 等[18]发现了数千种新的拓扑材料. 另一种筛选方式是直接计算出目标物性, 选出达到应用要求的材料, 电池材料的筛选大多使用这种直接筛选的方式. 例如Kirklin 等[42]从515 种硅化物、锡化物和磷化物中以电化学势、体积变化和容量为标准筛选出CoSi2, TiP, NiSi2等几种性能优于石墨的负极材料; Zhu 等[43]以锂电势和热力学稳定性为标准筛选出对金属锂负极稳定的化合物; Wang 等[44]以离子输运势垒为标准筛选出可以提高Li3PS4离子电导率的氧掺杂和锌氧共掺杂方案.
3.2 利用材料数据库进行构效关系的挖掘
随着高通量计算和高通量实验带来的材料大数据的出现, 机器学习成为探索材料的微观结构与宏观性质之间关联的新方法. 使用机器学习方法探究材料中的构效关系, 是借助数据挖掘算法在所关注的目标物性与材料的组分、结构等变量间建立映射关系. 如图4 所示, 对于电池材料而言, 目标物性可以是嵌锂电位、电子电导、脱嵌锂体积变化、离子迁移势垒等各种为满足应用需求所要达到的物性; 用于描述材料的组分、结构的变量称为描述因子, 研究人员可以根据对于材料的认识来进行构建, 例如用晶格参数、对称性等描述其晶体构造,用配位数、键长、键角等描述局域化学环境等.Sendek 等[45]通过选择锂离子周围配位数、配位距离等描述符并利用机器学习中的多元线性回归算法判断各种晶体结构作为锂电池固态电解质材料的可能性; Liu 等[46]利用支持向量机算法, 探究了掺杂元素化合价、掺杂离子半径、掺杂元素泡利电负性等描述因子与锂电极/固态电解质界面稳定性之间的关系. 表3 中列举了采用机器学习方法研究二次电池中各类构效关系的实例, 可以看出, 这种基于大数据的分析方法可广泛应用于固态电解质、聚合物电解质、电极/电解质界面和电池制造等各方面的研究.
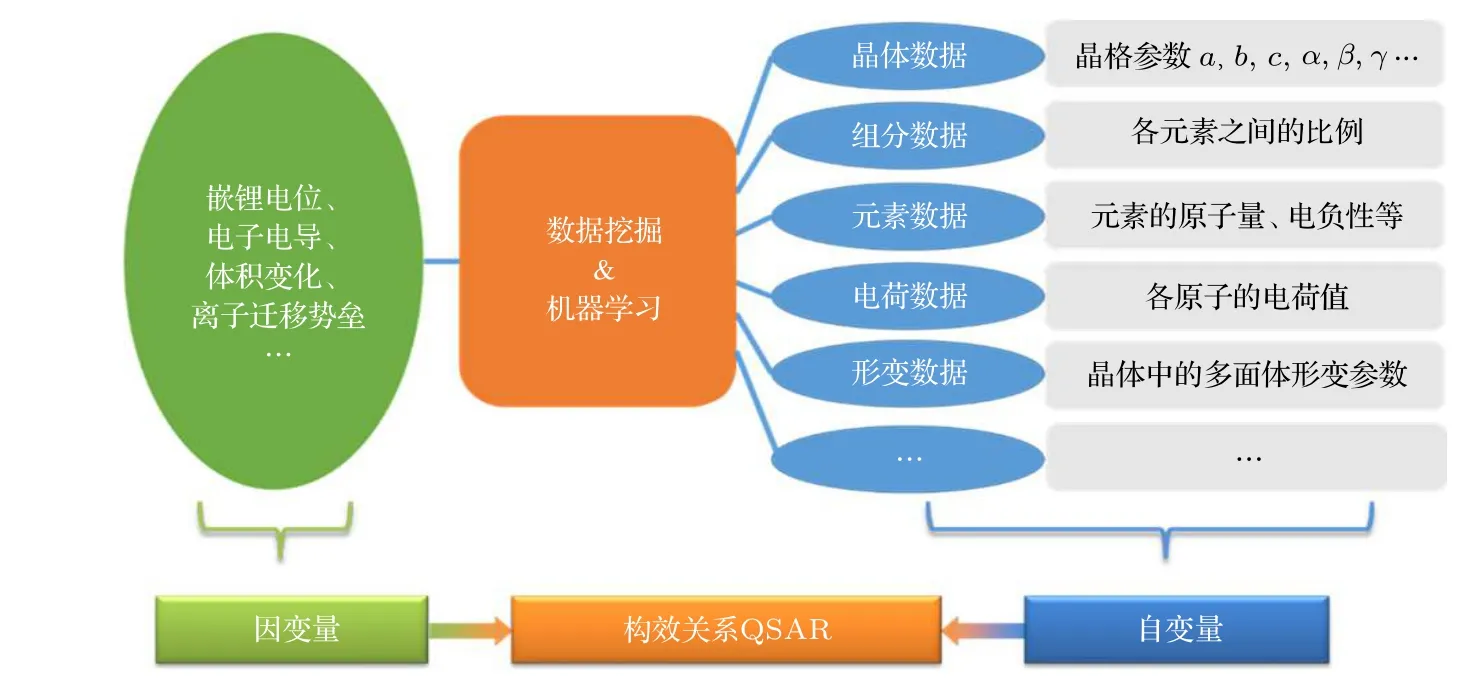
图4 数据挖掘方法在探究材料构效关系中的应用Fig. 4. Data mining method applied in exploring the relationship between structure and properties.
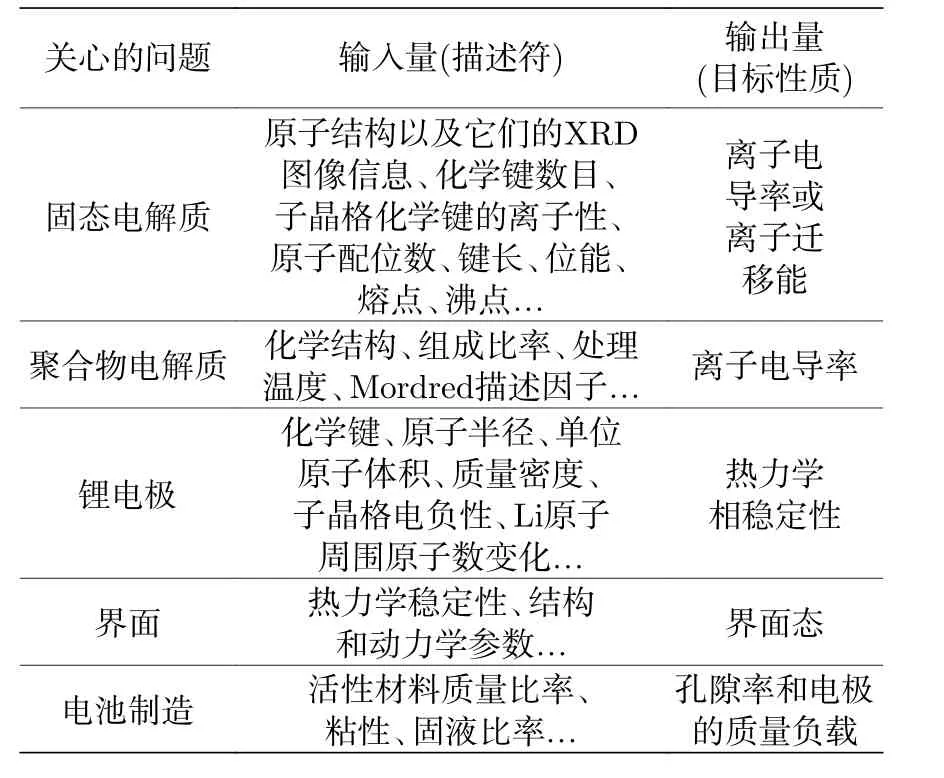
表3 机器学习模型应用于二次电池的构效关系Table 3. Application of machine learning method in the research of secondary batteries.
4 发展电池材料数据库的挑战
4.1 建立面向应用的电池材料数据库
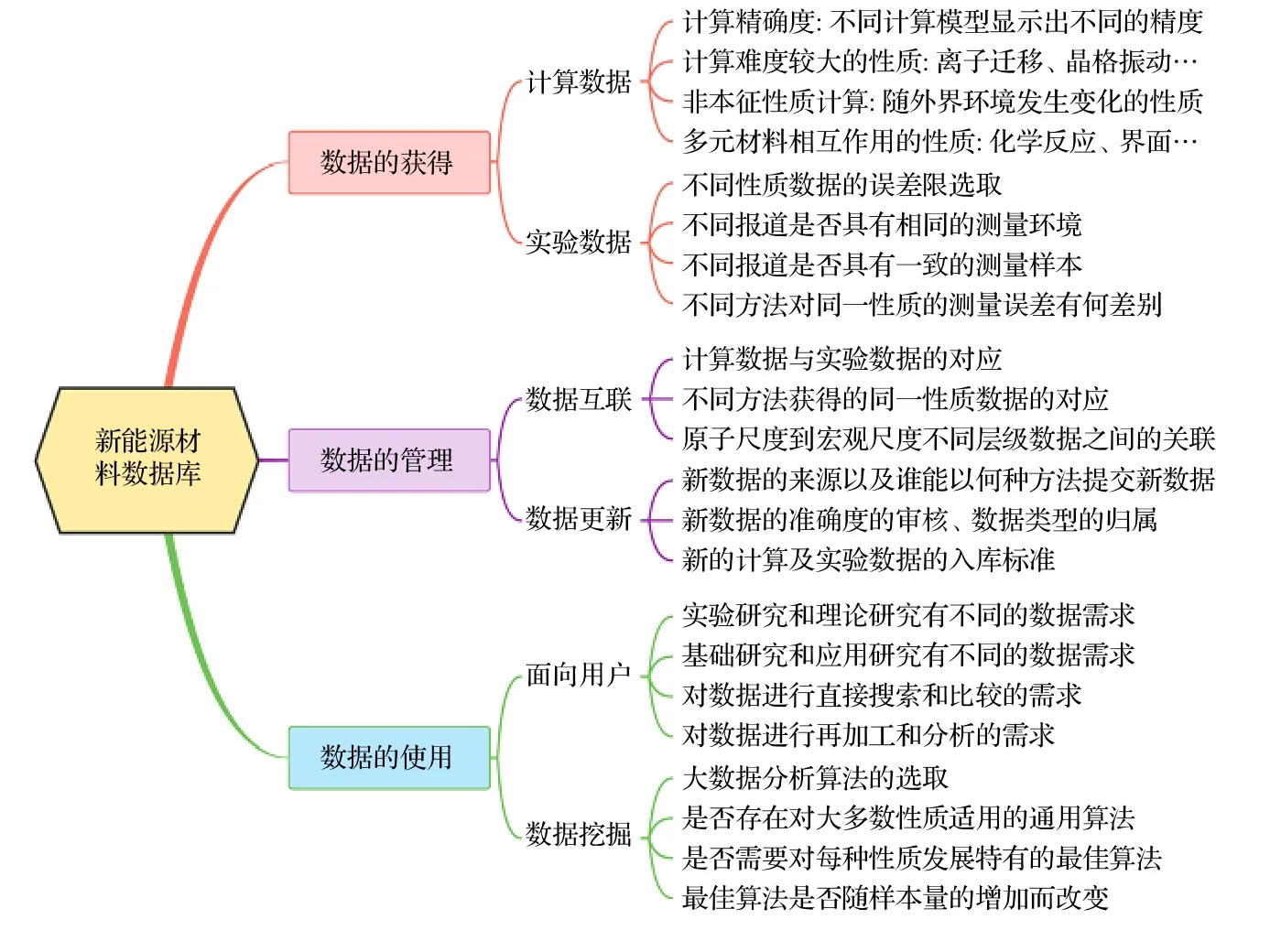
图5 新能源材料数据库的主要技术挑战Fig. 5. The main technologic challenges in the development of energy materials database.
电池材料数据库需面向各类科研及工业开发,因此在数据获取、数据管理和数据使用方面要兼顾多种应用场景. 图5 列举了电池材料数据库在构建过程中需要优化的各个方面. 数据的获取无论是计算数据还是实验数据, 都需要关注数据的误差范围和获取条件. 对于数据管理, 需考虑不同方法所获得的数据之间如何对应、不同空间或时间尺度的数据之间如何关联、在数据更新过程中如何检验数据的准确度等问题. 对于数据使用, 一方面需要提供快捷高效的搜寻方式供各种需求的使用者便利地获取所需数据; 另一方面需要开发对数据之间有效信息进行挖掘的研究工具, 拓展数据库中数据的应用价值.
4.2 建立多层级电池材料数据库
电池器件的性能不仅与电池材料的本征性质相关, 也与电池材料的微观形貌、多种材料之间的相互作用[47]、外界环境场及器件的宏观构造等多种不同空间和时间尺度上的性质紧密关联, 因此要获得从材料性质到器件性能之间的认识, 需要建立多层级的电池材料数据库[48,49]. 表4 列出了在原子尺度、微观尺度、外场效应、多相作用和宏观尺度上所涉及的电池材料数据及可能的用途和使用方法.
5 结 论
在材料基因组思想所推动的高通量技术发展下, 电池材料数据库获得了快速的发展, 在计算方法多样性、数据完备性和各类关键性质数据的获取方面都有进展. 未来, 电池材料数据库在提供材料数据的基础上, 将进一步面向应用需求, 构建不同层级的电池数据, 并整合嵌入通用的机器学习算法, 实现研究人员从数据获取、数据挖掘到数据预测的新材料探索过程. 电池材料数据库的建立将有效地提升基于材料基因组的科研数据的有效管理及公共服务能力, 对于与能源材料探索以及与电子、离子输运相关的物理性质的理解都会起到积极的作用, 同时也将为在材料研究领域引入人工智能方法提供必不可少的数据基础.
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
卫星应用(2022年3期)2022-05-23
中国典型病例大全(2022年11期)2022-05-13
中国典型病例大全(2022年11期)2022-05-13
初中生学习指导·提升版(2022年4期)2022-05-11
中学生数理化(高中版.高二数学)(2021年5期)2021-07-21
透析与人工器官(2020年1期)2020-11-16
中等数学(2020年6期)2020-09-21
中学生数理化·高一版(2016年7期)2016-12-07
试题与研究·中考化学(2016年1期)2016-09-30
