
基于Adaboost与朴素贝叶斯的农业短文本信息分类
2020-11-30 09:02陈鹏郭小燕
软件 2020年9期
陈鹏 郭小燕


摘 要: 朴素贝叶斯分类器过分依赖分类数据的质量,当待分类数据呈现复杂多元属性时,其分类的效果急剧下降,利用adaboost算法组合多个朴素贝叶斯分类器设计A_B模型。将3600份原始数据经过中文分词、句法分析、文本向量化后将A_B模型训练成一个A_B分类器。解决了分类器对于待分类数据敏感的问题,两个A_B分类器协同工作将二分类器转换为三分类器,解决了将原始农业文本信息分为农业新闻类,农业技术类,农业经济类三种类型的问题。分别利用600份标准数据与加了30%干扰信息的复杂数据测试分类器的分类效果,实验结果表明A_B分类器不仅对标准分类数据具有良好的分类效果,面对复杂多元的分类数据是仍然表现出较好的分类性能。利用不同的测试数据对A_B分类器测试发现:A_B分类器均具有良好的收敛性,其分类效果不依赖分类数据特征,具有分类效果的稳定性。
关键词: 贝叶斯;Adaboost;农业短文本;分类
中图分类号: S24;TP3 文献标识码: A DOI:10.3969/j.issn.1003-6970.2020.09.004
本文著录格式:陈鹏,郭小燕. 基于Adaboost与朴素贝叶斯的农业短文本信息分类[J]. 软件,2020,41(09):1318
【Abstract】: Naive Bayes classifier relies too much on the quality of classification data. When the classified data presents complex multivariate attributes, whose classification effect decreases sharply. Adaboost algorithm is used to combine multiple Naive Bayesian classifiers to design A_B model. After Chinese word segmentation, parsing and text vectorization, the A_B model is trained as an A_B classifier based the 3600 sets of original data. The problem that classifier is sensitive to data to be classified is solved. Two A_B classifiers work together to convert two two-category classifiers into one three-category classifiers, and solve the problem that the original agricultural text information is divided into three types: agricultural news, agricultural technology and agricultural economy. Using 600 sets of standard data and complex data with 30% disturbed information to test the classification effect of the classifier, the experimental results show that the A_B classifier not only has a good classification effect on the standard classification data, but also has a good classification performance to complex and multivariate classification data. Using different test data to test A_B classifier, it is found that A_B classifier has good convergence, whose classification effect does not depend on the characteristics of classification data, and has the stability of classification effect.
【Key words】: Bayes; Adaboost; Agricultural short text; Classification
0 引言
隨着农业信息化进程的加快,农业新闻网站,农产品销售网站,农业技术网站和农业数据库等农业信息平台也随之出现,农业数据随时间呈爆发式增长,海量的农业类数据需要处理。文本是网络信息的主要载体、BBS、博客、新闻评论中往往包含着诸如农业政策法规,农民的消费需求以及农村的发展趋势等数据信息。为了洞察农村、农业的发展规律,以及农民的消费规律,对这些文本信息进行合理地分析与挖掘显得非常必须。文本自动分类技术能够将海量非结构化文本信息规范归类,帮助人们更好地管理、利用和挖掘信息[1],为农业信息的服务对象提供更加精准的信息,把分散在网络中的信息进行整合,为用户提供个性化信息推送服务[2]。
近年来,国内许多研究机构对文本分类工作开展了研究工作,其中有代表性的有:中科院的史忠植、李晓黎把网络概念推理植入到文本分析中[3]。上海交通大学王永成将神经网络模型运用到了中文自动分类系统[4],山西大学刘开瑛开发金融自动分类系统[5],南京大学计算机系的刘静等对文本分类进行了研究,将分类规则和贝叶斯方法相结合放宽了贝叶斯对强独立性假设条件的要求[6]。目前文本分类的主要研究方法主要有:机器学习方法[7]和深度学习[8] 方法。对于高维数据以及抽象数据,已经有许多学者开始尝试使用深度
学习的方法并取得了一定的成果[9]。研究发现,深度学习在图像数据及语音数据中的优势表现明显,但是在短文本分析与计算中还未见突破性成果[10]。相比之下,传统的深度学习则表现出优越的性能[11]。传统机器学习常用模型有朴素贝叶斯模型(Naive Bayes)[12]、支持向量机模型(Support Vector Machine)[13]、逻辑回归模型(Logistic Regression)[14]和K近邻模型(K Nearest Neighbors)[15]等。朴素贝叶斯模型在文本特征提取,文本分类方面优势明显[16],传统的贝叶斯分类模型由于采用单分类器分类,使得分类的效果不理想[17]。通过Adaboost训练若干个弱分类器组合成强分类器,可大幅提升分类的准确率。杨丽丽利用Adaboost创建SVM分类器,解决棉叶螨危害的等级识别问题[18],胡祝华采用Adaboost进行鱼眼识别[19],顾玉萍将Ada boost应用于不平衡数据的分类问题中,以上研究都取得了较好的效果[20]。本文采用Adaboost算法将多个贝叶斯分类器(弱分类器)组合训练成一个强分类器(A_B分类器),解决农业网络短文本分类问题,分别使用规范数据以及加入干扰数据的复杂多元数据对A_B分类器测试发现,A_B分类器可以有效地进行农业短文本分类,对于待分类数据有一定的包容性,解决了复杂多元文本数据的分类问题,目前在国内尚未有这方面的研究探索成果发现。
1 材料与方法
1.1 原始语料预处理
采用网络爬虫技术分别从农业新闻网,农业技术网,和农业经济网,抓取4000份数据组成原始语料。由于html页面中抓取的原始语料存在干扰词组或者符号,为保证数据的有效性与准确性、降低冗余,需要对原始数据进行清洗,这主要包括:删除无效或者冗余信息、对缺失值进行处理(删除/填补)、对离群值进行处理(删除/均值填补)。为了降低数据的维度、提高分类的效率需对清洗后的数据进行中文分词和句法分析。
(1)中文分词
中文语法中单个的字往往没有特定的含义,为有效获取文本信息,需对清洗后的文本进行分词处理,即把连续的字序分解成词序。中文分词结果的好坏直接影响最后分类的结果,本文采用GitHub上开源的jieba分词技术进行分词处理[21-22],采用停用词库过滤技术去除无效词汇对待分类文本的干扰,从而对分词后所得的稀疏矩阵进行降维,提高分类的效率。
(2)句法分析与泛化
在对农业文本进行分词处理的基础上,为了统计高频词语,简化文本结构,降低分析的复杂度,需要对文本分词后的结果进行句法分析与泛化。本文利用哈工大社会计算与信息检索研究中心的语言技术平台()进行句法分析,并基于句法路径进行精确匹配[23],为了更准确地分析句子结构,本文归纳出常用的程度副词及常用词,如表2所示,利用该表能快速有效地泛化原始句法,重构网络短文本的句法结构。
将“蔬菜/价格/很快/回落”泛化后的结果为“蔬菜/价格/回落”,“很快”增强了“回落”得程度,但对分类结果没有影响,因此可以删除。
通过对原始语料进行清洗、中文分词、句法分析等预处理操做,消除了原始文本中的无效数据,空白数据,冗余数据,将短文分解成立离散的分词序列,以提高数据的有效性以及可操作性,降低数据的维度,原始语料预处理示例数表3所示。
1.2 文本向量化
(1)建立特征空间
经过数据清洗,文本分词技术,停用词过滤,句法分析后,将连续原始语料转换成离散的有效词汇信息,这些离散的有效词汇信息将作为文本分类的基础数据其中n为每份基础数据有效分词的个数,为有效词汇,。在基础数据中寻找具有代表性的特征词汇构成特征空间D(d1,d2…dm)作为分类的依据, 其中,m为特征空间中特征词的个数,为特征空间中词汇,。在本文中选取基础数据词频在前20%的词汇组成特征空间。
(2)向量化
对于每一份基础数据,映射到特征空间,形成m(m为特征词个数)维的向量空间,若基础文本中的某一个词在D中出现(一次或多次),在相应的位置的值设置为1,否则设置为0,如下式所示。
经过向量化后,每一份基础数据转换为一个与特征空间相应的m维0,1向量,所有的样本基础数据组成样本数据空间,在本文中数据空间分为:农业新闻类,农业技术类,农业经济类三种类型。
2 文本分类模型
将样本数据空间的数据分为两部分:训练空间和测试空间,其中为训练样本数量,为测试样本数量。对于训练空间中的数据做好类别标记,表示新闻类,农业技术类,农业经济类三种类别。样本数据用于训练分类模型,测试数据用来检测训练好的效果。
2.1 朴素贝叶斯文本分类器
贝叶斯分类器是基于贝叶斯定理,依据统计学实现分类的方法。將贝叶斯分类器用于文本分类时,其主要思想是将文章看做独立的单词集合,通过训练集,得到每个单词在不同类的概率大小,从而实现分类的效果。本文利用训练样本以及其所属的类别,计算每一个类别在训练空间中出现的概率,以及每一个训练样本中特征词在每个类别中出现的概率 ,如公式2,3所示。
式(2),(3)中,表示类在测试样本所有类别中所出现的频次,表示特征词在中出现的频次。为避免,本文采用转换,如式(3)所示,并取,V取所有词的权值总和。
训练完成后,利用测试样本测试所属的类别,计算方法为:
式中,为测试样本属于类的概率,为样本属于类的概率最大时的取值,即所属的类别。
2.2 AdaBoost算法
Adaboost是一种迭代算法[24],其核心思想是针对同一个训练集训练不同的分类器(弱分类器),将多个弱分类器集合起来,构成一个更强的最终分类器(强分类器)[25],算法流程如下。
2.3 AdaBoost-Bayes分类器
(1)A_B分类模型
为提升单个Bayes分类器的分类性能,本文设计A_B分类模型,利用Adaboost算法将多个Bayes分类器训练成强分类器(A_B分类器),其基本思想是对于同一个训练样本空间训练出T个有不同权值的Bayes分离器,这些分类器协同工作以照顾每一个样本的特征,从而达到提高分类效果的作用。A_B强分类器生成原理为:将标记好类别的训练样本输入到第一个Bayes分类器T1,输出分类结果,根据分类结果,得出此Bayes分类器的权值,从而计算每个训练样本的权值(分错的样本权值增大以便下一个分类器对其特别关注,分对的样本权值会减小),使原始的训练集变成一个带权训练集,利用带权训练集再次训练出下一个新的Bayes分类器T2并计算其权重,更新训练集中每个样本的权重产生新的训练集,再训练出新的Bayes分类器T3,一直往复,直到总误差率小于一定的值则训练结束,原理如果图2所示。
(2)多分类问题
在本文中,将样本空间分为3种类别,农业发展类(I类),农业技术类(II类),农业经济类(III类),传统的Adaboost分类器是一个将样本分为正类和负类的二分类器[18],为将二分类问题转化成三分类问题,设计以下转换方案进行二级分类的策略,将一个二分类问题转换为一个三分类问题,如图3所示。
2.4 分类流程
(1)设计分类词典,构建特征空间。
(2)将分类样本和分类词典进行比对,形成特征向量,从而产生样本空间。
(3)将样本空间划分为训练空间和测试空间。
(4)利用训练样本训练A_B模型,获得模型的参数值:Bayes分类器个数n,每个Bayes分类器的权重whi(i=1,2…,n),生成A_B分类器。
(5)将测试样本输入到训练好的A_B分类器,获得分类输出。
3 实验及结果分析
实验环境为intel i7处理器,12 GB机器内存。操作系统采用Windows 10企业版。软件开发环境为python2.7,PyCharm,采用sklearn的模型库进行算法的实现[17],采用scrapy爬虫框架爬取4000份数据组成原始语料,如表4所示。
其中,是分类为并且正确的文档数,是属于的文档数,为分类为的文档数。
本文首先利用朴素bayes,SVM,决策树对4000份经过预处理的标准数据进行30次分类实验,分类结果如表5所示。
从表5可以看出,使用朴素Bayes进行分类时准确率,召回率,F1检测值分别为92.01%,91.12%,91.62%,相比于SVM和决策树分类,朴素Bayes有一定的优势。为了测试以上算法对于多样性数据的鲁棒性,在测试数据中加入30%的干扰数据,使得数据中出现较多的离群值,从而增加测试数据的复杂性与多样性。实验结果表明,用Bayes,SVM,决策树进行复杂文本数据的分类时,其准确率、召回率、F1值都有大幅下降,证明基本Bayes,SVM,决策树在分类中对于待分类数据质量有很大程度的依赖,如果有离群数据或者不规范数据出现时分类的效果并不理想。
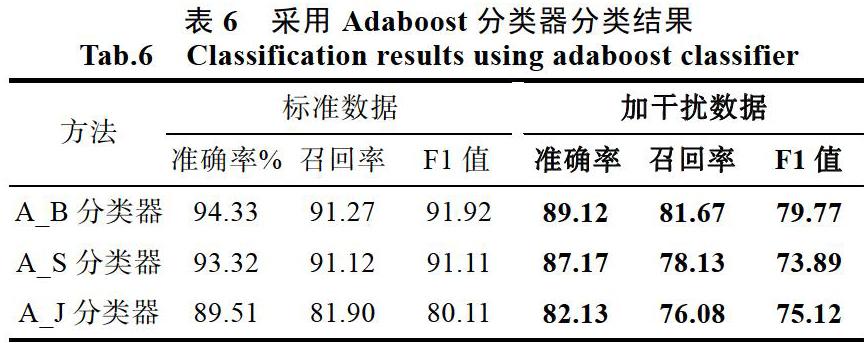
利用A_B分类器,以及A_S分类器(弱分类器采用SVM的Adaboost分类器),A_J分类器(弱分类器采用决策树的Adaboost分类器)分别采用规范数据与加30%干扰数据进行30次分类实验,实验结果如表6所示。从实验结果来看,采用标准规范测试数据测试发现分类的准确率、召回率、F1值都有所提升,其中表现最为明显的是A_J分类器,其准确率和基本决策树分类器相比提升了39.18%,召回率提升了33.12%,F1值提升了31.44%,说明利用Adaboost将弱分类器优化成强分类器对于文本分类有效可行。为测试分类器的鲁棒性,仍然加入30%的干扰数据测试发现,分类准确率、召回率,F1仍然有所下降,但下降的幅度和基本分類器相比已经有所降低,说明优化后的分类器对于测试数据质量已经有了某种程度的免疫性。对于复杂多样文本数据的分类结果发现,A_B分类器分类的准确率为89.12%,和普通bayes相比提升了9.01%,A_S分类器分类准确率为87.17%,和普通SVM相比提升了3.83%,A_J分类器准确率82.13%,和普通决策树分类相比提升了33.57%,从提升的幅度来看,A_J分类器表现明显,从分类的效果和准确率来看,A_B分类器占一定的优势,如图7所示。
通过加入干扰测试数据的实验结果来看,普通的分类器过分依赖数据的质量,如果数据中出现离群值等多元数据,则对分类效果有较大的影响。当利用Adaboost将多个普通分类器优化成强分类器后,分类准确率有一定的提升,从加入干扰数据对于分类效果的影响来看,利用Adaboost优化普通分类器,可以增加分类器的鲁棒性。从图7所示的实验结果来看,A_B分类器对分文本数据质量有较强的独立性,不会过分依赖待分类文本数据的质量以及特征,因此具有较好的普遍适用性。
为了测试A_B分类器对于不同质量数据分类的稳定性,跟踪利用不同待分类数据训练不同强分类器的过程发现,随着bayes基本分类器数目的增加,A_B分类器的分类准确率,召回率,F1值均在逐渐增加,通过30次试验取平均值发现,当bayes基本的数目达到15个左右时,分类准确率,召回率,F1值开始收敛,到达18个左右时分类准确率,召回率,F1值开始趋于一个稳定值,如图8a所示。跟踪A_S分类器的训练过程发现,基本分类器的个数对整个分类器的分类效果并没有很大的影响,随着基本SVM分类器个数的增加,A_S分类器并没有出现明显收敛的趋势如图8b所示。跟踪A_J分类器则发现,基本决策树分类器的个数增加到3个的时候,A_J分离器出现收敛程度趋势,因此其训练速度和A_B分类器相比占有一定的优势,但是观察其收敛值发现,A_B分类器分类准率、召回率、F1值发现,A_B分类效果优势明显。
从图8中可以看出,A_B分类器在经过训练后可以稳定地收敛,将其应用于农业文本类以及其他短文本分类时针对不同质量的数据均可以获得稳定的分类结果,同时A_B分類器对于待分数据有一定的包容性,多元复杂数据仍然可以获得较好分类效果。
4 结论
(1)设计了一种基于Adaboost算法的多个朴素贝叶斯分类模型A_B模型,提取样本数据出现频次前20%的词汇创建特征空间,3600份原始语料通过预处理,中文结巴分词,句法分析向量化为训练空间,将A_B模型训练为A_B分类器,将两个A_B分类器组合来解决三分类问题,实现将待分类文本分为农业新闻类,农业技术类,农业经济类三种类型分类的准确率,召回率F1值分别为:94.33%,91.27%,91.92%。
(2)将标准测试数据加入30%的干扰数据发现,和朴素贝叶斯分类器相比,A_B分类器对于数据质量有较大的包容性,对于复杂的多元数据而言仍然表现出较好的分类性能。将A_B分类器与A_S分类器,A_J分类器相比表现出较好的分类性能。
(3)通过30次试验测试发现,当在训练过程中当朴素贝叶斯分离器的数目增加到18个左右时,分类效果趋于稳定,证明A_B分类器具有良好的收敛性能,利用不同质量的测试数据测试分类器效果,均得到稳定的分类效果。但和A_J分类器相比,其收敛的速度较慢,今后可以从朴素贝叶斯权重更新算法等方面寻找突破。
参考文献
[1]赵明, 杜会芳, 董翠翠. 基于word2vec和LSTM的饮食健康文本分类研究[J]. 农业机械学报, 2017(10): 207-213.
[2]徐朝辉, 施丛丛, 吕超贤, 等. 基于结构化支持向量机的泄洪联动设计[J]. 软件, 2015, 36(9): 62-65.
[3]李志欣, 郑永哲, 张灿龙, 等. 结合深度特征与多标记分类的图像语义标注[J]. 计算机辅助设计与图形学学报, 2018, 30(02): 318-326.
[4]刁倩, 王永成, 张惠惠. 基于神经网络的中文信息概念联想构造算法[J]. 情报学报, 2000(02): 170-175.
[5]谷波, 李济洪, 刘开瑛. 基于COSA算法的中文文本聚类[J]. 中文信息学报, 2007(06): 65-70.
[6]刘静, 尹存燕, 陈家骏. 一种规则和贝叶斯方法相结合的文本自动分类策略[J]. 计算机应用研究, 2005(07): 84- 86+89.
[7]Lewis D D. Challenges in machine learning for text classification[C]//Conference on Computational Learning Theory. 1996.
[8]Liu J, Chang W C, Wu Y, et al. Deep Learning for Extreme Multi-label Text Classification[C]//International Acm Sigir Conference on Research & Development in Information Retrieval. ACM, 2017.
[9]Shen F, Luo X, Chen Y. Text classification dimension reduction algorithm for Chinese web page based on deep learning[C]// International Conference on Cyberspace Technology. IET, 2014.
[10]He Y, Xie J, Xu C. An improved naive Bayesian algorithm for web page text classification[C]//Eighth International Conference on Fuzzy System & Knowledge Discovery. 2011.
[11]Tong S, Koller D. Support Vector Machine Active Learning with Applications to Text Classification[J]. Journal of Machine Learning Research, 2002, 2(1): 999-1006.
[12]张洁琳. 试论贝叶斯网络在用户信用评估中的应用[J]. 软件, 2018, 39(12): 194-197.
[13]Manne S, Kotha S K, Hyderabad O. A Query based Text Categorization using K-Nearest Neighbor Approach[J]. International Journal of Computer Applications, 2013, 32(7): 16-21.
[14]李晓燃. 基于深度学习的倾斜车牌矫正识别[J]. 软件, 2018, 39(10): 215-219.
[15]王子牛, 吴建华, 高建瓴, 等. 基于深度神经网络和 LSTM 的文本情感分析[J]. 软件, 2018, 39(12): 19-22.
[16]Yang G, Lin Z Y, Chang Y X, et al. Comparative analysis on feature selection based Bayesian text classification[C]// International Conference on Computer Science & Network Technology. IEEE, 2013.
[17]吴文俊, 殷恒辉, 陈麟. 基于 AdaBoost 算法的人脸检测系统设计[J]. 软件, 2018, 39(10): 145-149.
[18]杨丽丽, 张大卫, 罗君. 基于SVM和AdaBoost的棉叶螨危害等级识别[J]. 农业机械学报, 2019. 50(2): 14-20.
[19]胡祝华, 张逸然, 赵瑶池, 等. 权重约束AdaBoost鱼眼识别及改进Hough圆变换瞳孔智能测量[J]. 农业工程学报, 2017, 33(23): 226-232.
[20]顾玉萍, 程龙生. 基于MTS-AdaBoost的不平衡数据分类研究[J]. 计算机应用研究, 2018, 35(02): 346-348+353.
[21]张永军. 一种改进的高效贝叶斯短信文本分类器[J], 南京师范大学学报(工程技术版), 2014, 14(3):
[22]林江豪. 一种基于朴素贝叶斯的微博情感分类[J], 计算机工程与科学, 2012, 34(9):
[23]张洁琳. 试论贝叶斯网络在用户信用评估中的应用[J]. 软件, 2018, 39(12): 194-197.
[24]徐凯, 陈平华, 刘双印. 基于AdaBoost-Bayes算法的中文文本分类系统[J]. 微电子学与计算机, 2016, 33(6): 63-67.
[25]Iwakura T, Saitou T, Okamoto S. An AdaBoost for Efficient Use of Confidences of Weak Hypotheses on Text Categorization[C]// Pacific Rim International Conference on Artificial Intelligence. Springer International Publishing, 2014.
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
大众健康(2021年6期)2021-06-08
法律方法(2021年4期)2021-03-16
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
数理化解题研究(2017年4期)2017-05-04
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
电子器件(2015年5期)2015-12-29
遗传(2014年2期)2014-02-28
